TutorialsWant to see FOMO in action? Check out our Detect objects with centroids (FOMO) tutorial.
And here’s FOMO doing 30 fps object detection on an Arduino Nicla Vision (Cortex-M7 MCU), using 245K RAM.
You can find the complete Edge Impulse project with the beers vs. cans model, including all data and configuration here: https://studio.edgeimpulse.com/public/89078/latest.
How does this 🪄 work?
So how does that work? First, a small primer. Let’s say you want to detect whether you see a face in front of your sensor. You can approach this in two ways. You can train a simple binary classifier, which says either “face” or “no face”, or you can train a complex object detection model which tells you “I see a face at this x, y point and of this size”. Object detection is thus great when you need to know the exact location of something, or if you want to count multiple things (the simple classifier cannot do that) - but it’s computationally much more intensive, and you typically need much more data for it.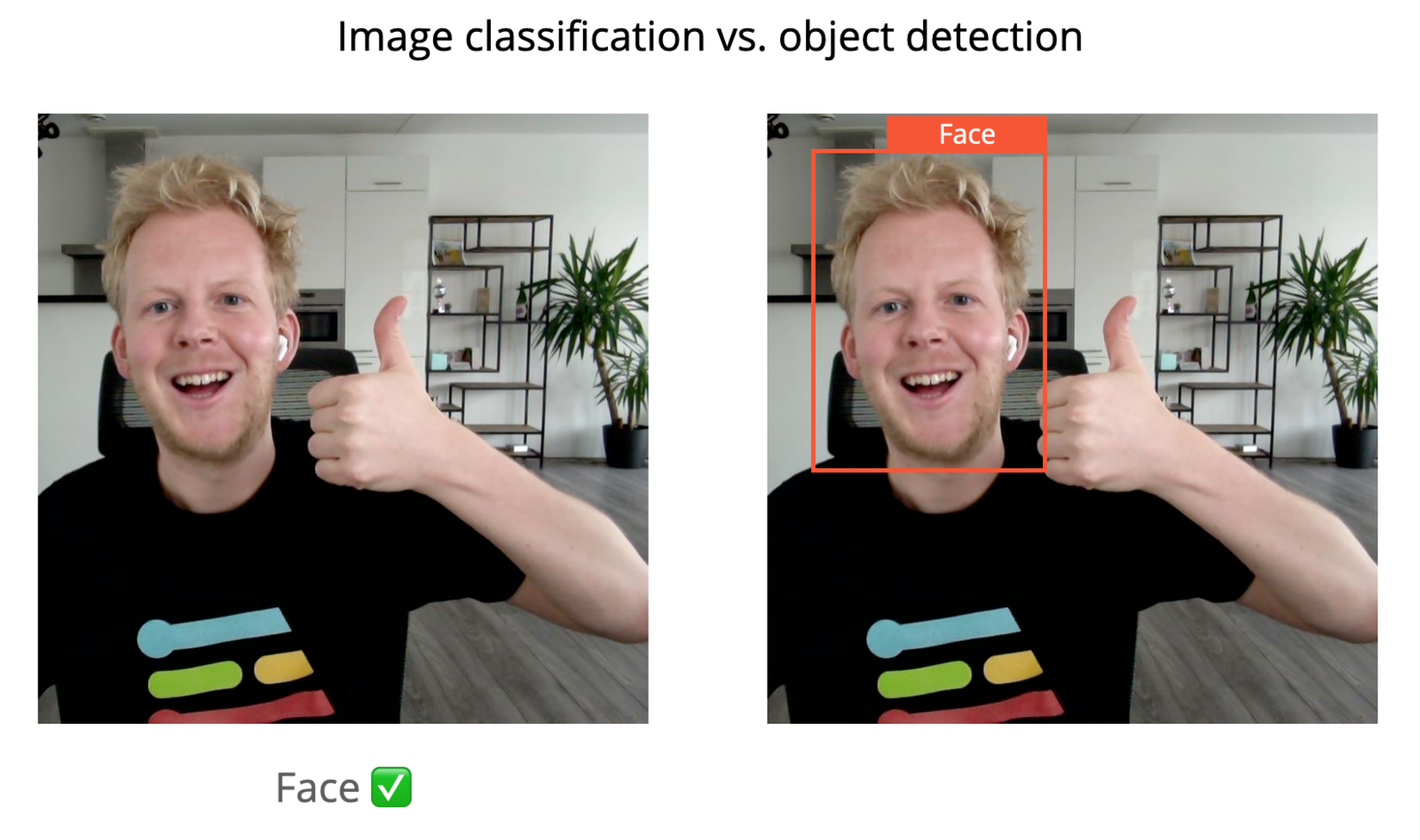
Heat maps
The first thing to realize is that while the output of the image classifier is “face” / “no face” (and thus no locality is preserved in the outcome) the underlying neural network architecture consists of a number of convolutional layers. A way to think about these layers is that every layer creates a diffused lower-resolution image of the previous layer. E.g. if you have a 16x16 image the width/height of the layers may be:- 16x16
- 4x4
- 1x1


Training on centroids
A difference between FOMO and other object detection algorithms is that it does not output bounding boxes, but it’s easy to go from heat map to bounding boxes. Just draw a box around a highlighted area.
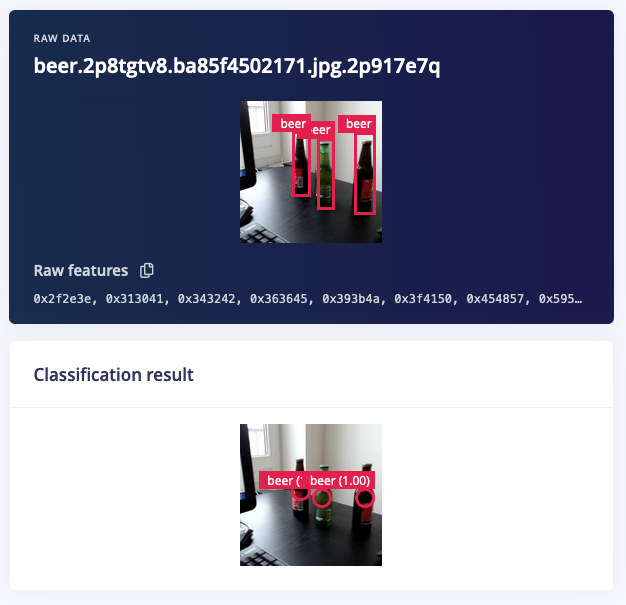
Flexible and very, very fast
A key benefit of FOMO is that it’s fully convolutional. If you set an image:heat map factor of 8 you can throw in a 96x96 image (outputs 12x12 heat map), a 320x320 image (outputs 40x40 heat map), or even a 1024x1024 image (outputs 128x128 heat map). This makes FOMO flexible, and useful even if you have very large images that need to be analyzed (e.g. in fault detection where the faults might be very, very small). You can even train on smaller patches, and then scale up during inference. Additionally FOMO is compatible with any MobileNetV2 model. Depending on where the model needs to run you can pick a model with a higher or lower alpha, and transfer learning also works (although you need to train your base models specifically with FOMO in mind). This makes it easy for end customers to use their existing models and fine-tune them with FOMO to also add locality (e.g. we have customers with large transfer learning models for wildlife detection). Together this gives FOMO the capabilities to scale from the smallest microcontrollers all the way to full gateways or GPUs. Just some numbers:- The video on the top classifies 60 times / second on a stock Raspberry Pi 4 (160x160 grayscale input, MobileNetV2 0.1 alpha). This is 20x faster than MobileNet SSD which does ~3 frames/second.
- The second video on the top classifies 30 times / second on an Arduino Nicla Vision board with a Cortex-M7 MCU running at 480MHz) in ~240K of RAM (96x96 grayscale input, MobileNetV2 0.35 alpha).
- During Edge Impulse Imagine we demonstrated a FOMO model running on a Himax WE-I Plus doing 14 frames per second on a DSP (video). This model ran in under 150KB of RAM (96x96 grayscale input, MobileNetV2 0.1 alpha). [1]
- The smallest version of FOMO (96x96 grayscale input, MobileNetV2 0.1 alpha) runs under 100KB RAM and ~10 fps. on a Cortex-M4F at 80MHz. [1]
How to get started?
To build your first FOMO models:- Create a new project in Edge Impulse.
- Make sure to set your labeling method to ‘Bounding boxes (object detection)’.
- Collect and prepare your dataset as in object detection.
- Add an ‘Object Detection (Images)’ block to your impulse.
- Under Images, select ‘Grayscale’
- Under Object detection, select ‘Choose a different model’ and select one of the FOMO models.
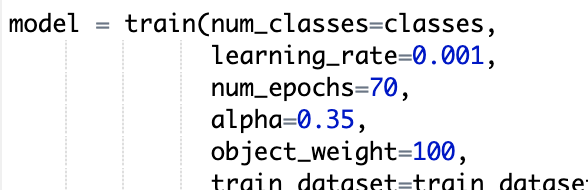
- Make sure to lower the learning rate to 0.001 to start.
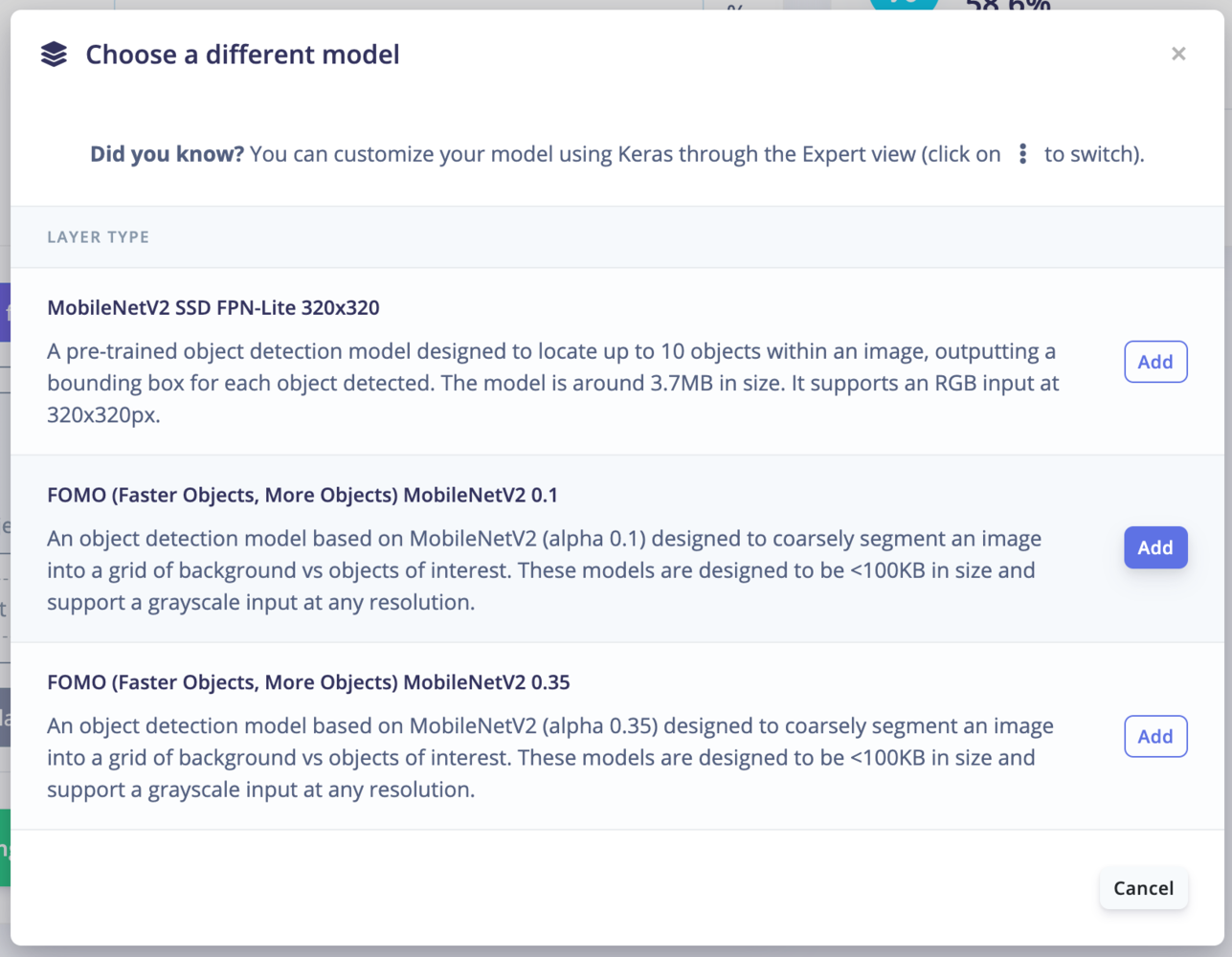
Expert mode tips
Additional configuration for FOMO can be accessed via expert mode.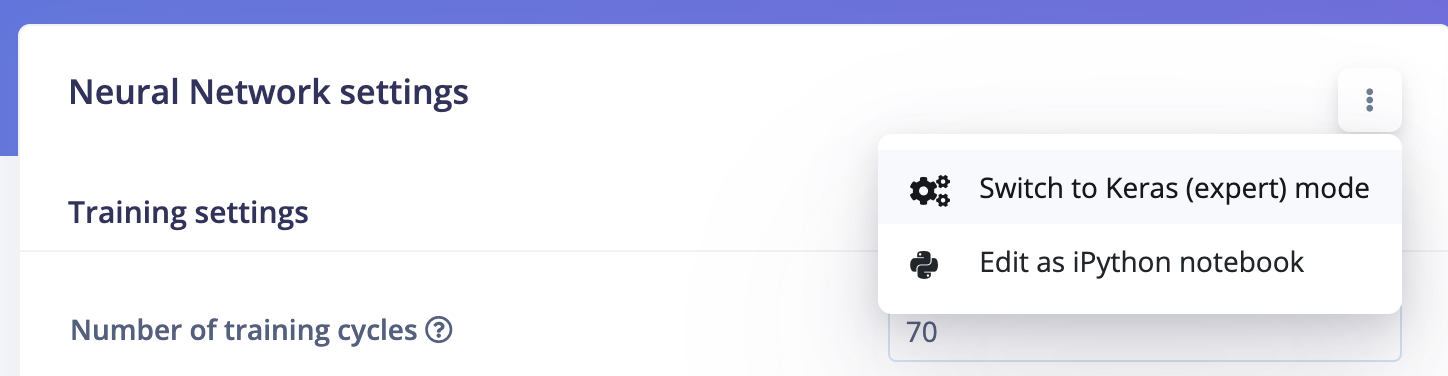
Object weighting
FOMO is sensitive to the ratio of objects to background cells in the labelled data. By default the configuration is to weight object output cells x100 in the loss function,object_weight=100, as a way of balancing what is usually a majority of background. This value was chosen as a sweet spot for a number of example use cases. In scenarios where the objects to detect are relatively rare this value can be increased, e.g. to 1000, to have the model focus even more on object detection (at the expense of potentially more false detections).
MobileNet cut point
FOMO uses MobileNetV2 as a base model for its trunk and by default does a spatial reduction of 1/8th from input to output (e.g. a96x96 input results in a 12x12 output). This is implemented by cutting MobileNet off at the intermediate layer block_6_expand_relu

cut_point results in a different spatial reduction; e.g. if we cut higher at block_3_expand_relu FOMO will instead only do a spatial reduction of 1/4 (i.e. a 96x96 input results in a 24x24output)
Note though; this means taking much less of the MobileNet backbone and results in a model with only 1/2 the params. Switching to a higher alpha may counteract this parameter reduction. Later FOMO releases will counter this parameter reduction with a UNet style architecture.
FOMO classifier capacity
FOMO can be thought of logically as the first section of MobileNetV2 followed by a standard classifier where the classifier is applied in a fully convolutional fashion. In the default configuration this FOMO classifier is equivalent to a single dense layer with 32 nodes followed by a classifier withnum_classes outputs.
.png?fit=max&auto=format&n=x9Ga-7v4NxdQ7jXX&q=85&s=8c956cc4ab7cc90e2bc251261d6563ca)
Conv2D layer, 2) adding additional layers or 3) doing both.
For example we might change the number of filters from 32 to 16, as well as adding another convolutional layer, as follows.

Performance and Minimum Requirements
Just like the rest of our Neural Network-based learning blocks, FOMO is delivered as a set of basic math routines free of runtime dependencies. This means that the hardware requirements for running FOMO are minimal, limited only to:- Making sure the model itself can fit into the target’s memory (flash/RAM), and
- making sure the target also has enough memory to hold the image buffer (flash/RAM)in addition to your application logic
| Requirement | Minimum | Recommended |
|---|---|---|
| Memory Footprint (RAM) | 256 KB 64x64 pixels (B&W, buffer included) | ≥ 512 KB 96x96 pixels (B&W, buffer Included) |
| Latency (100% load) | 80 MHz < 1 fps | > 80 MHz + acceleration ~15 fps @ 480MHz 40-60fps in RPi4 |