- Audio MFE
- Audio MFCC
- Audio Syntiant
- EEG
- Flatten
- HR/HRV features
- Image
- IMU Syntiant
- Raw Data
- Spectral features
- Spectrogram
Custom processing blocks
If you have a very specific sensor, want to apply custom filters, or are implementing the latest research in digital signal processing, follow our tutorial on Building custom processing blocks.Feature importance
In most of our DSP blocks, you have the option to calculate the feature importance. Edge Impulse Studio will then output a Feature Importance list that will help you determine which axes generated from your DSP block are most significant to analyze when you want to train a model.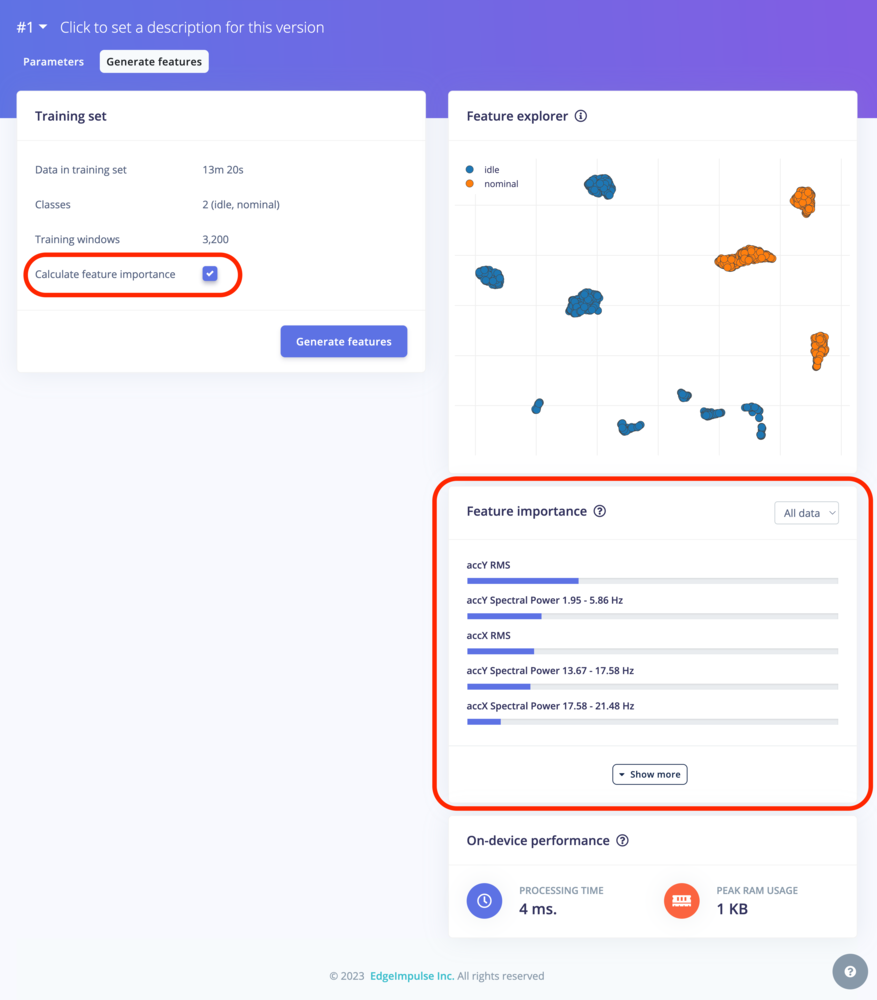
Features importance
feature_importances_ are extracted from the trained classifier.
Data normalization
In some cases, you may want to normalize your data before training a model. This is especially useful when your data has different scales or units, as it can help improve the performance of your model. Normalize features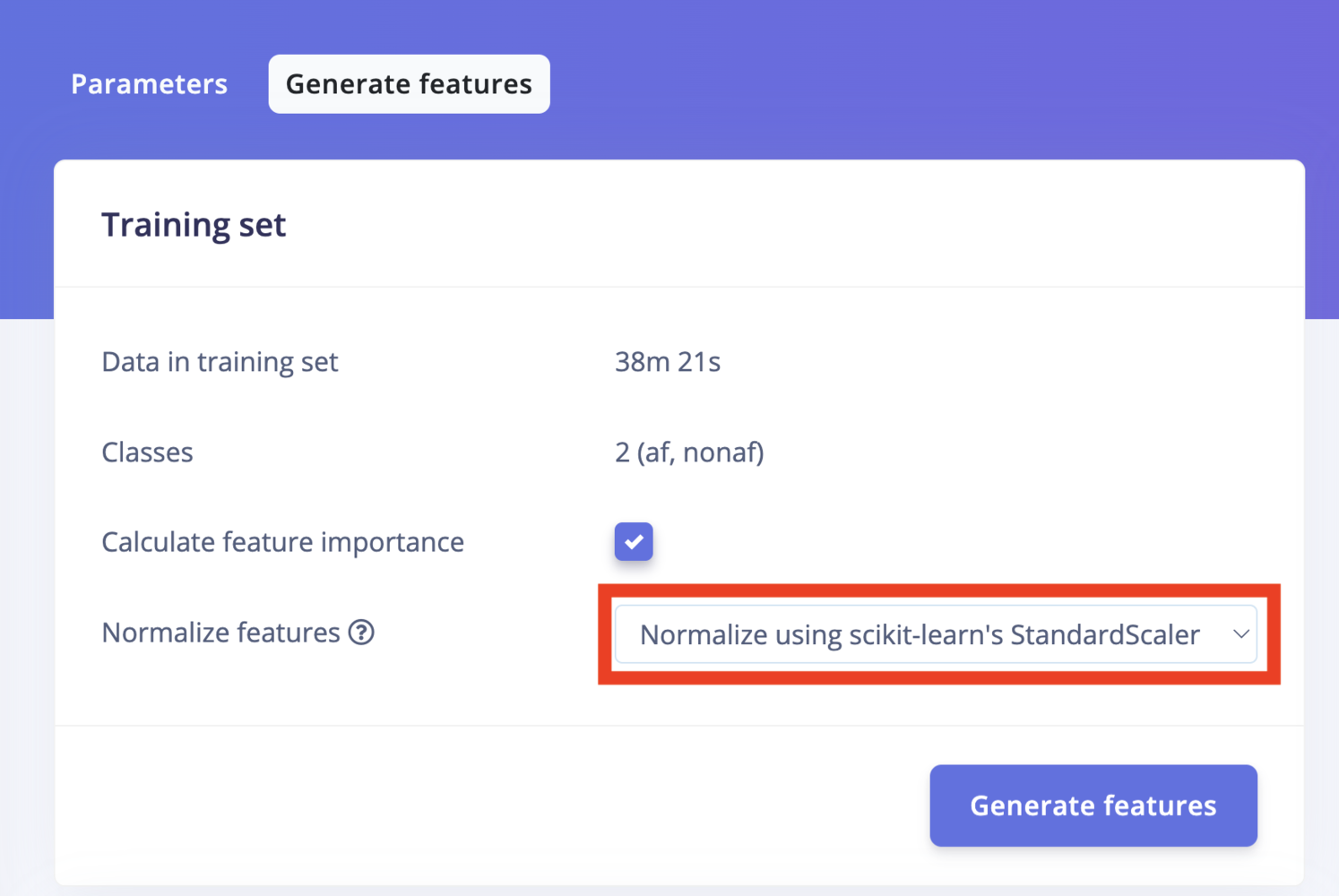
Normalize features
Why normalize?
Machine-learning algorithms assume every input dimension has a comparable numeric range. Large differences (e.g., temperature ∈ [–10, 40] vs. vibration RMS ∈ [0, 2 000]) make the optimiser search in a distorted space, slowing training and sometimes letting one feature dominate the loss. Many Edge Impulse DSP blocks already emit values with bounded ranges (e.g., image pixels are auto-normalised to 0–1 ), but generic numeric or multi-sensor pipelines typically are not. With the Normalize features option we can ensure that all features are on a similar scale, which can lead to better model performance.- Before normalization 94.6%
- After normalization 99.1%
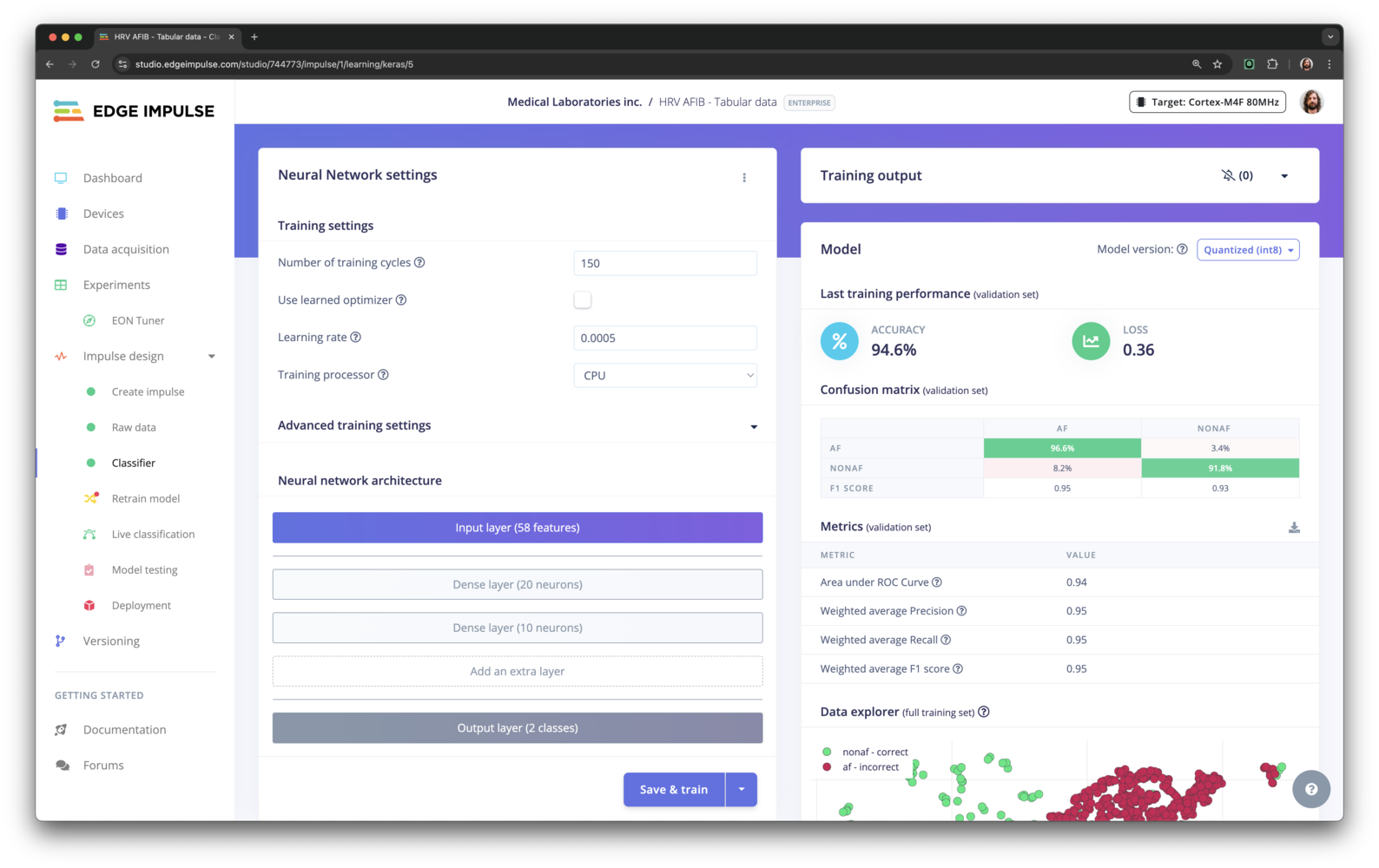
Training run without scaling