Identify need and scope
Before starting a machine learning project, it is imperative that you examine the actual need for such a project: what problem are you trying to solve? For example, you could improve user experience, such as creating a more accurate fall detection or voice-activated smart speaker. You might want to monitor machinery to identify anomalies before problems become unmanageable, which could save you time and money in the long run. Alternatively, you could count people in a retail store to identify peak times and shopping trends. Once you have identified your requirements, you can begin scoping your project:- Can the project be solved through traditional, rules-based methods, or is AI needed to solve the problem?
- Is cloud AI or edge AI the better approach?
- What kind of hardware is the best fit for the problem?
Machine learning pipeline
Most ML projects follow a similar flow when it comes to collecting data, examining that data, training an ML model, and deploying that model.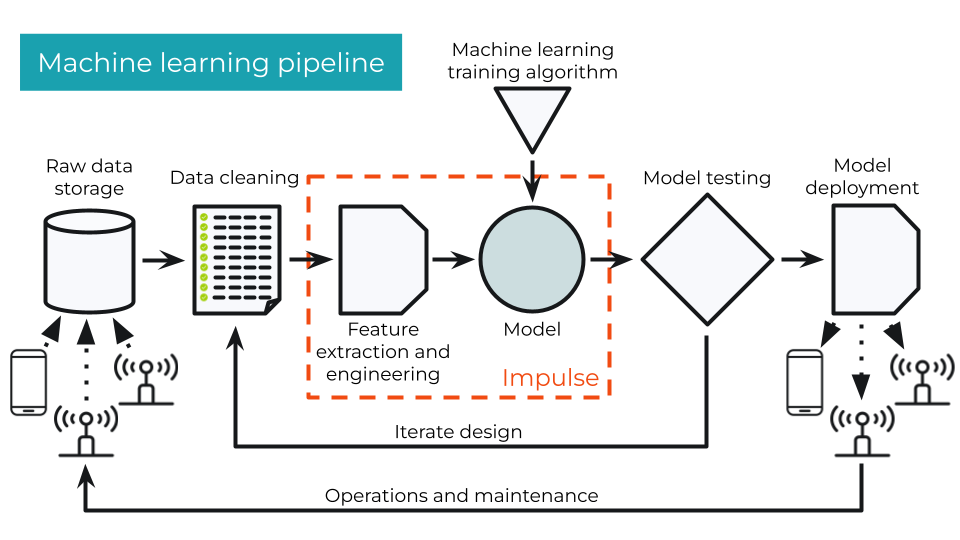
Data collection
To start the process, you need to collect raw data. For most deep learning models, you need a lot of data (think thousands or tens of thousands of samples). In many cases, data collection involves deploying sensors to the field or your target environment and let them collect raw data. You might collect audio data with a smartphone or vibration data using an IoT sensor. You can create custom software that automatically transmits the data to a data lake or store it directly to an Edge Impulse project. Alternatively, you can store data directly to the device, such as on an SD card, that you later upload to your data storage. Examples of data can include raw time-series data in a CSV file, audio saved as a WAV file, or images in JPEG format. Note that sensors can vary. As a result, it’s usually a good idea to collect data using the same device and/or sensors that you plan to ultimately deploy to. For example, if you plan to deploy your ML model to a smartphone, you likely want to collect data using smartphones.Data cleaning
Raw data often contains errors in the forms of omissions (some fields missing), corrupted samples, or duplicate entries. If you do not fix these errors, the machine learning training process will either not work or contain errors.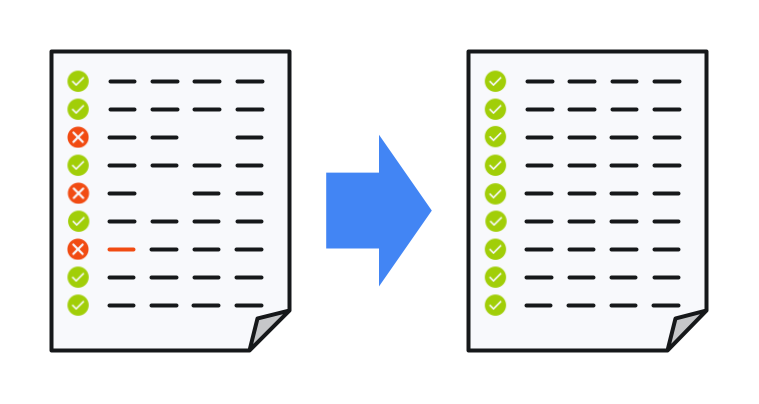
Data analysis
Once the data is cleaned, it can be analyzed by domain experts and data scientists to identify patterns and extract meaning. This is often a manual process that utilizes various algorithms (e.g. unsupervised ML) and tools (e.g. Python, R). Such patterns can be used to construct ML models that automatically generalize meaning from the raw input data. Additionally, data can contain any number of biases that can lead to a biased machine learning model. Analyzing your data for biases can create a much more robust and fair model down the road.Feature extraction
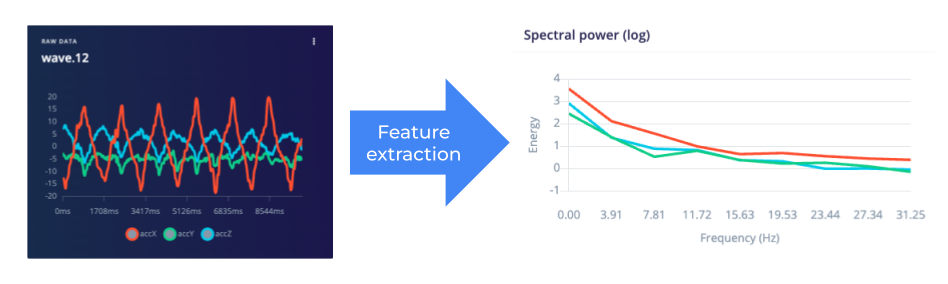
Sometimes, the raw data is not sufficient or might cause the ML model to be overly complex. As a result, manual features can be extracted from the raw data to be fed into the ML model. While feature engineering is a manual step, it can potentially save time and inference compute resources by not having to train a larger model. In other words, feature extraction can simplify the data going to a model to help make the model smaller and faster.