Edge machine learning (edge ML) is the process of running machine learning algorithms on computing devices at the periphery of a network to make decisions and predictions as close as possible to the originating source of data. It is also referred to as edge artificial intelligence or edge AI.
In traditional machine learning, we often find large servers processing heaps of data collected from the Internet to provide some benefit, such as predicting what movie to watch next or to label a cat video automatically. By running machine learning algorithms on edge devices like laptops, smartphones, and embedded systems (such as those found in smartwatches, washing machines, cars, manufacturing robots, etc.), we can produce such predictions faster and without the need to transmit large amounts of raw data across a network.
To accurately describe edge ML, we first need to understand the history of artificial intelligence (AI).
Check out our Edge AI Fundamentals course to learn more about edge computing, the difference between AI and machine learning, and edge MLOps.
Artificial intelligence vs. machine learning
The name “artificial intelligence” originates from a proposal in 1956 by John McCarty, Marvin Minsky, Nathaniel Rochester, and Claude Shannon to host a summer research conference exploring the possibility of programming computers to “simulate many of the higher functions of the human brain.”
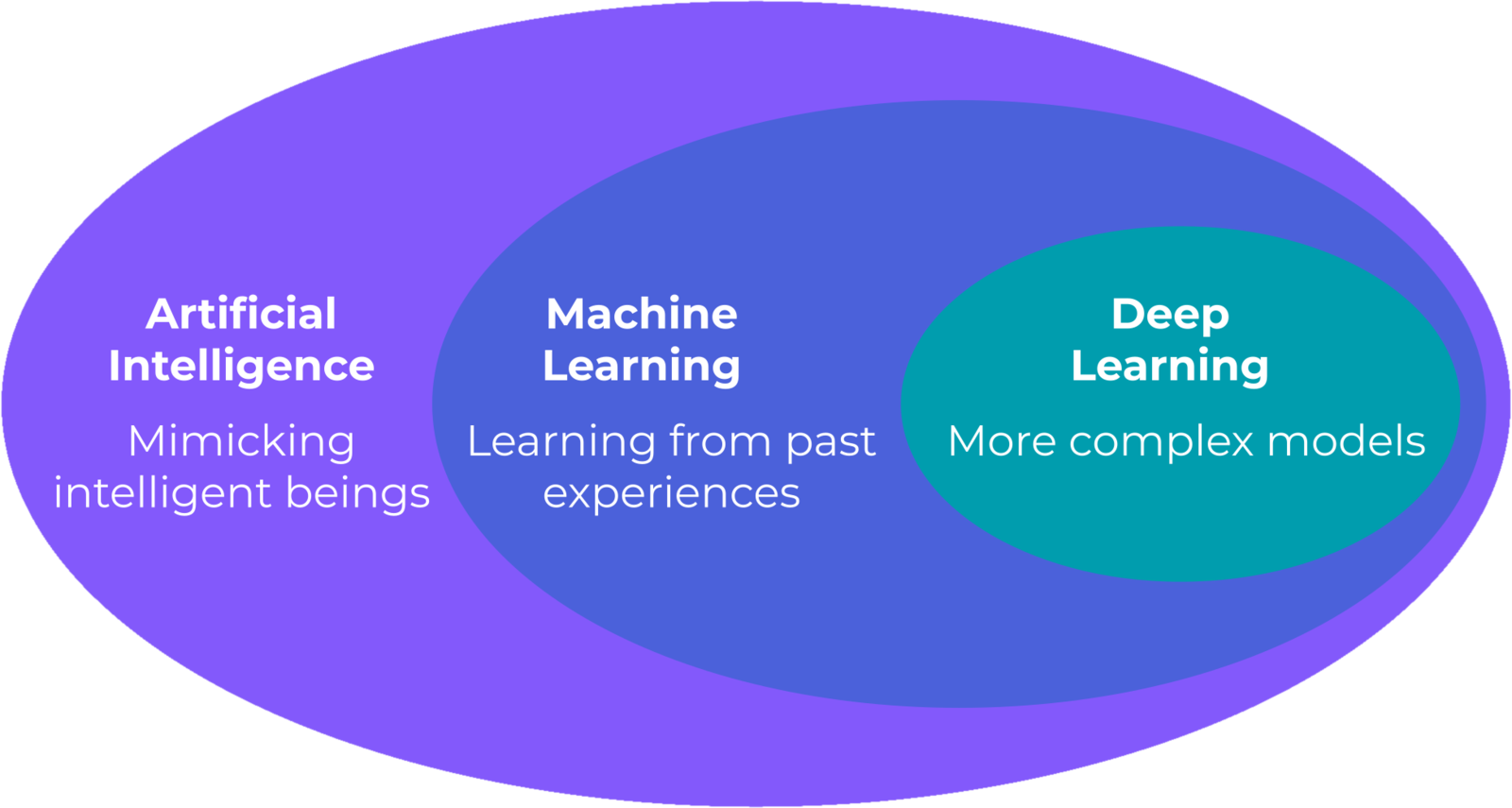
Many years later, McCarthy would define AI as “the science and engineering of making intelligent machines, especially intelligent computer programs,” where the definition of intelligence is “the computational part of the ability to achieve goals in the world.” From this definition, we see that AI is an extremely broad field of study involving the use of computers to make decisions to achieve arbitrary goals.
AI researcher Arthur Samuel trained a computer to play checkers better than most humans by having the program play thousands of games against itself and learning from each iteration. He coined the term “machine learning” in his 1959 paper to mean any program that can learn from experience.
The term “deep learning” (DL) comes from a 1986 paper by the mathematician and computer scientist Rina Dechter. She used the term to describe ML models that can be trained to automatically learn features or representations. We often use the term deep learning to describe artificial neural networks with more than a few layers, but it can be used more broadly to refer to other forms of machine learning.
From these definitions, we can view deep learning as a subset of machine learning, which is a subset of artificial intelligence. As a result, all DL algorithms can be considered ML and AI. However, not all AI is ML.
Since the early days of AI, advances in algorithms, software, and hardware have allowed us to begin using machine learning in helpful and unique ways.
Modern machine learning
In the early 2010s, the Google Brain team worked to make deep learning more accessible, which resulted in the creation of the popular TensorFlow framework. The team made headlines in 2012 when they created a model that could accurately classify an image as “cat or not cat.”
Since then, AI has soared in popularity, mostly due to the research and development of complex deep neural networks. Powerful graphics cards and server clusters could be employed to speed up the training and inference processes required for deep learning.
These powerful algorithms are used everyday to perform a variety of helpful tasks, such as:
- Image and video labeling
- Speech recognition and synthesis
- Language translation
- Product and content recommendations
- Email spam filtering
- Credit card fraud detection
- Market and customer segmentation
- Stock market trading
To train these complex machine learning models, we need enormous amounts of data. Thanks to the Internet, that data can be readily obtained by sharing pre-made datasets or through actively collecting information in real time (e.g. usage statistics of a website). If we want to collect data from the world around us, we need to rely on sensors.
The Internet of Things
The Internet of Things (IoT) is the collection of sensors, hardware devices, and software that exchange information with other devices and computers across communication networks. We often think of IoT as a series of sensors with WiFi or Bluetooth connectivity that can relay to us information about the environment.
In 1982, a few graduate students in the computer science department at Carnegie-Mellon connected a Coca-Cola vending machine to the Internet for fun. The machine would display its temperature and various soda stock in real time to a web page. This project is the first known instance of IoT.
For many years, IoT was known as “machine to machine” (M2M). It involved connecting sensors and automating control processes between various computing devices, and it saw wide adoption in industrial machines and processes.
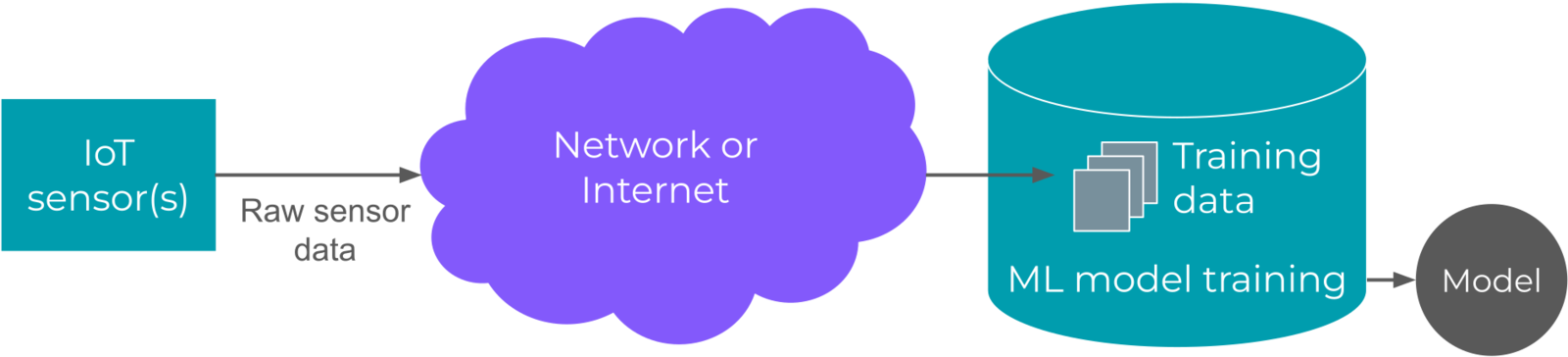
Machine learning offers the ability to create further advancements in automation by introducing models that can make predictions or decisions without human intervention. Due to the complex nature of many machine learning algorithms, the traditional integration of IoT and ML involves sending raw sensor data to a central server, which performs the necessary inference calculations to generate a prediction.
For low volumes of raw data and complex models, this configuration may be acceptable. However, there are several potential issues that arise:
- Transmitting large sensor data, such as images, may hog network bandwidth
- Transmitting data also requires power
- The sensors require constant connection to the server to provide near real time ML computations
To counter the need to transmit large amounts of raw data across networks, data storage and some computations can be accomplished on devices closer to the user or sensor, known as the “edge.” Qualcomm’s Karim Arabi, in his 2014 IEEE DAC keynote and 2015 MIT MTL Seminar, defined edge computing as all computing happening outside of the cloud. Edge computing stands in contrast to cloud computing, where remote data and services are available on demand to users.
Edge computing includes personal computers and smartphones in addition to embedded systems (such as those that comprise the Internet of things). To make all of these devices smarter and less reliant on backend servers, we turn to edge machine learning.
Edge and embedded machine learning
Advances in hardware and machine learning have paved the way for running deep ML models efficiently on edge devices. Complex tasks, such as object detection, natural language processing, and model training, still require powerful computers. In these cases, raw data is often collected and sent to a server for processing.
However, performing ML on low-power devices offers a variety of benefits:
- Less network bandwidth is spent on transmitting raw data
- While some information may need to be transmitted over a network (e.g. inference results), less communication often means reduced power usage
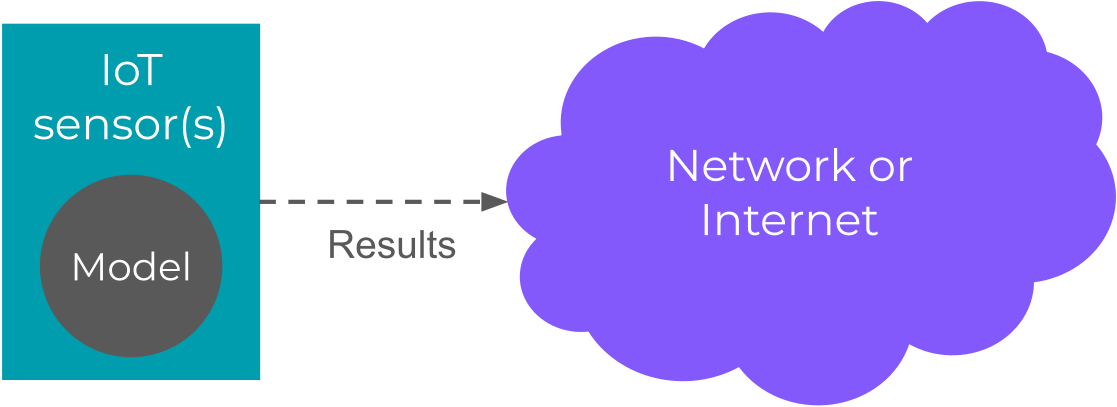
- Prediction results are available immediately without the need to send them across a network
- Inference can be performed without a connection to a network
- User privacy is ensured, as data is only stored long enough to perform inference (not including data collected for model training)
Edge ML includes personal computers, smartphones, and embedded systems. As a result, embedded ML, also known as tinyML, is a subset of edge ML that focuses on running machine learning algorithms on embedded systems, such as microcontrollers and headless single board computers.
In most cases, training a machine learning model is more computational intensive than performing inference.
Model: the mathematical formula that attempts to generalize information from a given set of data.Training: the process of automatically updating the parameters in a model from data. The model “learns” to draw conclusions and make generalizations about the data.Inference: the process of providing new, unseen data to a trained model to make a prediction, decision, or classification about the new data.
Edge ML use cases
The ability to run machine learning on edge devices without the need to maintain a connection to a more powerful computer allows for a variety of automation tools and smarter IoT systems. Here are a few examples where edge ML is enabling innovation in various industries.
Agriculture
Smart buildings
- Smart HVAC systems that can adapt to the number of people in a room
- Security sensors that listen for the unique sound signature of glass breaking
Environment conservation
Health and fitness
Human-computer interaction (HCI)
- Keyword spotting and wake word detection to control household appliances
- Gesture control as assistive technology
Industry
- Safety systems that automatically detect the presence of hard hats
- Predictive maintenance that identities faults in machinery before larger problems arise
The computational power required to perform machine learning at the edge is generally much higher than simply needing to poll a sensor and transmit raw data. However, performing such calculations locally often requires less electrical power than transmitting the raw data to a remote server.
The following chart offers some insights into the types of hardware required to perform machine learning inference at the edge depending on the desired application.
Edge ML is enabling technologies in new areas and allowing for novel solutions to problems. Some of these applications will be visible to consumers (such as keyword spotting on smart speakers) while others will be transforming our lives in invisible ways (such as smart grids delivering power more efficiently).
Learn more
Edge Impulse is the leading development platform for machine learning on edge devices. One of the fastest ways to try Edge Impulse is to follow this guided tour of creating your own keyword spotting model in 5 minutes or our computer vision walkthrough. No programming experience is required!