Overview
The dataset selected to use in this example is the PPG-DaLiA dataset, which includes 15 subjects performing 9 activities, resulting in a total of 15 recordings. See the CSV file summary here, and read more about it in the publishers website here, This dataset covers an activity study where data is recorded from a wearable end device (PPG + accelerometer), along with labels such as Stairs, Soccer, Cycling, Driving, Lunch, Walking, Working, Clean Baseline, and No Activity. The data is collected and validated, then written to a clinical dataset in an Edge Impulse organization, and finally imported into an Edge Impulse project where we train a classifier. The health reference design builds transformation blocks that sync clinical data, validate the dataset, query the dataset, and transform the data to process raw data files into a unified dataset.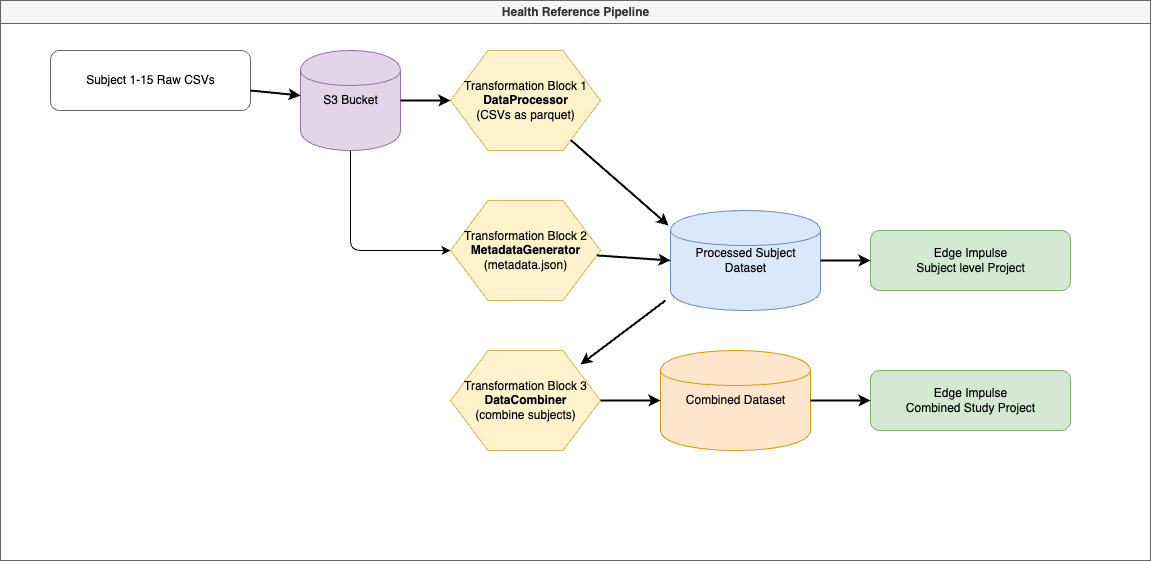
Health Reference Design Sections
This health reference design section helps you understand how to create a full clinical data pipeline by:- Synchronizing clinical data with a bucket: Collect and organize data from multiple sources into a sorted dataset.
- Validating clinical data: Ensure the integrity and consistency of the dataset by applying checklists.
- Querying clinical data: Explore and slice data using a query system.
- Transforming clinical data: Process and transform raw data into a format suitable for machine learning.
Bringing it all together
After you have completed the health reference design, you can go further by combining the individual transformation steps into a data pipeline. Refer to the following guide to learn how to build data pipelines:- Building data pipelines: Build pipelines to automate data processing steps.
- DataProcessor: Processes raw data files for each subject.
- MetadataGenerator: Extracts and attaches metadata to each subject’s data.
- DataCombiner: Merges all processed data into a unified dataset.
Data Pipeline Workflow
The data pipeline workflow for the Health Reference Design is as follows:Creating and Running the Pipeline in Edge Impulse
Now that all transformation blocks are pushed to Edge Impulse, you can create a pipeline to chain them together.Steps:
- Access Pipelines:
- In Edge Impulse Studio, navigate to your organization.
- Go to Data > Pipelines.
- Add a New Pipeline:
- Click on + Add a new pipeline.
- Name: PPG-DaLiA Data Processing Pipeline
- Description: Processes PPG-DaLiA data from raw files to a combined dataset.
- Configure Pipeline Steps:
- Paste the following JSON configuration into the pipeline steps:
Replace the transformationBlockId values with the actual IDs of your transformation blocks.
- Save the Pipeline.
- Run the Pipeline:
- Click on the ⋮ (ellipsis) next to your pipeline.
- Select Run pipeline now.
- Monitor Execution:
- Check the pipeline logs to ensure each step runs successfully.
- Address any errors that may occur.
- Verify Output:
- After completion, verify that the datasets (processed-dataset and combined-dataset) have been created and populated.
Next Steps
After the pipeline has successfully run, you can import the combined dataset into an Edge Impulse project to train a machine learning model. If you didn’t complete the pipeline, don’t worry, this is just a demonstration. However, you can still import the processed dataset from our HRV Analysis tutorial to train a model. Refer to the following guides to learn how to import datasets into Edge Impulse:- HRV Analysis: Analyze Heart Rate Variability (HRV) data.
- Activity Recognition: Classify activities using accelerometer data.
- MLOps: Implement MLOps practices in your workflow.