Hosting custom processing blocks in Edge Impulse is only available on the Enterprise planHosting a custom processing block in the Edge Impulse infrastructure, and making it available to everyone in your organization, is only available on the Enterprise plan. Other developers can host their custom processing block themselves and expose it to projects. See Testing the block locally in this document.
Block structure
The processing block structure is shown below. A key difference for processing blocks versus other types of blocks is that they implement an HTTP server within the application. Please see the custom blocks overview page for more details.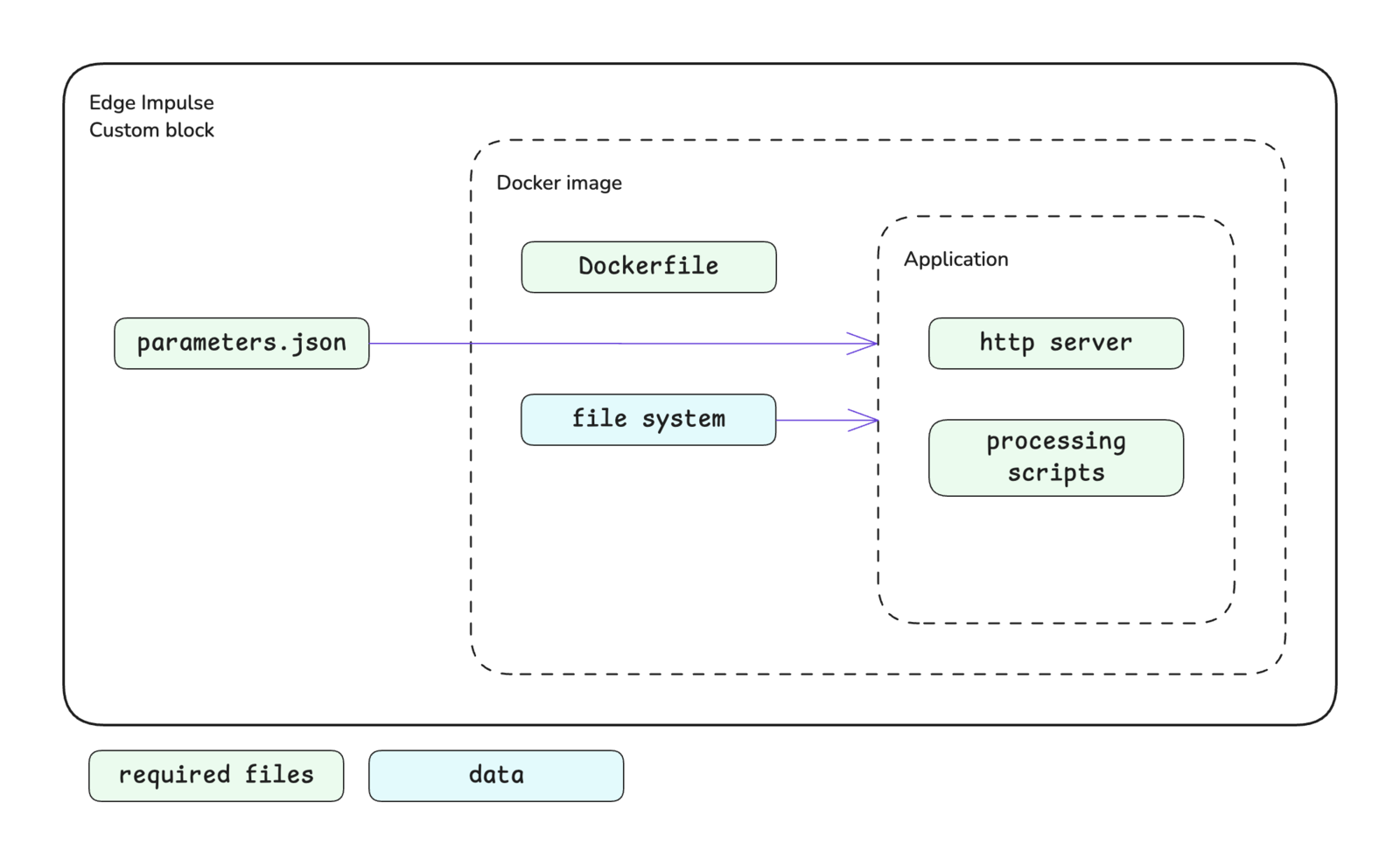
Custom processing block structure
Block interface
Processing blocks are expected to implement an HTTP server to handle requests. The sections below define the required and optional inputs (requests) and the expected outputs (responses) for custom processing blocks.Inputs
Information will be provided to your custom processing block through the request headers and body.Requests
Request headers
Request body
The request body adheres to the following interfaces for thePOST methods. GET methods do not have a request body.
features property.
The axes property provides the names of the signals for the data sample. For example, if this was an accelerometer data sample, the axes could be [ 'accX', 'accY', 'accZ' ]. These names could be mapped to other names in the named_axes property.
The parameters defined in your parameters.json file will be passed to your block in the params property. If your parameter names contain dashes, these are replaced with underscores before being added to the request body. For example, a processing block parameter named custom-processing-param is passed as custom_processing_param. Please refer to the parameters.json documentation for further details about creating this file, parameter options available, and examples.
Outputs
The expected response from the HTTP server in your custom processing block varies depending on the type of request.GET methods
GET /:
A plain text response with some information about the block. For example, the response could be the block name and author.
GET /parameters:
The parameters file returned as a JSON object.
POST methods
The POST response bodies are expected to adhere to the following interfaces.features property is where you return the features that were generated by processing the data sample(s).
The labels property can be used return the names of the features you generated. For example, if you calculated the average, maximum, and minimum values of the signal, the labels could be [ 'Average', 'Maximum', 'Minimum' ]. These labels will be used for the feature explorer.
Adding visualizations
The results of generating features can be shown in Studio through graphs and the feature explorer.Graphs
When configuring parameters for a processing block in Studio, a preview of the feature generation results for a single sample is shown. This preview can include displaying graphs. These are the graphs that you define and return in thegraphs property of the response body for the POST /run method. Graphs should be created in your feature generation script conditionally based on the draw_graphs property in the request body. See the interface for a graphs object in the Outputs section above.
Graphs can be of different types: linear, logarithmic, or an image. The type of graph is controlled by the type property of a graph object.
Feature explorer
The results of generating features on all samples can be shown in the feature explorer. If you output high-dimensional data, you can enable dimensionality reduction for the feature explorer. This will run UMAP over the data to compress the features into two dimensions. To do so, you can set thevisualization property in your parameters.json file to dimensionalityReduction.
Initializing the block
When you are finished developing your block locally, you will want to initialize it. The procedure to initialize your block is described in the custom blocks overview page. Please refer to that documentation for details.Testing the block locally
The most convenient way to test your custom processing block before pushing it to Edge Impulse is to host it locally and then expose it to the internet so that it can be accessed by Studio. There are two ways to achieve this. You will need to have Docker and ngrok installed on your machine for either approach.With blocks runner
For the first method, you can use the CLIedge-impulse-blocks runner tool. See Block runner for additional details.
The port you publish for your Docker container can be configured in the parameters.json file. The blocks runner will also look for the EXPOSE instruction in your Dockerfile and publish that port for you if you wish to override the default port.
With ngrok and Docker
For the second method, you can run Docker and ngrok directly instead of using the CLI blocks runner tool. First, you can build the Docker image and run the container.https:// forwarding address in the response. You can use this URL to add the block to an impulse in a Studio project.
Viewing in Studio
With a public URL for your custom processing block, you can go into your project and add a processing block to your impulse. When the processing block selection modal pops up, go to the bottom left corner and click theAdd custom block button. In the next modal that pops up, enter your forwarding URL from above and save. The block can now be used in your project and you will be able to view the processing results, including any visualizations you have created.

Adding a custom processing block using an ngrok forwarding URL
Pushing the block to Edge Impulse
When you have initialized and finished testing your block locally, you will want to push it to Edge Impulse. The procedure to push your block to Edge Impulse is described in the custom blocks overview page. Please refer to that documentation for details.Using the block in a project
After you have pushed your block to Edge Impulse, it can be used in the same way as any other built-in block.Running on device
One caveat for custom processing blocks is that Edge Impulse cannot automatically generate optimized code to run on-device as is done with processing blocks built into the platform. This code will need to be written by you. To help you get started, the structure is provided for you. After exporting the C++ library from the Deployment page in Studio, you can see that a forward declaration for your custom processing block will have been created for you in themodel-parameters/model_variables.h file.
cppType property in your parameters.json file.
main.cpp file of the C++ library. Example implementations for the processing blocks built into Edge Impulse can be found in the C++ inferencing SDK.
Examples
Edge Impulse has developed several processing blocks that are built into the platform. The code for these blocks can be found in a public repository under the Edge Impulse GitHub account. See below. Additional examples can also be found in the Edge Impulse account. These repository names typically follow the convention ofexample-custom-processing-block-<description>. As such, they can be found by searching the repositories for example-custom-processing.
Below are direct links to some examples:
Troubleshooting
No common issues have been identified thus far. If you encounter an issue, please reach out on the forum or, if you are on the Enterprise plan, through your support channels.