Similarly to the Spectrogram block, the Audio MFE processing block extracts time and frequency features from a signal. However it uses a non-linear scale in the frequency domain, called Mel-scale. It performs well on audio data, mostly for non-voice recognition use cases when sounds to be classified can be distinguished by human ear.
GitHub repository containing all DSP block code: edgeimpulse/processing-blocks.
The “Processed features” array has the following format:
- Column major, from low frequency to high.
- Number of rows will be equal to the filter number
- Each column represents a single frame
Consider a toy example where the the signal is a pure tone, and Filter number is set to 6:
Output would begin as shown. The tone is a low frequency, so it falls into the first two Mel bins. The higher frequency bins are 0. The pattern repeats at the 7th element, which is the 1st row of the 2nd column.
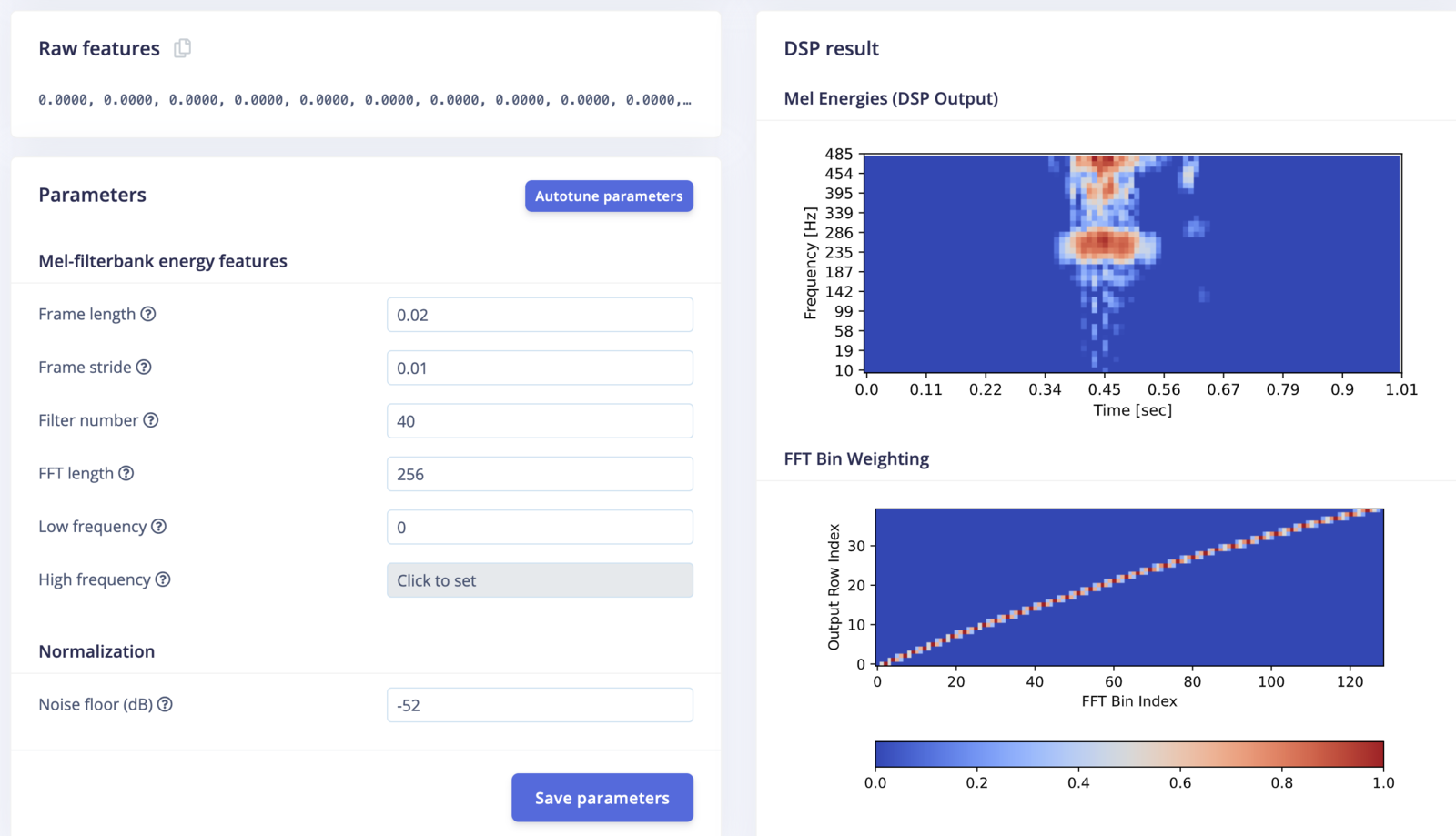
Audio MFE parameters
Compatible with the DSP AutotunerPicking the right parameters for DSP algorithms can be difficult. It often requires a lot of experience and experimenting. The autotuning function makes this process easier by recommending a set of parameters that is tuned for your dataset.
- Frame length: The length of each frame in seconds
- Frame stride: The step between successive frame in seconds
- Filter number: The number of triangular filters applied to the spectrogram
- FFT length: The FFT size
- Low frequency: Lowest band edge of Mel-scale filterbanks
- High frequency: Highest band edge of Mel-scale filterbanks
Normalization
- Noise floor (dB): signal lower than this level will be dropped
How does the MFE block work?
The features’ extractions is similar to the Spectrogram (Frame length, Frame stride, and FFT length parameters are the same) but it adds 2 extra steps.
After computing the spectrogram, triangular filters are applied on a Mel-scale to extract frequency bands. They are configured with parameters Filter number, Low frequency and High frequency to select the frequency band and the number of frequency features to be extracted. The Mel-scale is a perceptual scale of pitches judged by listeners to be equal in distance from one another. The idea is to extract more features (more filter banks) in the lower frequencies, and less in the high frequencies, thus it performs well on sounds that can be distinguished by human ear.
The graph titled “FFT Bin Weighting” shows how the FFT bins are scaled and summed into the output columns for your chosen parameters.
The last step clips the MFE output for noise reduction. Any sample below Noise floor is set to zero instead.