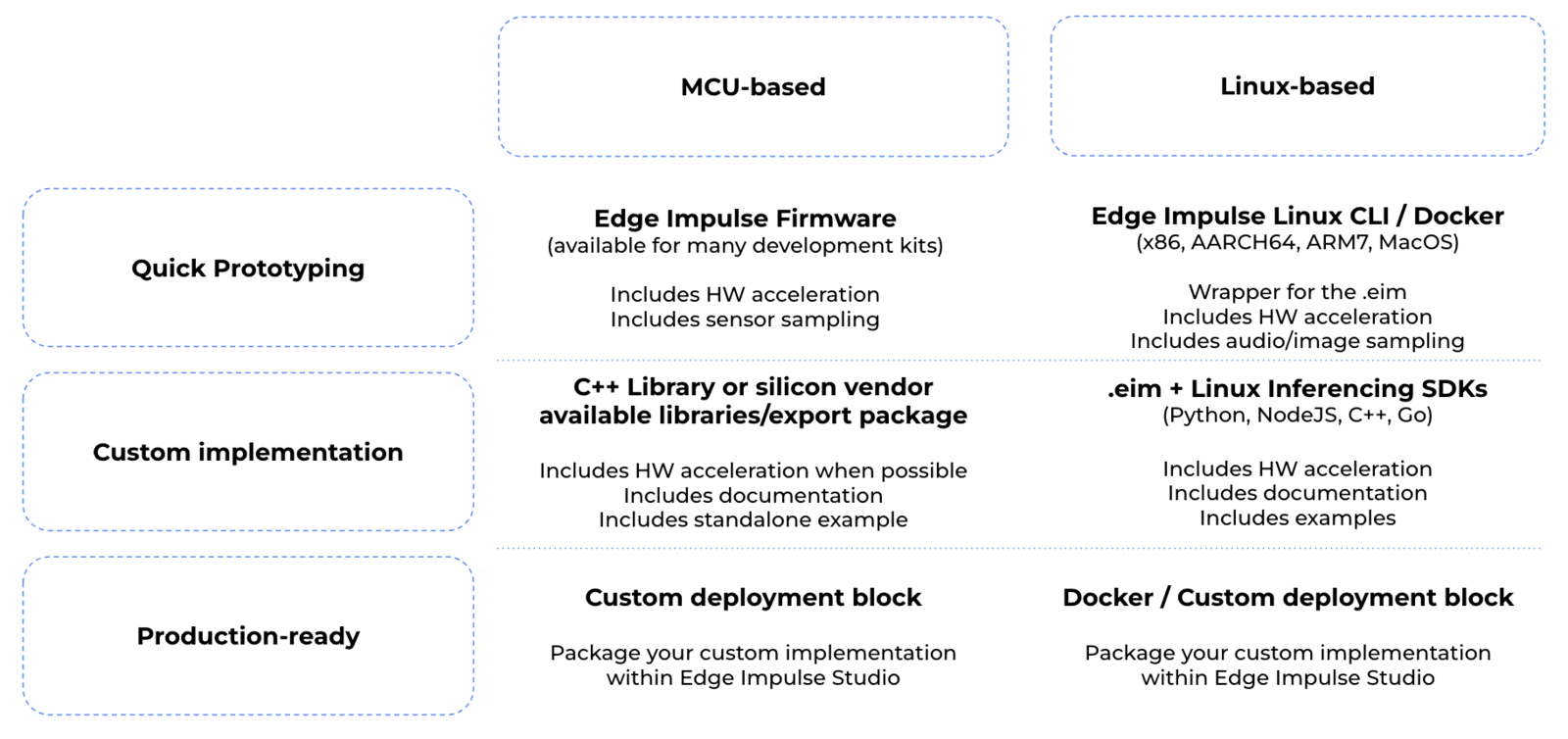
The Deployment page consists of a variety of deployment options to choose from depending on your target device. Regardless of whether you are using a fully supported development board or not, you can deploy your impulse to any supported device. The C++ library and Edge Impulse SDK enable the model to run without an internet connection on the device, minimize latency, and with minimal power consumption.
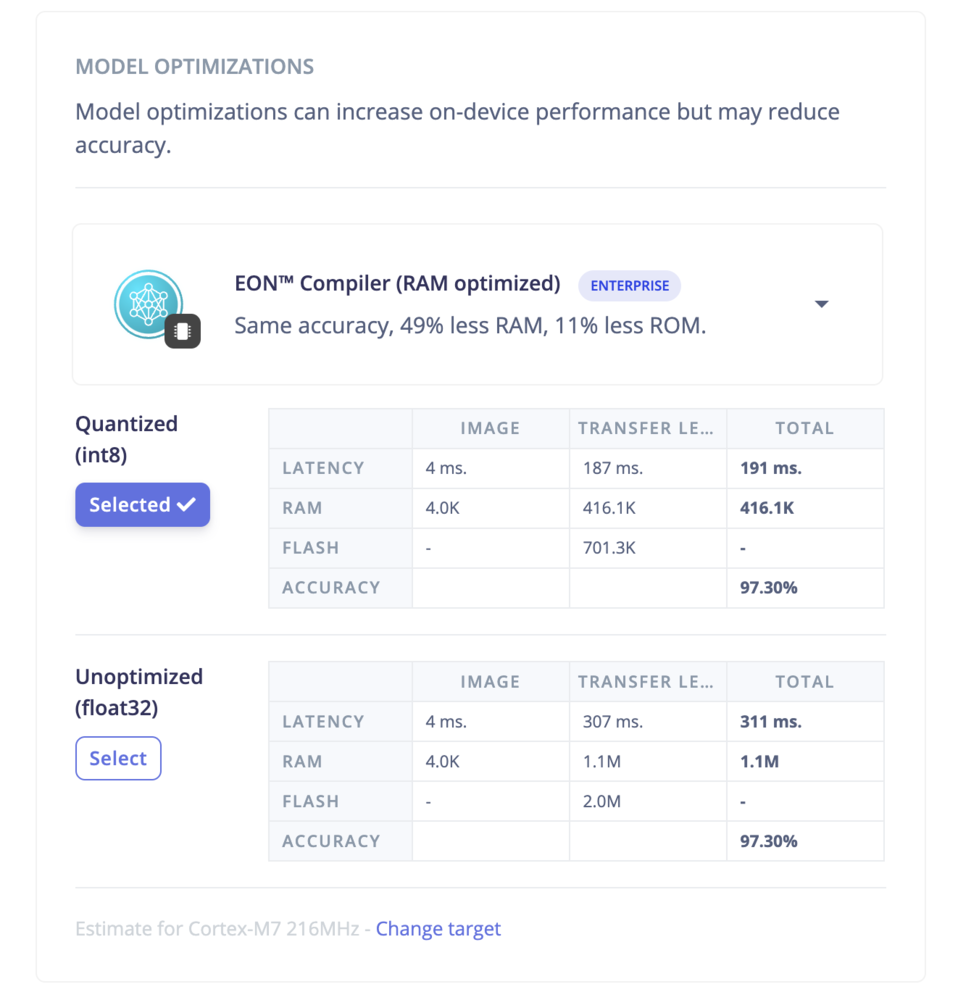
- Model version: Quantized (int8) vs unoptimized (float32) versions.
- Compiler options: TFLite vs EON Compiler. The EON Compiler also comes with an extra option: EON Compiler (RAM optimized) to reduce the RAM even further when possible.
- Deploy as a customizable library
- Deploy as a pre-built firmware (for fully supported development boards)
- Deploy as a Linux .eim binary
- Deploy as a Docker container
- Deploy in your web browser
- Create a custom deployment block (enterprise feature)
Deploy as a customizable library
These deployment options let you turn your impulse into a fully optimized source code that can be further customized and integrated with your application. The customizable library packages all of your signal processing blocks, configuration and machine learning blocks into a single package with all available source code. Edge Impulse supports the following libraries (depending on your dataset’s sensor type):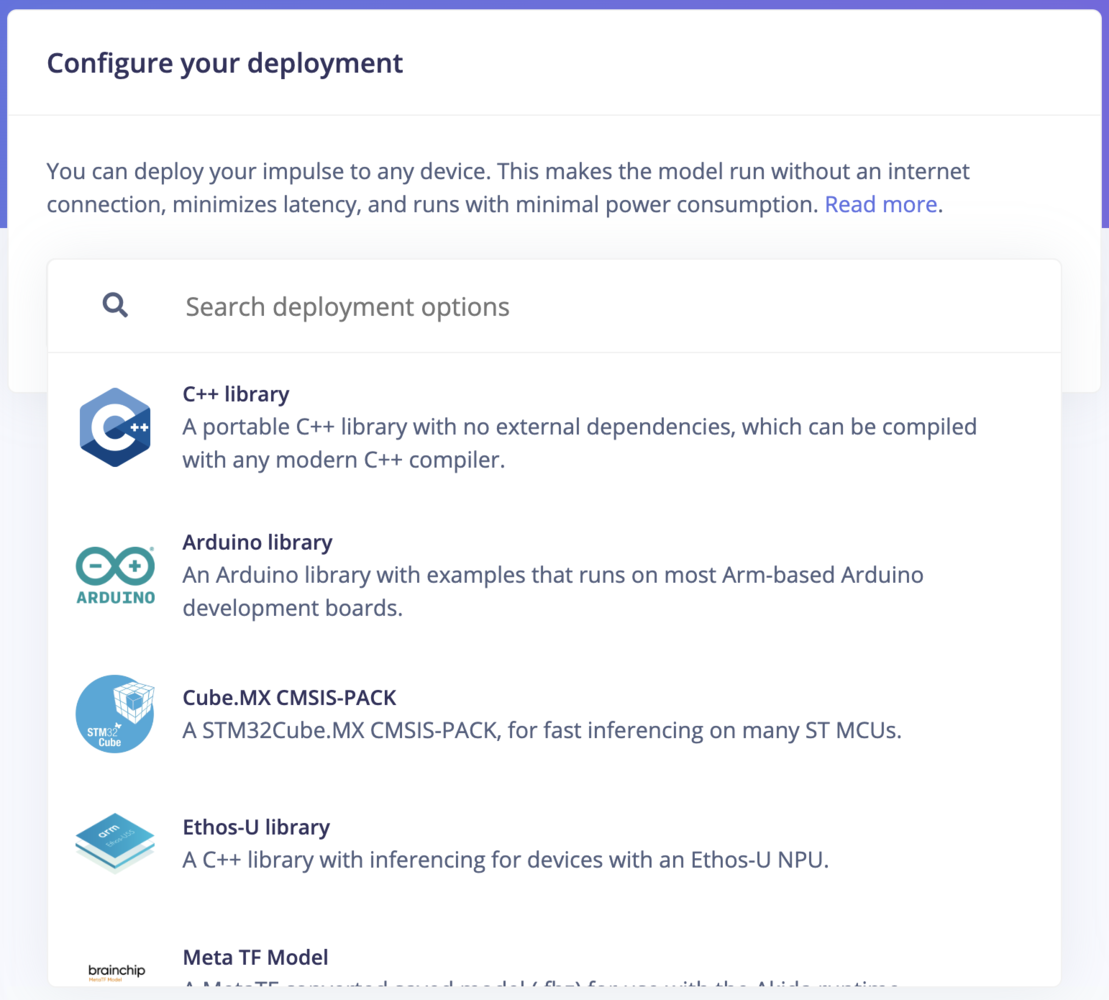
| Library | Description |
|---|---|
| C++ Library | A portable C++ library with no external dependencies, which can be compiled with any modern C++ compiler.Learn more |
| Arduino Library | An Arduino library with examples that runs on most Arm-based Arduino development boards. Learn more |
| WebAssembly | A WebAssembly package that can be run in browsers or other JavaScript environments. Learn more |
| Cube.MX CMSIS-PACK | A CMSIS-PACK library for integrating Edge Impulse models with STM32CubeMX for STM MCUs. Learn more |
| DRP-AI Library | Generate machine learning models using DRP-AI TVM with the DRP-AI Translator for use on Renesas RZ/ products. Learn more |
| OpenMV Library | An OpenMV library for vision-based projects, enabling efficient deployment on OpenMV cameras. Learn more |
| Ethos-U Library | A C++ library for running machine learning models on Arm Ethos-U NPUs, optimized for low-power applications. Learn more |
| Simplicity Studio Component | A C/C++ library package with Simplicity Studio Component file (SLCC) for integration with Silicon Labs’ tools. Learn more |
| TensorRT Library | A library optimized for running inference on the GPU of NVIDIA Jetson devices using TensorRT. Learn more |
| TIDL-RT Library | A deployment option for generating machine learning models to use with Texas Instruments Deep Learning Accelerator (TIDL) on TI processors. Learn more |
| Tensai Flow Library | A library using Tensai Flow for running inference in building custom applications. Learn more |
Deploy as a pre-built firmware
For these deployment options, you can use a ready-to-go binary for your development board that bundles signal processing blocks, configuration and machine learning blocks into a single package. This option is available for fully supported development boards.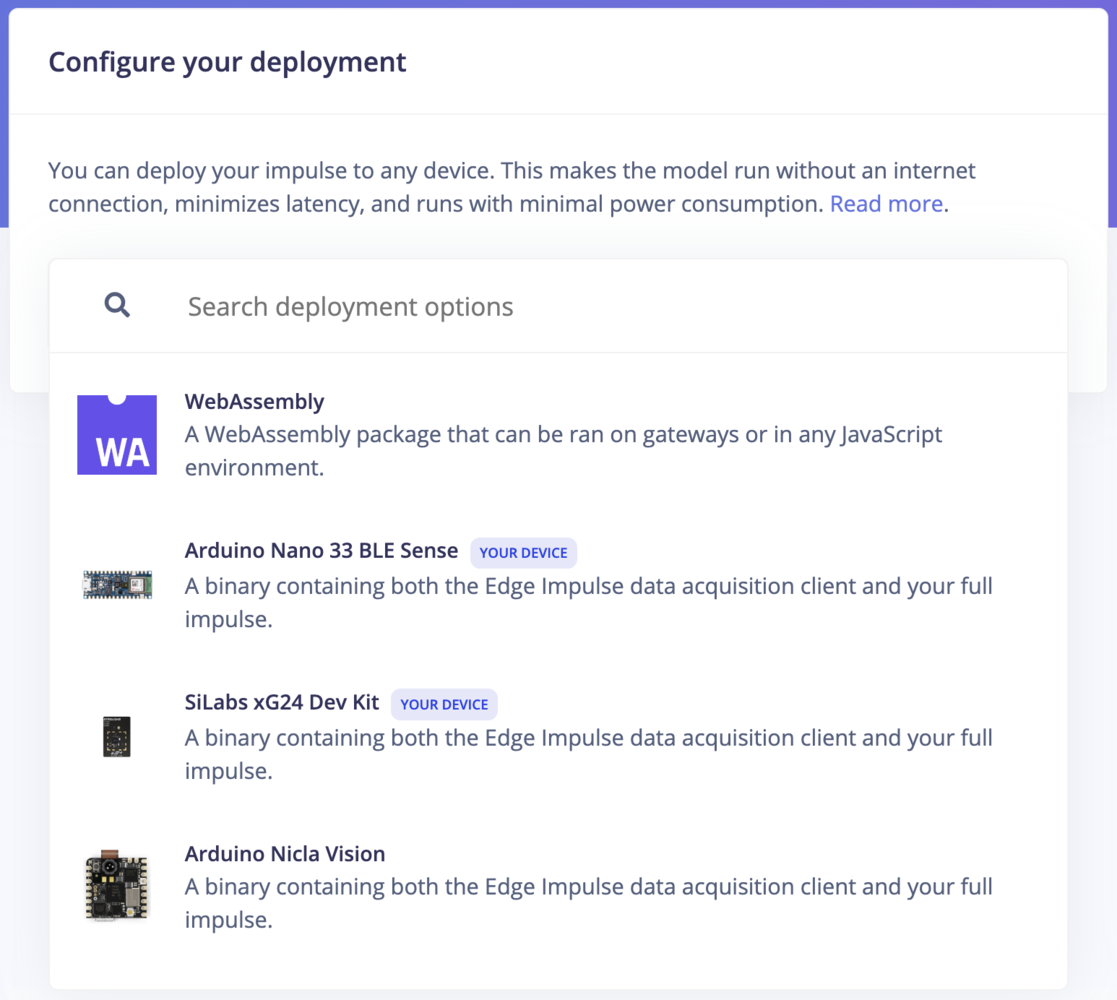
Deploy as a Linux .eim binary
If you are developing for Linux-based devices, you can use Edge Impulse for Linux to deploy using an.eim binary. The Linux SDKs contain tools that let you collect data from sensors, microphones, and cameras, and can run impulses with full hardware acceleration - with easy integration points to write your own applications.
For a deep dive into deploying your impulse to Linux targets using Edge Impulse for Linux, you can visit the Edge Impulse for Linux guides.
Deploy as a Docker container
Deploying Edge Impulse models as a Docker container allows for packaging signal processing, configurations, and learning blocks into a single container that exposes an HTTP inference server. This method is ideal for environments supporting containerized workloads, facilitating deployment on gateways or in the cloud with full hardware acceleration for most Linux targets. Users can initiate deployment by selecting the “Docker container” option within the Deployment section of their Edge Impulse project. See how to run inference using a Docker container.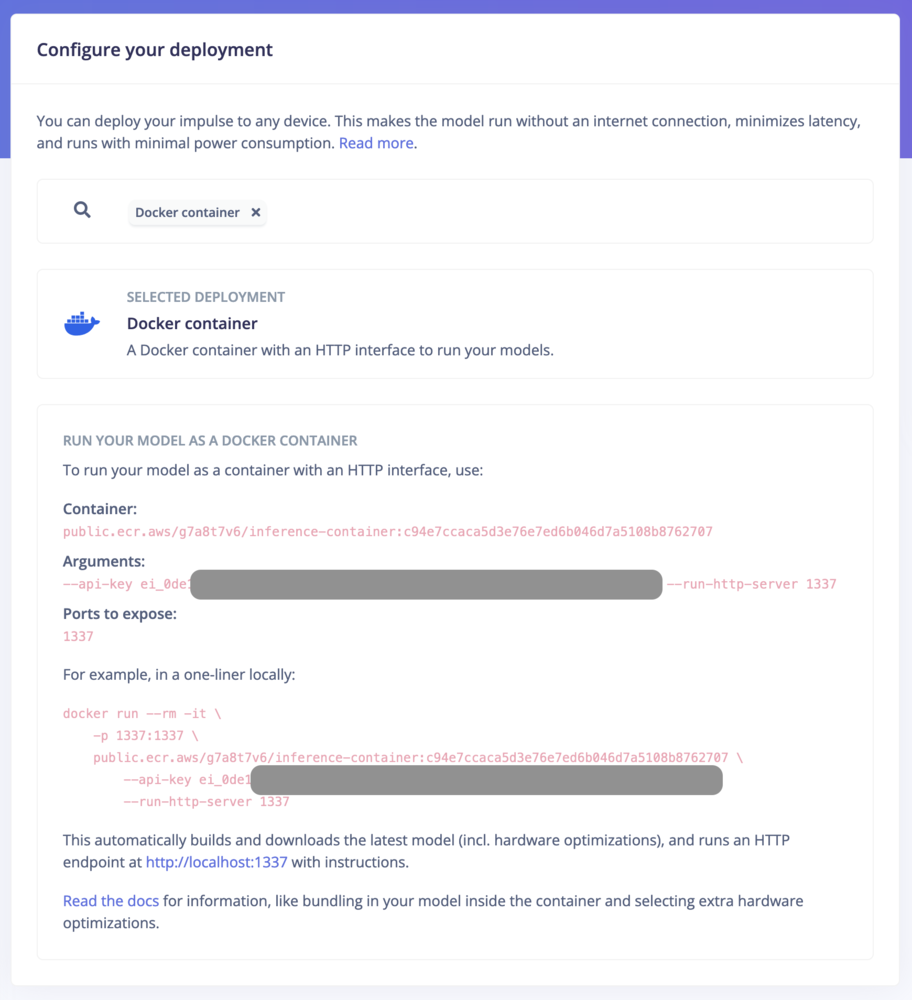
Deploy to ROS 2
If you are building robots on the Robot Operating System (ROS 2), you can plug your impulse straight into your robot’s software withedgeimpulse_ros. This open-source package wraps a Linux .eim binary in a ROS 2 node that subscribes to a standard sensor_msgs/Image topic and publishes structured results as vision_msgs (Detection2DArray and Classification), so on-device intelligence becomes available to the rest of your robot with no custom glue code.
The node supports object detection, image classification, FOMO, and visual anomaly detection (FOMO-AD), decodes common camera encodings (bgr8, rgb8, mono8/16, bgra8, rgba8, yuyv, uyvy, and nv12/nv21) natively, and preserves source timestamps and frame_id so TF and sensor fusion keep working.
First, deploy your model as a Linux .eim binary, then build and run the node in your ROS 2 workspace:
edgeimpulse_ros repository.
Deploy to your web browser
You can run your impulse directly in your web browser using your computer or mobile phone without the need of an additional app. To run on your computer, click Launch in browser. To run on your mobile phone, scan the QR code and click Switch to classification mode.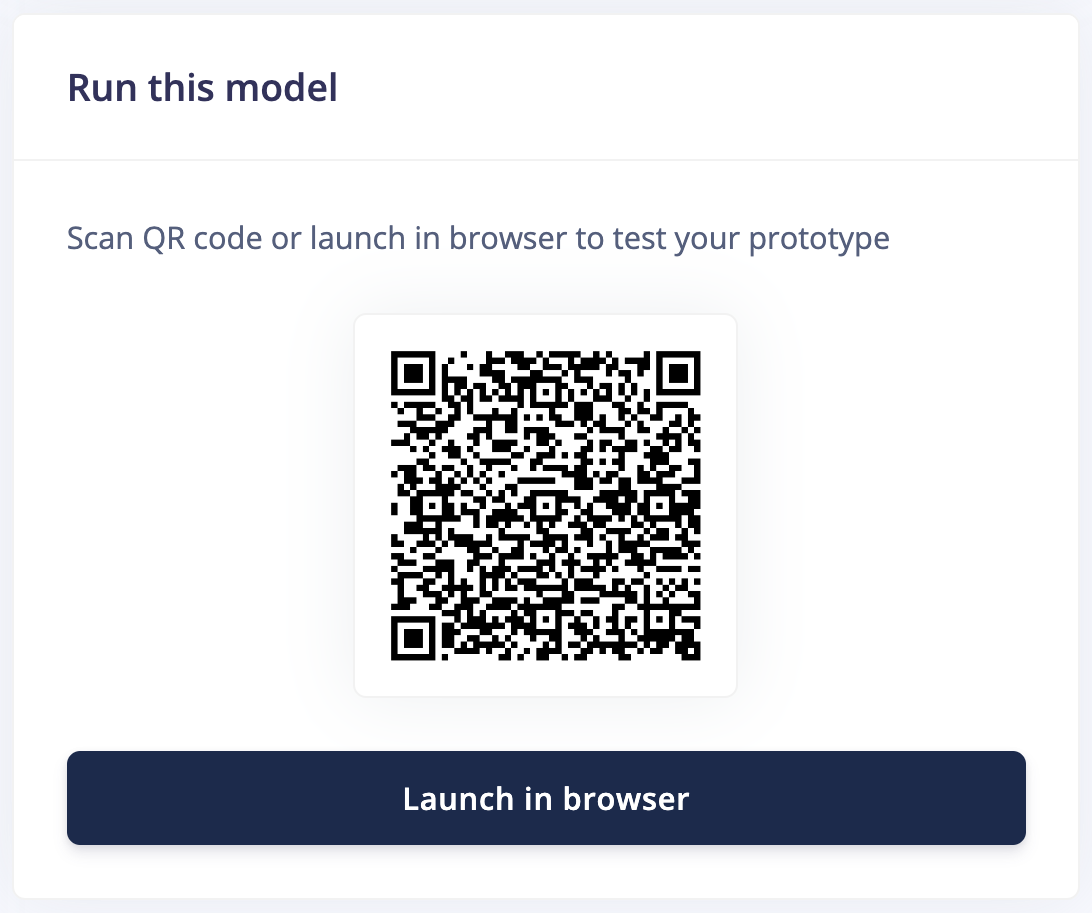
Latest build
Download the most recent build from your project’s deployment page under Latest build: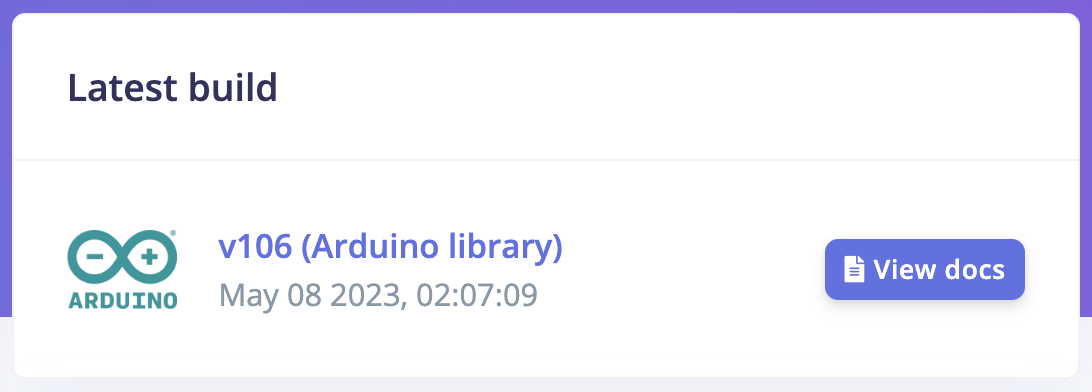
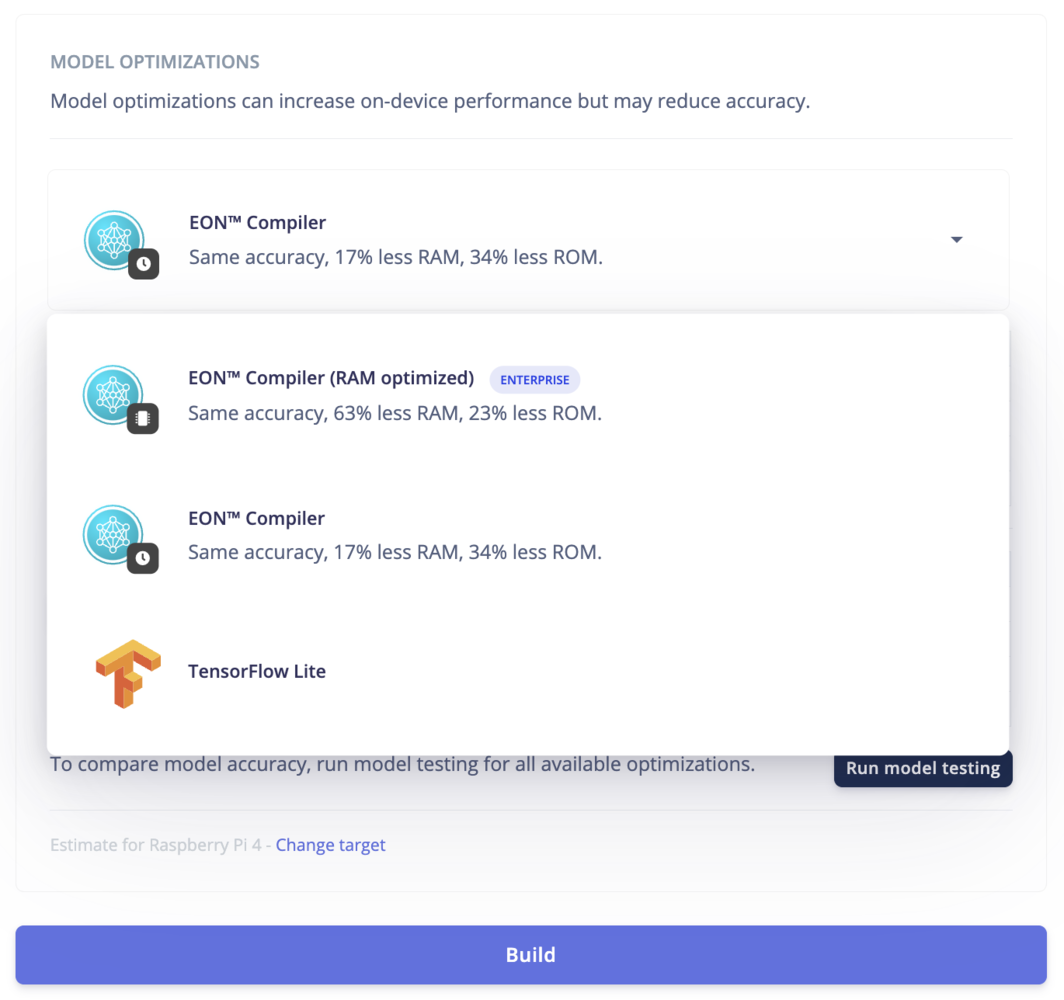
Model optimizations
EON Compiler
When building your impulse for deployment, Edge Impulse gives you the option of adding another layer of optimization to your impulse using the EON compiler. The EON Compiler lets you run neural networks using less RAM, and saving flash resource, while retaining the same accuracy compared to LiteRT (previously Tensorflow Lite) for Microcontrollers. Depending on your neural network architecture, we can also provide one extra layer of optimization with the EON Compiler (RAM optimized).