Some of the key advantages of EON Compiler, which include:
Key Benefits of EON Compiler:
- 25-65% less RAM
- 10-35% less flash
- Same accuracy as TFLite
- Faster inference
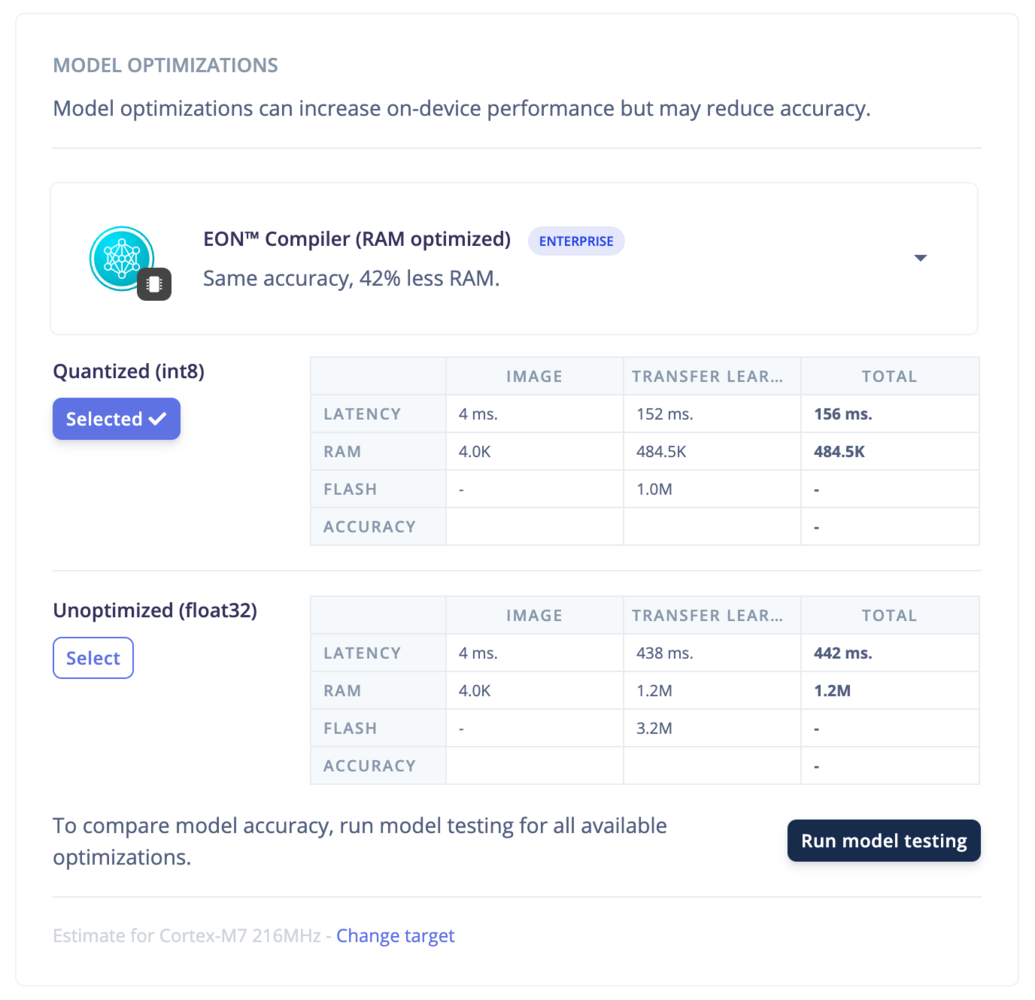
EON Compiler (RAM optimized)
Only available on the Enterprise planThis feature is only available on the Enterprise plan. Review our plans and pricing or sign up for our free expert-led trial today.
Examples
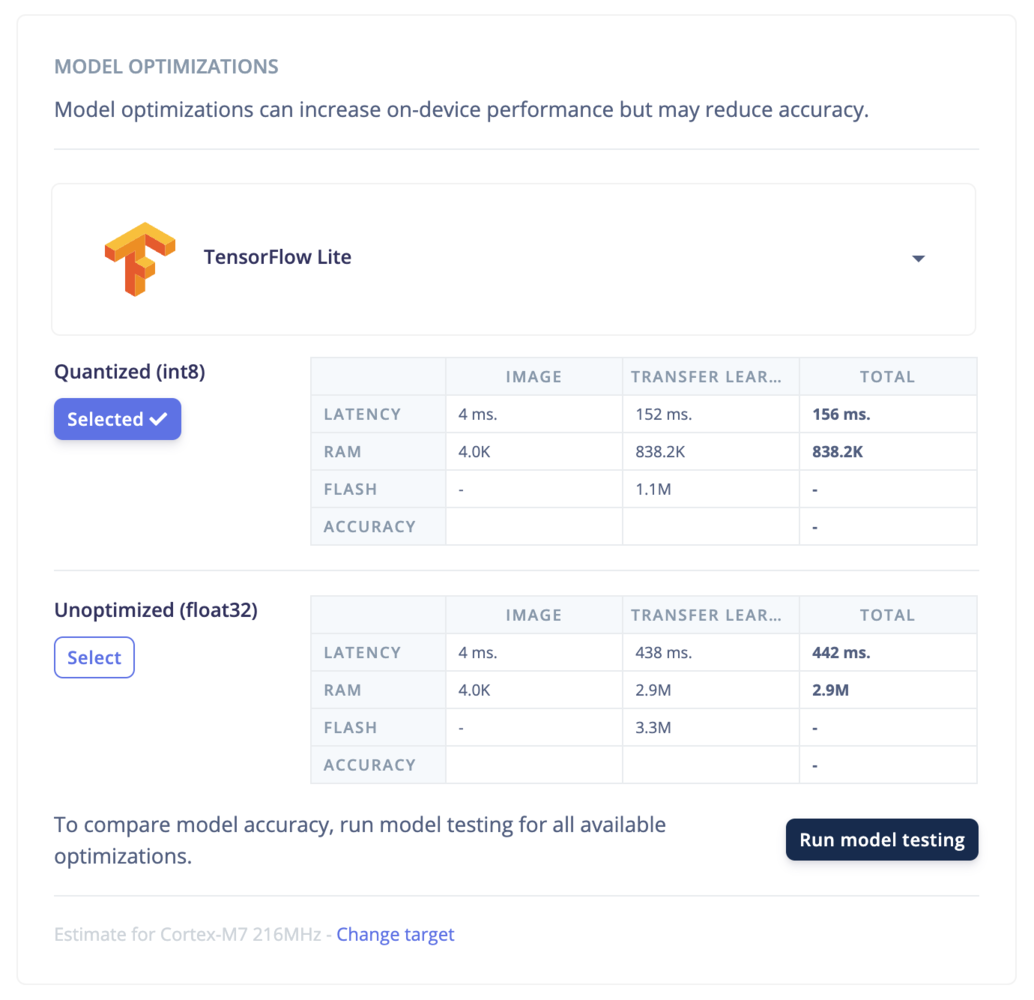
- LiteRT (previously Tensorflow Lite)
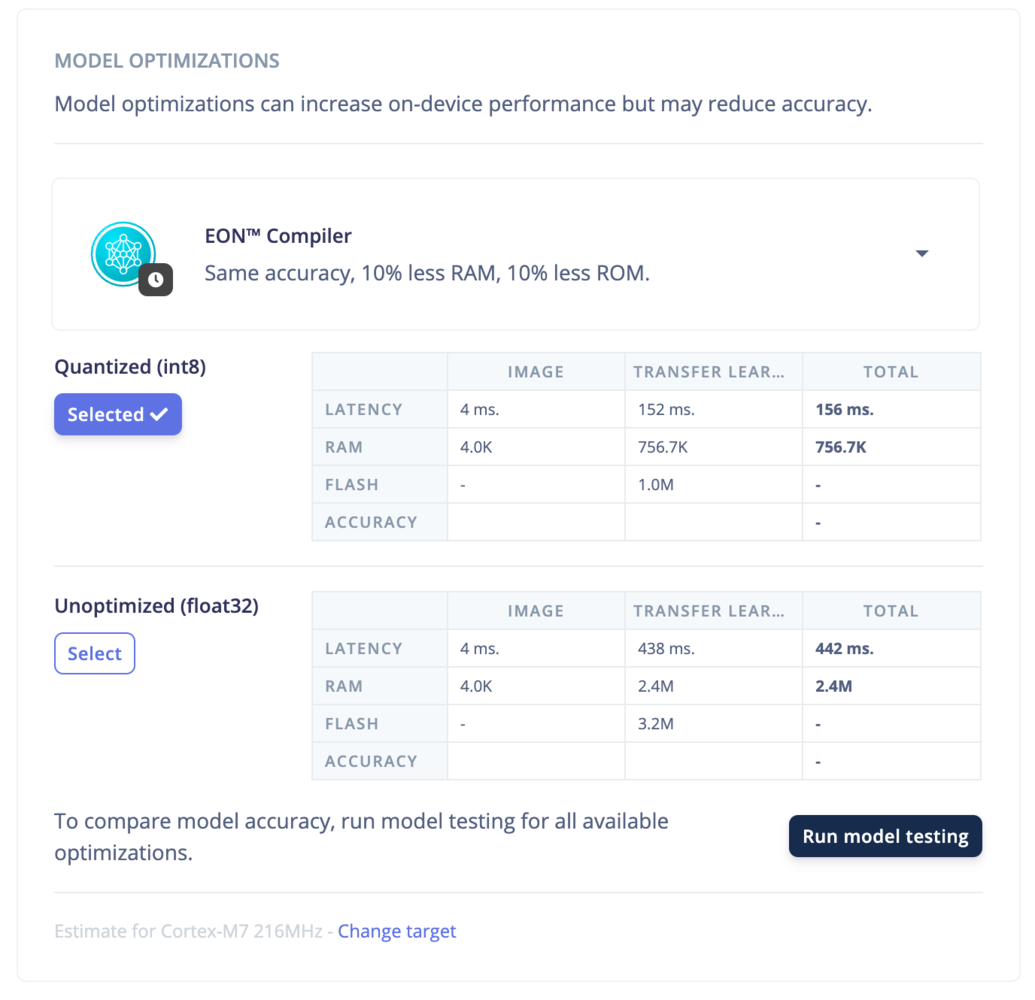
- EON Compiler
- EON Compiler (RAM optimized)
On-device resource usage - TFlite
- Processing blocks: Here we can see the optimizations for the DSP components of the compiled model DSP components. e.g. Spectral Features, MFCC, FFT, Image, etc.
- Learn Blocks: The performance of the compiled model on the device. Here we see the time it takes to run inference.
- Latency: the time it takes to run the model on the device.
- RAM: the amount of RAM the model uses.
- Flash: the amount of ROM the model uses.
- Accuracy: the accuracy of the model.
How does it work?
The input of the EON compiler is a LiteRT (previously Tensorflow Lite) Flatbuffer file containing model weights. The output is a .cpp and .h files containing unpacked model weights and functions to prepare and run the model inference. Regular Tflite Micro is based on LiteRT (previously Tensorflow Lite) and contains all the necessary instruments for reading the model weights in Flatbuffer format (which is the content of .tflite file), constructing the inference graph, planning the memory allocation for tensors/data, executing the initialization, preparation and finally invoking the operators in the inference graph to get the inference results. The advantage of using the traditional Tflite Micro approach is very versatile and flexible. The disadvantage is that all the code for getting the model ready on the device is pretty heavy for embedded systems. To overcome these limitations, our solution involves performing resource-intensive tasks, such as reading the model from Flatbuffer, constructing the graph, and planning memory allocation directly on our servers. Subsequently, the EON compiler performs the generation of C++ files, housing the necessary functions for the Init, Prepare, and Invoke stages. These C++ files can then be deployed on the embedded systems, alleviating the computational burden on those devices. The EON Compiler (RAM Optimized) option adds, on top of the above, a novel approach by computing values directly as needed and minimizing the storage of intermediate results. This method leads to a significant decrease in RAM usage - sometimes at the cost of a slightly higher latency/flash - without impacting the accuracy of model predictions. In practice, we demonstrated this with our default 2D convolutional model for visual applications. By slicing the model graph into smaller segments, we managed to reduce the RAM usage significantly — by as much as 40 to 65% compared to LiteRT (previously Tensorflow Lite) — without altering the accuracy or integrity of the model’s predictions.Limitations
The EON Compiler, including the EON Compiler (RAM optimized) version, optimizes neural network projects effectively. However, there are some important limitations to keep in mind: Unsupported Operators Not all operators are supported by our compiler. If your model includes an operator we don’t support, the compiler won’t be able to fully optimize your model. This means that certain complex operations within your model might prevent the compiler from working as efficiently as possible. Concerning the EON Compiler (RAM optimized) option, our slicing algorithm supports limited operators. For instance, if a standard convolutional model incorporates an unsupported operator in its architecture, the compiler will not be able to perform beyond that point. This limitation could restrict the application of our compiler to models that use only supported operations. Residual Layers We support models with certain types of residual layers—specifically, those that feed directly into a subsequent layer, like in MobileNet. However, if your model processes residuals in a more complex manner, the EON Compiler may not optimize it effectively.More metrics
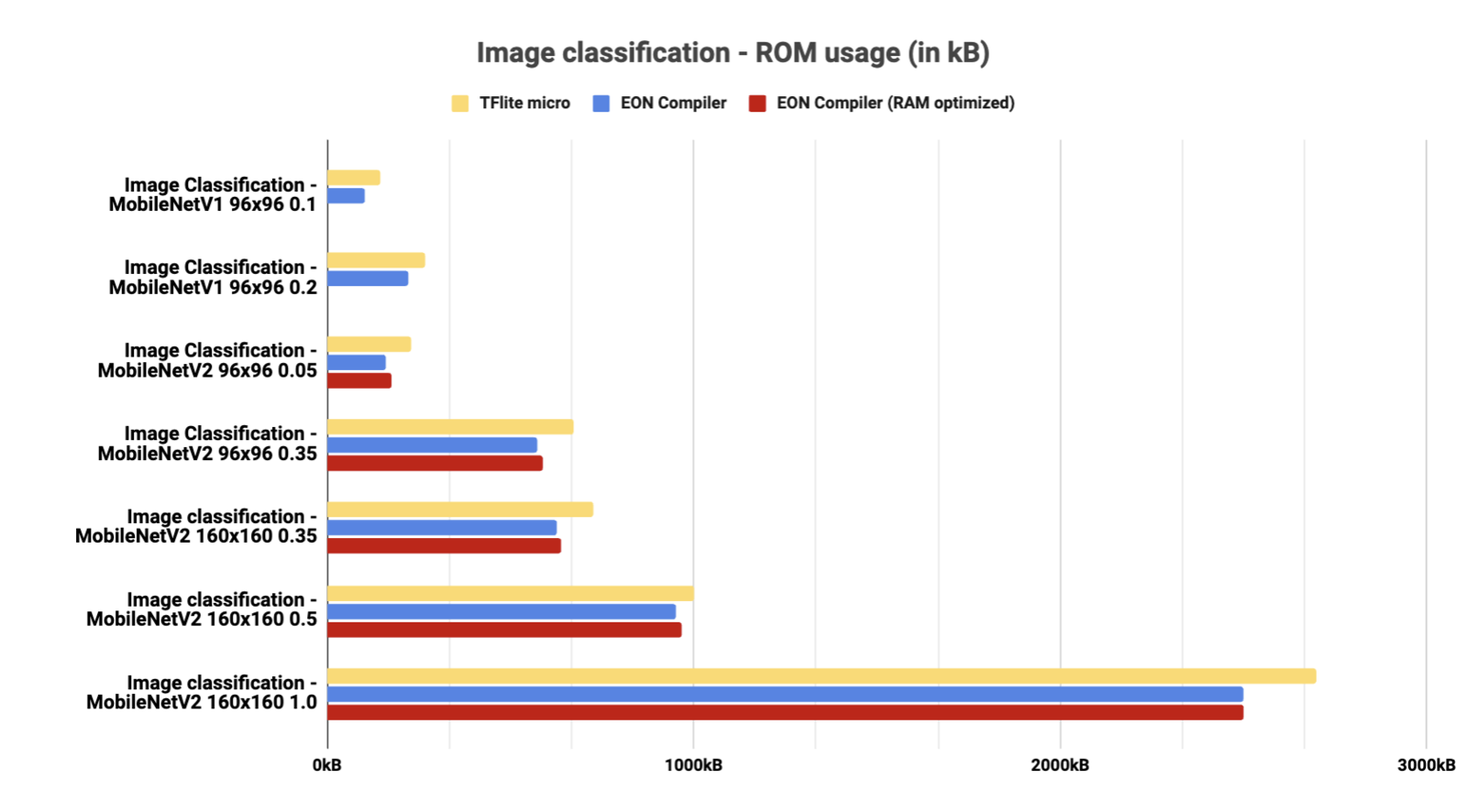
In this section, we tested many different architectures. Some architectures may not be available with TFLite micro or with the EON-Compiler (RAM-Optimized) - see the limitations section.Image classification
- RAM
- ROM
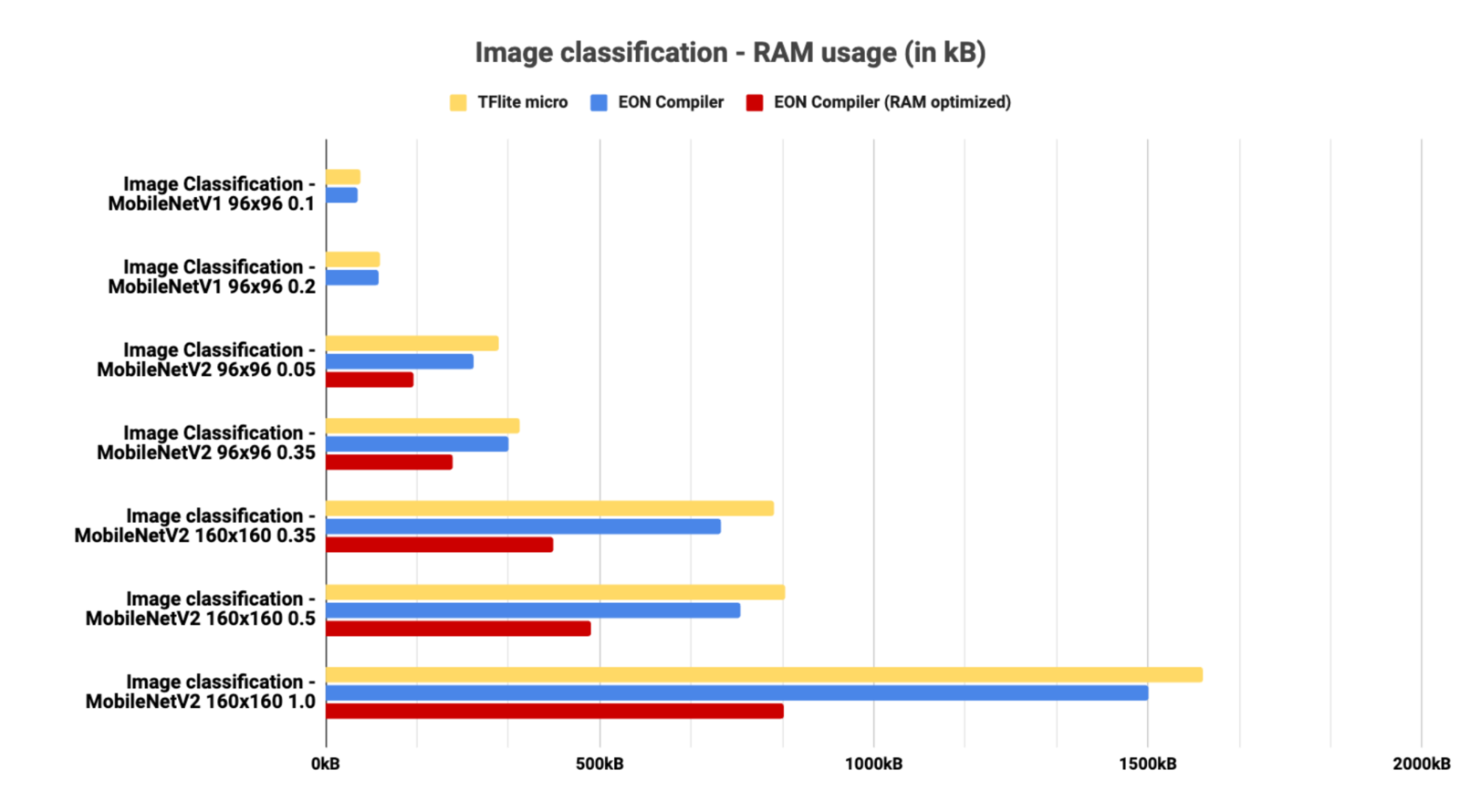
RAM usage for Image classification architectures
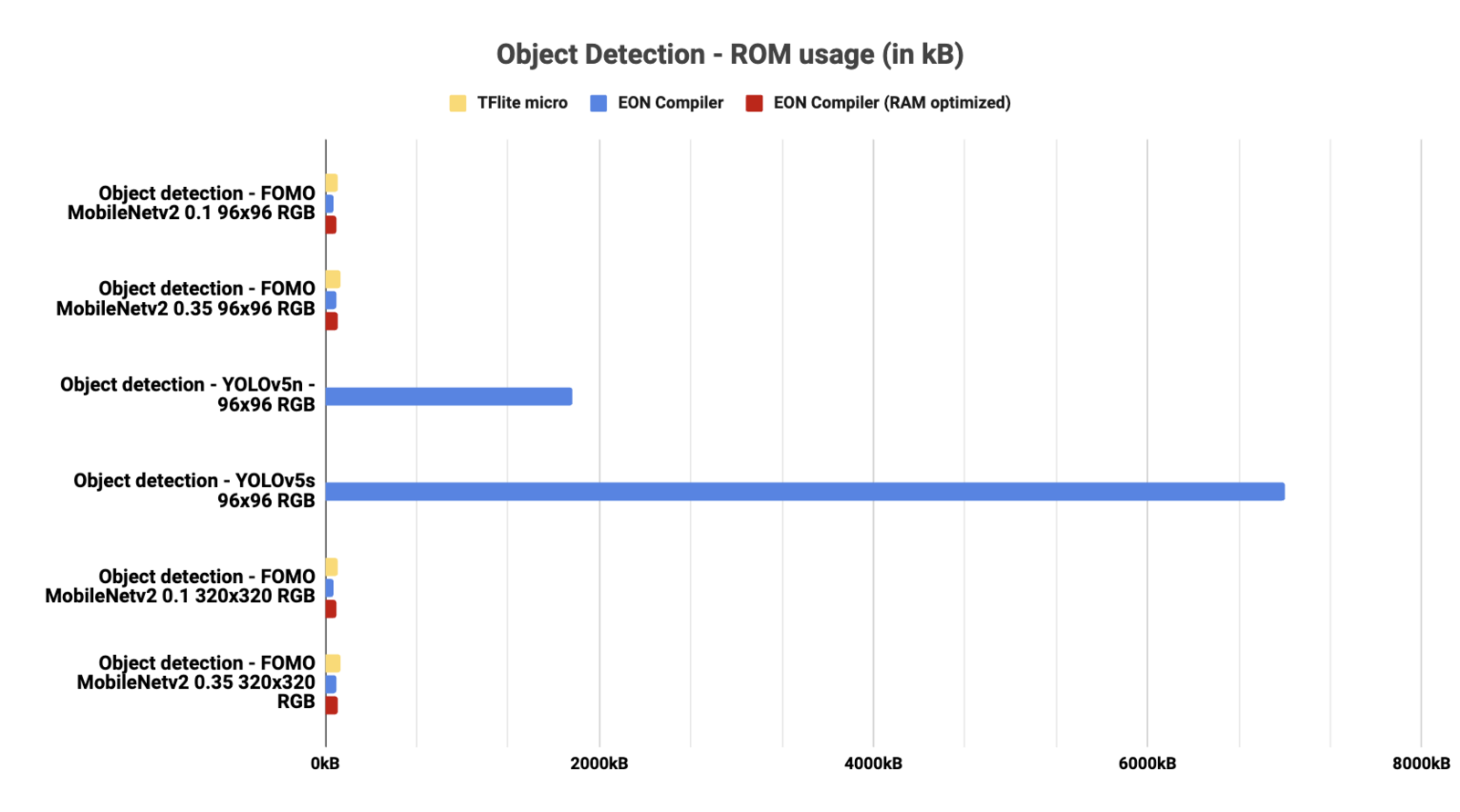
Object Detection
- RAM
- ROM
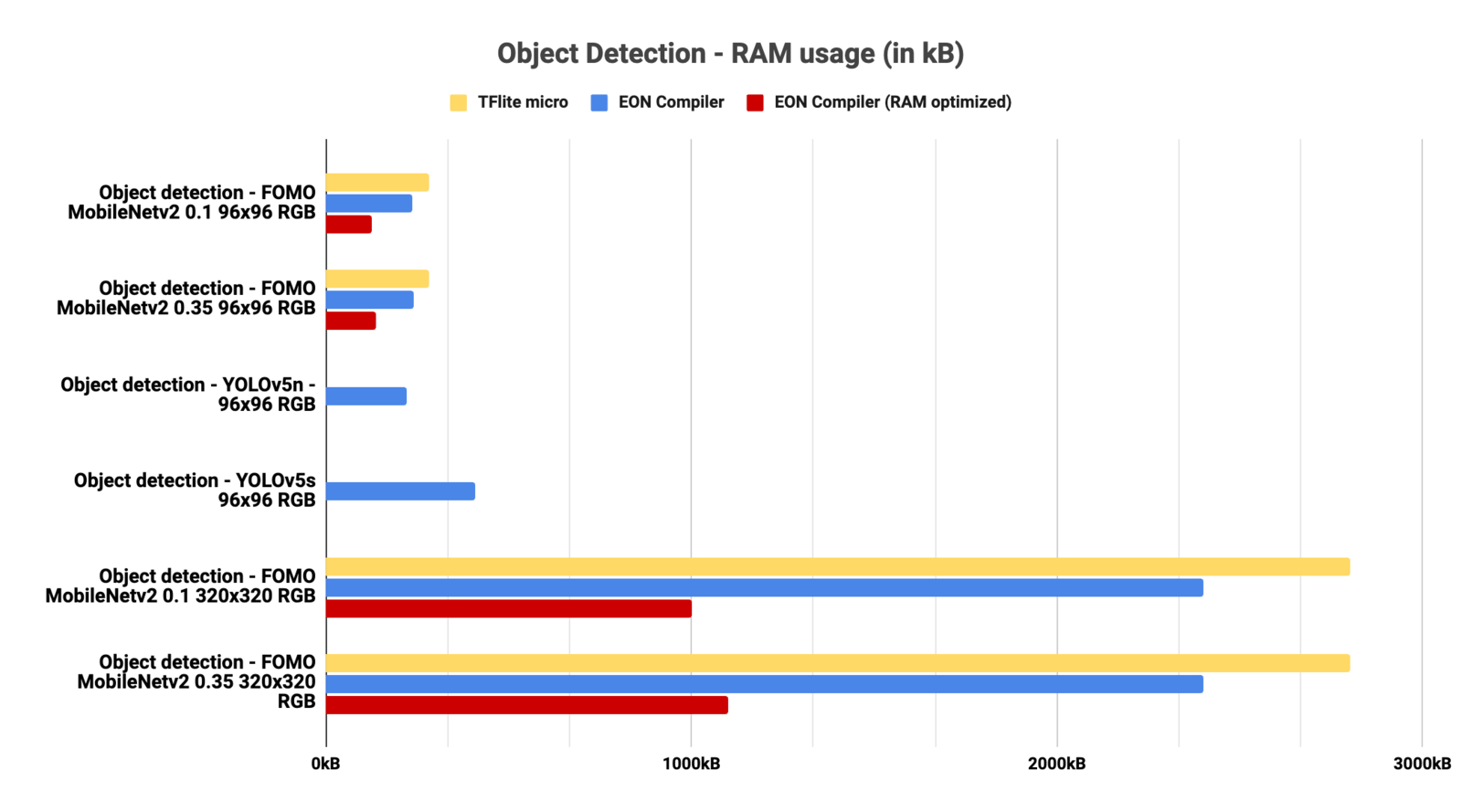
RAM usage for Object Detection architectures
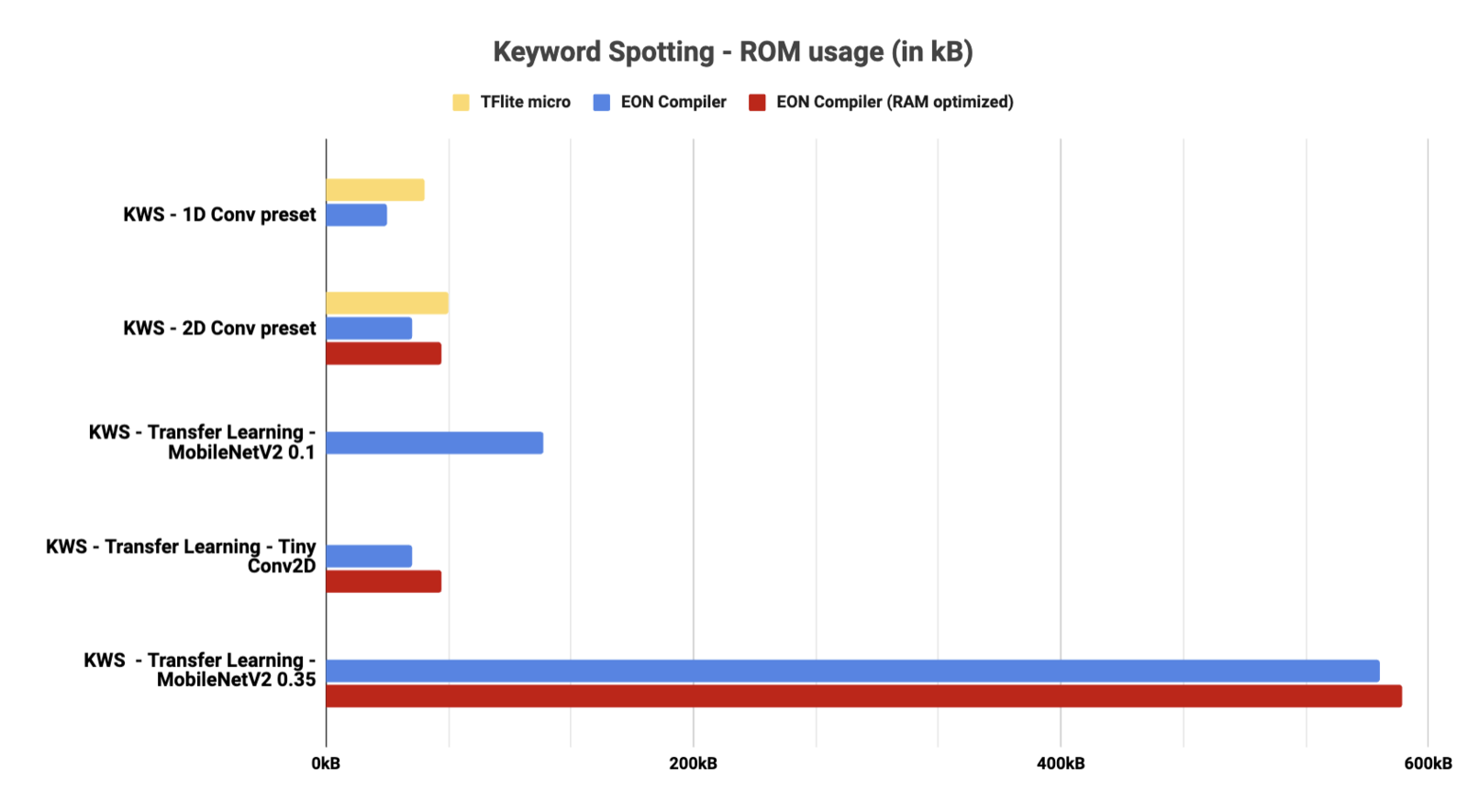
Keyword Spotting
- RAM
- ROM
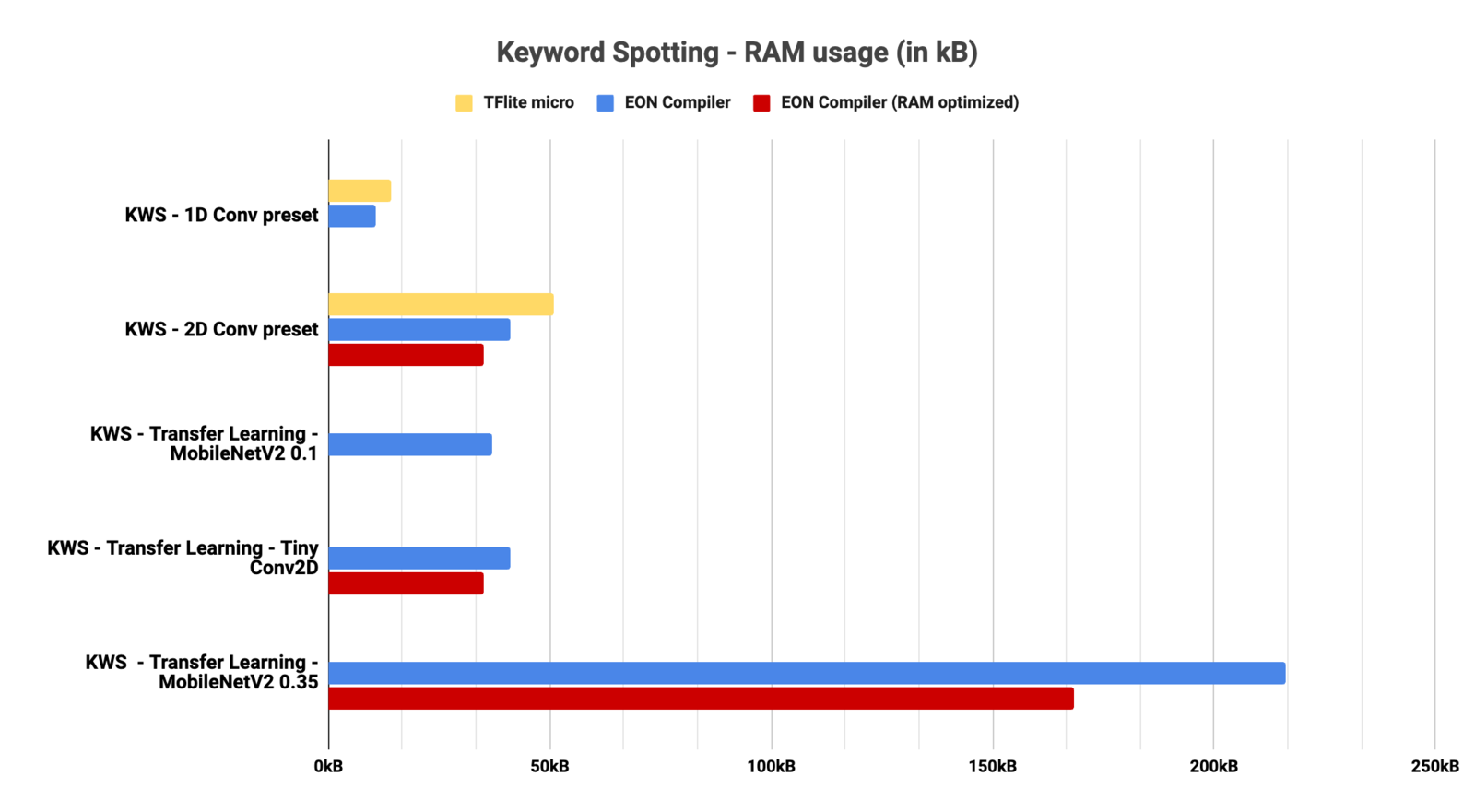
RAM usage for Keyword Spotting architectures - 3960 features (MFE 1000ms 16kHz)
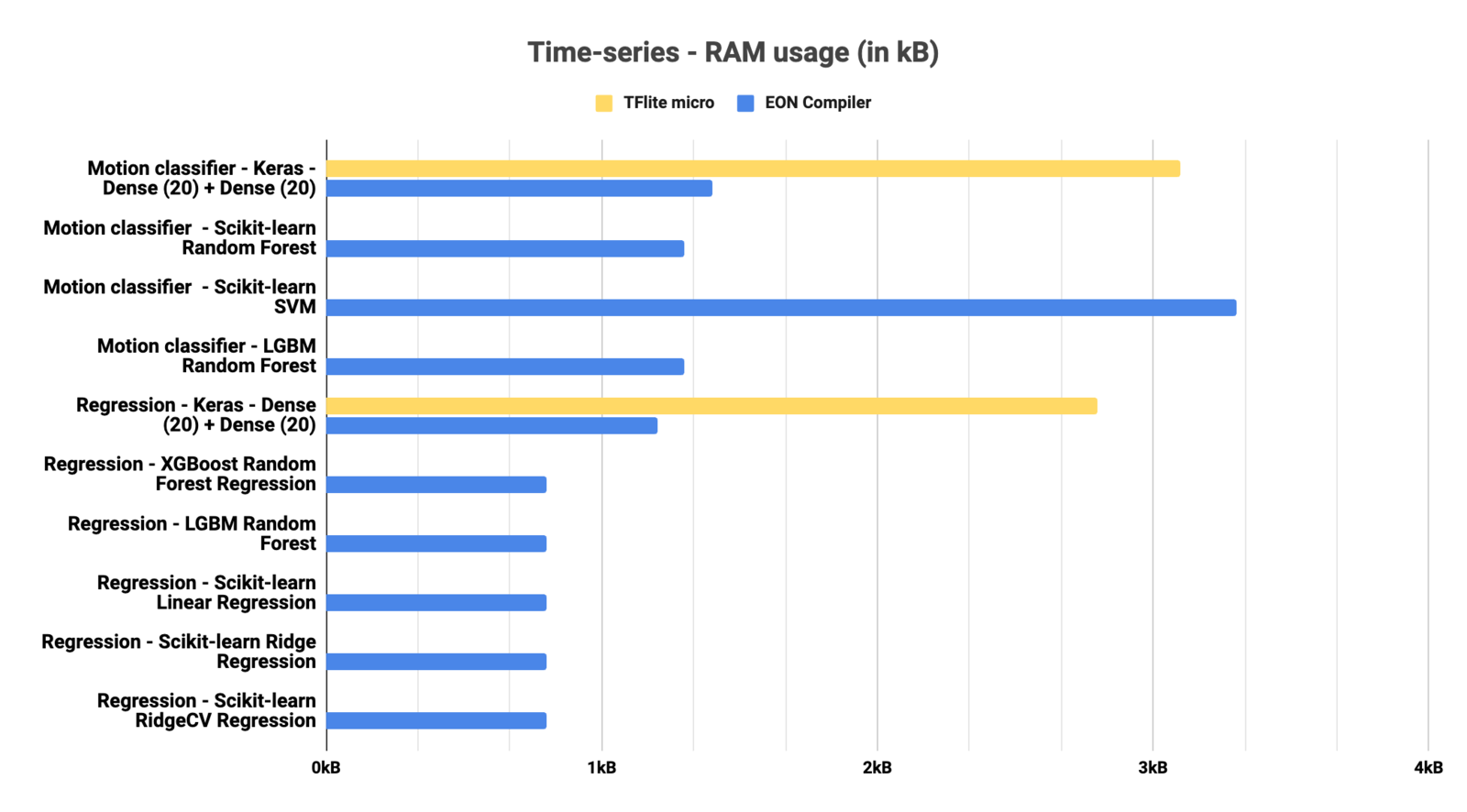
Time series
- RAM
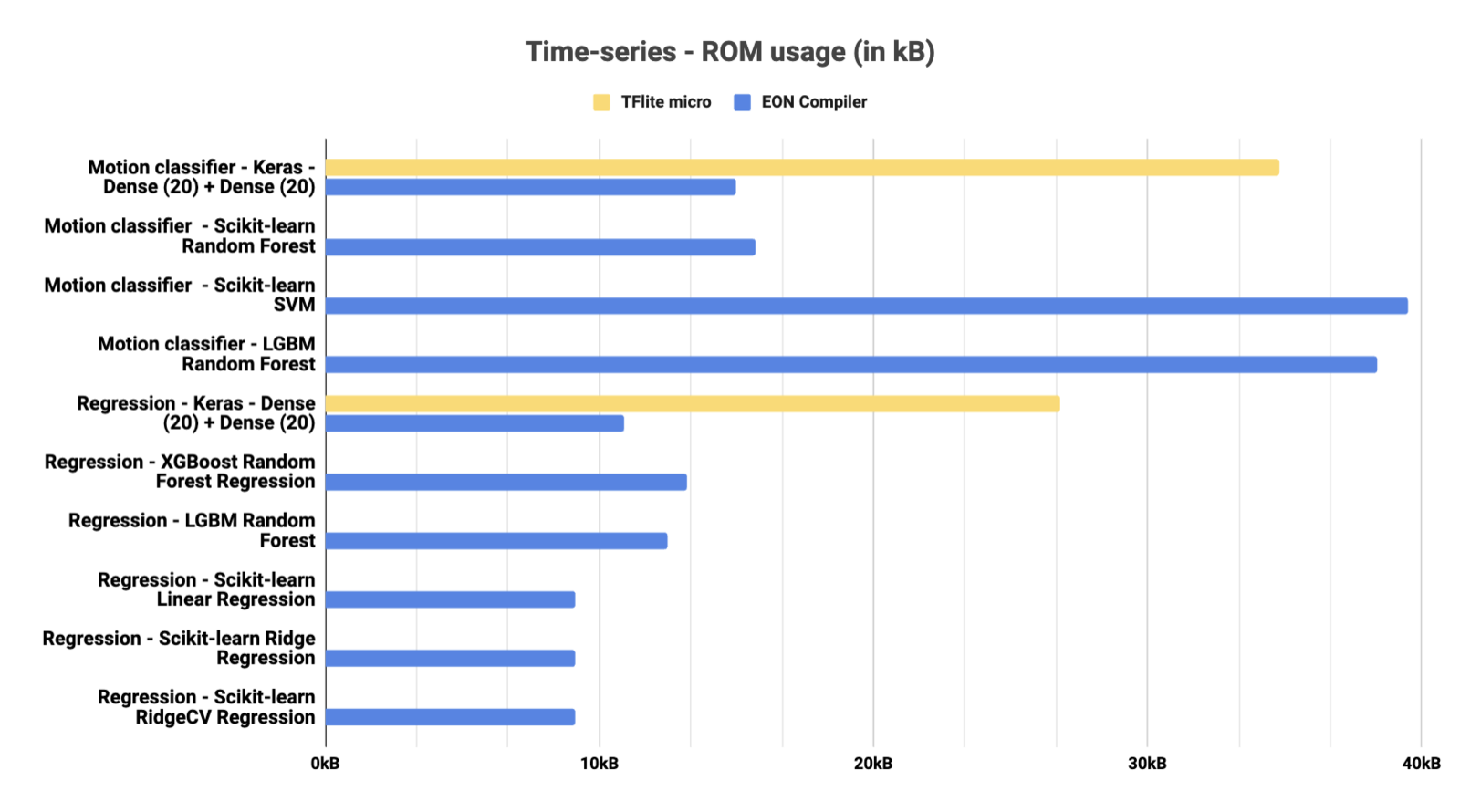
- ROM
RAM usage for time-series architectures
Supported Operators
TensorFlow Lite for Microcontrollers supports a subset of TensorFlow Lite operators. The matrix compares TensorFlow Lite builtin operators, supported op-version ranges, TFLM coverage, and Edge Impulse support. Use the TensorFlow docs links in the table for operator-level descriptions. Open the full-window matrix view: TensorFlow 2.19 operator matrix. Legend- TFLite builtin: Operator exists in the TensorFlow Lite builtin enum.
- TFLM supported: Operator is wired through the TFLM all-ops resolver in this repo.
- TFLM kind: Whether TFLM exposes the op as
builtinorcustom. - Op version: TensorFlow Lite version range for that operator in this source snapshot (for example
v1-v5). TFLM in this repo ignores version during resolver lookup. - EI supported: Operator is wired through the Edge Impulse resolver.
- EI extra: Operator is supported by Edge Impulse but not part of TFLite builtin ops.