WARNING: This notebook will add and delete data in your Edge Impulse project, so be careful! We recommend creating a throwaway project when testing this notebook.To start, create a new project in Edge Impulse. Do not add any data to it.
ei.API_KEY value in the following cell:
Upload dataset
We start by downloading the continuous motion dataset and uploading it to our project.Run the Tuner
To start, we need to list the possible target devices we can use for profiling. We need to pick from this list.start_tuner() and wait for completion via check_tuner(). In this example, we configure the tuner to target for the cortex-m4f-80mhz device. Since we want to classify the motion, we choose classification for our classifcation_type and our dataset as motion continuous. We constrain our model to a latency of 100ms for running the impulse.
NOTE: We set the max trials to 3 here. In a real life situation, you will omit this so the tuner decides the best number of trials.Once the tuner is done, you can print out the results to determine the best combination of blocks and hyperparameters.
Print EON Tuner results
To visualize the results of the tuner trials, you can head to the project page on Edge Impulse Studio. Alternatively, you can access the results programmatically: the configuration settings and output of the EON Tuner is stored in the variablestate. You can access the results of the various trials with state.trials. Note that some trials can fail, so it’s a good idea to test the status of each trial.
From there, you will want to sort the results based on some metric. In this example, we will sort based on int8 test set accuracy from highest to lowest.
Note: Edge Impulse supports only one learning block per project at this time (excluding anomaly detection blocks). As a result, we will use the first learning block (e.g. learning_blocks[0]) in the list to extract metrics.
Note: we assume the first learning block has the metrics we care about.
Graph results
You can optionally use a plotting package like matplotlib to graph the results from the top results to compare the metrics.Results as a DataFrame
If you have pandas installed, you can make the previous section much easier by reporting metrics as a DataFrame.Set trial as impulse and deploy
We can replace the current impulse with the top performing trial from the EON Tuner. From there, we can deploy it, just like we would any impulse.'zip' from the above list. To do that, we first need to create a Classification object which contains our label strings (and other optional information about the model). These strings will be added to the C++ library metadata so you can access them in your edge application.
Note that instead of writing the raw bytes to a file, you can also specify an output_directory argument in the .deploy() function. Your deployment file(s) will be downloaded to that directory.
Important! The deployment targets list will change depending on the values provided for model, model_output_type, and model_input_type in the next part. For example, you will not see openmv listed once you upload a model (e.g. using .profile() or .deploy()) if model_input_type is not set to ei.model.input_type.ImageInput(). If you attempt to deploy to an unavailable target, you will receive the error Could not deploy: deploy_target: .... If model_input_type is not provided, it will default to OtherInput. See this page for more information about input types.
Configure custom search space
By default, the EON Tuner will make a guess at a search space based on the type of data you uploaded (e.g. using spectral-analysis blocks for feature extraction). As a result, you can run the tuner without needing to construct a search space. However, you may want to define your own search space. The best way to define a search space is to open your project (after uploading data), head to the EON Tuner page, click Run EON Tuner, and select the Space tab.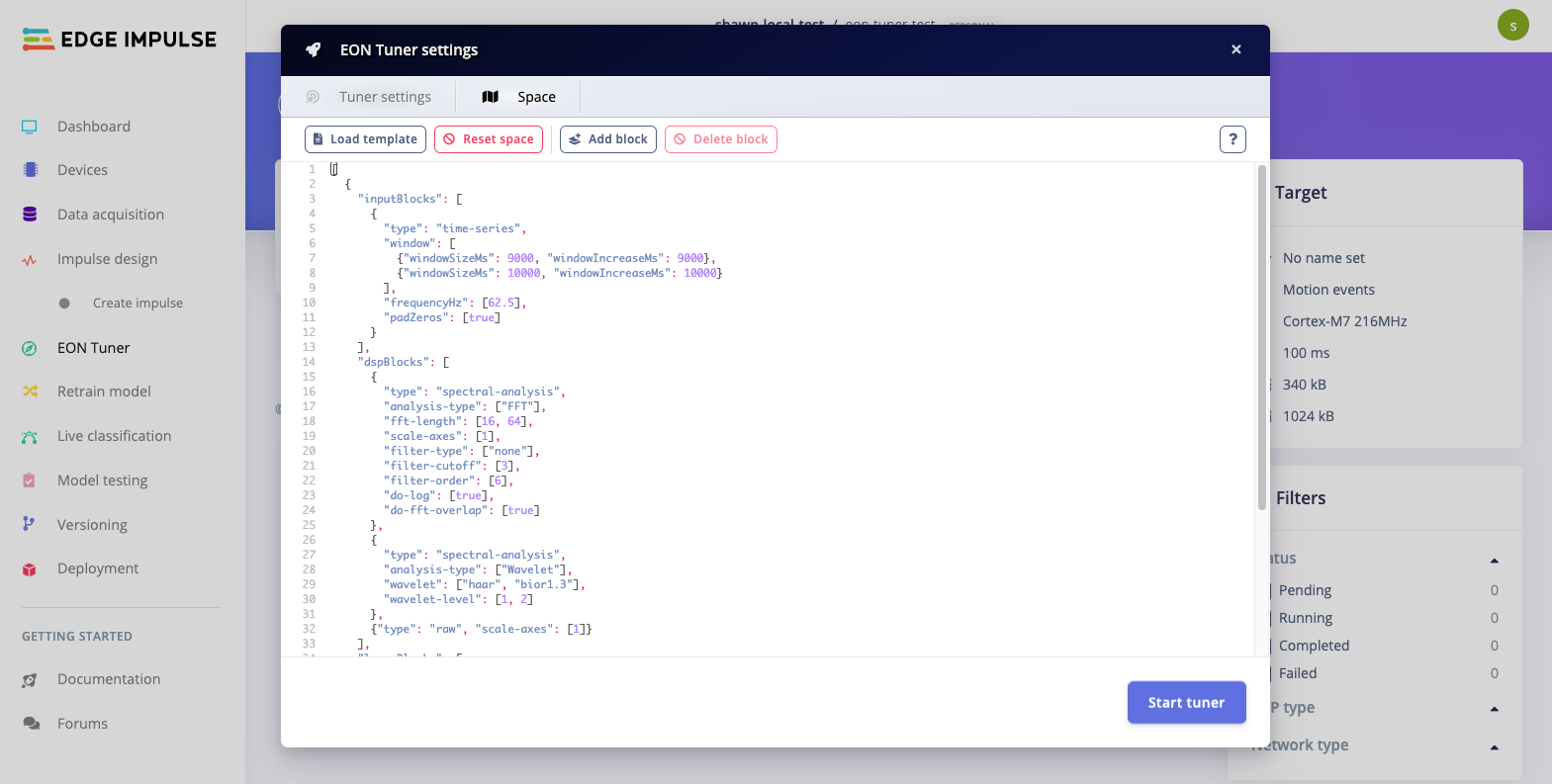
Note: Functions to get available blocks and search space parameters coming soon