- Starting with a model with randomly initialized weights.
- Passing labeled data through the model and comparing the output with the correct output using a “loss function”.
- Using an optimizer to make adjustments to the model weights based on the loss function results.
- Repeating the process until the model’s performance ceases to improve.
What is an optimizer?
If you are not familiar with optimizers, see this page: OptimizersVeLO: A learned optimizer
VeLO (Versatile Learned Optimizers) is an innovative concept where the optimizer is trained using a large number of training jobs, as detailed in the paper “VeLO: Training Versatile Learned Optimizers by Scaling Up” [2]. This approach contrasts with traditional optimizers, like Adam, which are handcrafted functions.When to use the learned optimizer?
The learned optimizer can help you get some extra performance for certain models. For optimal results with VeLO, it is recommended to use as large a batch size as possible, potentially equal to the dataset’s size. This approach, however, may lead to out-of-memory issues for some projects. Here are some pros and cons of using the learned optimizer:Pros- VeLO generally requires less tuning compared to Adam.
- The learned optimizer works well across various scenarios without specific adjustments.
- VeLO comprises a large LSTM model, often larger than the models it trains. This requires more computational resources, particularly for GPU-intensive models like vision models.
Studio integration
The Learned Optimizer can be enabled in Edge Impulse as an option on the training page.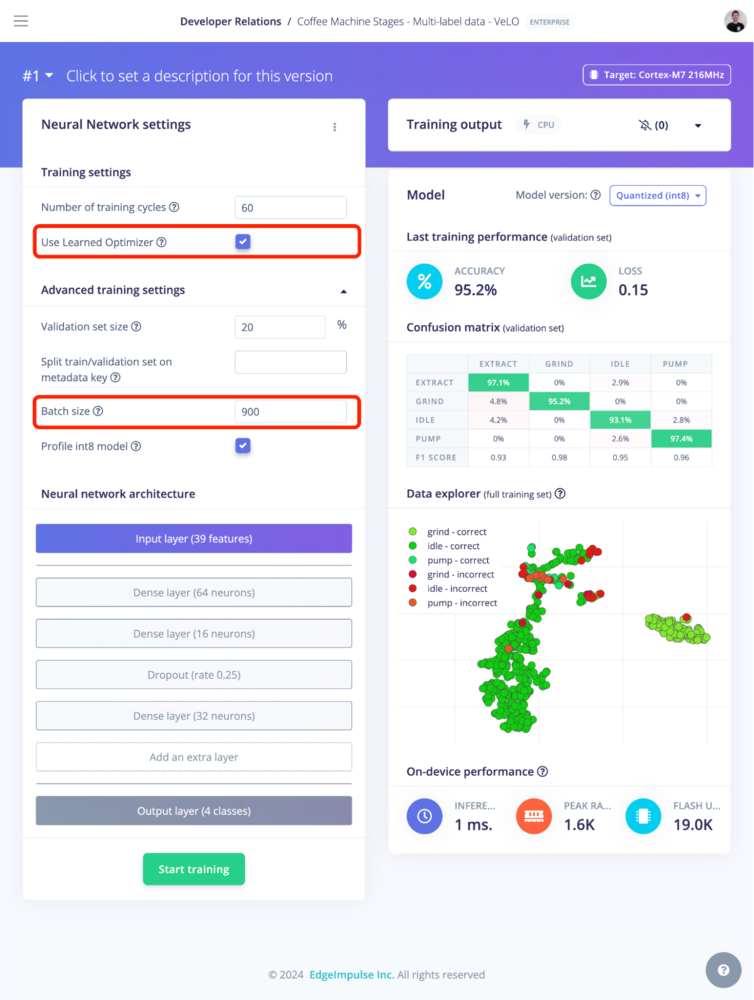
Using VeLO in expert mode
The simplest way to use VeLO in expert mode is to enable the flag for a project and then switch to expert mode. This will pre-fill the needed lines of code in the expert mode. To use VeLO in expert mode for an existing project:- Remove any existing optimizer creation,
model.compile, ormodel.fitcalls. - Replace with the
train_keras_model_with_velomethod.
How does VeLO compare to Adam?
Consider the following graph which shows several runs of Adam vs VeLO: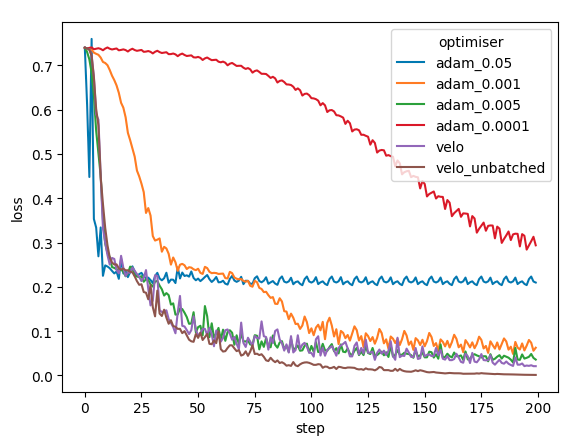
Examples
The following projects contain both a learning block with and without the learned optimizer so you can easily see the differences:- Image classification using transfer learning: Microscope - VeLO
- Vibration analysis: Coffee Machine Stages - Multi-label data - VeLO