TutorialsWant to see the Classification block in action? Check out our tutorials:
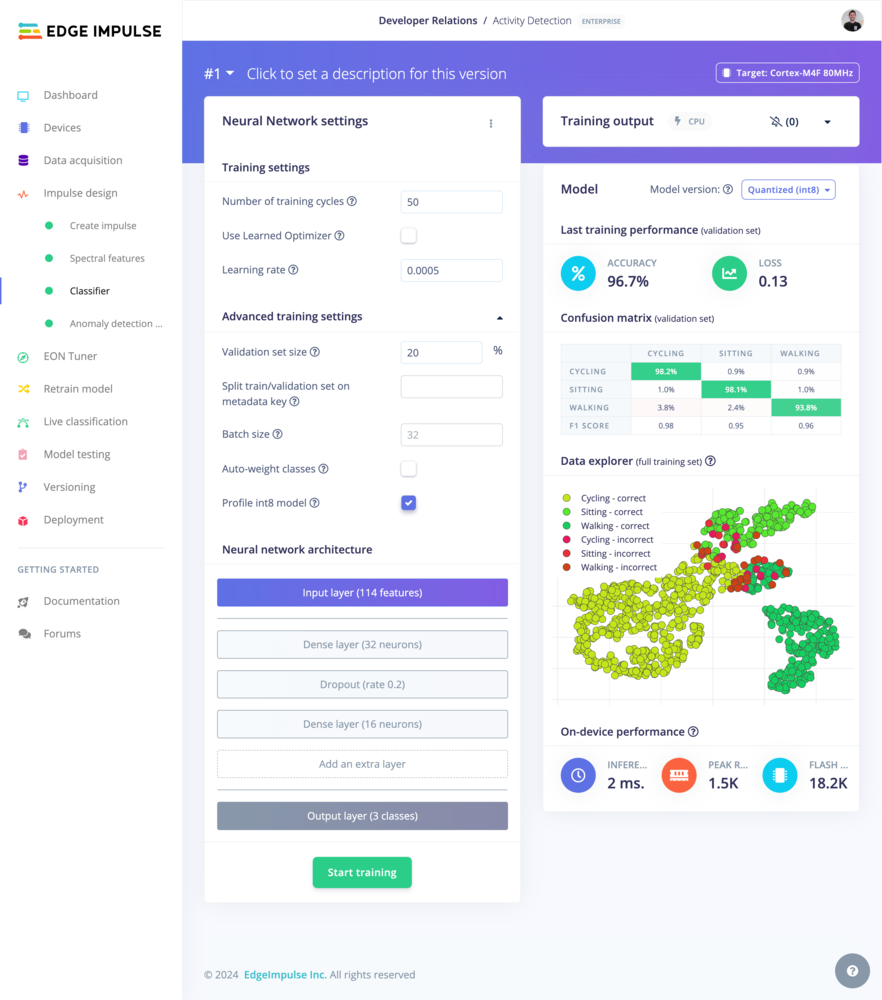
Neural Network settings
See Neural Network Settings on the Learning Block page.Neural Network architecture
See Neural Network Architecture on the Learning Block page.Expert mode
See Expert mode on the Learning Block page.Training output
This panel displays the output logs during the training. The previous training logs can also be retrieved from the Jobs tab in the Dashboard page (enterprise feature).Model performances