Using the feature explorer
To access the feature explorer, go to the Processing page in your project. The name of this page depends on which processing block you used, such as Raw, Flatten, Spectral analysis, and so on. On the processing page, configure your processing block and click Save parameters. You will be automatically transferred to the Generate features tab. From there, click Generate features and wait while your raw data is transformed into features. If you are using the Flatten processing block, you will see a 3D representation of up to 3 axes from the features generated in that block. You can select which axes are shown by selecting them from the drop-down menus above the plot.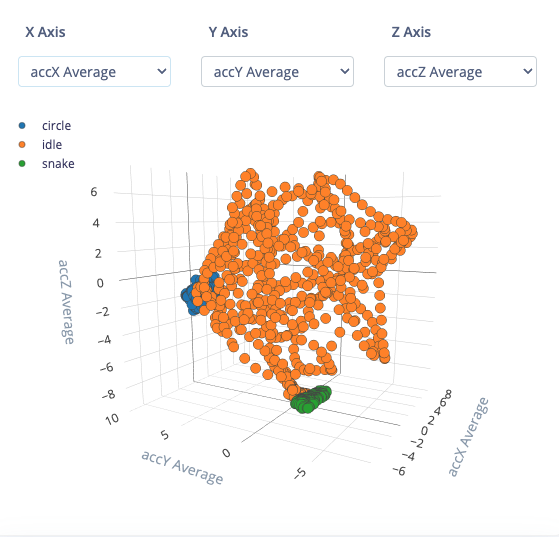
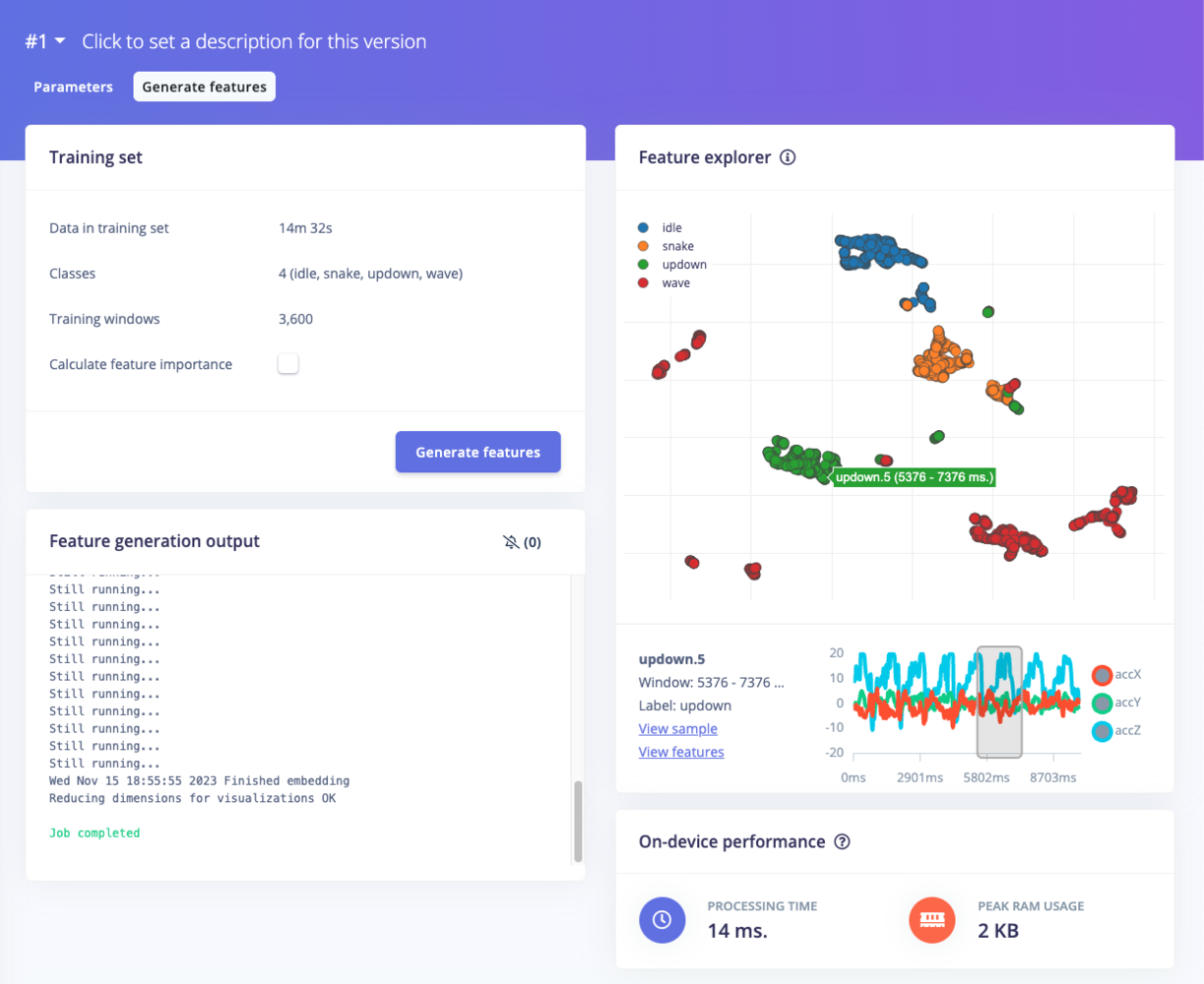
Understanding the feature explorer
The feature explorer is a tool for analyzing your dataset, your feature extraction (processing) method, and how well you should expect a machine learning model to classify new samples. We will use our example above, which consists of the spectral analysis features extracted from the continuous motion recognition tutorial to help you get started.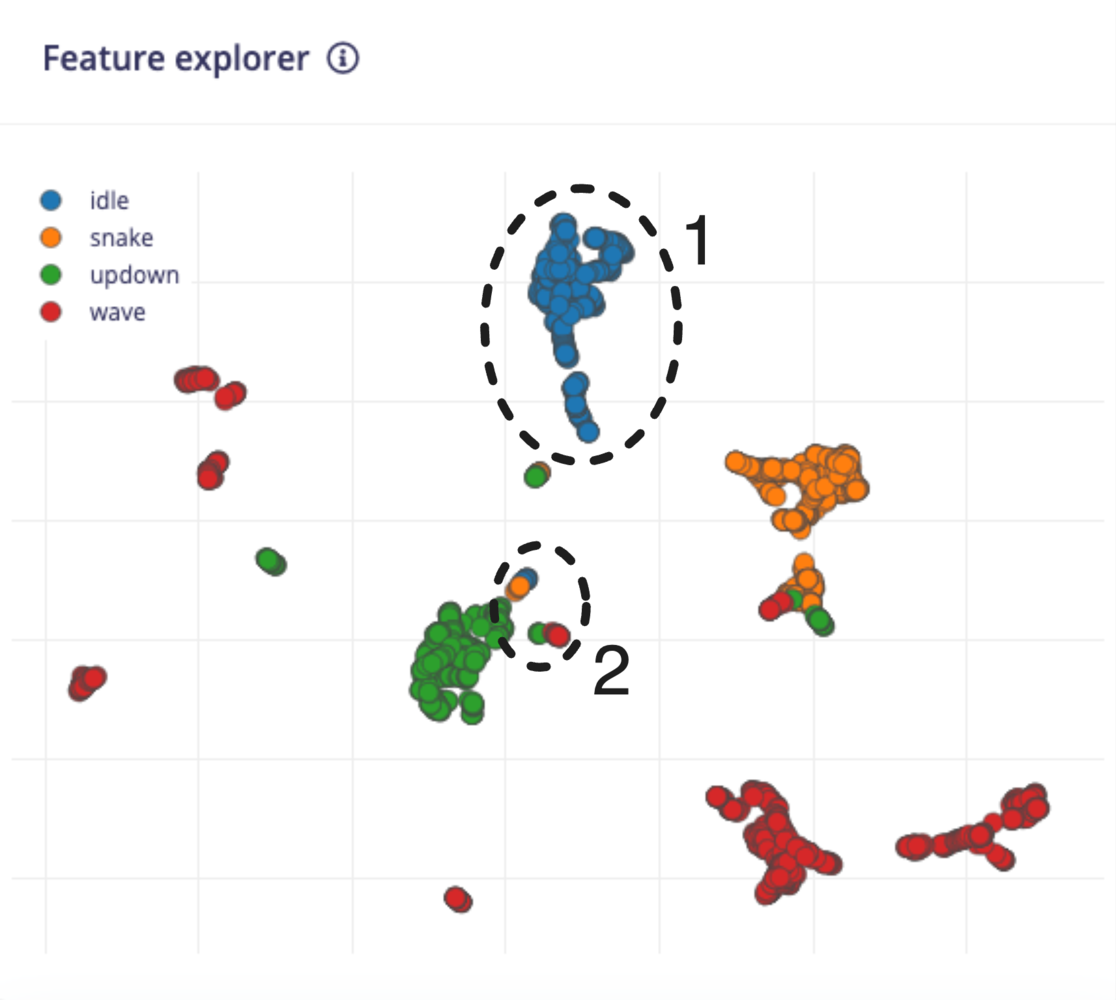
- Collect more data. This will sometimes help flesh out more distinguishable clusters in your features.
- Try a different processing method. You might need to change how your features are extracted. Spectral analysis not working? Try a spectrogram. Grayscale images create overlapping features? Try using color (RGB) instead to see if the extra information helps separate the groupings.
- Try different processing parameters. Play with the feature extraction settings in your processing block to see if you can create better groupings.
- Use a more complex ML model. If you feel you have tried your best to get the features to separate into clusters but there is still a lot of overlap, then you might need to rely on your ML model to perform the separation for you. Often, this means using more complex models (e.g. more layers, more nodes). As before, be aware of under- and over-fitting as you tweak your model’s hyperparameters.
How does this work?
With the Flatten block, the points are drawn in a 3D space with the value for each axis coming from one of the features. For example, let’s say you chose average acceleration X, average acceleration Y, and average acceleration Z as your axes, and a sample had the following values for those features:- Avg accX = -0.24
- Avg accY = 0.17
- Avg accZ = -9.81
Questions?
If you have any questions about the feature explorer, we’d be happy to help on the forums, or reach out to your solutions engineer.Legacy 3D feature explorer
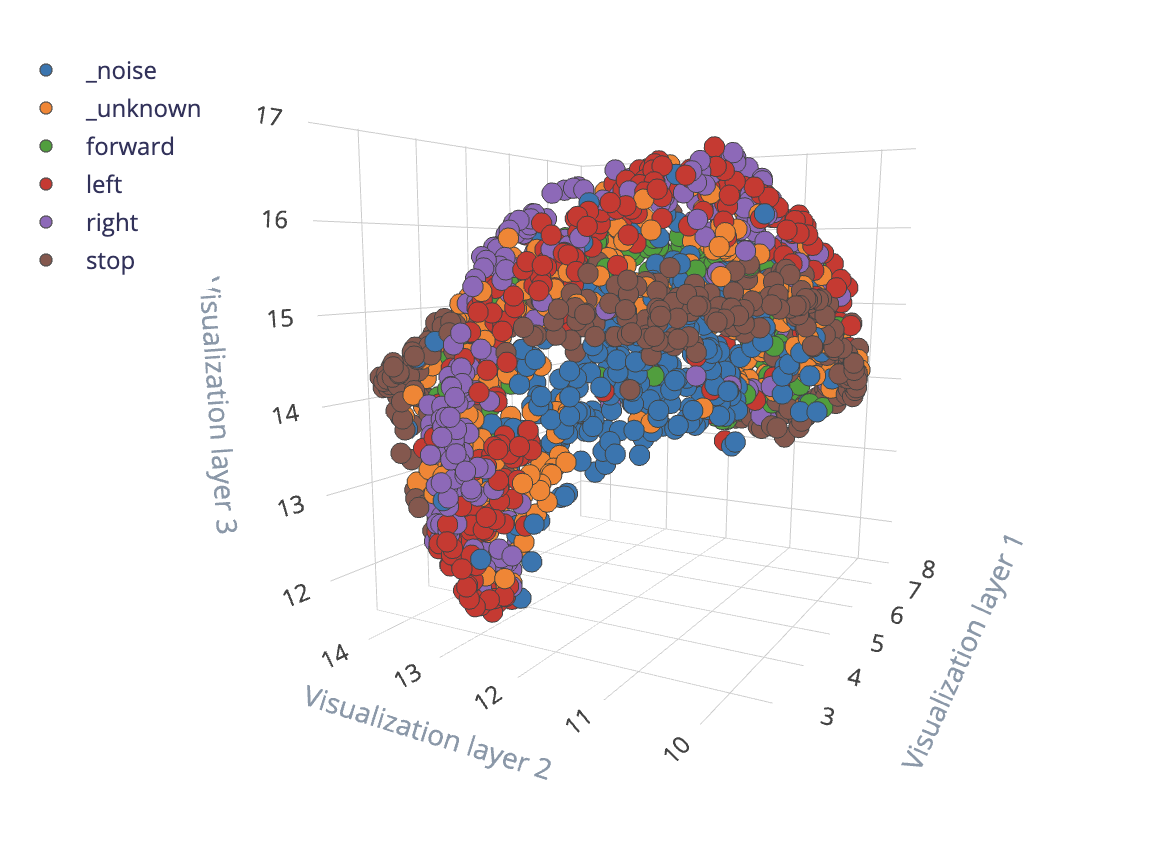
Older versions of Edge Impulse used a 3D viewer with UMAP on non-Flatten blocks. This legacy feature explorer accomplished the same goal of performing dimensionality reduction to provide a visual representation of your extracted features. Because 2D images load faster on web pages than 3D models while retaining much of the same information, we switched to 2D images. However, if feature extraction was performed prior to this switch, some projects may still have 3D feature explorer plots.