The videos above show a previous version of the EON Tuner. The Studio user interface and the EON Tuner configuration, operation, and results have since been updated. However, the videos provide relevant background information and are still worth watching, even though you will come across differences in your projects today.
Overview
The EON Tuner explores a user defined parameter search space to perform end-to-end impulse optimizations, from the input block, to the processing block, learning block, and even additional configurations such as data augmentation, to help you find the ideal trade-off between options for these block, their associated parameters, and your target hardware resources constraints. The exploration of a specific search space is called an EON Tuner run. Each run consists of a number of trials, with each trial being a variation of the input, processing, and learning block options and their parameter values that had been specified in the search space. After the creation of several trials, the training and testing of each one is then scheduled and executed, with several trials being completed in parallel.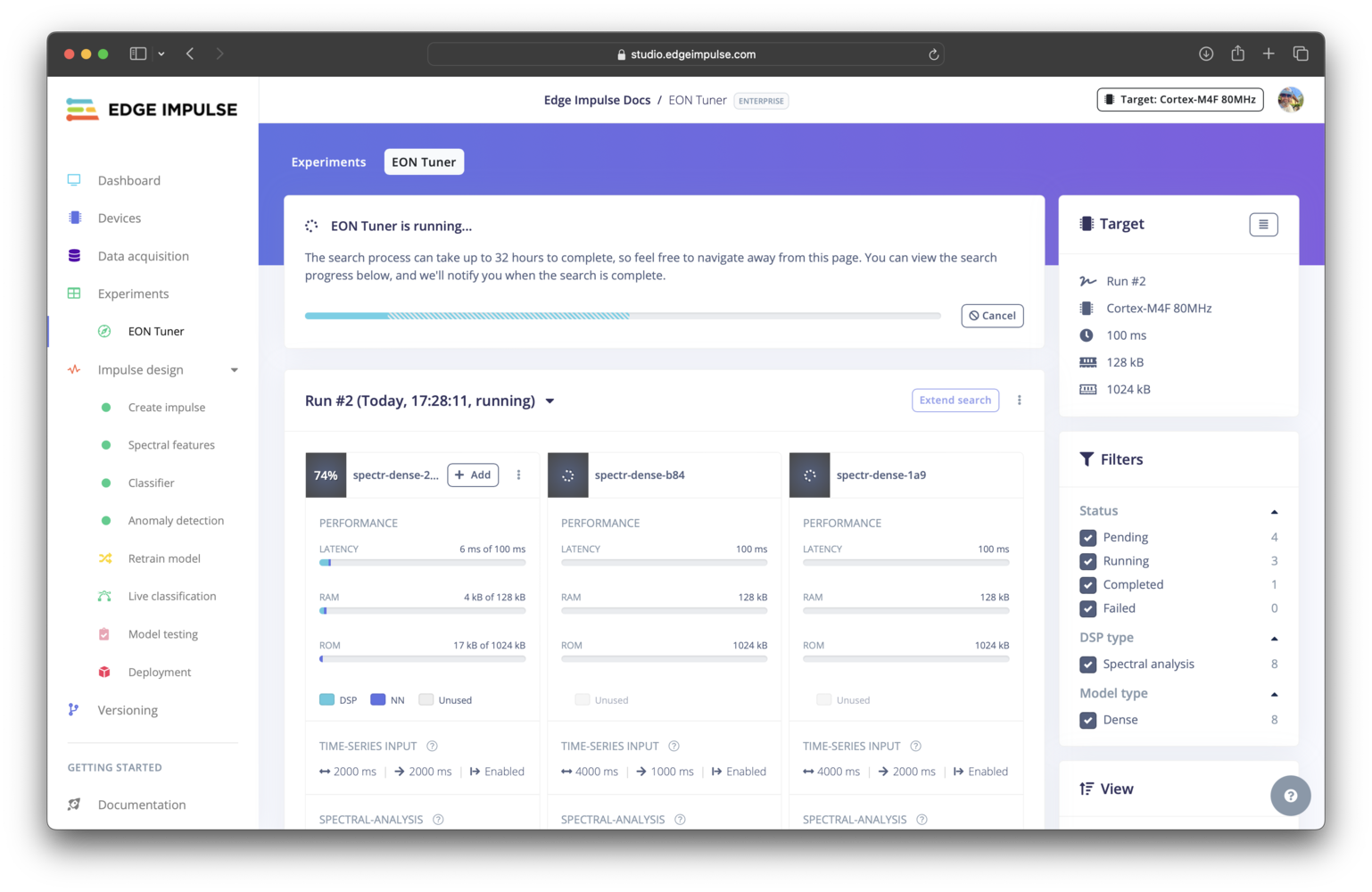
EON Tuner run progress
Search algorithm
There are several approaches to exploring a parameter search space. For example, the most common methods include: manual search, random search, grid search, and Bayesian optimization. The EON Tuner has been updated to use Bayesian optimization (previously random search). Compared to the other techniques listed, Bayesian optimization is a more efficient and effective option. It is a “smarter” algorithm that learns from prior results by building a probabilistic model based on these results, the possible parameter values, and your objectives to determine what area of the search space to explore next. This leads to improved results in a shorter amount of time using fewer compute resources.Getting started
EON Tuner tab
Configuring a new run
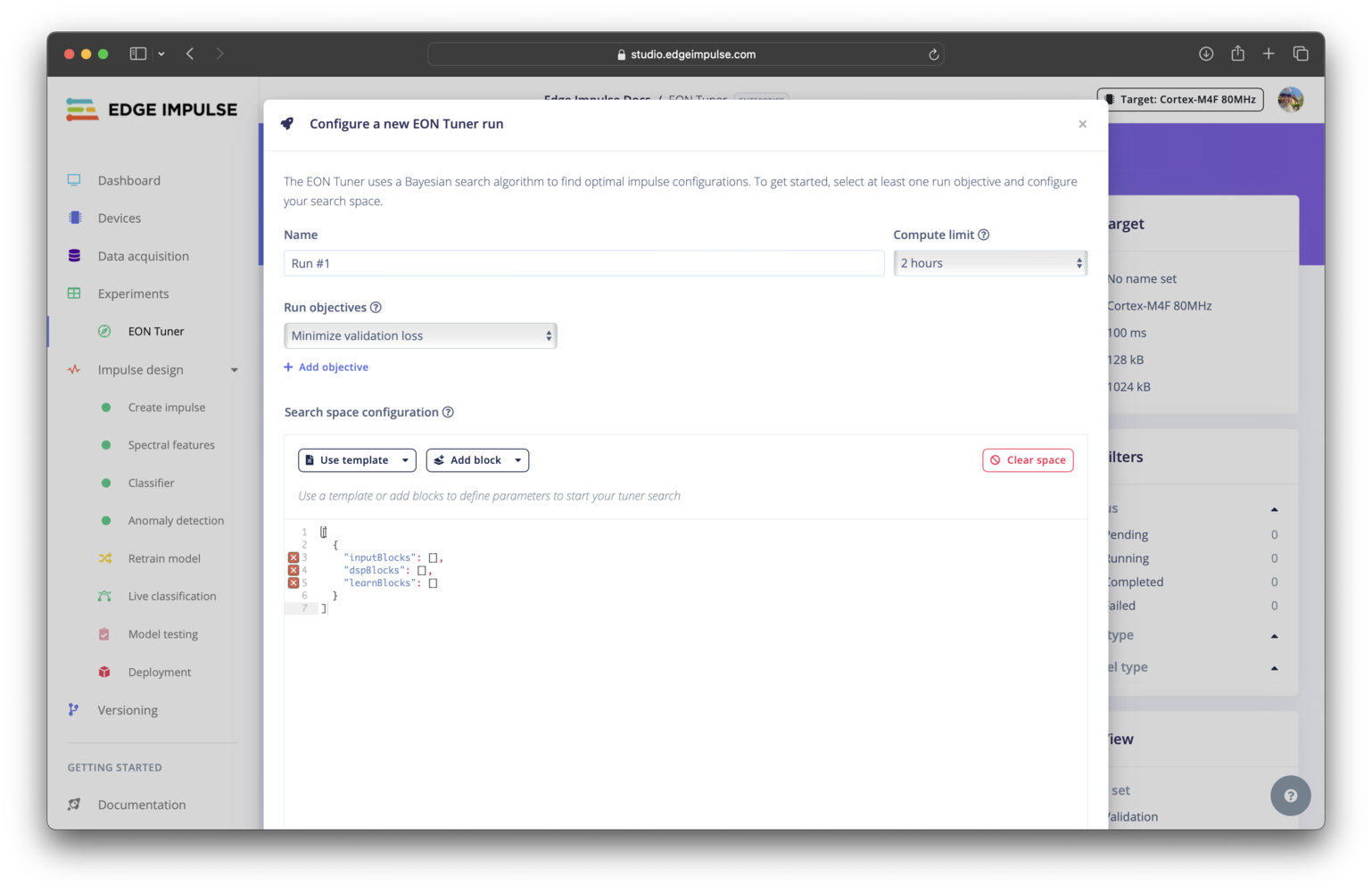
Configuring an EON Tuner run
New run button. This will launch a modal window where you can adjust the settings for the run. In this modal, you will be able to set the name, select the compute time limit, specify the run objectives, and define the parameter search space for your run.
You are able to prioritize one or more run objectives that are most relevant to your application. The objectives you set are taken into account in the Bayesian optimization algorithm. Note that an objective that is higher on the list will be weighted more heavily (given a greater importance) than the the objectives that come below it.
Search space
For information on configuring the search space, please see the EON Tuner search space documentation.Reviewing run results
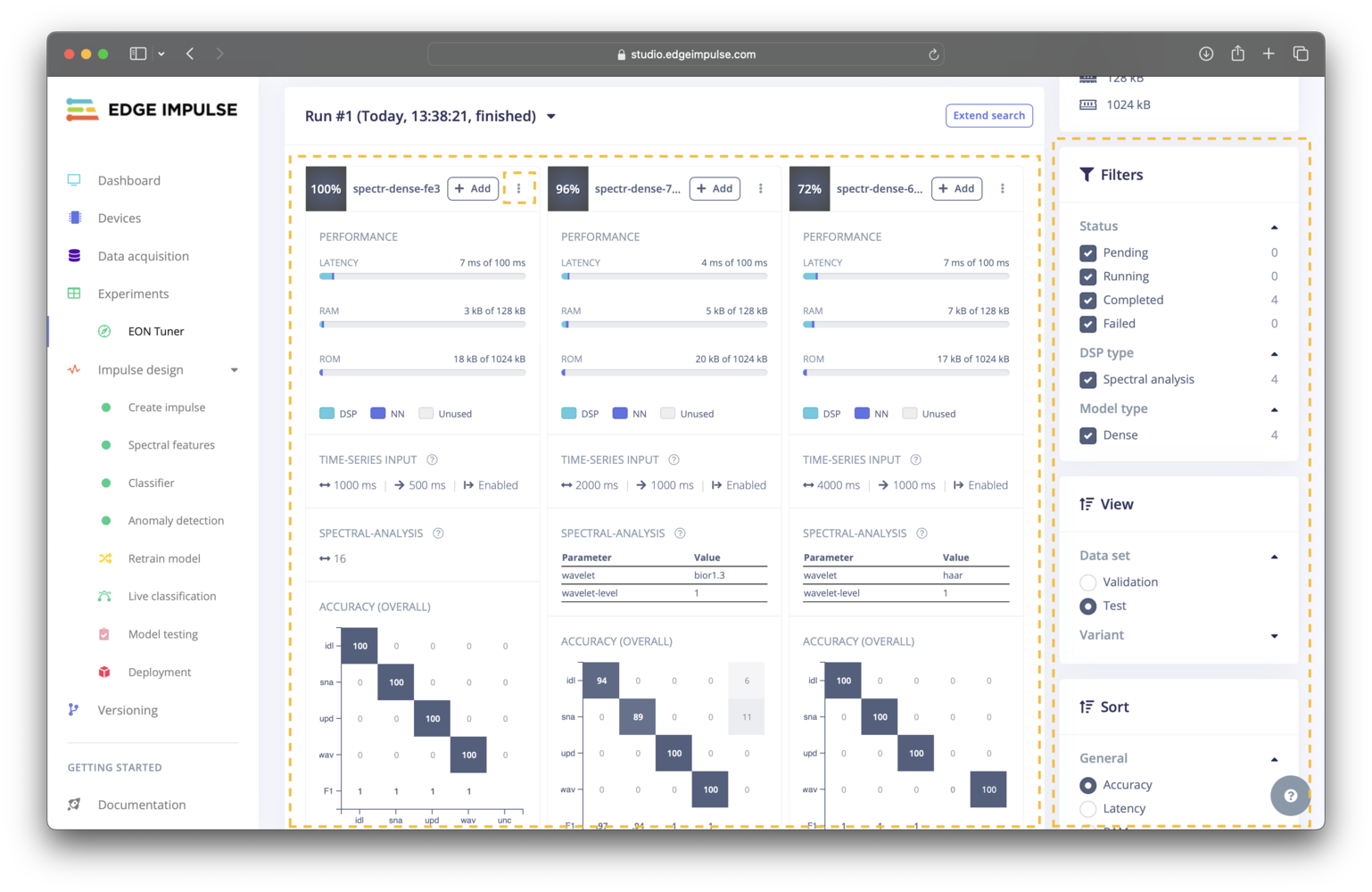
Reviewing EON Tuner results
Show logs. This will launch a trial logs modal window.
Trial results can be filtered based on the trial status, the processing block used, or the machine learning model used. The results can also be sorted by several metrics. Lastly, you are able to view the results for either the validation or test datasets.
These filtering, sorting, and view options are available to the right of the trial results.
Extending a run
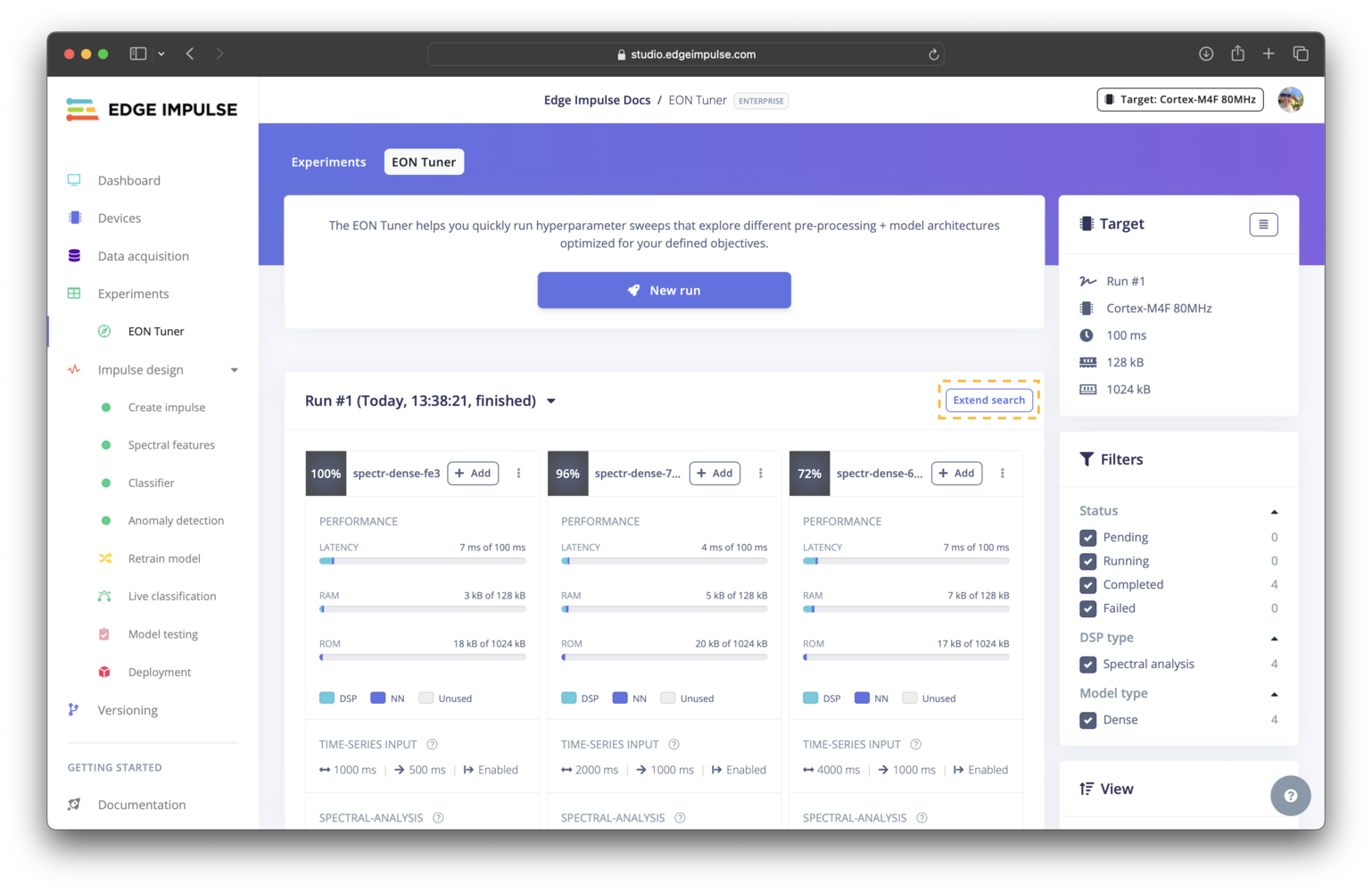
Extending an EON Tuner run
Extend search button located above the the trial results.
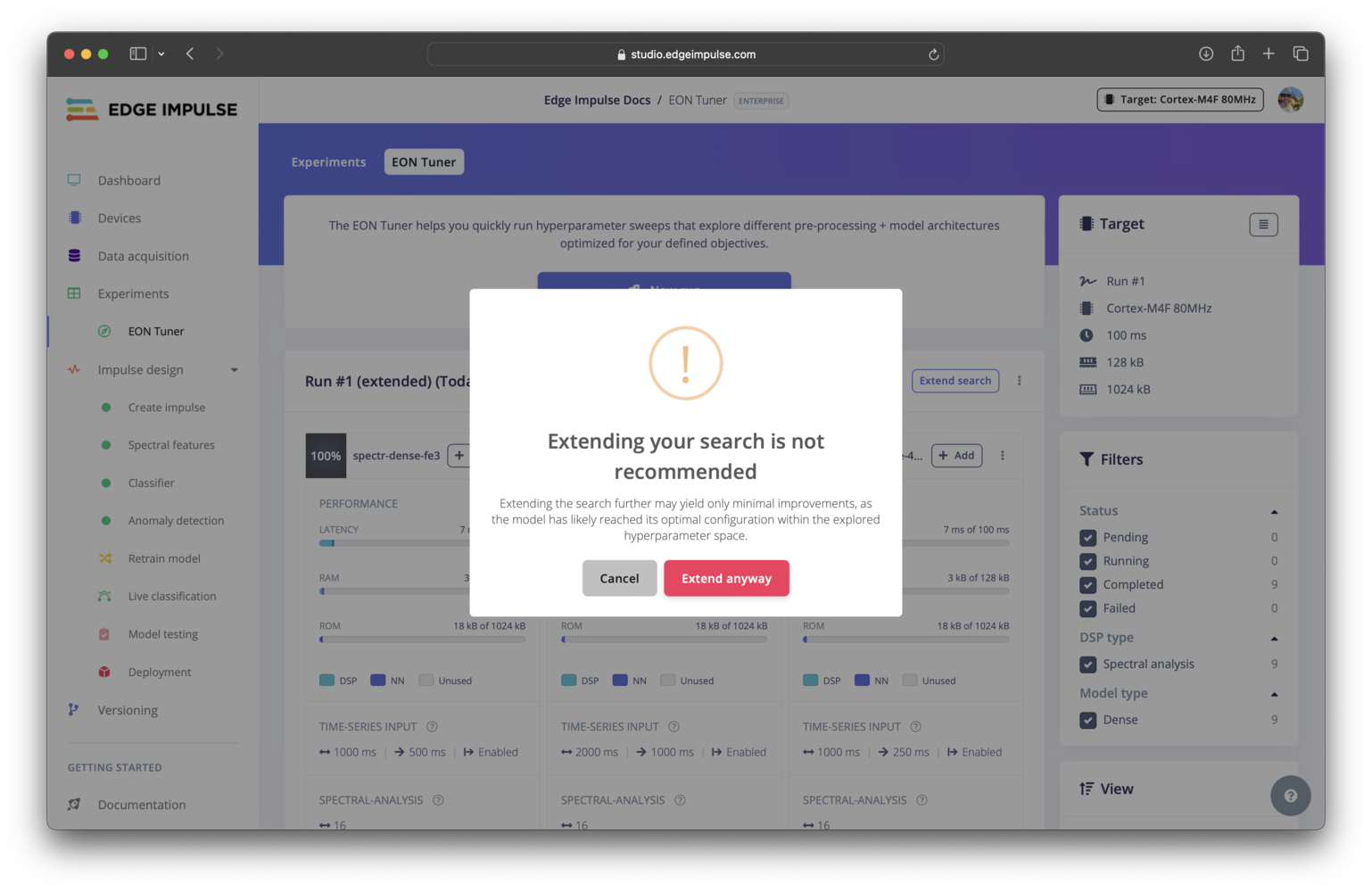
Extending an EON Tuner run not recommended
Adding a trial to your experiments
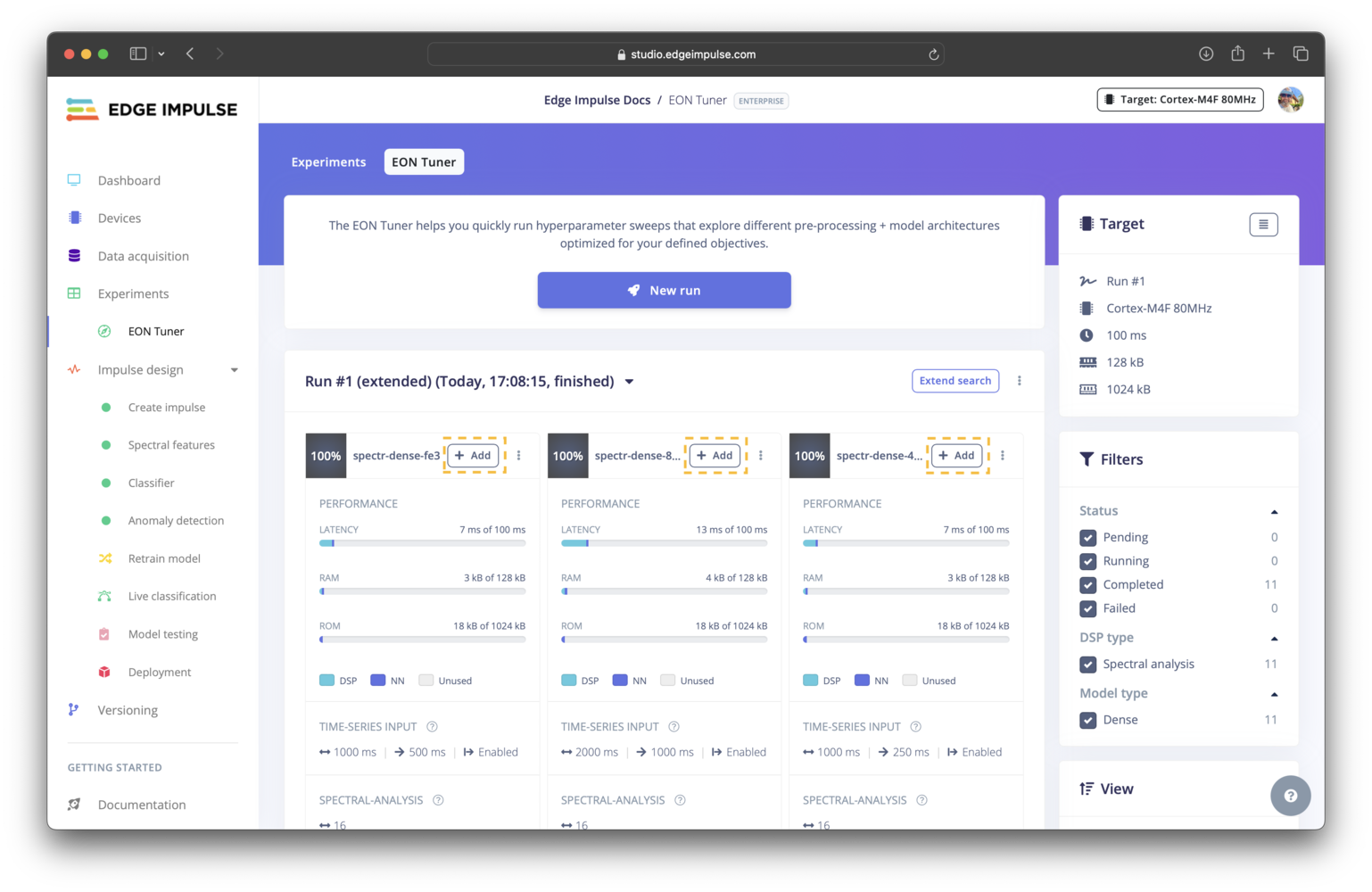
Adding a trial to your experiments list
+ Add button for the trial.
Troubleshooting
No common issues have been identified thus far. If you encounter an issue, please reach out on the forum or, if you are on the Enterprise plan, through your support channels.