This tutorial is for advanced users. We will provide limited support on the forum until this feature is fully integrated into the platform. If you have subscribed to an Enterprise plan, you can contact our customer success or solution engineering team.
Multi-impulse vs multi-model vs sensor fusionRunning multi-impulse refers to running two separate projects (different data, different DSP blocks and different models) on the same target. It will require modifying some files in the EI-generated SDKs.Running multi-model refers to running two different models (same data, same DSP block but different tflite models) on the same target. See how to run a motion classifier model and an anomaly detection model on the same device in this tutorial.Sensor fusion refers to the process of combining data from different types of sensors to give more information to the neural network. See how to use sensor fusion in this tutorial.
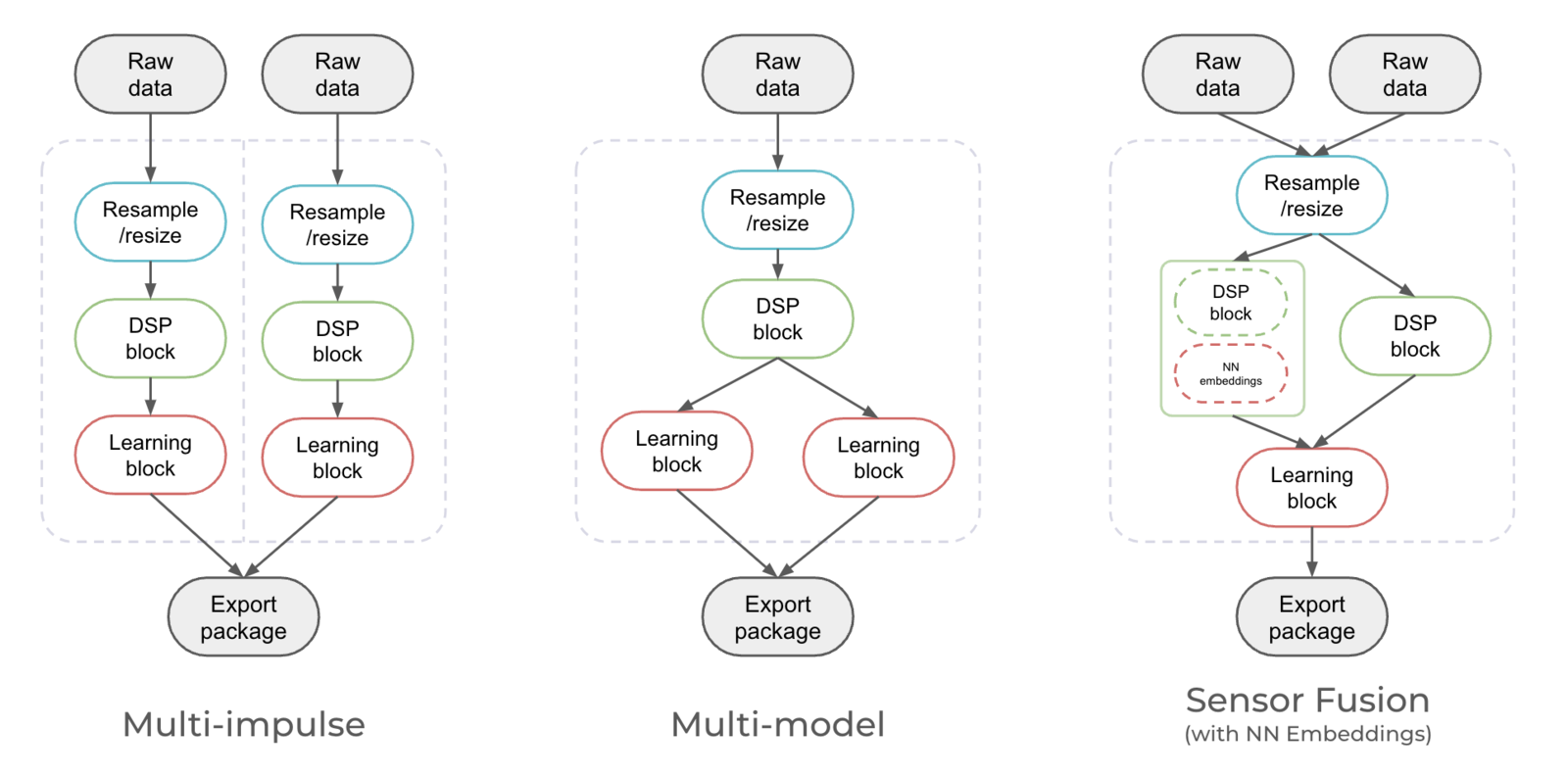
Multi-impulse vs Multi-model vs Sensor Fusion
Examples
Make sure you have at least two impulses fully trained. You can use one of the following examples:Audio + Image classification
Audio + Image classification
This example can be used for an intrusion detection system. We will use a first model to detect glass-breaking sounds, if we detected this sound, we will then classify an image to see if there is a person or not in the image. In this tutorial, we will use the following public projects:
Merge multiple impulses into a single C++ Library
The source code and the generator script can be found here. By default, the quantized version is used when downloading the C++ libraries. To use float32, add the option--float32 as an argument.
Similarly by default the EON compiled model is used, if you want to use full tflite then add the option --full-tflite and be sure to include a recent version of tensorflow lite compiled for your device architecture in the root of your project in a folder named tensorflow-lite
If you need a mix of quantized and float32, you can look at the dzip.download_model function call in generate.py and change the code accordingly.
By default, the block will download cached version of builds. You can force new builds using the --force-build option.
Locally
Retrieve API Keys of your projects and run the generate.py command as follows:Docker
Build the container:Custom deployment block
Initialize the custom block - select Deployment block and Library when prompted:- CLI arguments:
--api-keys ei_0b0e...,ei_acde... - Privaliged mode: Enabled
Understanding the process
If you have a look at thegenerate.py script, it streamline the process of generating a C++ library from multiple impulses through several steps:
- Library Download and Extraction:
- If the script detects that the necessary projects are not already present locally, it initiates the download of C++ libraries required for edge deployment. These libraries are fetched using API keys provided by the user.
- Libraries are downloaded and extracted into a temporary directory. If the user specifies a custom temporary directory, it’s used; otherwise, a temporary directory is created.
- Customization of Files:
- At the file name level:
- It adds a project-specific suffix to certain patterns in compiled files within the
tflite-modeldirectory. This customization ensures that each project’s files are unique. - Renamed files are then copied to a target directory, mainly the first project’s directory.
- It adds a project-specific suffix to certain patterns in compiled files within the
- At the function name level:
- It edits
model_variables.hfunctions by adding the project-specific suffix to various patterns. This step ensures that model parameters are correctly associated with each project.
- It edits
- Merging the projects
model_variables.his merged into the first project’s directory to consolidate model information.- The script saves the intersection of lines between
trained_model_ops_define.hfiles for different projects, ensuring consistency.
- Copying Templates:
- The script copies template files from a
templatesdirectory to the target directory. The template available includes files with code structures and placeholders for customization. It’s adapted from the example-standalone-inferencing example available on Github.
- Generating Custom Code:
- The script retrieves impulse IDs from
model_variables.hfor each project. Impulses are a key part of edge machine learning models. - Custom code is generated for each project, including functions to get signal data, define raw features, and run the classifier.
- This custom code is inserted into the
main.cppfile of each project at specific locations.
- Archiving for Deployment:
- Finally, the script archives the target directory, creating a zip file ready for deployment. This zip file contains all the customized files and code necessary for deploying machine learning models on edge devices.
Compiling and running the multi-impulse library
Now to test the library generated:- Download and unzip your Edge Impulse C++ multi-impulse library into a directory
- Copy a test sample’s raw features into the
features[]array in source/main.cpp - Enter
make -jin this directory to compile the project. If you encounter any OOM memory error trymake -j4(replace 4 with the number of cores available) - Enter
./build/appto run the application - Compare the output predictions to the predictions of the test sample in the Edge Impulse Studio
Want to add your own business logic?
You can change the template you want to use in step 4 to use another compilation method, implement your custom sampling strategy and how to handle the inference results in step 5 (apply post-processing, send results somewhere else, trigger actions, etc.).Limitations
General limitations:- The custom ML accelerator deployments are unlikely to work (TDA4VM, DRPAI, MemoryX, Brainchip).
- The custom tflite kernels (ESP NN, Silabs MVP, Arc MLI) should work - but may require some additional work. I.e: for ESP32 you may need to statically allocate arena for the image model.
- In general, running multiple impulses on an MCU can be challenging due to limited processing power, memory, and other hardware constraints. Make sure to thoroughly evaluate the capabilities and limitations of your specific MCU and consider the resource requirements of the impulses before attempting to run them concurrently.
model_metadata.h comes from the first API Key of your project. This means some #define statement might be missing or conflicting.
-
Object detection: If you want to run at least one Object Detection project. Make sure to use this project API KEY first! This will set the
#define EI_CLASSIFIER_OBJECT_DETECTION 1and eventually the#define EI_HAS_FOMO 1. Note that you can overwrite them manually but it requires an extra step. -
Anomaly detection: If your anomaly detection model API Key is not in the first position, the
model-parameter/anomaly_metadata.hfile will not be included. -
Visual anomaly detection AND time-series anomaly detection (K-Means or GMM): It is not possible to combine two different anomaly detection models. The
#define EI_CLASSIFIER_HAS_ANOMALYstatement expect ONLY one of the following argument:
Troubleshooting
Segmentation fault
If you see the following segmentation fault, make sure to subtract and merge the trained_model_ops_define.h or tflite_resolver.hFileExistsError: [Errno 17] File exists
If you see an error like the following, you probably used twice the same API Key:Manual procedure
When we first wrote this tutorial, we explained how to merge two impulses manually; This process is now deprecated due to recent changes in our C++ SDK, some files and functions may have been renamed.See the legacy steps
See the legacy steps
Download the impulses from your projects
Head to your projects’ deployment pages and download the C++ libraries:
Deployment page of the glass-breaking project
multi-impulse for example).Rename the tflite model files
Rename the tflite model files:Go to thetflite-model directory in your extracted archives and rename the following files by post-fixing them with the name of the project:- for EON compiled projects:
tflite_learn_[block-id]_compiled.cpp/tflite_learn_[block-id]_compiled.h. - for non-EON-compiled projects:
tflite_learn_[block-id].cpp/tflite_learn_[block-id].h.
Rename the variables in the tflite-model directory
Rename the variables (EON model functions, such as trained_model_input etc. or tflite model array names) by post-fixing them with the name of the project.e.g: Change thetrained_model_compiled_audio.h from:tflite-model/tflite_learn_[block-id]_compiled.htflite-model/tflite_learn_[block-id]_compiled.cpp
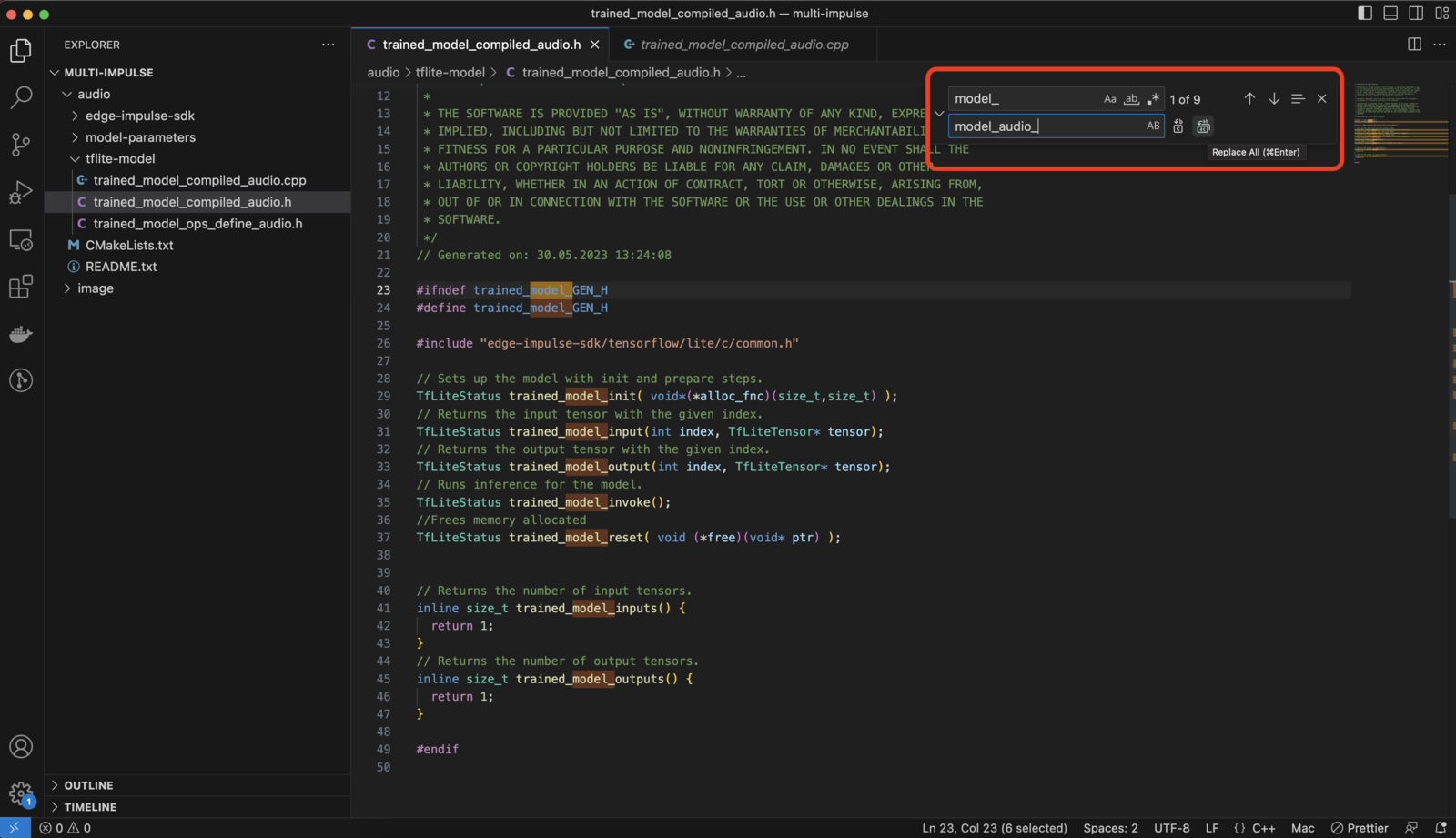
Visual Studio find and replace
Rename the variables and structs in model-parameters/model_variables.h
Be careful here when using the “find and replace” from your IDE, NOT all variables looking like _model_ need to be replaced.Example for the audio project:Merge the files
Create a new directory (merged-impulse for example). Copy the content of one project into this new directory (audio for example). Copy the content of the tflite-model directory from the other project (image) inside the newly created merged-impulse/tflite-model.The structure of this new directory should look like the following:Merge the variables and structs in model_variables.h
Copy the necessary variables and structs from previously updatedimage/model_metadata.h file content to the merged-impulse/model_metadata.h.To do so, include both of these lines in the #include section:const char* ei_classifier_inferencing_categories... to the line before const ei_impulse_t ei_default_impulse = impulse_<ProjectID>_<version>.Make sure to leave only one const ei_impulse_t ei_default_impulse = impulse_233502_3; this will define which of your impulse is the default one.Subtract and merge the trained_model_ops_define.h or tflite_resolver.h
Make sure the macrosEI_TFLITE_DISABLE_... are a COMBINATION of the ones present in two deployments.For EON-compiled projects:E.g. if #define EI_TFLITE_DISABLE_SOFTMAX_IN_U8 1 is present in one deployment and absent in the other, it should be ABSENT in the combined trained_model_ops_define.h.For non-EON-Compiled projects:E.g. if resolver.AddFullyConnected(); is present in one deployment and absent in the other, it should be PRESENT in the combined tflite-resolver.h. Remember to change the length of the resolver array if necessary.In this example, here are the lines to deleted: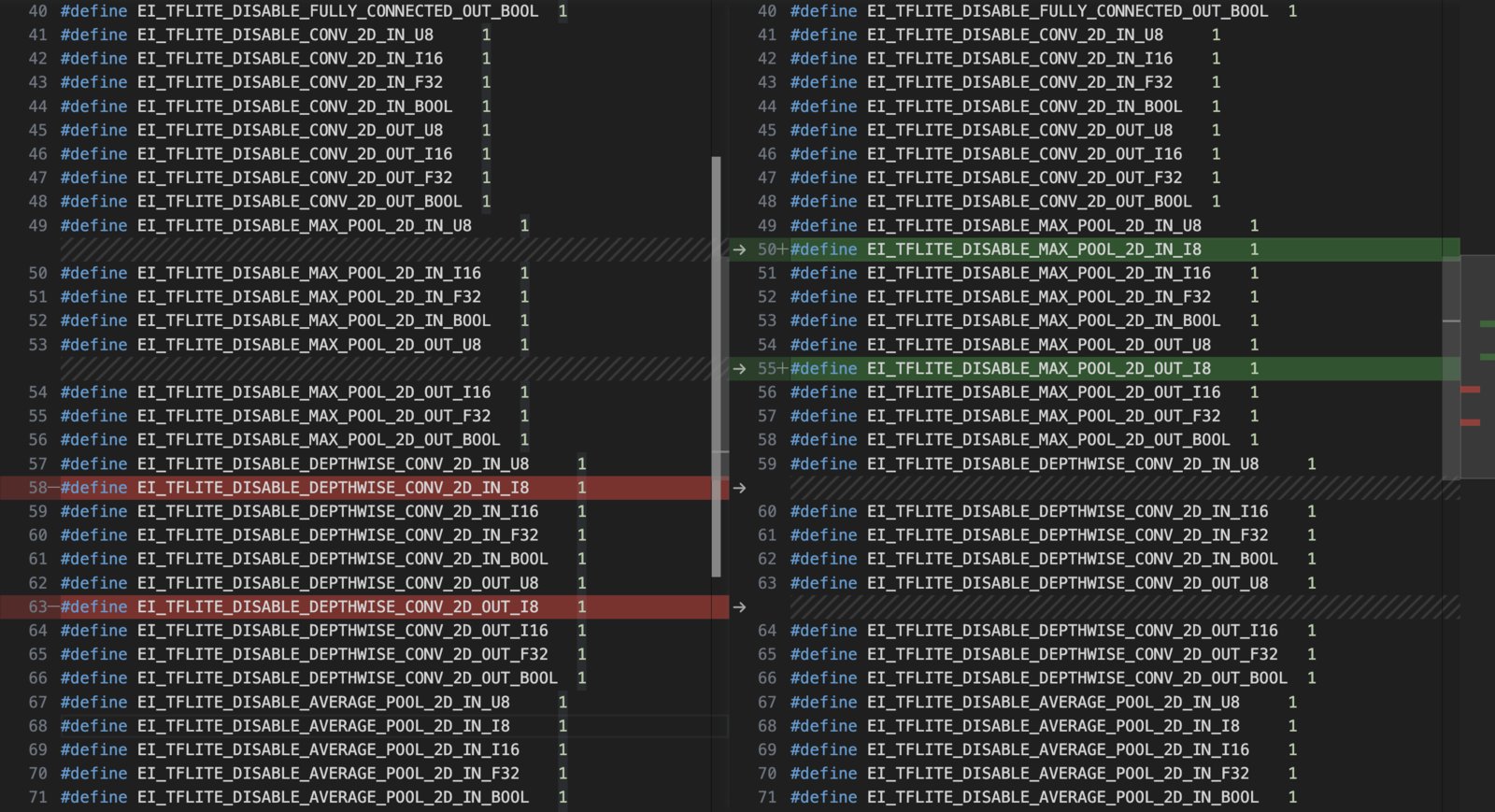
diff trained_model_ops_define.h