Only available on the Enterprise planThis feature is only available on the Enterprise plan. Review our plans and pricing or sign up for our free expert-led trial today.
- Synchronizing clinical data with a bucket
- Validating clinical data
- Querying clinical data
- Transforming clinical data
- Building data pipelines
Buckets
Before we get started, you must link your organization with one or more storage buckets. Further details about how to integrate with cloud storage providers can be found in the Cloud data storage document.Datasets
Two types of dataset structures can be used - Generic datasets (default) and Clinical datasets.There is no required format for data files. You can upload data in a wide range of formats, whether it’s CSV, Parquet, or a proprietary data format.However, to import data items to an Edge Impulse project, you will need to use the right format as our studio ingestion API only supports these formats:
- JPG, PNG images
- MP4, AVI video files
- WAV audio files
- JSON/CBOR files in the Edge Impulse data acquisition format
- CSV files
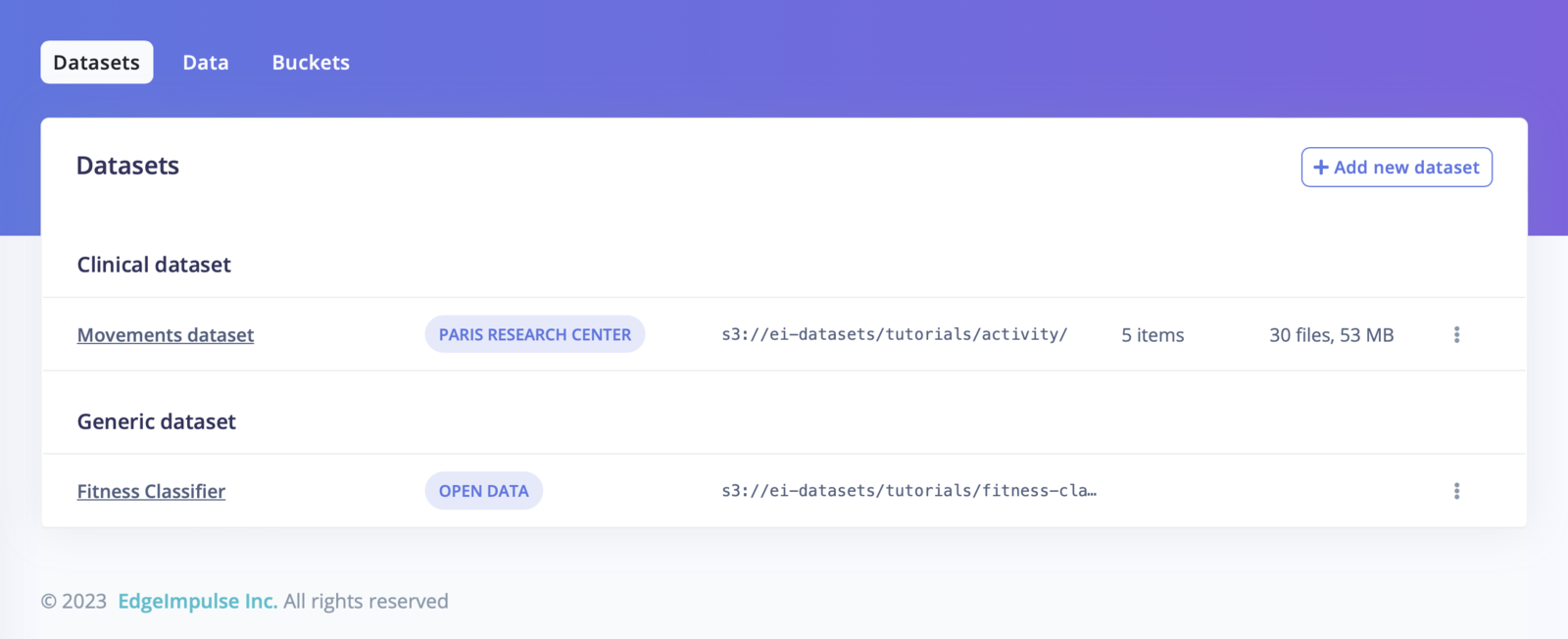
Datasets overview
- Default dataset
- Clinical dataset
The default dataset structure is a file-based one, no matter the directory structure:For example:or:Note that you will be able to associate the labels of your data items from the file name or the directory name when importing your data in a project.
Create a new dataset
Once you successfully linked your storage bucket to your organization, head to the Datasets tab and click on + Add new dataset: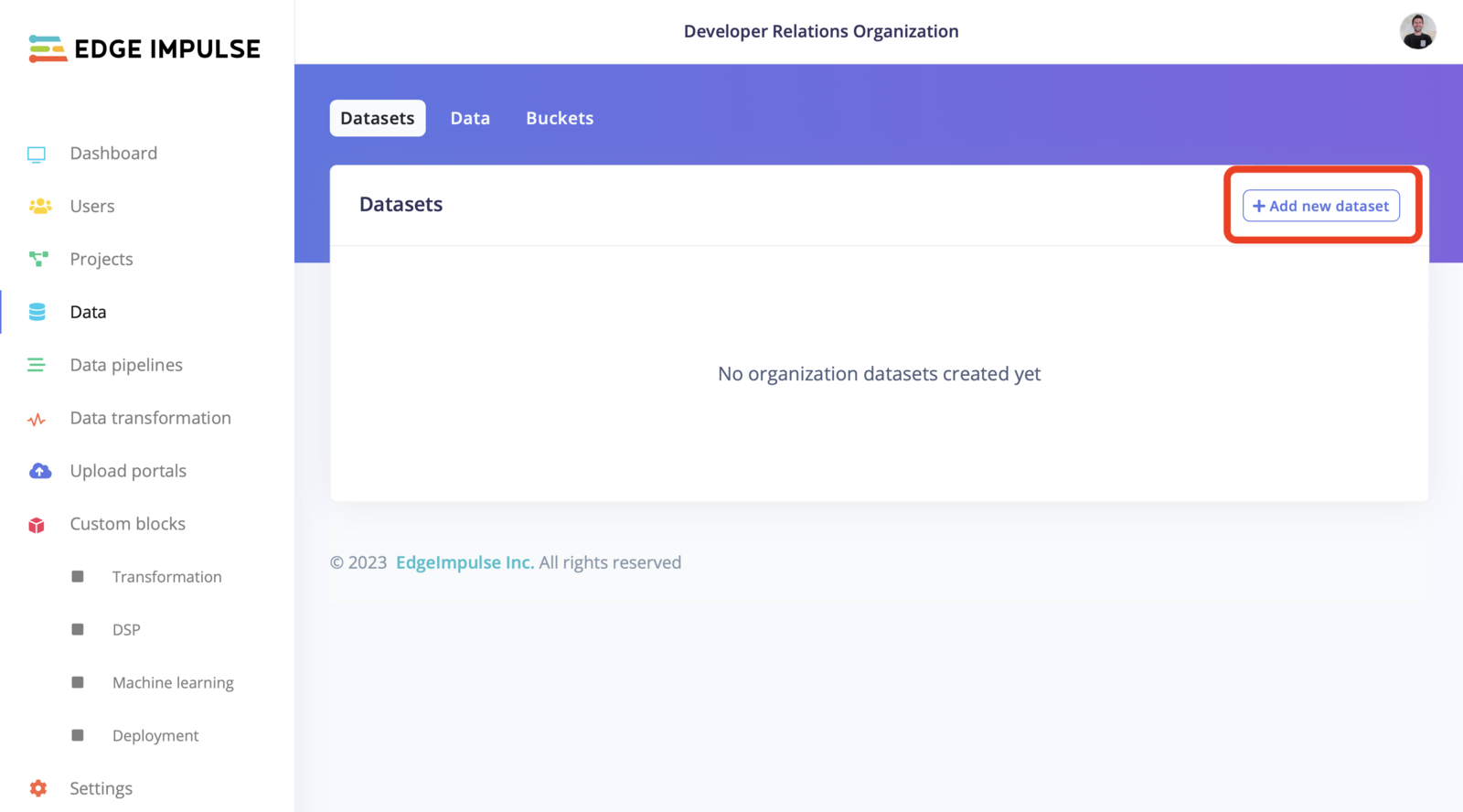
Add new dataset
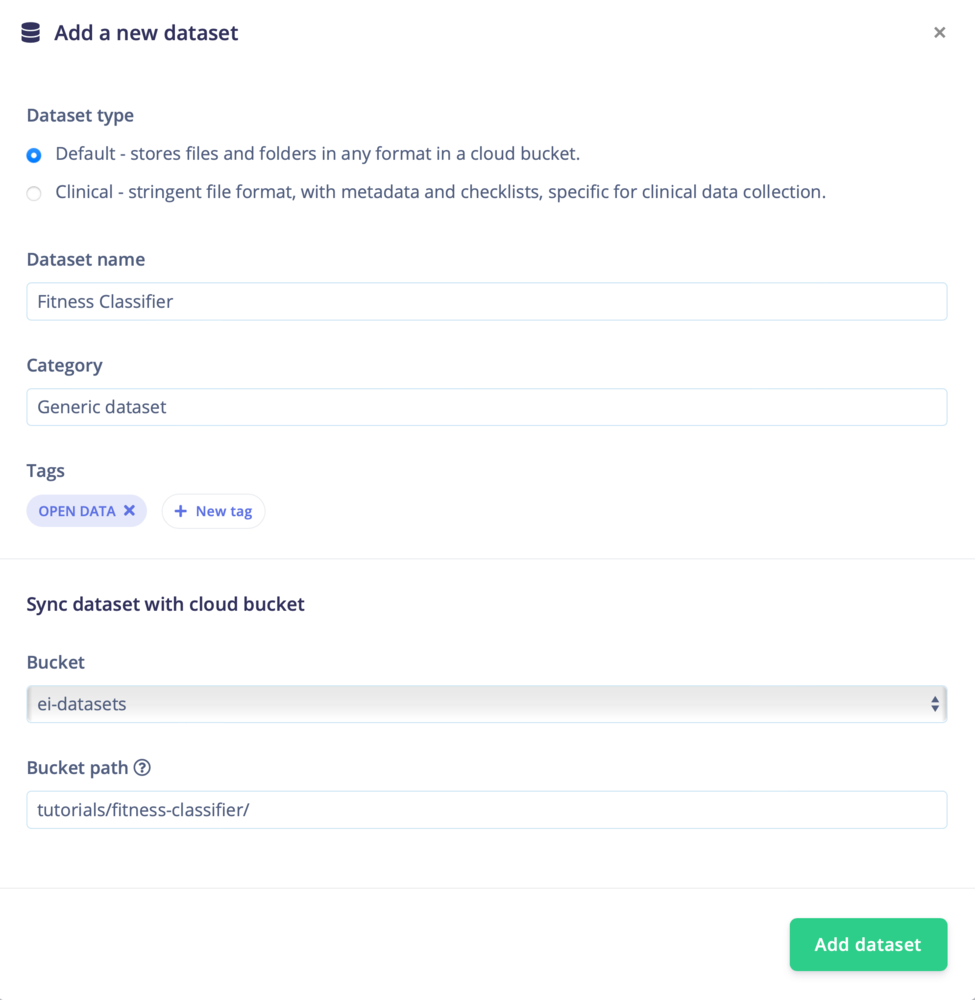
Add dataset
Data
With your datasets imported, you can now navigate into your dataset, create folders, query your dataset, add data items and import your data to an Edge Impulse project.- Default dataset
- Clinical dataset
Default view
The default view lets you navigate in your bucket following the directory structure. You can easily add data using the ”+ New folder” button. To add new data, use the right panel - drag and drop your files and folders and it will automatically upload them to your bucket.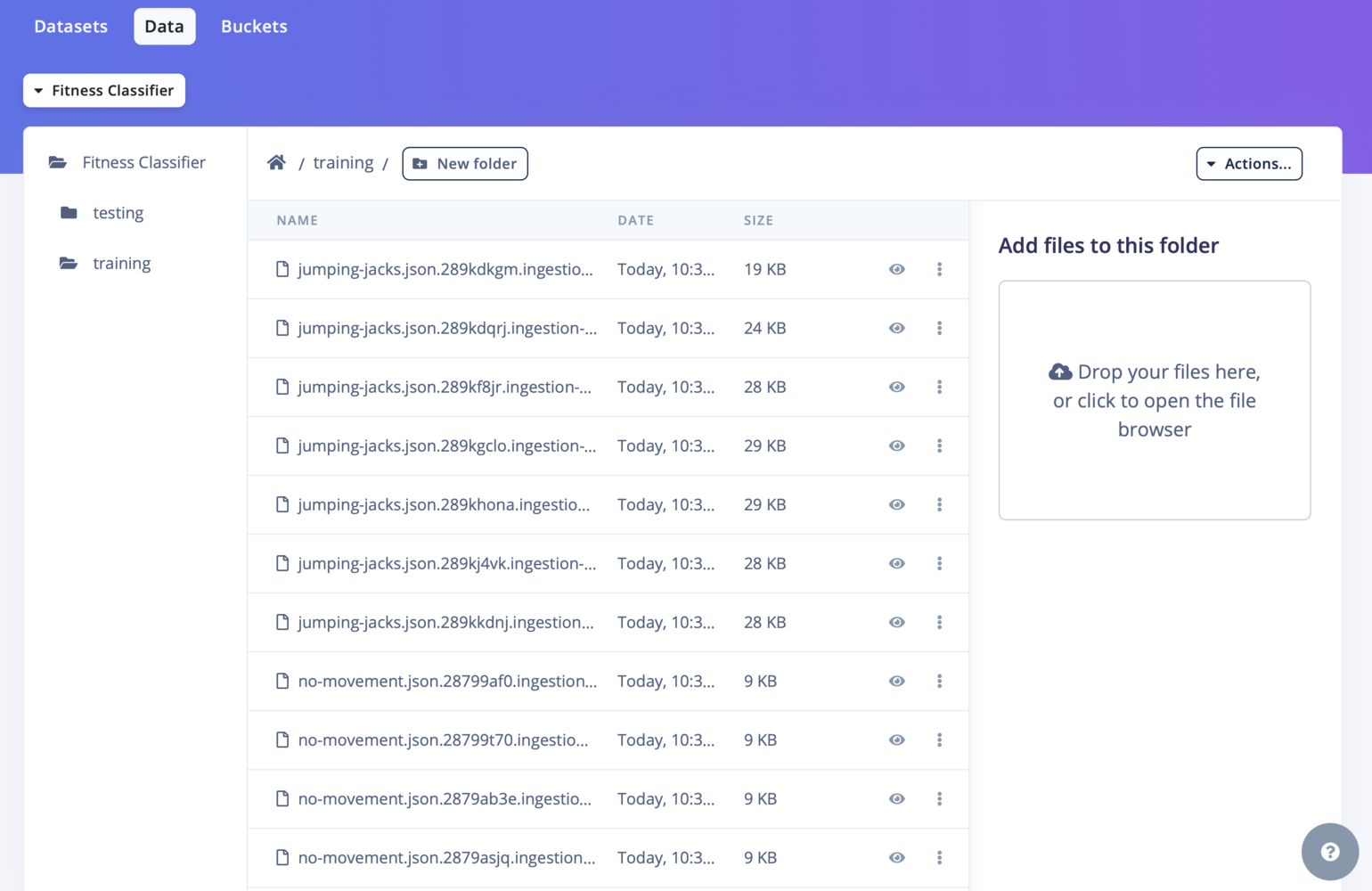
Data items overview
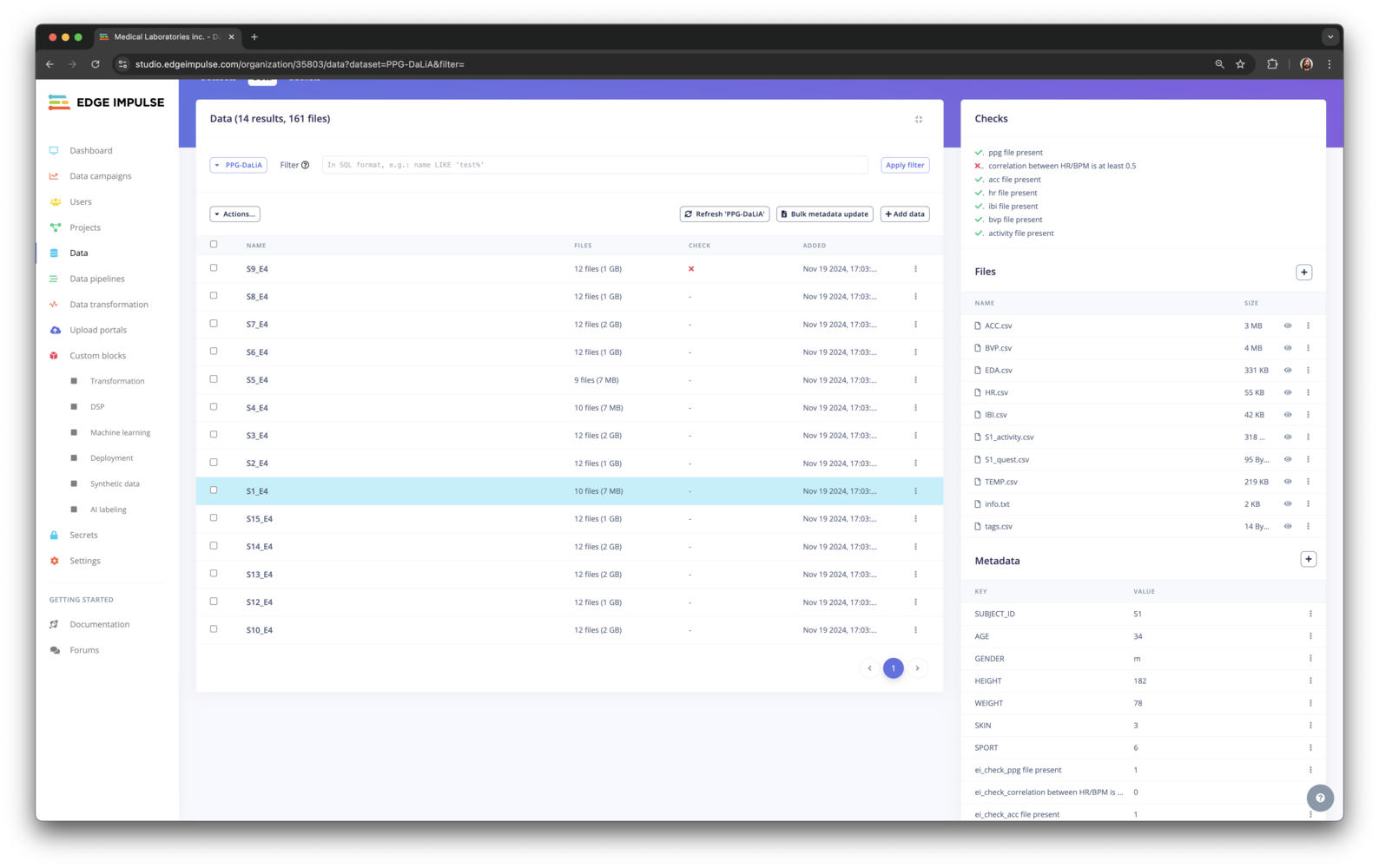
Adding data to your project
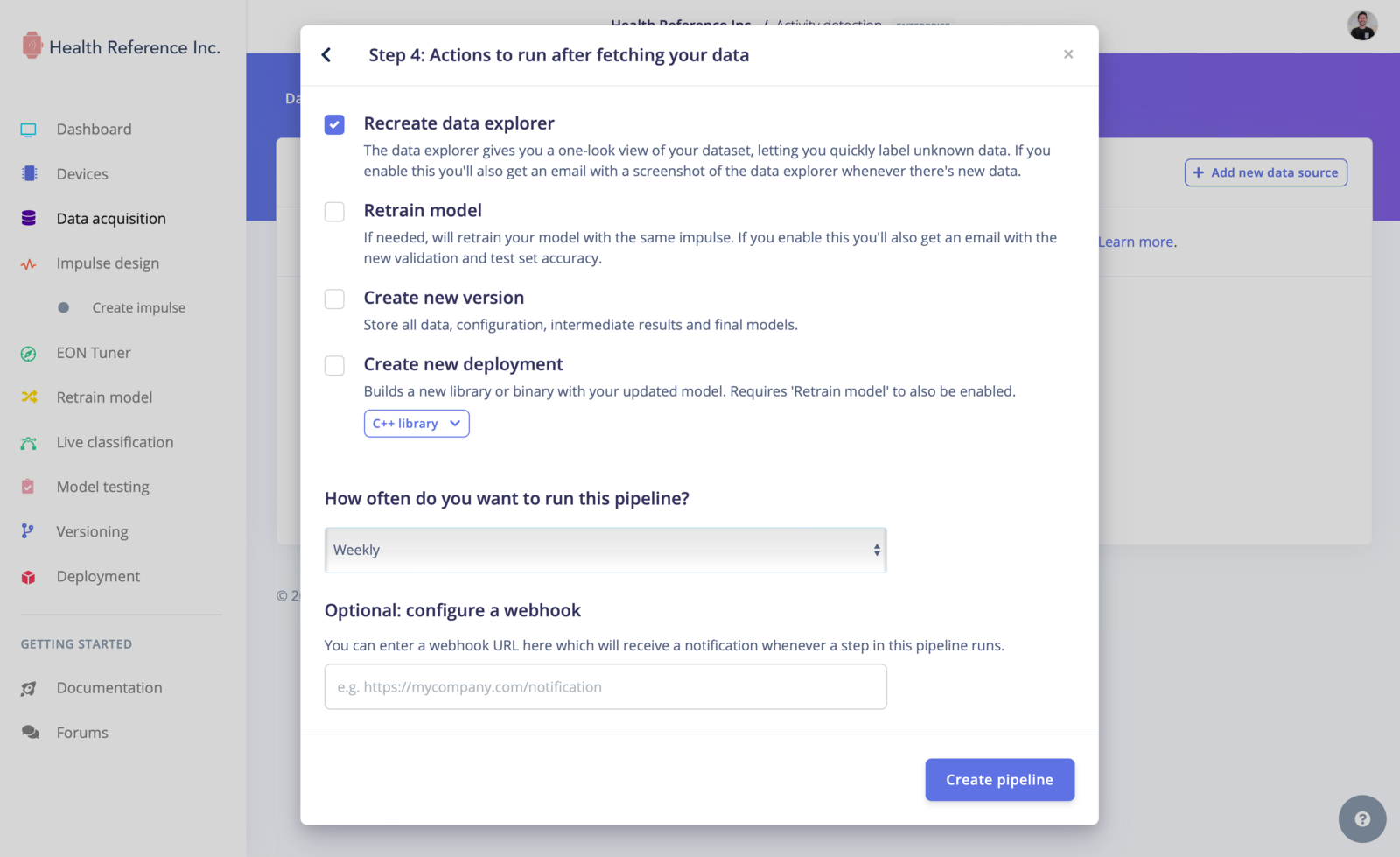
Go to the Actions…->Import data into a project, select the project you wish to import to and click Next, Configure how to label this data: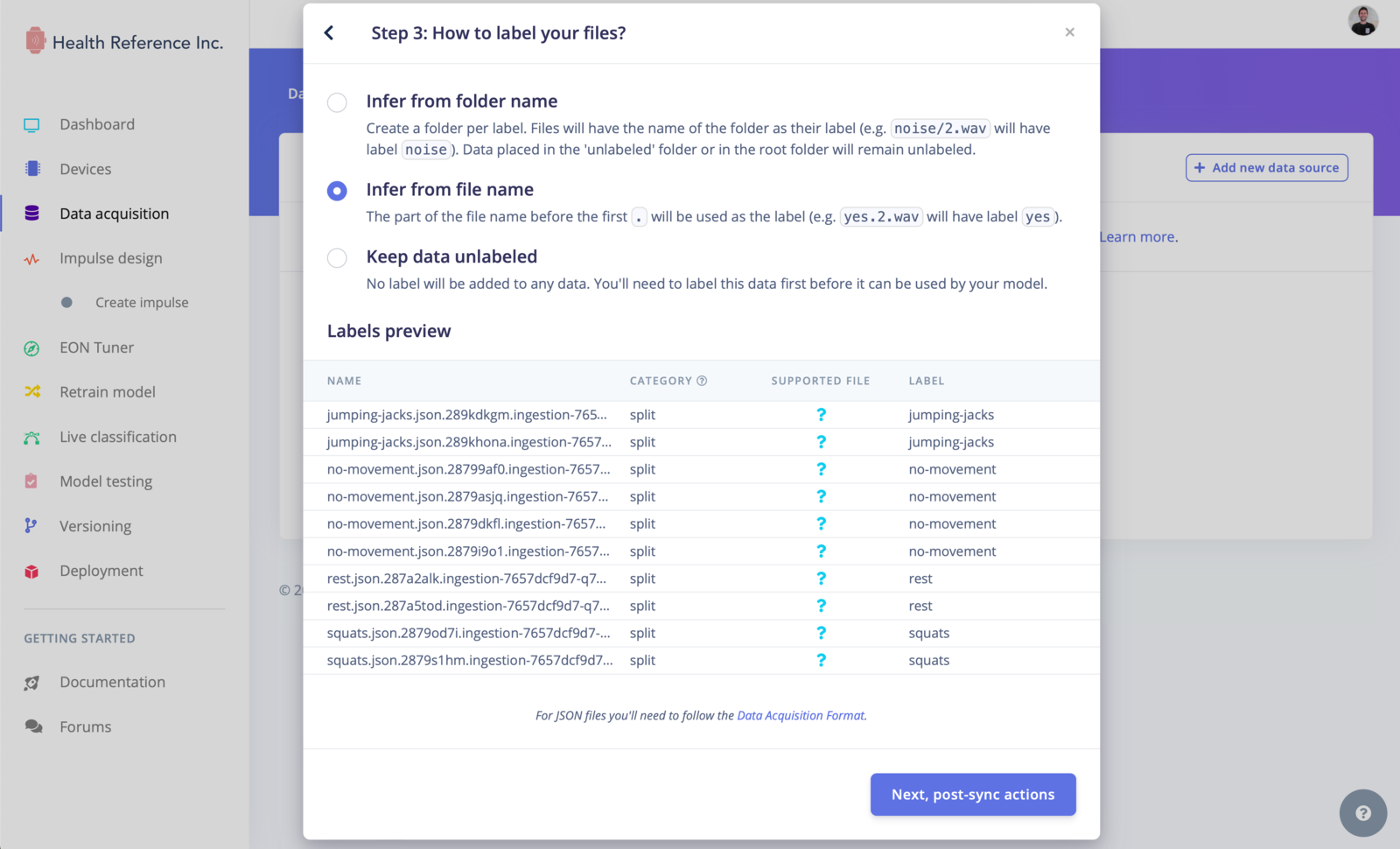
Uploading Files
Label your files
Previewing Data
We also have added a data preview feature, allowing you to visualize certain types of data directly within the organization data tab. Supported data types include tables (CSV/Parquet), images, PDFs, audio files (WAV/MP3), and text files (TXT/JSON). This feature gives you a quick overview of your data and helps ensure its integrity and correctness.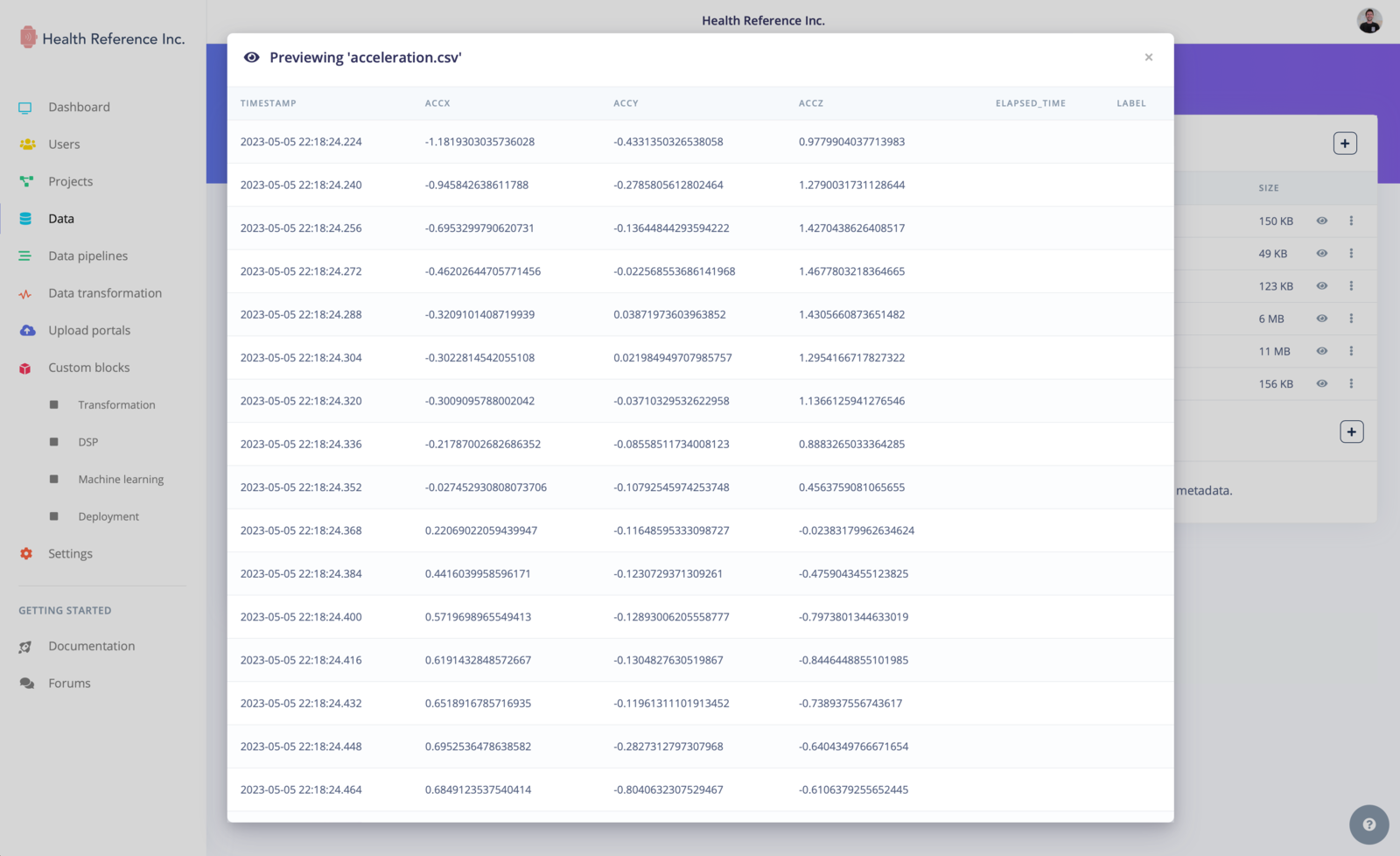
Data items overview - CSV/Parquet type
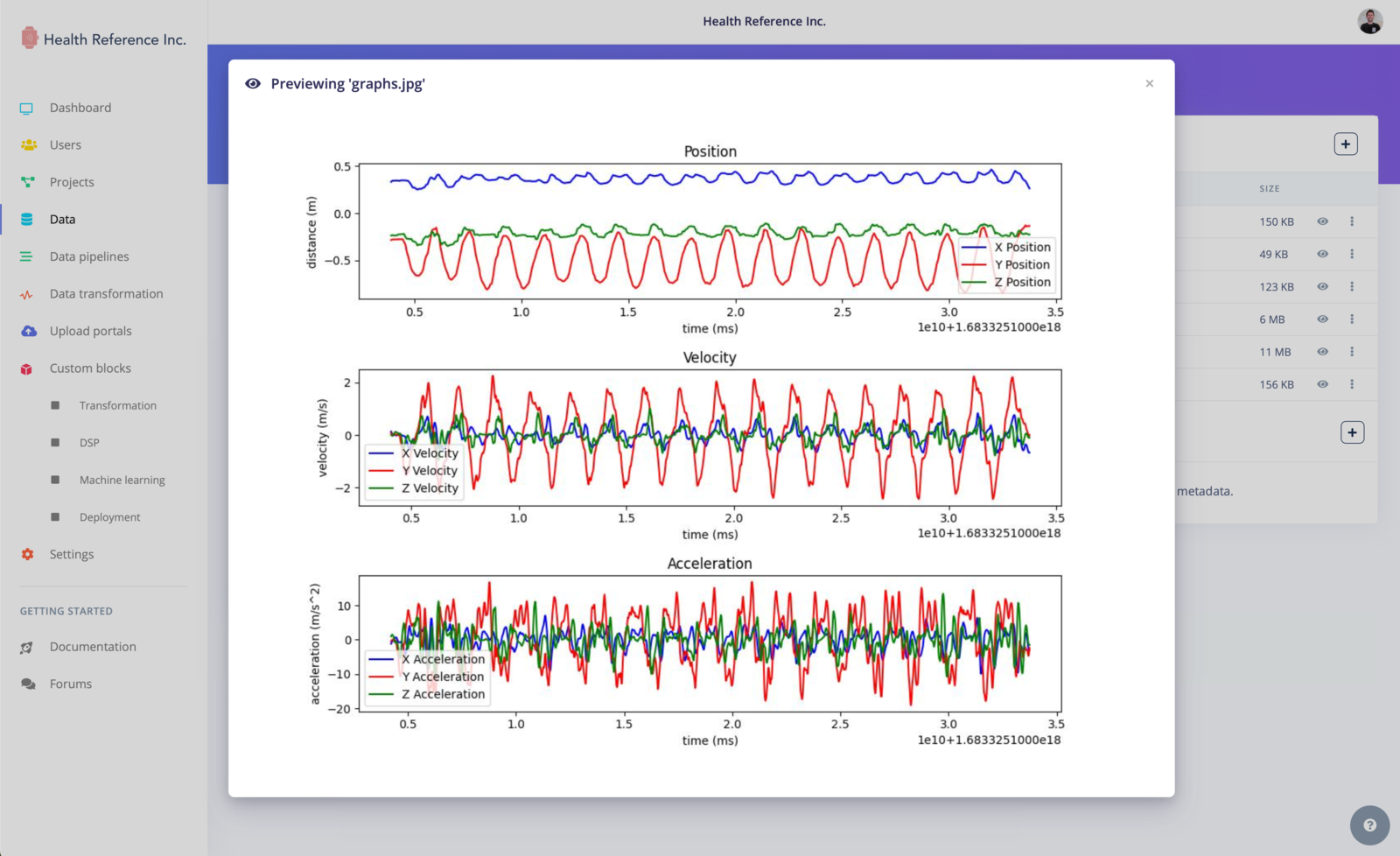
Data items overview - image type