What is audio feature extraction?
Audio feature extraction involves transforming raw audio signals into a set of meaningful features that can be used for further processing or analysis, including training Edge AI models. These features capture essential characteristics of the audio signal, such as its frequency content, amplitude, and temporal dynamics.Why is audio feature extraction important?
Raw audio data is often too complex and voluminous to be directly used for machine learning tasks. Feature extraction simplifies the audio signal, making it easier to analyze and interpret. This process helps in reducing the dimensionality of the data while retaining the most informative aspects, improving the performance of machine learning models, especially in Edge AI applications where computational resources are limited.Audio features extraction techniques with Edge Impulse
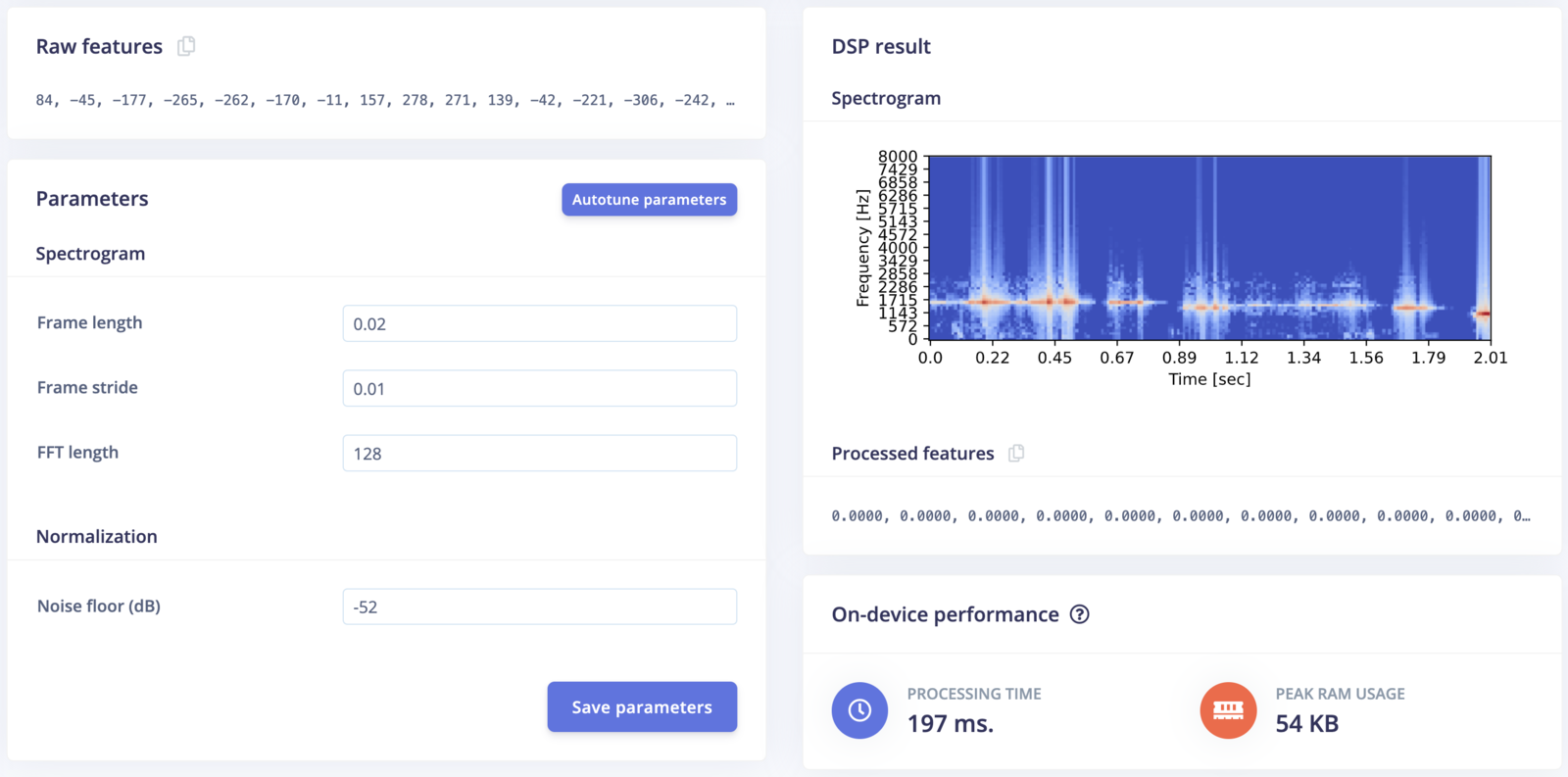
Edge Impulse offers several pre-processing blocks to extract key audio features, simplifying the development process for Edge AI applications:- Spectrogram: A visual representation of the spectrum of frequencies in a signal as it varies with time. It helps in understanding how the energy of the signal is distributed across different frequencies. See the Spectrogram pre-processing block in Edge Impulse.
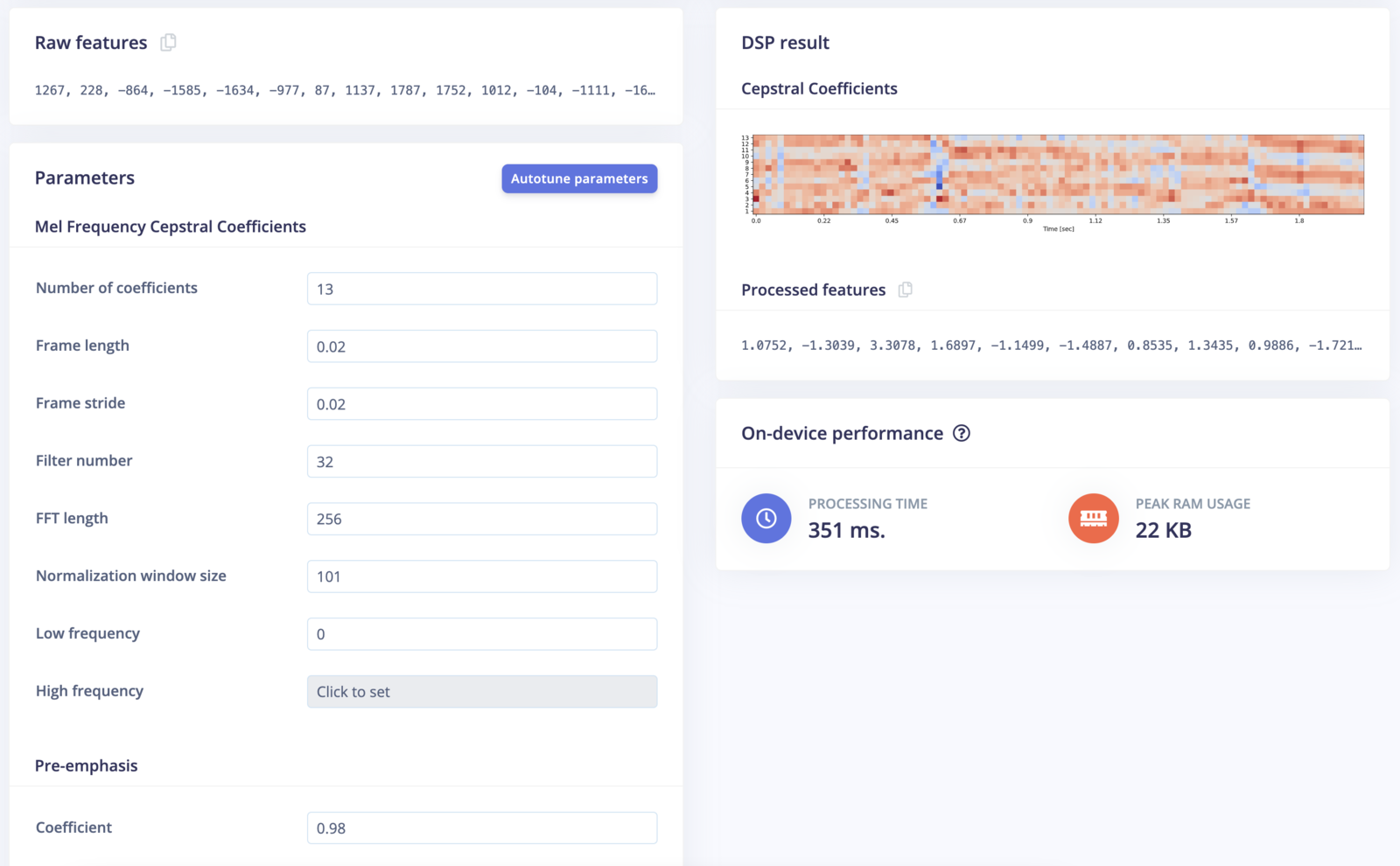
- Mel-Frequency Cepstral Coefficients (MFCC): Represent the short-term power spectrum of a sound, widely used in speech and audio processing due to their effectiveness in capturing the phonetically relevant characteristics of the audio signal. See the MFCC block in Edge Impulse.
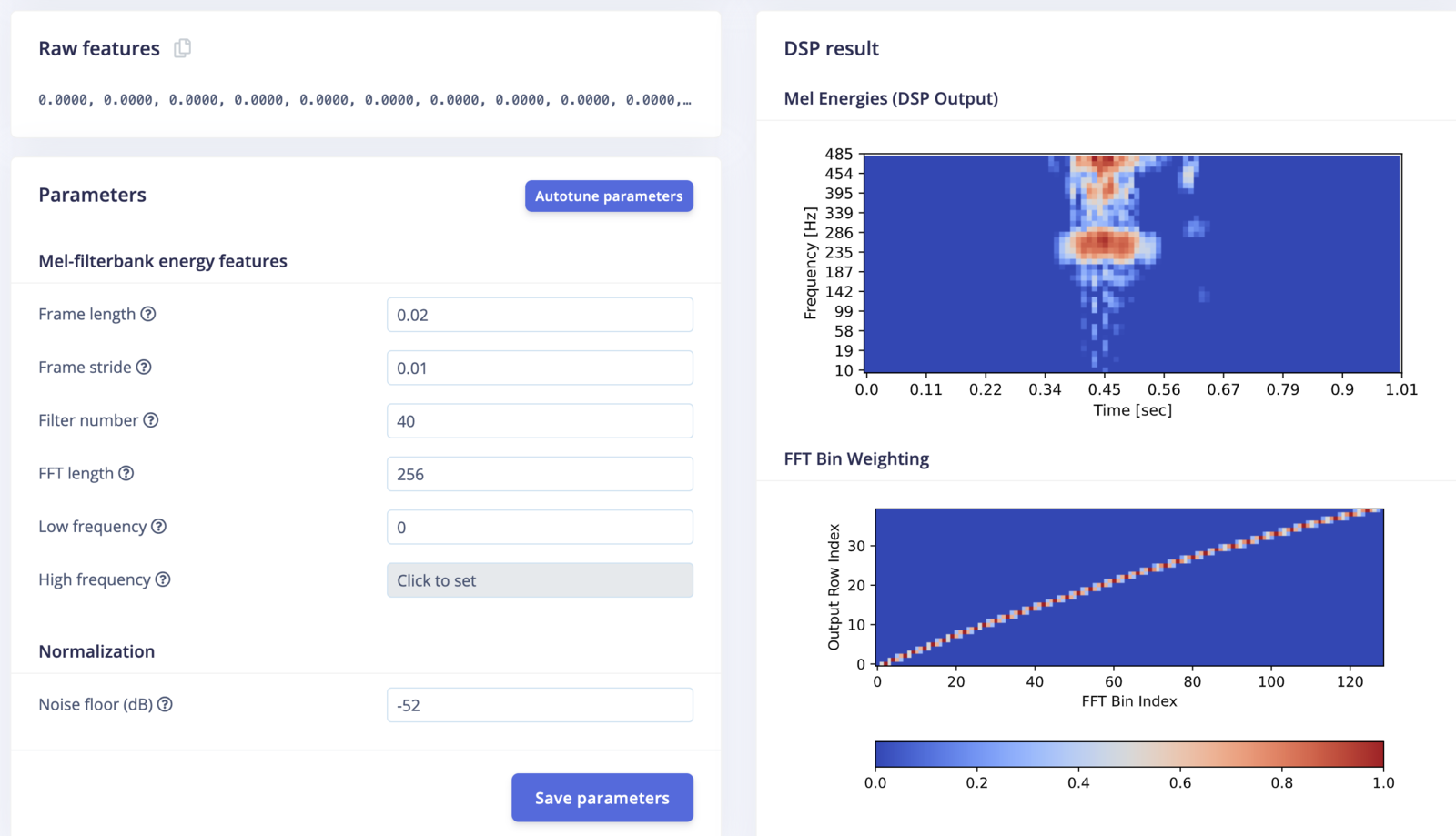
- Mel-filterbank Energy (MFE): Similar to MFCCs but focuses on the energy in different frequency bands, providing a simpler yet powerful representation of the audio signal. See the MFE block in Edge Impulse.
- Spectrogram
- MFCC
- MFE
Other resources
Tutorials:- Keyword Spotting: Keyword spotting
- Continuous Audio Classification: Sound recognition