Prerequisites
Make sure you follow the Continuous motion recognition tutorial, and have a trained impulse.Development flowThis tutorial shows you the development flow of building custom processing blocks, and requires you to run the processing block on your own machine or server. Enterprise customers can share processing blocks within their organization, and run these on our infrastructure. See custom processing blocks for more details.
1. Building your first custom processing block
Processing blocks take data and configuration parameters in, and return features and visualizations like graphs or images. To communicate to custom processing blocks, Edge Impulse studio will make HTTP calls to the block, and then use the response both in the UI, while generating features, or when training a machine learning model. Thus, to load a custom processing block we’ll need to run a small server that responds to these HTTP calls. You can write this in any language, but we have created an example in Python. To load this example, open a terminal and run:
Exposing the processing block to the world
As this block is running locally the studio cannot reach the block. To resolve this we can use ngrok which can make a local port accessible from a public URL. After you’ve finished development you can move the processing block to a server with a publicly accessible address (or run it on our infrastructure through your enterprise account). To set up a tunnel:- Sign up for ngrok.
- Install the ngrok binary for your platform.
- Get a URL to access the processing block from the outside world via:
Forwarding. Note down the address that includes https://.
Adding the custom block to Edge Impulse
Now that the custom processing block was created, and you’ve made it accessible to the outside world, you can add this block to Edge Impulse. In a project, go to Create Impulse, click Add a processing block, choose Add custom block (in the bottom left corner of the modal), and paste in the public URL of the block: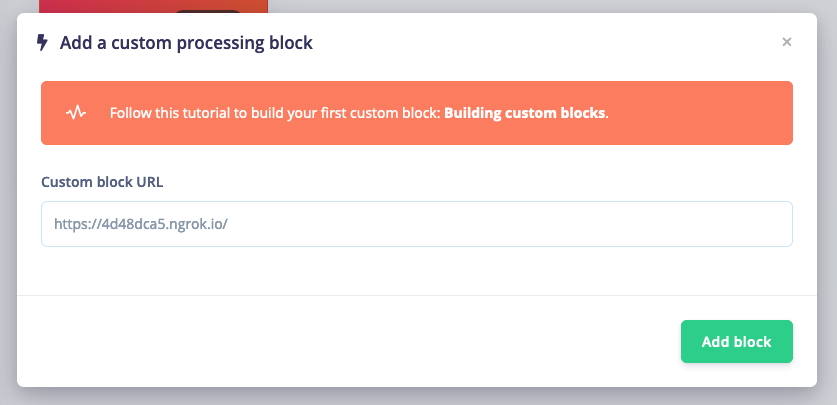
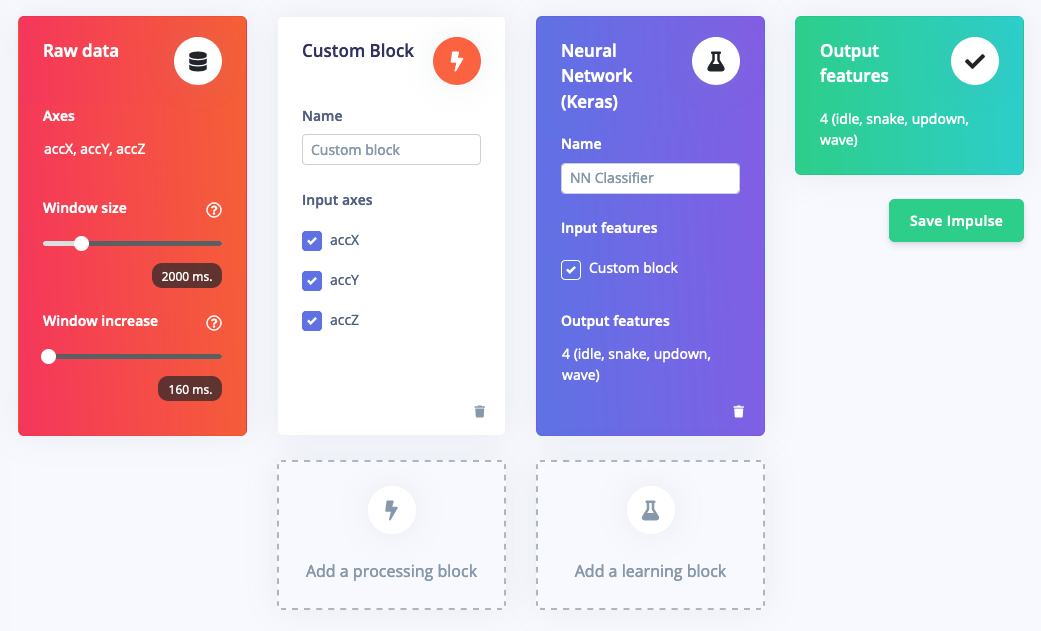
2. Adding configuration options
Processing blocks have configuration options which are rendered on the block parameter page. These could be filter configurations, scaling options, or control which visualizations are loaded. These options are defined in theparameters.json file. Let’s add an option to smooth raw data. Open example-custom-processing-block-python/parameters.json and add a new section under parameters:
example-custom-processing-block-python/dsp.py and replace its contents with:
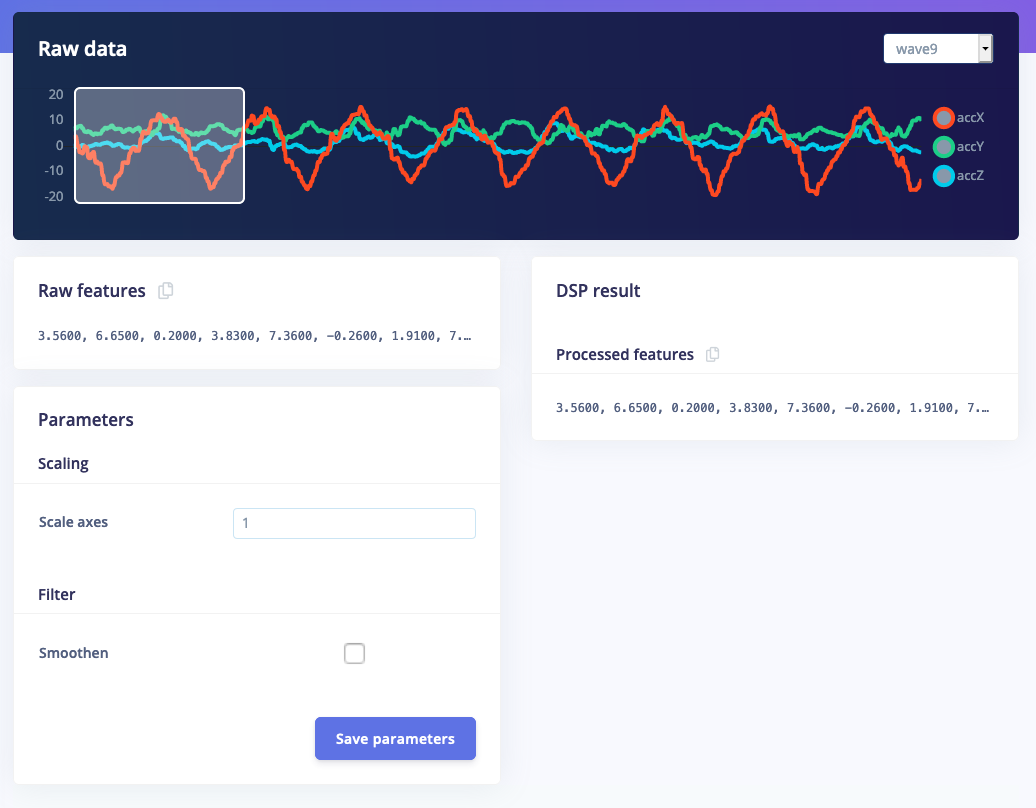
2.1 Customizing parameters
For the full documentation on customizing parameters, and a list of all configuration options; see parameters.json.3. Implementing smoothing and drawing graphs
To show the user what is happening we can also draw visuals in the processing block. Right now we support graphs (linear and logarithmic) and arbitrary images. By showing a graph of the smoothed sample we can quickly identify what effect the smooth option has on the raw signal. Opendsp.py and replace the content with the following script. It contains a very basic smoothing algorithm and draws a graph:
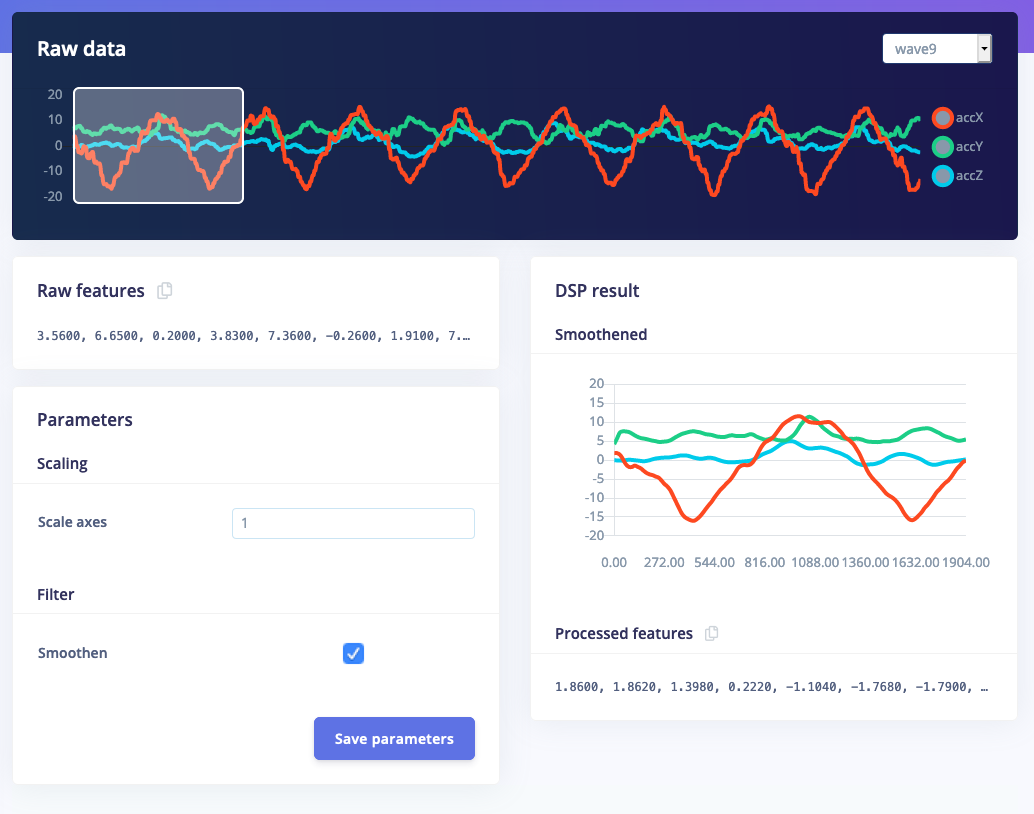
3.1 Adding features to labels
If you extract set features from the signal, like the mean, that you that return, you can also label these features. These labels will be used in the feature explorer. To do so, add alabels array that contains strings that map back to the features you return (labels and features should have the same length).
4. Other type of graphs
In the previous step we drew a linear graph, but you can also draw logarithmic graphs or even full images. This is done through thetype parameter:
4.1 Logarithmic graphs
This draws a graph with a logarithmic scale: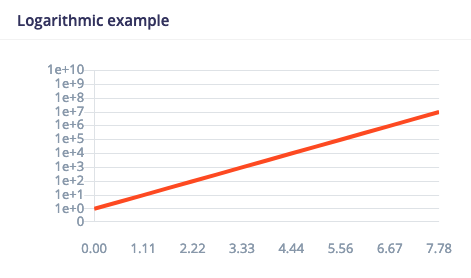
4.2 Images
To show an image you should return the base64 encoded image and its MIME type. Here’s how you draw a small PNG image:
4.3 Dimensionality reduction
If you output high-dimensional data (like a spectrogram or an image) you can enable dimensionality reduction for the feature explorer. This will run UMAP over the data to compress the features into three dimensions. To do so, set:info object in parameters.json.
4.4 Full documentation
For all options that you can return in a graph, see the Run DSP return types in the API documentation.5. Running on device
Your custom block behaves exactly the same as any of the built-in blocks. You can process all your data, train neural networks or anomaly blocks, and validate that your model works. However, we cannot automatically generate optimized native code for the block, like we do for built-in processing blocks, but we try to help you write this code as much as possible. Export as a C++ Library:- In the Edge Impulse platform, export your project as a C++ library.
- Choose the model type that suits your target device (
quantizedvs.float32).
model-parameters/model_variables.h file of the exported C++ library, you can see a forward declaration for the custom DSP block you created.
For example:
cppType field in your custom DSP parameter.json. It takes your {cppType} and generates the following extract_{cppType}_features function.
Implement the Custom DSP Block:
In the main.cpp file of the C++ library, implement the extract_my_preprocessing_features block. This block should:
- Call into the Edge Impulse SDK to generate features.
- Execute the rest of the DSP block, including neural network inference.
- Copy a test sample’s raw features into the
features[]array insource/main.cpp - Enter
make -jin this directory to compile the project. If you encounter any OOM memory error trymake -j4(replace 4 with the number of cores available) - Enter
./build/appto run the application - Compare the output predictions to the predictions of the test sample in the Edge Impulse Studio.
6. Other resources
Blog post: Utilize Custom Processing Blocks in Your Image ML Pipelines7. Conclusion
With good feature extraction you can make your machine learning models smaller and more reliable, which are both very important when you want to deploy your model on embedded devices. With custom processing blocks you can now develop new feature extraction pipelines straight from Edge Impulse. Whether you’re following the latest research, want to implement proprietary algorithms, or are just exploring data. For inspiration we have published all our own blocks here: edgeimpulse/processing-blocks. If you’ve made an interesting block that you think is valuable for the community, please let us know on the forums or by opening a pull request. We’d be happy to help write efficient native code for the block, and then publish it as a standard block!Parameters.json format
This is the format for theparameters.json file: