Only available on the Enterprise planThis feature is only available on the Enterprise plan. Review our plans and pricing or sign up for our free expert-led trial today.
| File Name | Description |
|---|---|
| S1_activity.csv | Data containing labels of the activities. |
| S1_quest.csv | Data from the questionnaire, detailing the subjects’ attributes. |
| ACC.csv | Data from 3-axis accelerometer sensor. The accelerometer is configured to measure acceleration in the range [-2g, 2g]. Therefore, the unit in this file is 1/64g. Data from x, y, and z axis are respectively in the first, second, and third column. |
| BVP.csv | Blood Volume Pulse (BVP) signal data from photoplethysmograph. |
| EDA.csv | Electrodermal Activity (EDA) data expressed as microsiemens (μS). |
| tags.csv | Tags for the data, e.g., Stairs, Soccer, Cycling, Driving, Lunch, Walking, Working, Clean Baseline, No Activity. |
| HR.csv | Heart Rate (HR) data, as measured by the wearable device. Average heart rate extracted from the BVP signal. The first row is the initial time of the session expressed as a Unix timestamp in UTC. The second row is the sample rate expressed in Hz. |
| IBI.csv | Inter-beat Interval (IBI) data. Time between individual heartbeats extracted from the BVP signal. No sample rate is needed for this file. The first column is the time (relative to the initial time) of the detected inter-beat interval expressed in seconds (s). The second column is the duration in seconds (s) of the detected inter-beat interval (i.e., the distance in seconds from the previous beat). |
| TEMP.csv | Data from temperature sensor expressed in degrees on the Celsius (°C) scale. |
| info.txt | Metadata about the participant, e.g., Age, Gender, Height, Weight, BMI. |
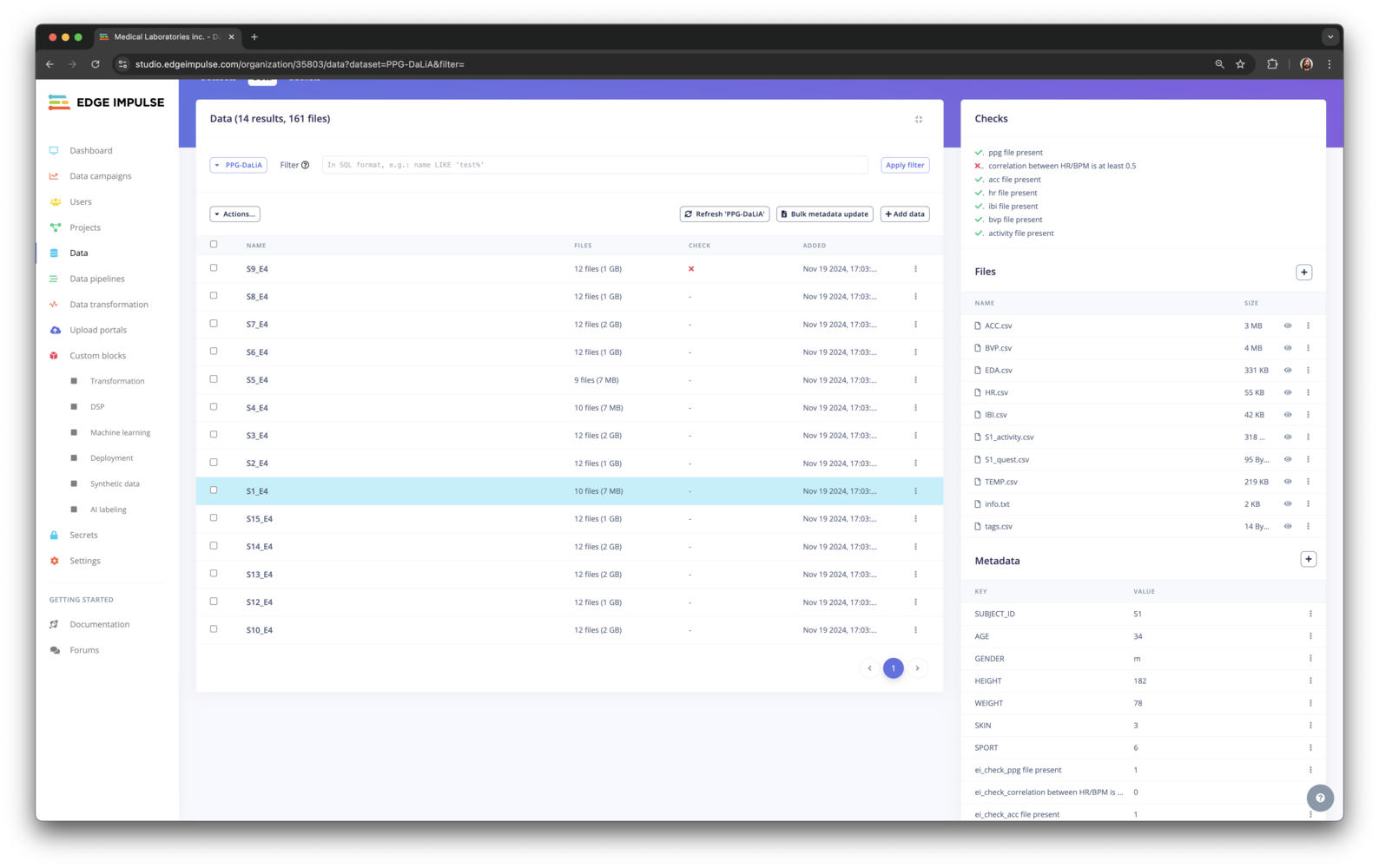
- Initial subject files (ACC.csv, BVP.csv, EDA.csv, HR.csv, IBI.csv, TEMP.csv, info.txt, S1_activity.csv, tags.csv) live in the company data lake in S3. The data lake uses an internal structure with non-human readable IDs for each participant (e.g. Subject 1 as
S1_E4for anonymized data):
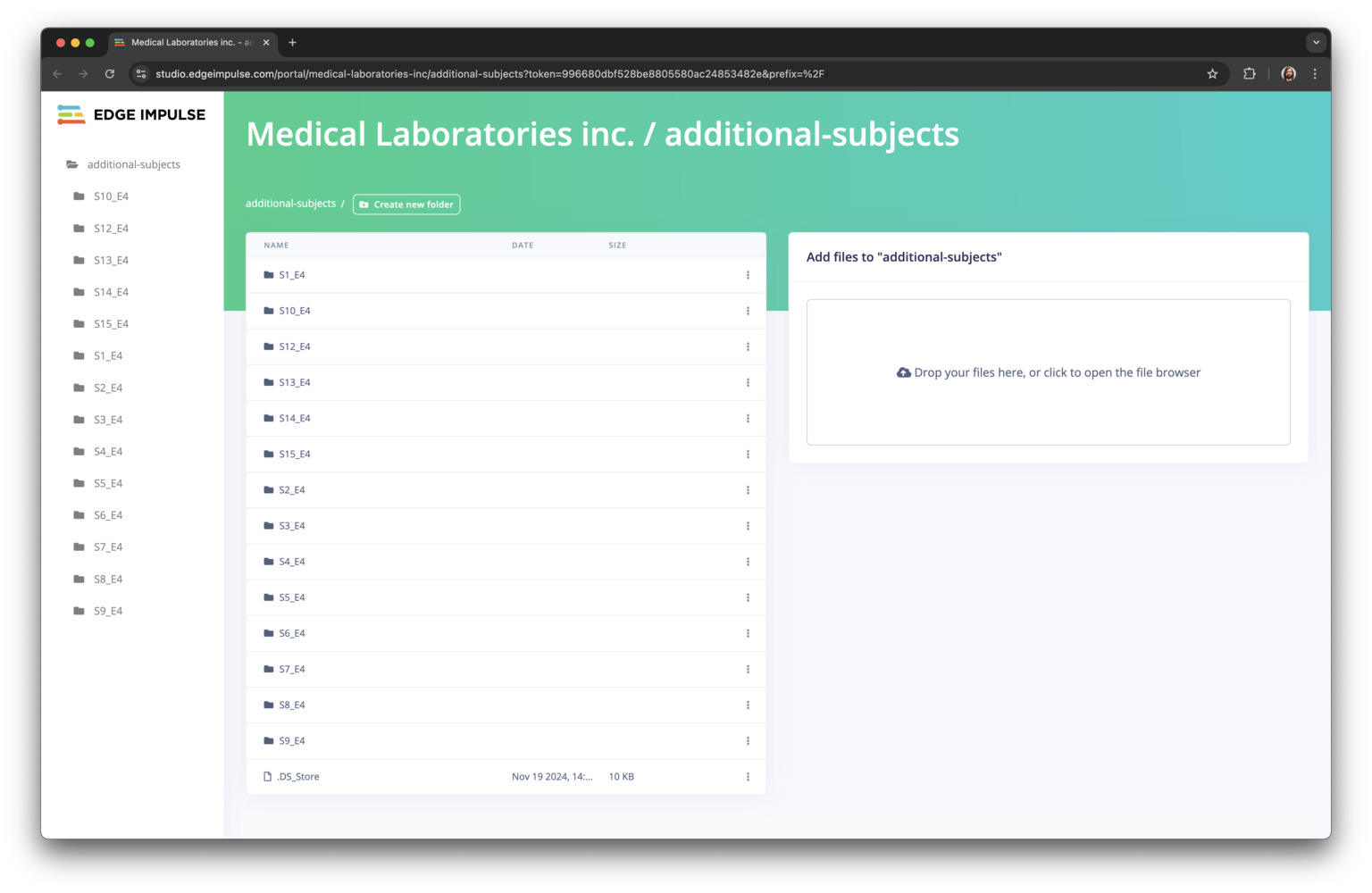
- Other files are uploaded by the research partner to an upload portal. The files are prefixed with the subject ID:
S2_E4 indicating that this data is from the second subject in the study, or prefixing the files with S2_ (e.g. S2_activity.csv).
Anonymizing your data (optional)
This is a manual step that some countries regulations may require, this example is for reference, but not needed or used in this example. To create the mapping between the study ID, subjects name, and the internal data lake ID we can use a study master sheet. It contains information about all participants, ID mapping, and metadata. E.g.:Configuring a storage bucket for your dataset
Data is stored in cloud storage buckets that are hosted in your own infrastructure. To configure a new storage bucket, head to your organization, choose Data > Buckets, click Add new bucket, and fill in your access credentials. For additional details, refer to Cloud data storage. Our solution engineers are also here to help you set up your buckets.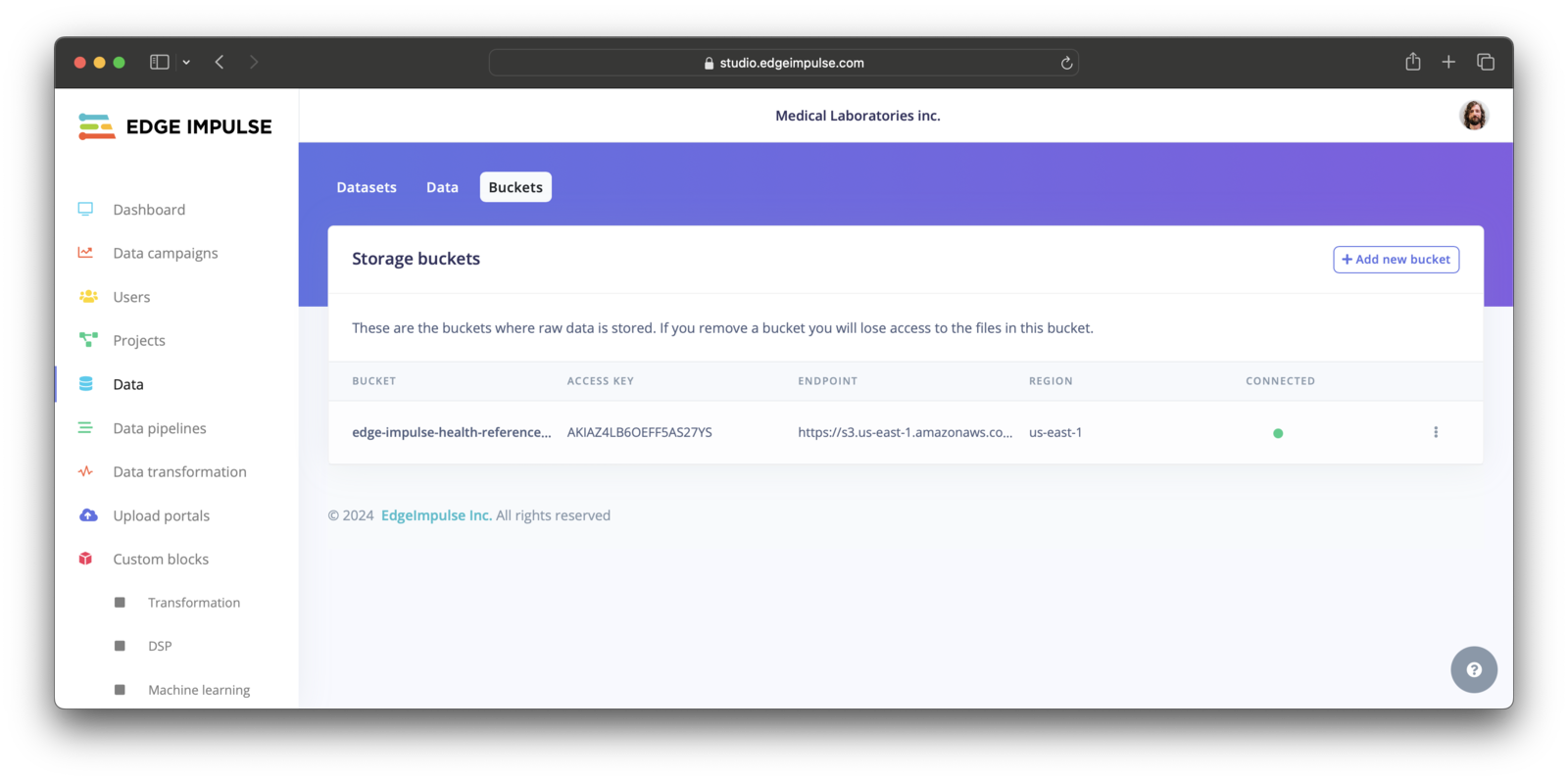
About datasets
With the storage bucket in place you can create your first dataset. Datasets in Edge Impulse have three layers: Datasets in Edge Impulse have three layers:- Dataset: A larger set of data items grouped together.
- Data item: An item with metadata and Data file attached.
- Data file: The actual files.
Adding research data to your organization
There are three ways of uploading data into your organization. You can either:- Upload data directly to the storage bucket (recommended method). In this case use Add data… > Add dataset from bucket and the data will be discovered automatically.
- Upload data through the Edge Impulse API.
- Upload the files through the Upload Portals.
Sorter and combiner
Sorter
The sorter is the first step of the research pipeline. Its job is to fetch the data from all locations (here: internal data lake, portal, metadata from study master sheet) and create a research dataset in Edge Impulse. It does this by:-
Creating a new structure in S3 like this:
-
Syncing the S3 folder with a research dataset in your Edge Impulse organization (like
PPG-DaLiA Activity Study 2024). -
Updating the metadata with the metadata from the master sheet (
Age,BMI, etc…). Read on how to add and sync S3 data
Combiner
With the data sorted we then:- Need to verify that the data is correct (see validate your research data)
- Combine the data into a single Parquet file. This is essentially the contract we have for our dataset. By settling on a standard format (strong typed, same column names everywhere) this data is now ready to be used for ML, new algorithm development, etc. Because we also add metadata for each file here we’re very quickly building up a valuable R&D datastore.
No required format for data files
There is no required format for data files. You can upload data in any format, whether it’s CSV, Parquet, or a proprietary data format.Parquet is a columnar storage format that is optimized for reading and writing large datasets. It is particularly useful for data that is stored in S3 buckets, as it can be read in parallel and is highly compressed. That is why we are converting the data to Parquet in the transform block code.See Parquet for more information. or an example in our Create a Transform Block Doc