Running on a microcontroller?We recently released a brand-new approach to perform object detection tasks on microcontrollers, FOMO, if you are using a constraint device that does not have as much compute, RAM, and flash as Linux platforms, please head to this end-to-end tutorial: Detect objects using FOMOAlternatively, if you only need to recognize a single object, you can follow our tutorial on Image classification - which performs image classification, hence, limits you to a single object but can also fit on microcontrollers.
1. Prerequisites
For this tutorial, you’ll need a supported device. If you don’t have any of these devices, you can also upload an existing dataset through the Uploader - including annotations. After this tutorial you can then deploy your trained machine learning model as a C++ library and run it on your device.2. Building a dataset
In this tutorial we’ll build a model that can distinguish between two objects on your desk - we’ve used a lamp and a coffee cup, but feel free to pick two other objects. To make your machine learning model see it’s important that you capture a lot of example images of these objects. When training the model these example images are used to let the model distinguish between them. Capturing data Capture the following amount of data - make sure you capture a wide variety of angles and zoom level. It’s fine if both images are in the same frame. We’ll be cropping the images later to be square so make sure the objects are in the frame.- 30 images of a lamp.
- 30 images of a coffee cup.
- Collecting image data from the Studio - for the Raspberry Pi 4 and the Jetson Nano.
- Collecting image data with your mobile phone
AI-Assisted LabelingUse AI-Assisted Labeling for your object detection project! For more information, check out our blog post.
3. Designing an impulse
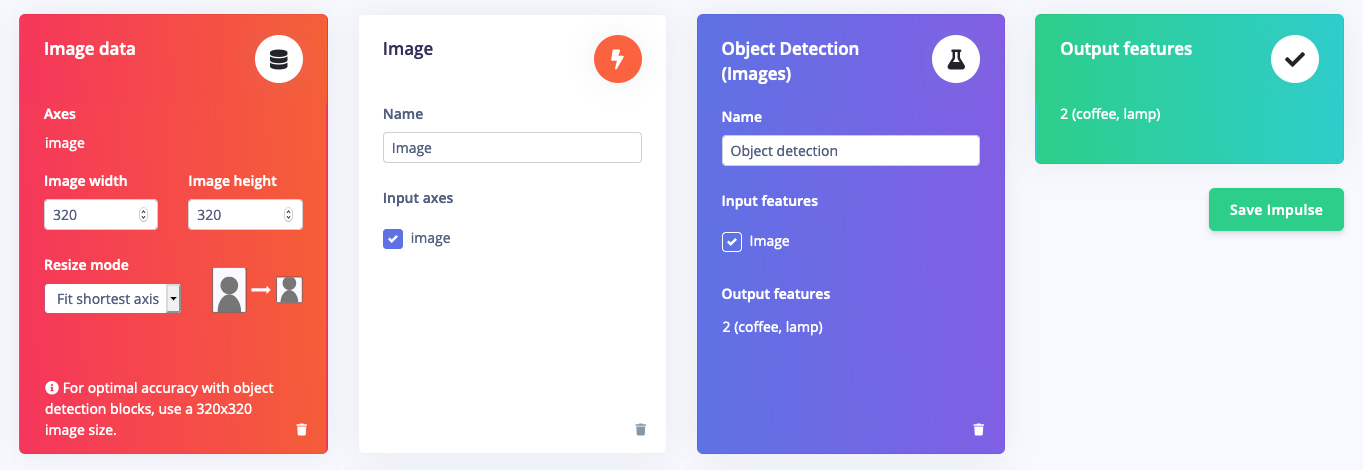
With the training set in place you can design an impulse. An impulse takes the raw data, adjusts the image size, uses a preprocessing block to manipulate the image, and then uses a learning block to classify new data. Preprocessing blocks always return the same values for the same input (e.g. convert a color image into a grayscale one), while learning blocks learn from past experiences. For this tutorial we’ll use the ‘Images’ preprocessing block. This block takes in the color image, optionally makes the image grayscale, and then turns the data into a features array. If you want to do more interesting preprocessing steps - like finding faces in a photo before feeding the image into the network -, see the Building custom processing blocks tutorial. Then we’ll use a ‘Transfer Learning’ learning block, which takes all the images in and learns to distinguish between the two (‘coffee’, ‘lamp’) classes. In the studio go to Create impulse, set the image width and image height to320, the ‘resize mode’ to Fit shortest axis and add the ‘Images’ and ‘Object Detection (Images)’ blocks. Then click Save impulse.
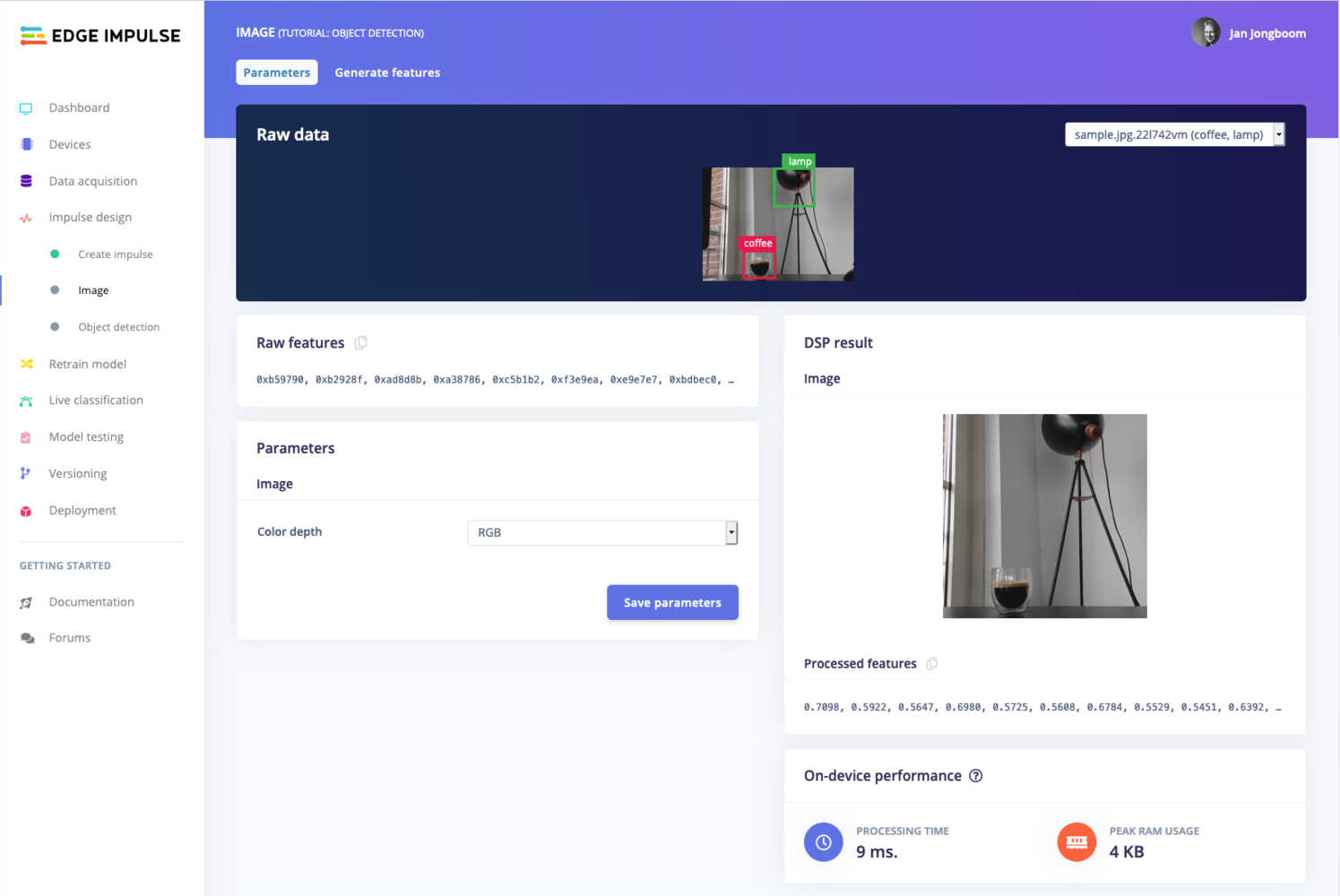
- Resize all the data.
- Apply the processing block on all this data.
- Create a 3D visualization of your complete dataset.
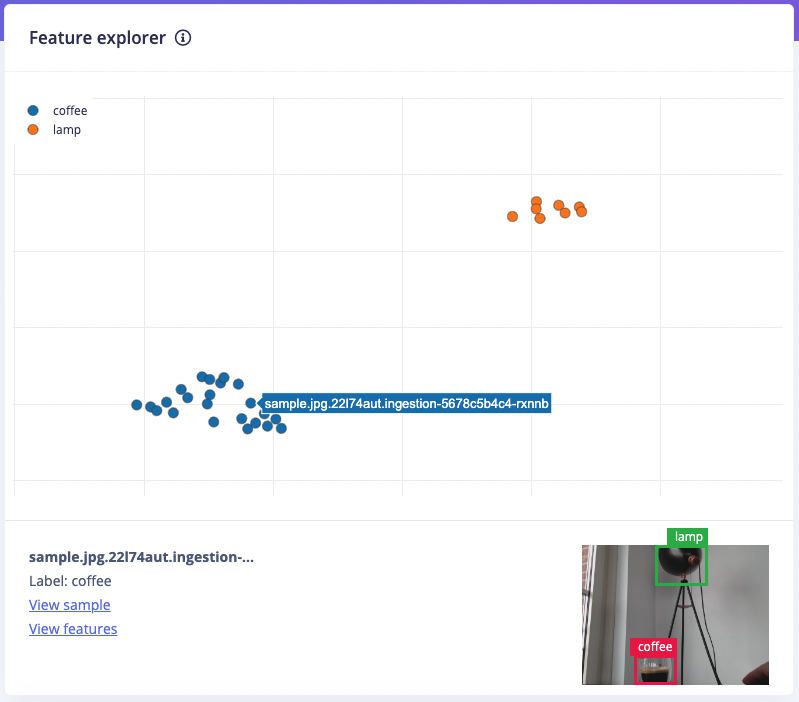
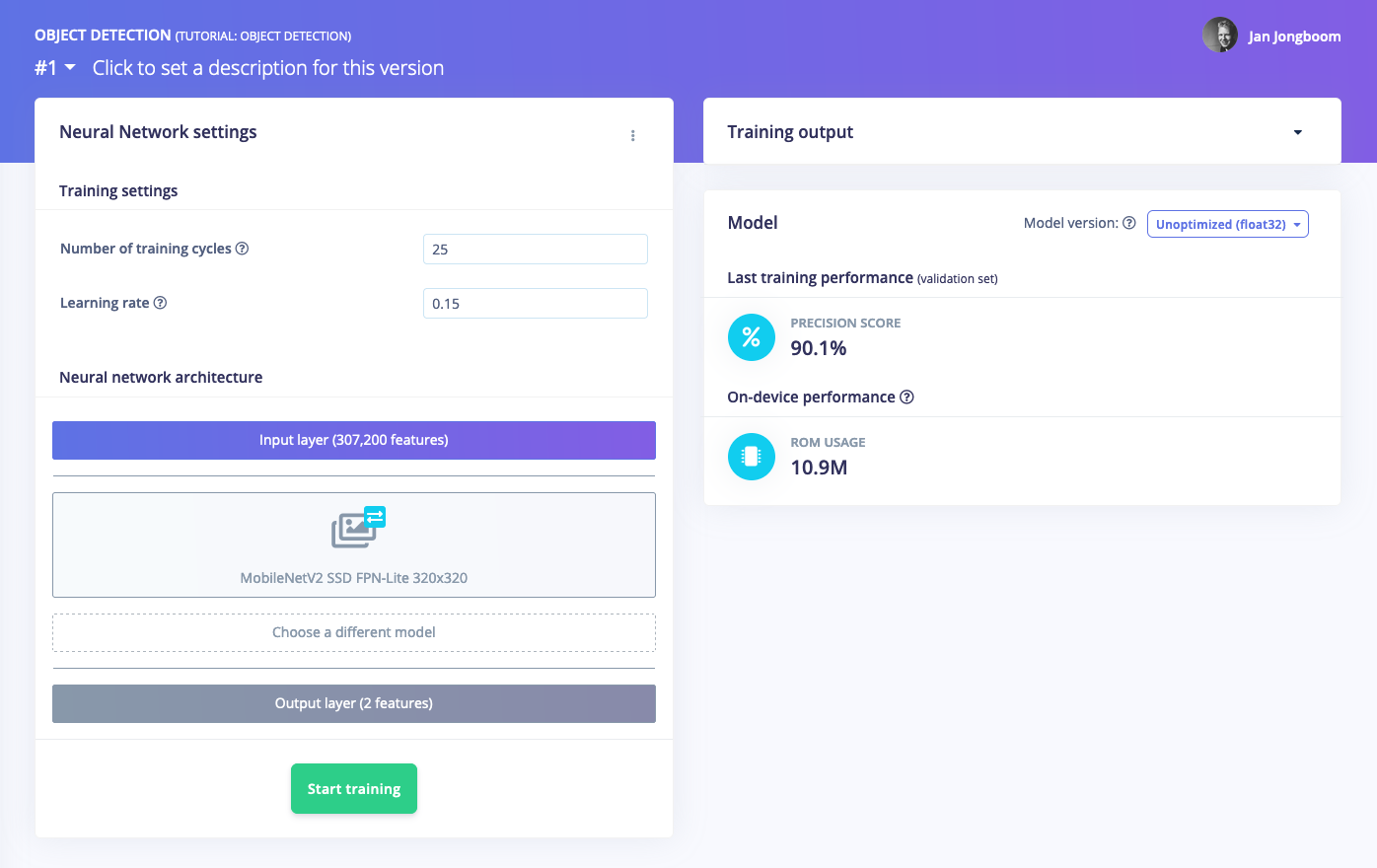
4. Validating your model
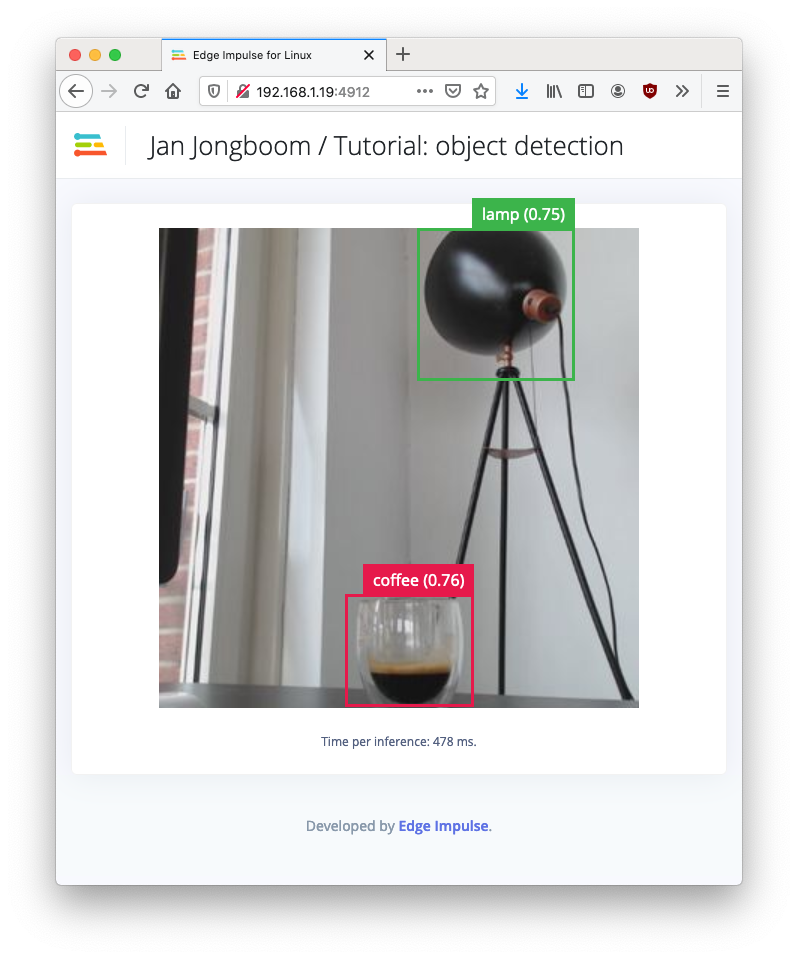
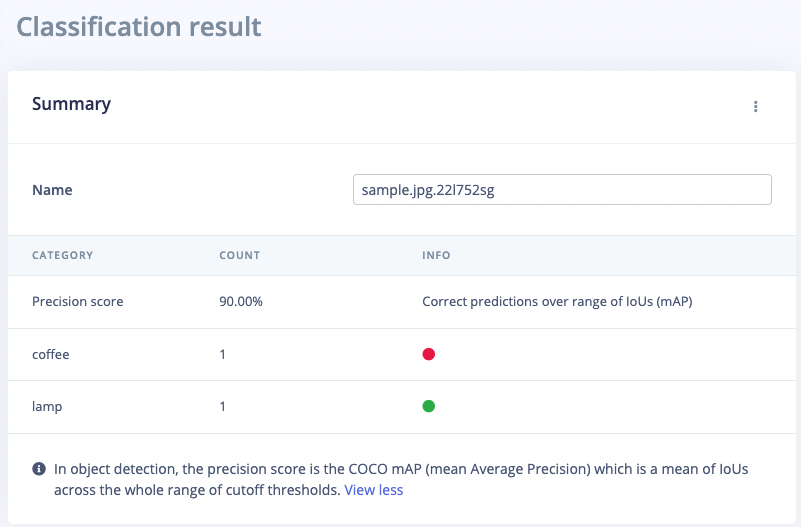
With the model trained let’s try it out on some test data. When collecting the data we split the data up between a training and a testing dataset. The model was trained only on the training data, and thus we can use the data in the testing dataset to validate how well the model will work in the real world. This will help us ensure the model has not learned to overfit the training data, which is a common occurrence. To validate your model, go to Model testing and select Classify all. Here we hit 92.31% precision, which is great for a model with so little data.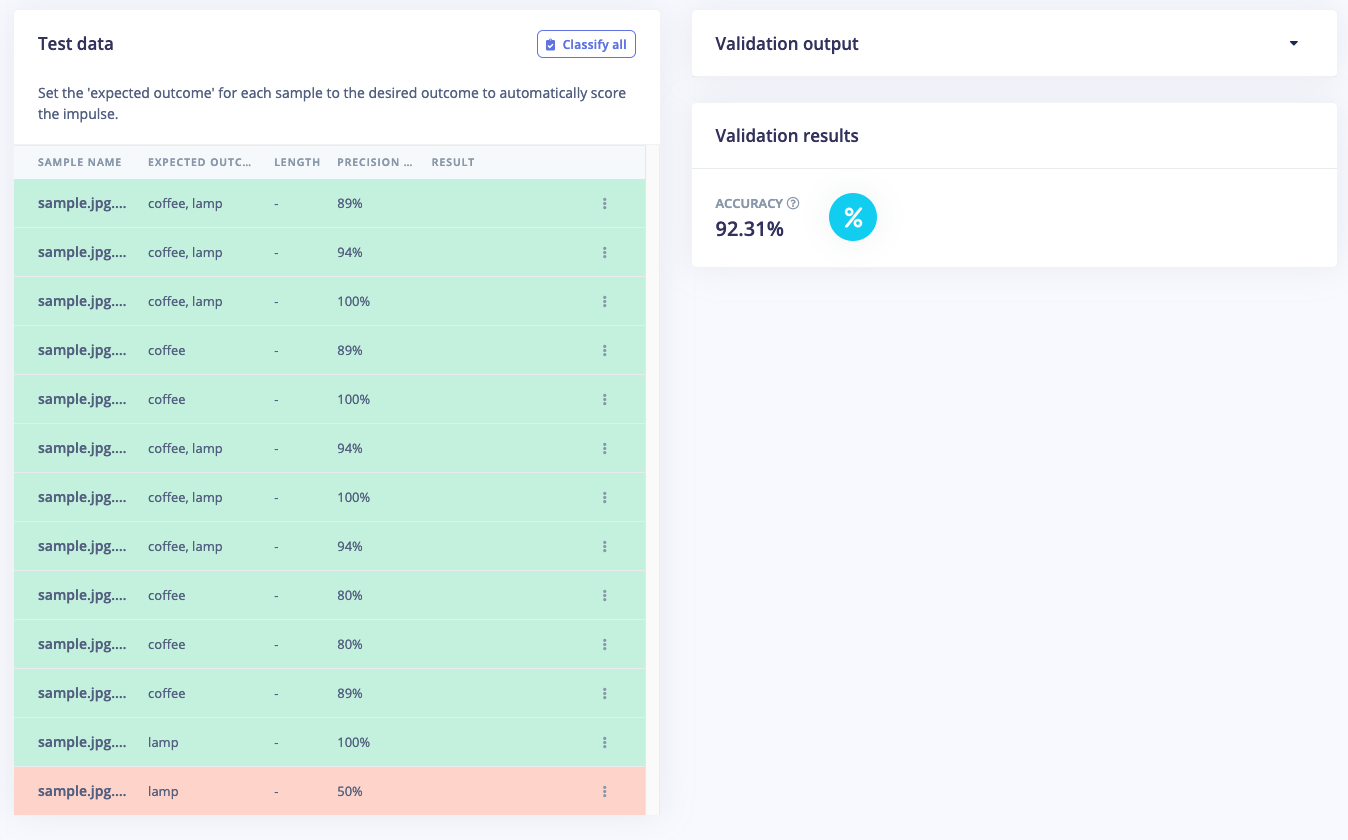
Live Classification Result
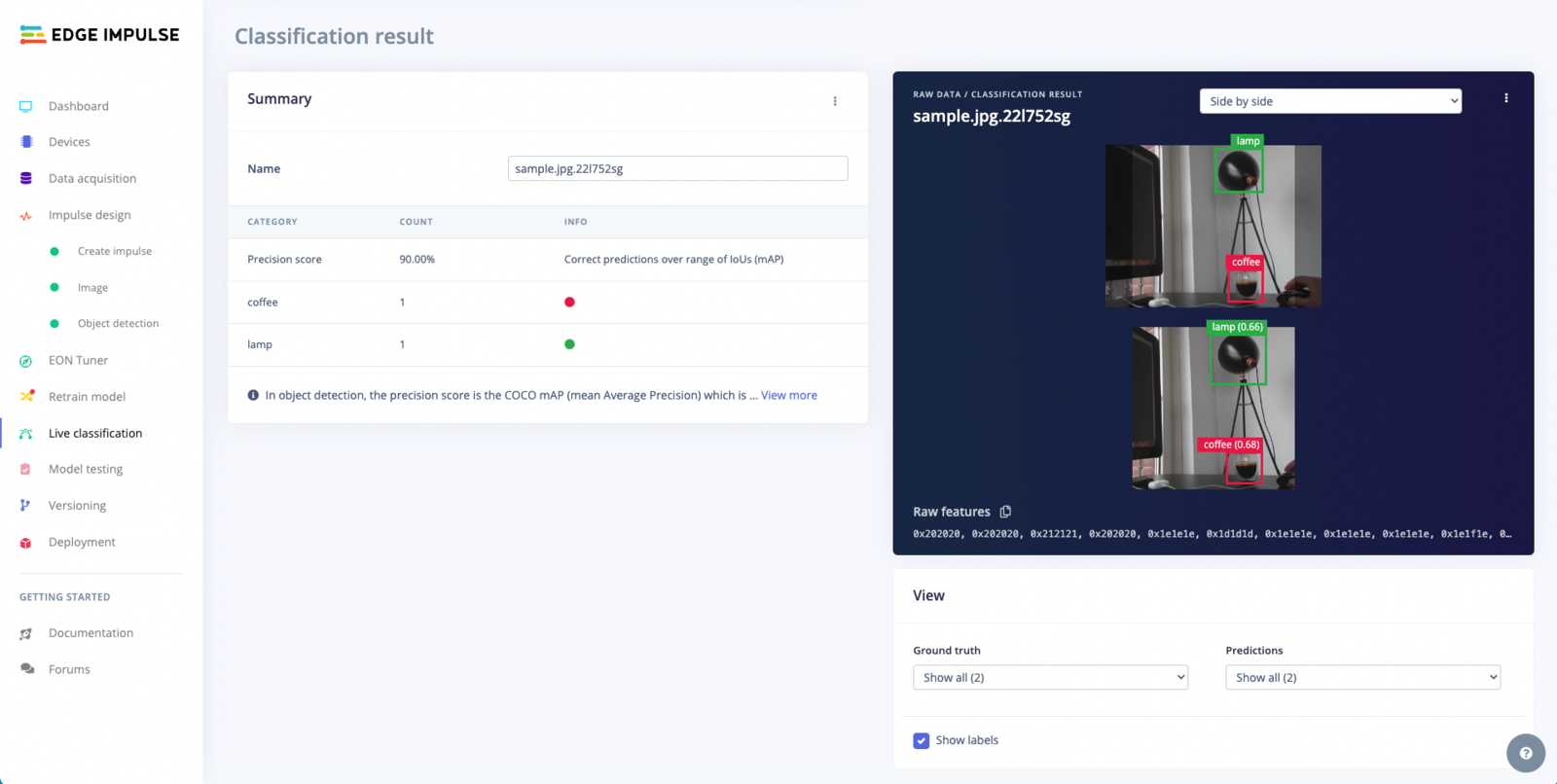
Overlay Mode for the Live Classification Result
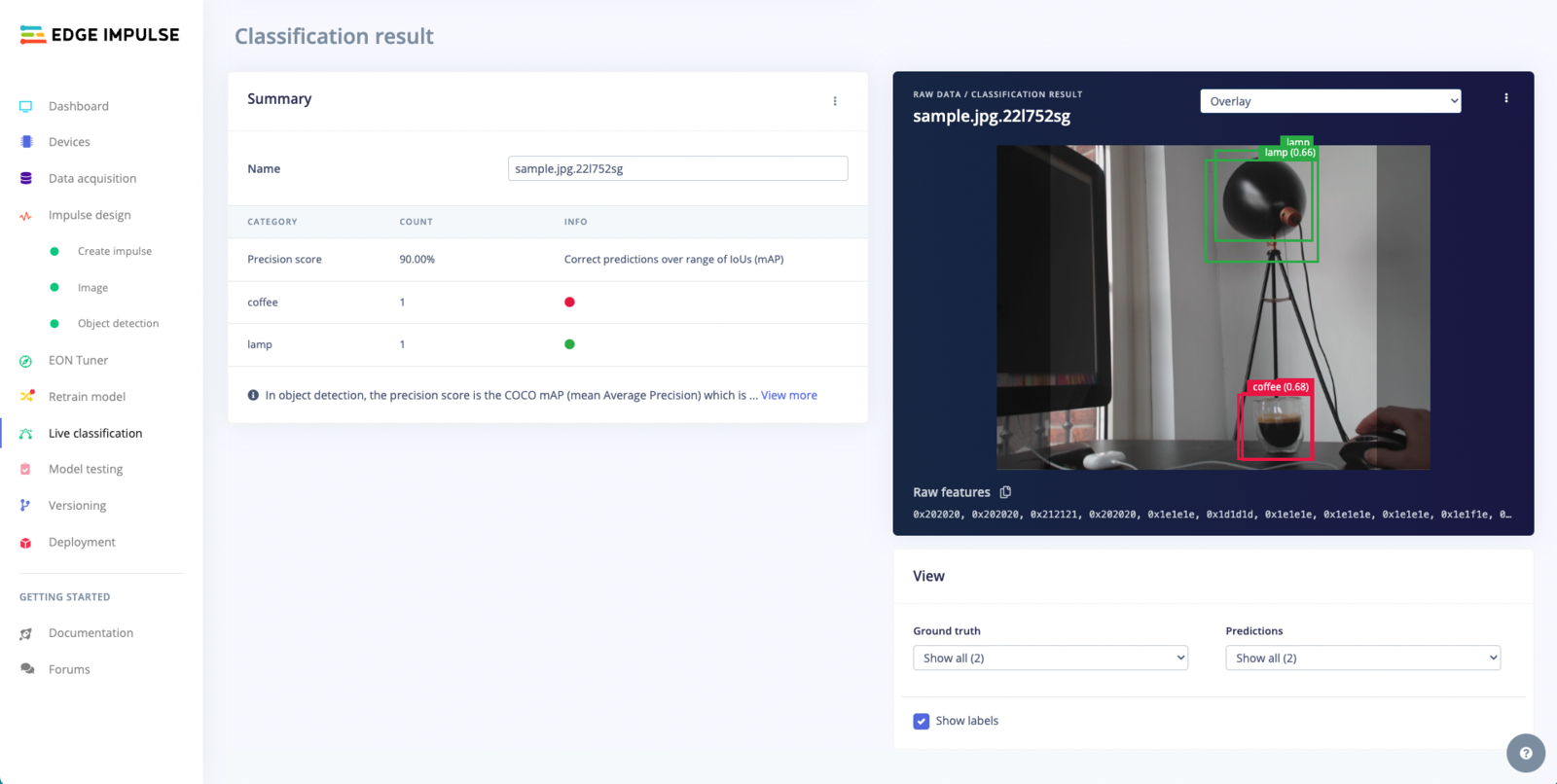
Summary Table
5. Running the model on your device
With the impulse designed, trained and verified you can deploy this model back to your device. This makes the model run without an internet connection, minimizes latency, and runs with minimum power consumption. Edge Impulse can package up the complete impulse - including the preprocessing steps, neural network weights, and classification code - in a single C++ library or model file that you can include in your embedded software. Running the impulse on your Raspberry Pi 4 or Jetson Nano From the terminal just runedge-impulse-linux-runner. This will build and download your model, and then run it on your development board. If you’re on the same network you can get a view of the camera, and the classification results directly from your dev board. You’ll see a line like: