Prerequisites
Labeling
To build a regression model you collect data as usual, but rather than setting the label to a text value, you set it to a numeric value.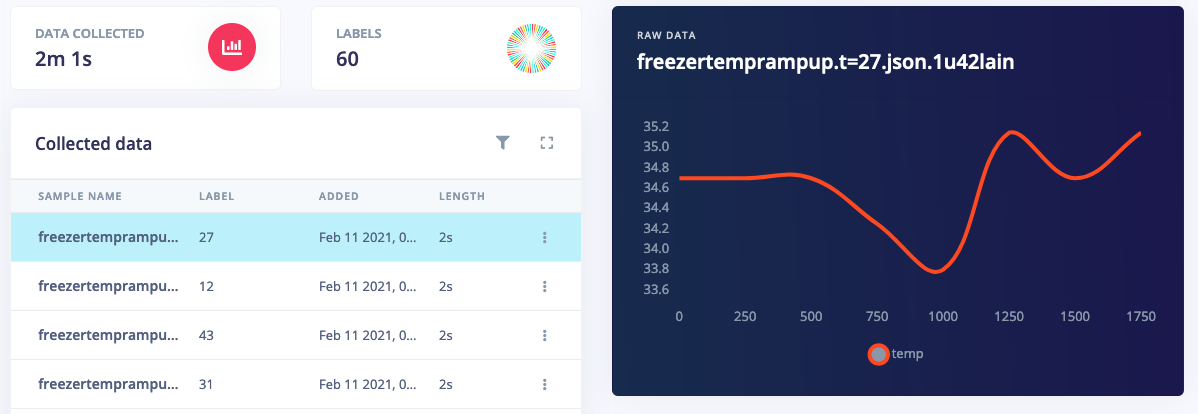
Regression data samples labeled with numerical values
Processing blocks
You can use any of the built-in signal processing blocks to pre-process your vibration, audio or image data, or use custom processing blocks to extract novel features from other types of sensor data.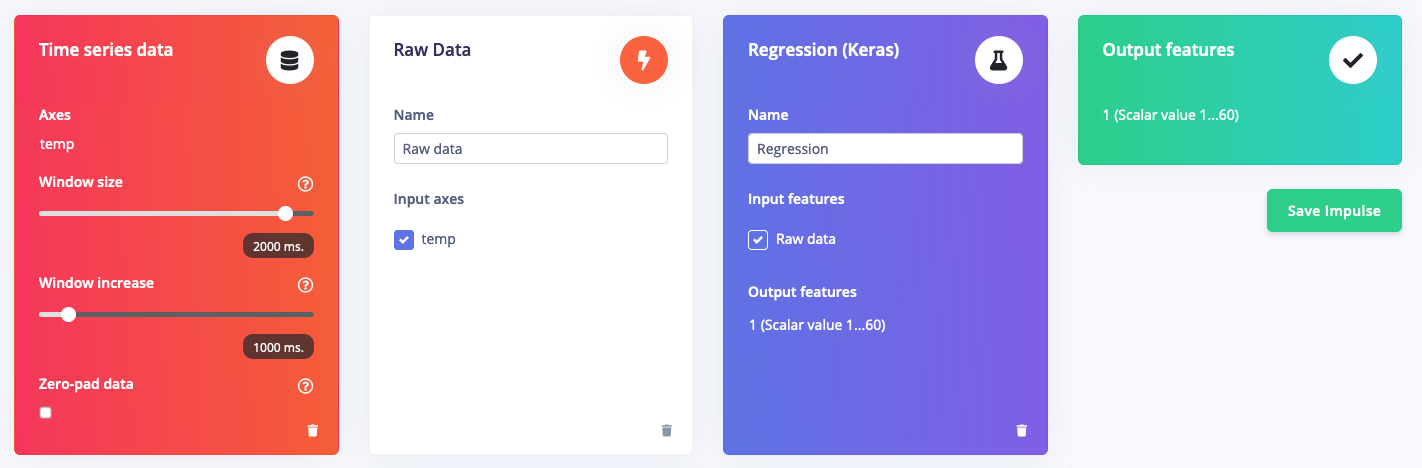
An impulse with a regression block
Train your regression block
You have full freedom in modifying your neural network architecture - whether visually or through writing Keras code.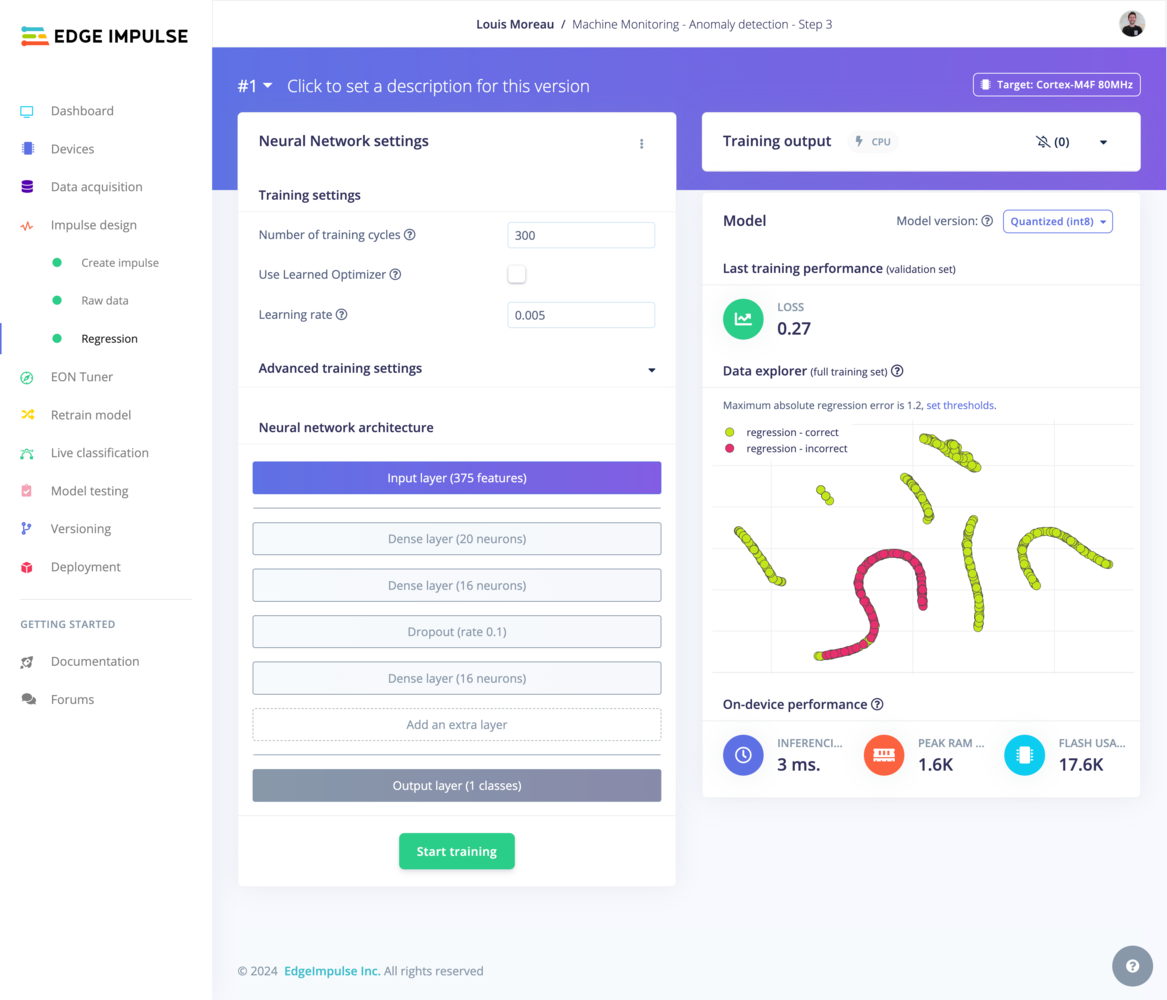
Regression view
Neural Network settings
See Neural Network Settings on the Learning Block page.Neural Network architecture
See Neural Network Architecture on the Learning Block page.Expert mode
See Expert mode on the Learning Block page.Test your regression model
If you want to see the accuracy of your model across your test dataset, go to Model testing. You can adjust the Maximum error percentage by clicking on the ”⋮” button.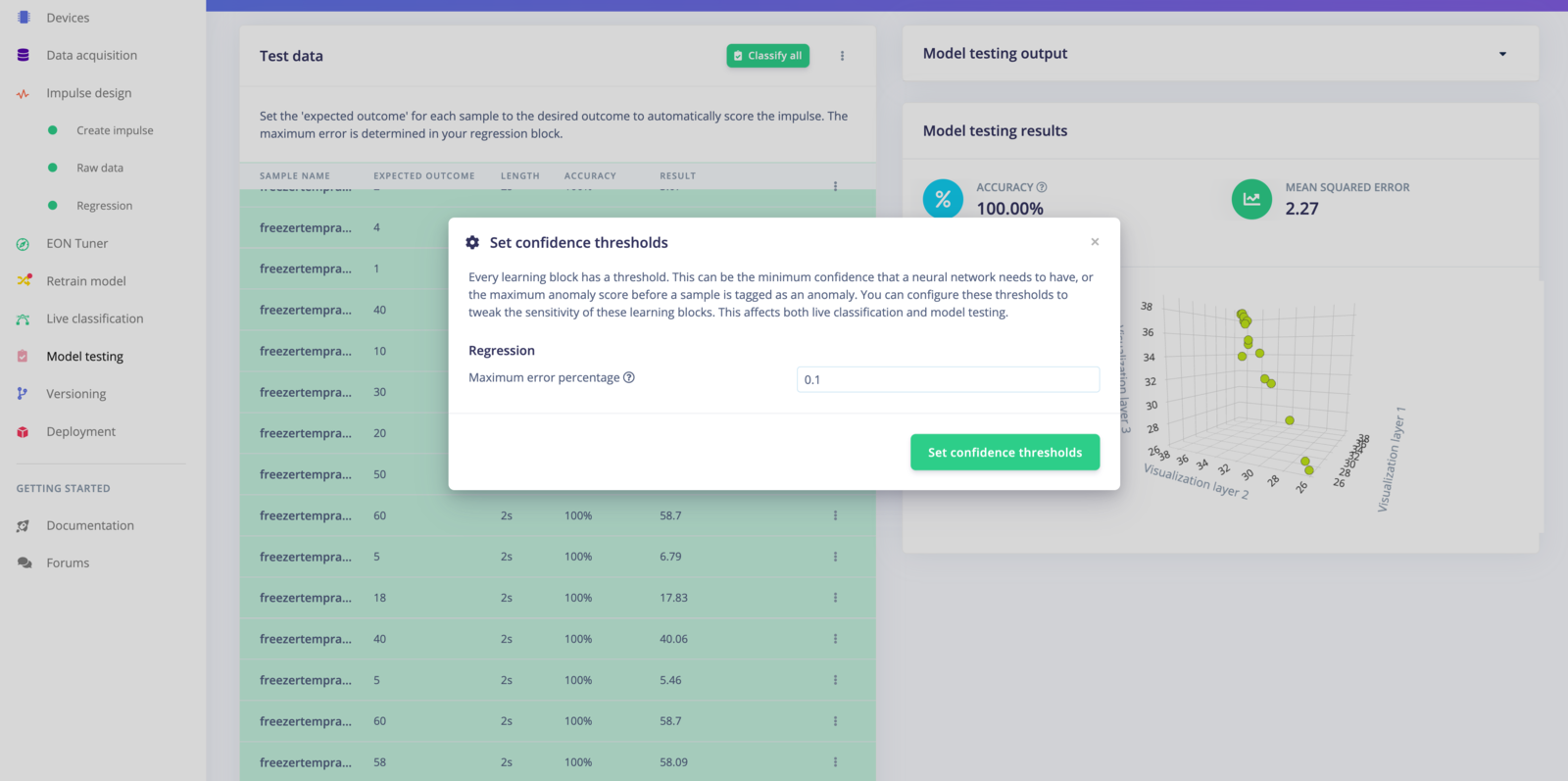
Testing regression model