Only available on the Enterprise planThis feature is only available on the Enterprise plan. Review our plans and pricing or sign up for our free expert-led trial today.
Block structure
Synthetic data blocks are an extension of transformation blocks operating instandalone mode and, as such, follow the same structure without being able to pass a directory or file directly to your scripts. Please see the custom blocks overview page for more details.
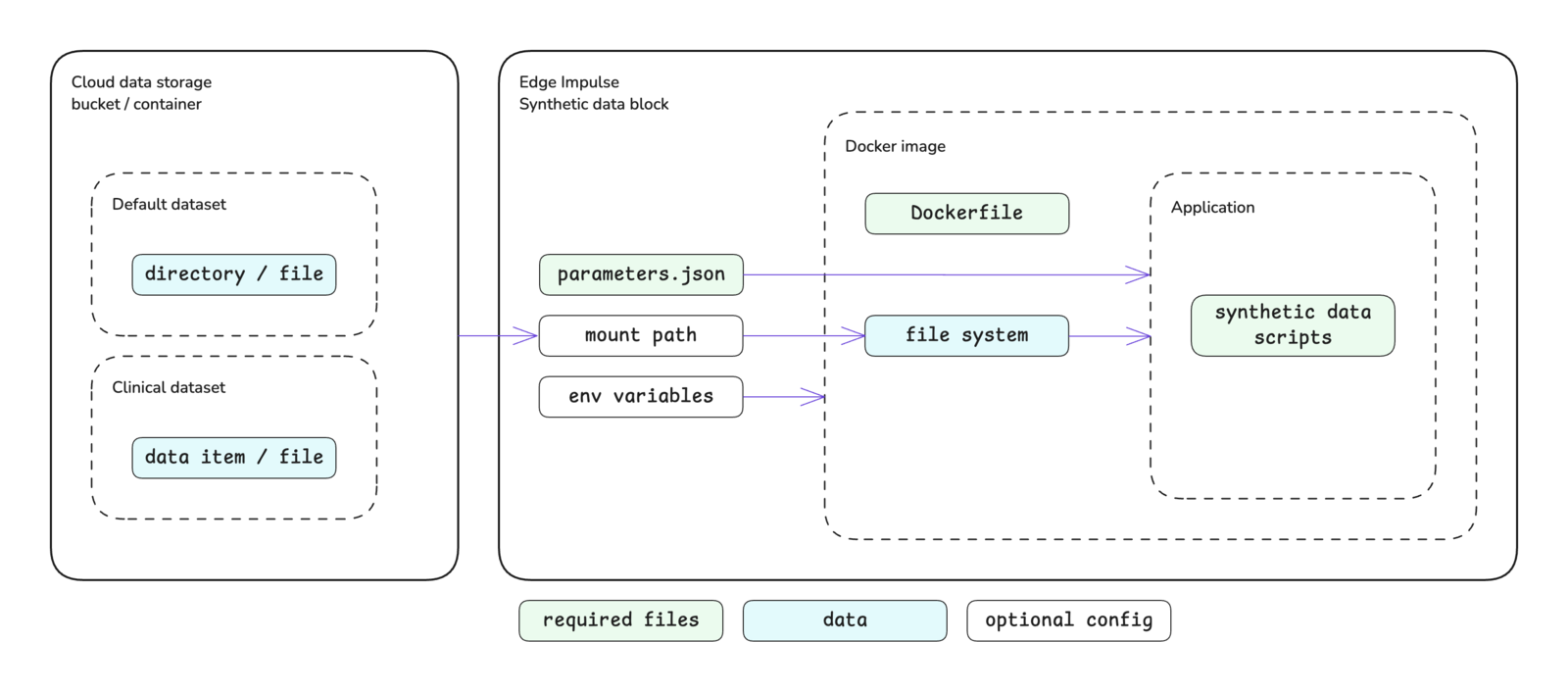
Block interface
The sections below define the required and optional inputs and the expected outputs for custom synthetic data blocks.Inputs
Synthetic data blocks have access to environment variables, command line arguments, and mounted storage buckets.Environment variables
The following environment variables are accessible inside of synthetic data blocks. Environment variable values are always stored as strings.| Variable | Passed | Description |
|---|---|---|
EI_API_ENDPOINT | Always | The API base URL: https://studio.edgeimpulse.com/v1 |
EI_API_KEY | Always | The organization API key with member privileges: ei_2f7f54... |
EI_INGESTION_HOST | Always | The host for the Ingestion API: edgeimpulse.com |
EI_ORGANIZATION_ID | Always | The ID of the organization that the block belongs to: 123456 |
EI_PROJECT_ID | Always | The ID of the project: 123456 |
EI_PROJECT_API_KEY | Always | The project API key: ei_2a1b0e... |
requiredEnvVariables property in the parameters.json file. You will then be prompted for the associated values for these properties when pushing the block to Edge Impulse using the CLI. Alternatively, these values can be added (or changed) by editing the block in Studio.
Command line arguments
The parameter items defined in yourparameters.json file will be passed as command line arguments to the script you defined in your Dockerfile as the ENTRYPOINT for the Docker image. Please refer to the parameters.json documentation for further details about creating this file, parameter options available, and examples.
In addition to the items defined by you, specific arguments will be automatically passed to your synthetic data block.
Synthetic data blocks are an extension of transformation blocks operating in standalone mode, the arguments that are automatically passed to transformation blocks in this mode are also automatically passed to synthetic data blocks. Please refer to the custom transformation blocks documentation for further details on those parameters.
Along with the transformation block arguments, the following synthetic data specific arguments are passed as well.
| Argument | Passed | Description |
|---|---|---|
--synthetic-data-job-id <job-id> | Always | Provides the job ID as an integer. The job ID must be passed as the x-synthetic-data-job-id header value when uploading data to Edge Impulse through the Ingestion API. |
Mounted storage buckets
One or more cloud data storage buckets can be mounted inside of your block. If storage buckets exist in your organization, you will be prompted to mount the bucket(s) when initializing the block with the Edge Impulse CLI. The default mount point will be:Outputs
There are no required outputs from synthetic data blocks. In general, however, the pattern is that the data generated is uploaded to Edge Impulse using the data Ingestion API.Setting the Ingestion API request header
When uploading synthetic data to Edge Impulse using the Ingestion API, you will need to include the thex-synthetic-data-job-id header in your request. The value for this header is the job ID provided to your block through the --synthetic-data-job-id <job-id> argument.
This header is required to show a preview of the generated samples on the Synthetic data tab on the Data acquisition page in Studio when the samples are being created.
An example header is provided below.
Initializing the block
When you are finished developing your block locally, you will want to initialize it. The procedure to initialize your block is described in the custom blocks overview page. Please refer to that documentation for details.Testing the block locally
Synthetic data blocks are not currently supported by the blocks runner in the Edge Impulse CLI. To test you custom synthetic data block, you will need to build the Docker image and run the container directly. You will need to pass any environment variables or command line arguments required by your script to the container when you run it.Pushing the block to Edge Impulse
When you have initialized and finished testing your block locally, you will want to push it to Edge Impulse. The procedure to push your block to Edge Impulse is described in the custom blocks overview page. Please refer to that documentation for details.Using the block in a project
After you have pushed your block to Edge Impulse, it can be used in the same way as any other built-in block.Examples
Edge Impulse has developed several synthetic data blocks, some of which are built into the platform. The code for these blocks can be found in public repositories under the Edge Impulse GitHub account. The repository names typically follow the convention ofexample-transform-<description>. As such, they can be found by going to the Edge Impulse account and searching the repositories for example-transform.
Note that when using the above search term you will come across transformation blocks as well. Please read the repository description to identify if it is for a synthetic data block or a transformation block.
Below are direct links to a some examples:
Troubleshooting
No common issues have been identified thus far. If you encounter an issue, please reach out on the forum or, if you are on the Enterprise plan, through your support channels.