DevOps
DevOps is the collaboration between software development teams and IT operations to formalize and automate various parts of both cycles in order to deliver and maintain software.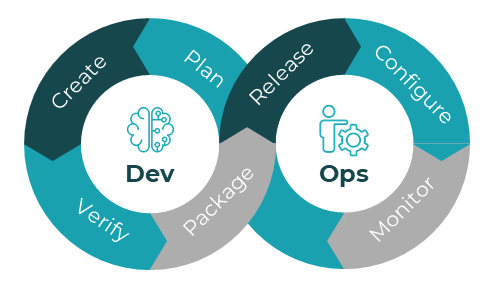
DevOps cycle
MLOps
Machine learning operations extends the DevOps cycle by adding the design and development of ML models into the mix.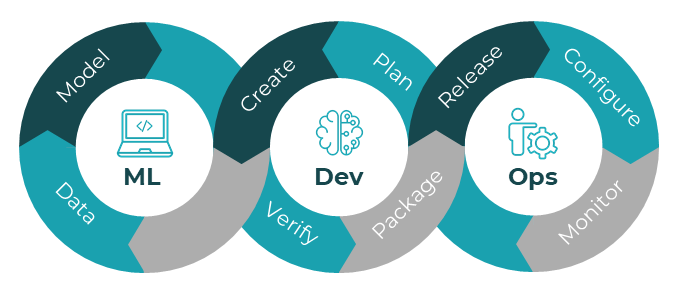
MLOps cycle
- Shorter development cycles and time to market
- Increased reliability, performance, scalability, and security
- Standardized and automated model development/deployment frees up time for developers to tackle new problems
- Streamlined operations and maintenance (O&M) for efficient model deployment
Team effort
In most cases, implementing an edge MLOPs framework is not the work of a single person. It involves the cooperation of several teams. These teams can include some of the following experts:- Data scientists - analyze raw data to find patterns and trends, create algorithms and data models to predict outcomes (which can include machine learning)
- Data engineers - build systems to collect, manage, and transform raw data into useful information for data scientists, ML researchers/engineers, and business analysts
- ML researchers - similar to data scientists, they work with data and build mathematical models to meet various business or academic needs
- ML engineers - build systems to train, test, and deploy ML models in a repeatable and robust manner
- Software developers - create computer applications and underlying systems to perform specific tasks for users
- Operations specialists - oversee the daily operation of network equipment and software maintenance
- Business analysts - form business insights and market opportunities by analyzing data
Edge AI lifecycle
The edge AI lifecycle consists of the steps required to collect data, clean that data, extract required features, train one or more ML models, test the model, deploy the model, and perform necessary maintenance. Note that these steps do not include some of the larger project processes of identifying business needs and creating the application around the model.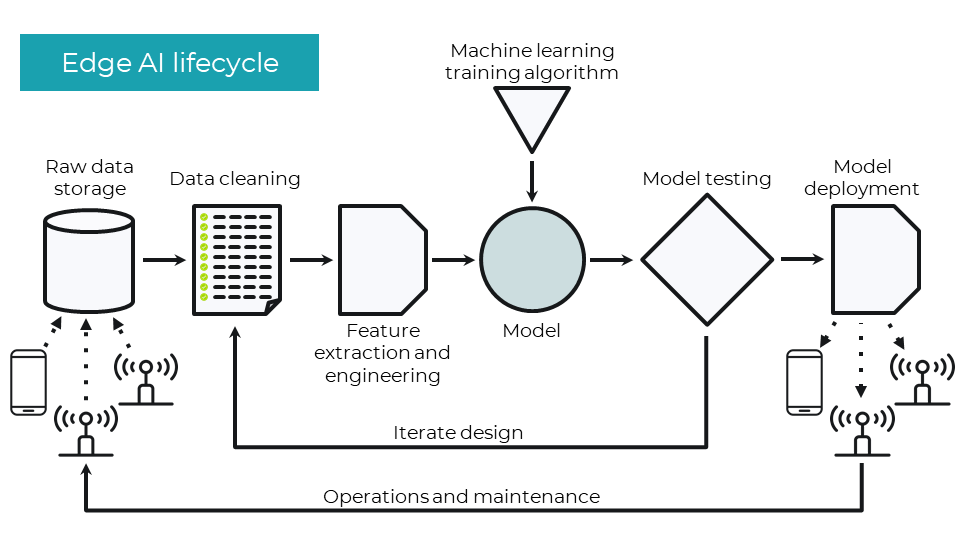
Edge AI lifecycle
Principles
Edge MLOps is built on three main principles: version control, automation, and governance.Version control
In software development, the ability to track code versions and roll back versions is incredibly important. It goes beyond simply “saving a copy,” as it allows you to create branches to try new features and merge code from other developers. Tools like git and GitHub provide robust version control capabilities. While these tools can be used for files and data beyond just code, they are mostly focused on text-based code. Versioning data can be tricky, as the storage requirements increases with the amount of data. You likely also want to version various ML pipelines in addition to the training/testing code and model itself. Edge Impulse offers the ability to version control individual blocks as well as your entire project and pipeline.Automation
Automating anything requires an initial, up-front investment to build the required processes and software. In cases where you need to use that process multiple times, such automation can pay off in the long run. Setting up automated tasks is a crucial step in edge MLOps, as it allows your teams to work on other tasks once the automation is built. Almost anything in the edge AI lifecycle can be automated, including data collection, data cleaning, model training, and deployment. These often fall into one of the following categories:- Continuous collection - Data collection happens continuously or triggered by some event.
- Continuous training - Feature extraction and model training/testing can occur autonomously.
- Continuous integration - Any code changes checked into a repository can trigger a series of unit and system tests to ensure correct operation before the code is merged into the main application.
- Continuous delivery - Software is created in short cycles and can be reliably released to users on a continuous basis as needed. Some deployment steps in this stage can be automated.
- Continuous monitoring - Automated tools are used to monitor the performance and security of an application or system to detect problems early to mitigate risks.
- User-requested - the user makes a request to update or rebaseline the model
- Time - one or more steps in the lifecycle can be executed on a set schedule, such as once per day or once per month
- Data changes - the presence of newly collected data can trigger a new lifecycle execution to clean the data, train a model, and deploy the model
- Code change - a new version of the application might necessitate a new model and thus trigger any of the collection, cleaning, training, testing, or deployment processes
- Model monitoring - issues with deployed models (such as model drift) might require any or all of the lifecycle to execute in order to update the model
Governance
Part of edge MLOps includes ensuring that your data and processes adhere to best practices and complies with any necessary regulations. Such regulations might include data privacy laws, such as HIPAA and GDPR. Similar rules are currently being enacted around AI, such as the EU AI act. Be sure to become familiar with any potential governing regulations around data, privacy, and AI! The rules can vary by country and specific technology usage (e.g. medical vs. consumer electronics). In addition to adhering to laws, you should check for fairness and bias in your data and model. Bias can come in many different forms and greatly impact your resulting model. The popular computer science phrase garbage in, garbage out applies here: if you train a model on biased data, the model will reflect that bias. Finally, like with any computer system, you should design and implement best security practices to ensure:- Confidentiality to protect sensitive data from unauthorized access
- Integrity to guarantee that data has not been altered
- Availability of data to authorized users when needed
Model drift
Model drift occurs when an ML model’s loses accuracy over time. This can happen over the course of days or years.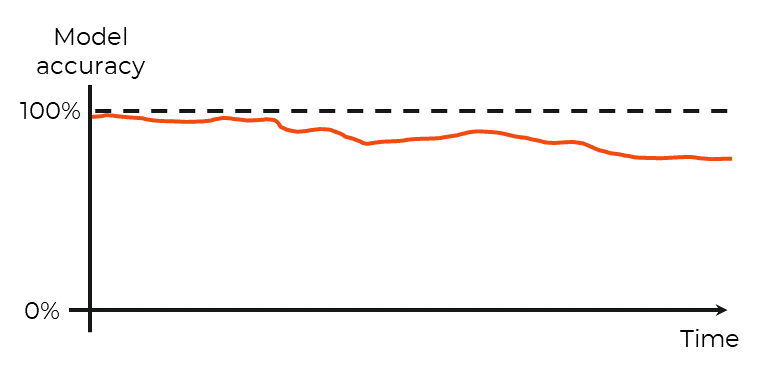
Machine learning model drift
- Data drift occurs when the incoming data skews from the original training/test datasets. For example, the operating environment may change (e.g. collecting data on a machine in winter and expecting inference to work the same during the summer).
- Concept drift happens when the relationship between the input data and target changes. For example, spammers discover a new tactic to outwit spam filters. The spam filters are still accurate, but only on older methods.