Only available on the Enterprise planThis feature is only available on the Enterprise plan. Review our plans and pricing or sign up for our free expert-led trial today.
Classical machine learning (ML) refers to traditional algorithms in machine learning that predate the current wave of deep learning. Deep learning usually involves large, complex neural networks. Classical ML techniques include various algorithms, such as logistic regression, support vector machines (SVMs), and decision trees. However, these techniques rely heavily on feature engineering to work well.Deep neural networks can discover or create features from the raw data automatically, but classical ML models often require human domain knowledge expertise to generate these features. This is where Edge Impulse can help! We offer a number of processing blocks to help generate features based on various use cases. You can also perform autoML with EON Tuner to see which combinations of processing and machine learning (including classical ML) blocks work best for your dataset.Traditional ML models are often easier to understand and interpret than their deep learning cousins. The simpler algorithms and structures used in traditional models make it easier to understand the relationship between input features and output predictions.We implement these modules using scikit-learn, which is an extremely popular ML package used in the creation of models for real-world applications. Once trained, models are converted to Jax, a linear algebra library. That model is then converted to a LiteRT (previously Tensorflow Lite) (float 32) model, which will run on a variety of platforms.The ability to convert Jax to LiteRT (previously Tensorflow Lite) models opens up a wide variety of possibilities when it comes to deploying different machine learning models to edge devices. If you are interested in developing a custom learning block, see here. You can also use this scikit-learn custom learning block source code as a starting point.You can select one of several algorithms depending on your project type: classification or regression. Here is a quick reminder about the difference between the two types:
Classification is used when you want to identify a sample as belonging to one particular grouping. It requires the number of possible outputs to be a discrete number. For example, classification is used if you want to determine if a picture is of a dog or a cat (2 possible outputs).
Regression is used to predict a continuous value based on the input data. For example, predicting the price of a house based on location, average neighborhood sell price, etc.
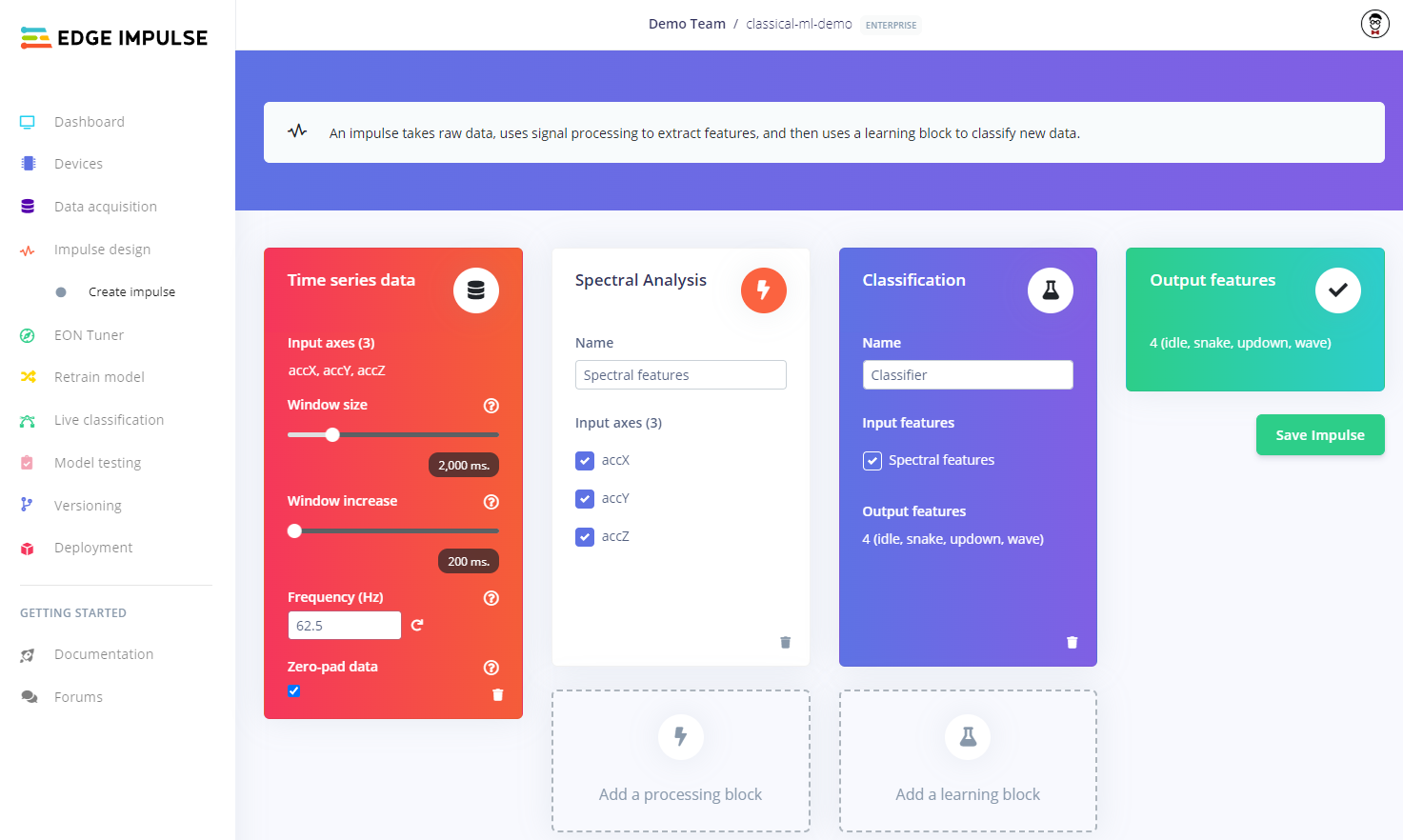
To start, select the Classificationlearning block when building your impulse.
Classical ML models are also available for Regression.
Select the classifier learning block
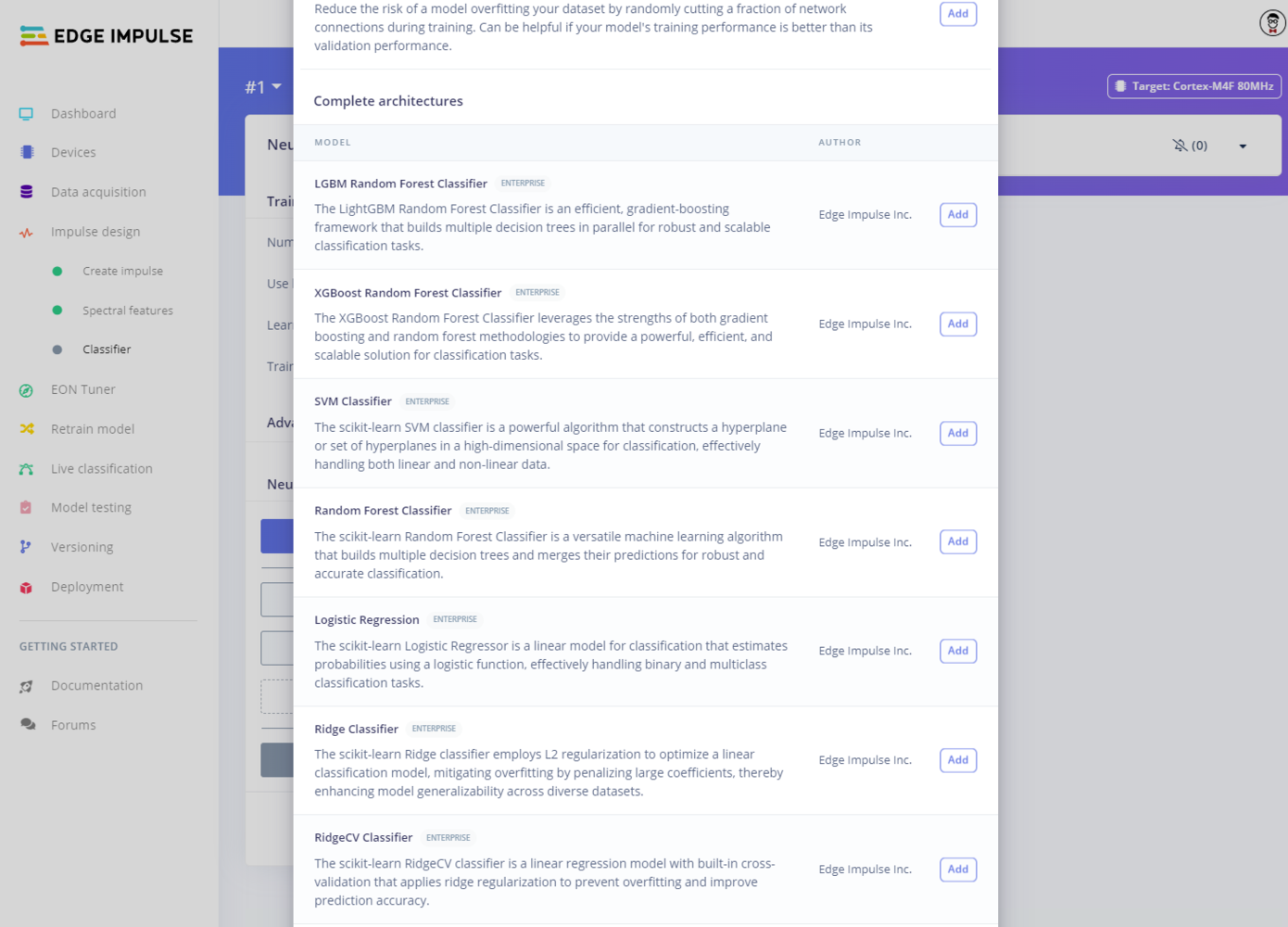
After generating features, head to the Classifier learn block page. Click Add an extra layer. Under Complete architectures, you can select one of the many available classical ML models.
Classical ML models available in Edge Impulse
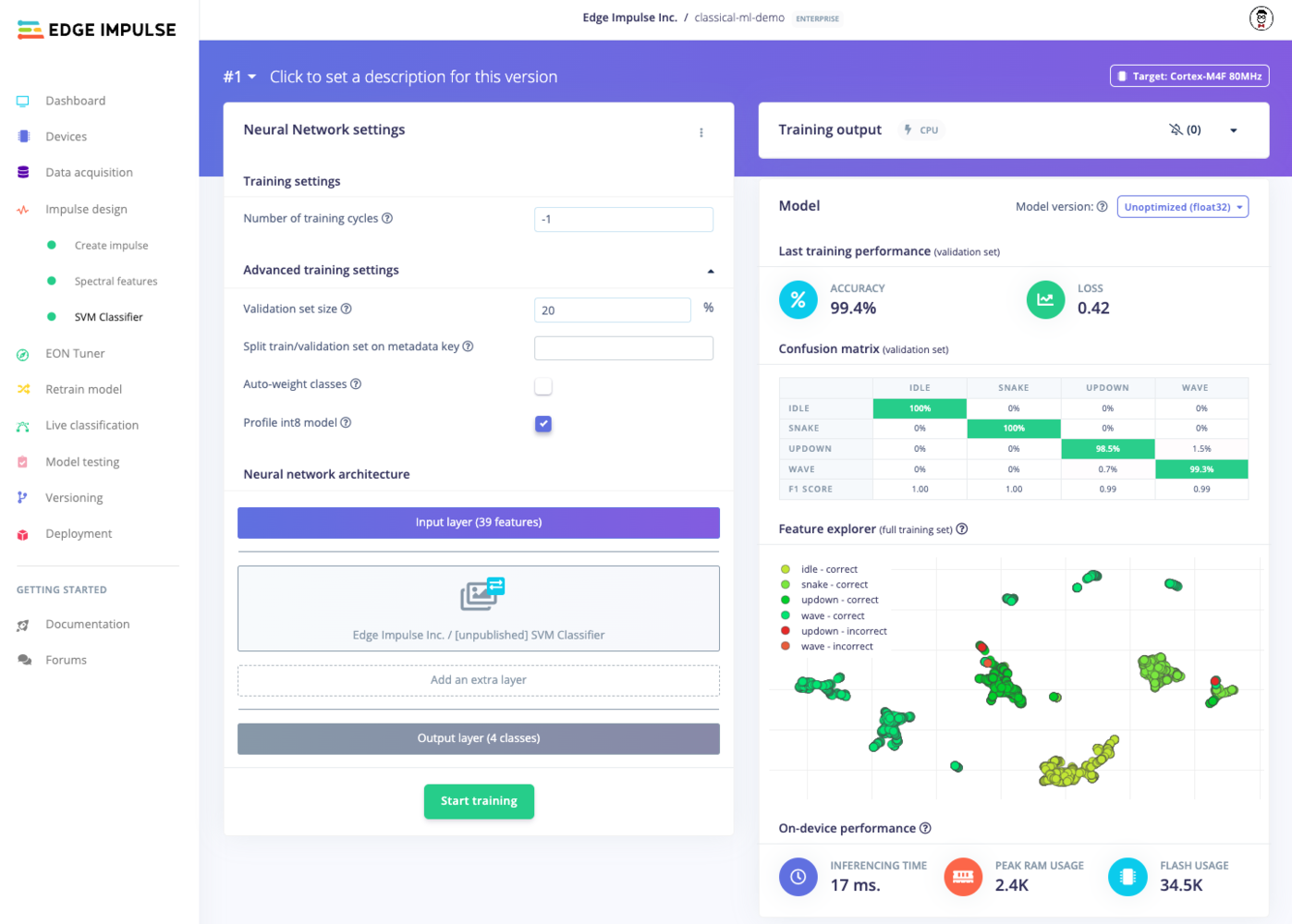
See the Supported classical ML algorithms section below to learn about the different options.When training your classical ML model, you should configure the required hyperparameters. Note that some may require far more training cycles (epochs) than what you are used to with deep learning (e.g. 1000 epochs). However, note that these algorithms train much faster than most neural networks!
Training a classical ML model in Edge Impulse
Note that Expert mode is not available for classical ML models.
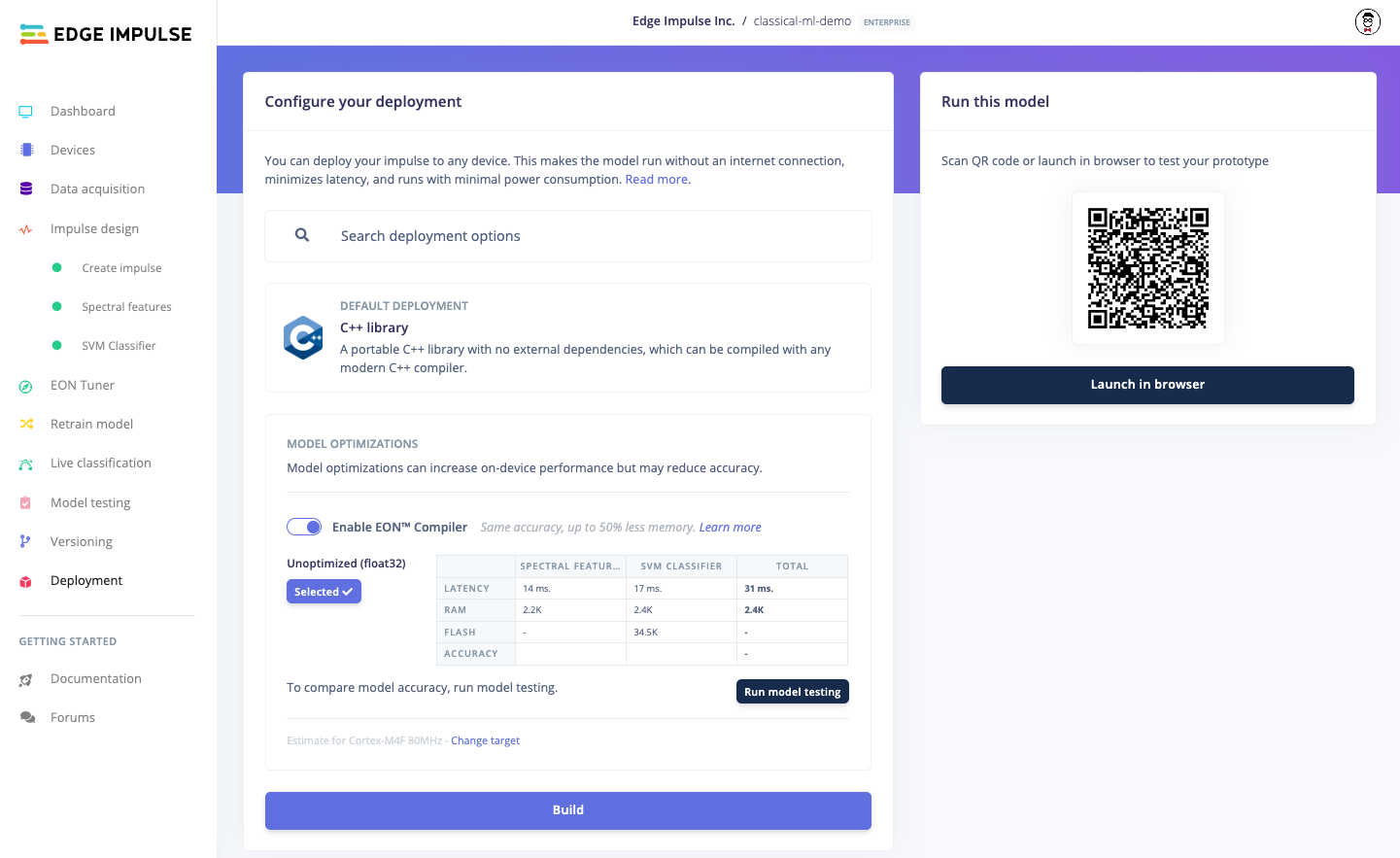
Once you have your trained model, you can deploy the impulse to a variety of devices, including microcontrollers.
Training a classical ML model in Edge Impulse
The gesture dataset is relatively simple. As a result, feature engineering and a classical ML model work very well. On more complex data, you might need to use deep learning to achieve your desired accuracy.
Edge Impulse supports a number of classical algorithms to get you started. If you are unsure of which algorithm to use, we recommend using the EON Tuner to guide you.
Logistic regression (despite its name) is a classifier; it is used to classify input data into one of several, discrete categories. It works by first fitting a line (or surface) to the data, just like in linear regression. From there, the predicted output (of linear regression) is fed into the sigmoid function to classify the input as belonging to one of several classes.Logistic regression is simple, fast, and efficient. However, it requires a linear relationship between the input and predicted class probabilities, which means it will not work well on complex data (e.g. non-linear relationships or many input dimensions).The source code for the logistic regression block can be found in this repository: sklearn-linear-models.
Support vector machines rely on a technique called the “kernel trick” for mapping points in low-dimensional to high-dimensional space. By doing this, groupings of data can often be separated into clearly defined categories.SVMs make for robust classification systems that work well with high-dimensional data (i.e. a single sample containing many values, such as different sensor values). However, they can struggle if classes in the dataset overlap significantly. If this is the case for your dataset, you may want to turn to neural networks.An example Edge Impulse project using an SVM can be found here: sklearn SVM Classification.The source code for the SVM block can be found in this repository: example-custom-ml-block-svm.
Extreme gradient boosting (XGBoost) for classification and regression
XGBoost is an open-source implementation of gradient boosting, which is a type of ensemble learning that uses a combination of simpler models, such as decision trees. It works well for classification and regression tasks. Tree-based methods, like XGBoost, compare values only between samples and not between values in a sample. As a result, they work well with features that have different magnitudes and scales.XGBoost is fast and efficient. It also has built-in methods for handling missing data, and it generally performs better with smaller datasets over LightGBM. However, it does not work as well as neural networks on complex data, and it is prone to overfitting.An example Edge Impulse project using XGBoost for regression can be found here: XGBoost Random Forest Regression.The source code for the XGBoost block can be found in this repository: example-custom-ml-block-xgboost.
Light gradient boosting machine (LightGBM) for classification and regression
Similar to XGBoost, LightGBM is another type of gradient-boosted ensemble model often constructed with decision trees, and it works well for both classification and regression tasks. Because it is a tree-based method, LightGBM compares values between samples rather than between features in a sample, thus making it robust when dealing with features that have different magnitudes.LightGBM is also fast and efficient, but slightly less so than XGBoost, making it a better choice for larger datasets. Like XGBoost, it may not work well with complex data and is prone to overfitting.An example Edge Impulse project using LightGBM for classification can be found here: LGBM Random Forest Classification.The source code for the LightGBM block can be found in this repository: example-custom-ml-block-lgbm.