ei.API_KEY value in the following cell:
wandb.login() function. This will prompt you to log in to your account. Your credentials should be stored, which allows you to use the wandb package in your Python library.
Gather a dataset
We want to create a classifier that can uniquely identify handwritten digits. To start, we will use TensorFlow and Keras to train a very simple convolutional neural network (CNN) on the classic MNIST dataset, which consists of handwritten digits from 0 to 9.Create an experiment
We want to vary the hyperparameters in our model and see how it affects the accuracy and predicted RAM, ROM, and inference time on our target platform. To do that, we construct a function that builds a simple model using Keras, trains the model, and computes the accuracy and loss from our holdout test set. We then use the Edge Impulse Python SDK to generate a profile of our model for our target hardware. We log the hyperparameter (number of nodes in the hidden layer), test loss, test accuracy, estimated RAM, estimated ROM, and estimated inference time (ms) to our Weights and Biases console.Run the experiment
Now, it’s time to run the experiment and log the results in Weights and Biases. Simply call our function and provide a new hyperparameter value for the number of nodes.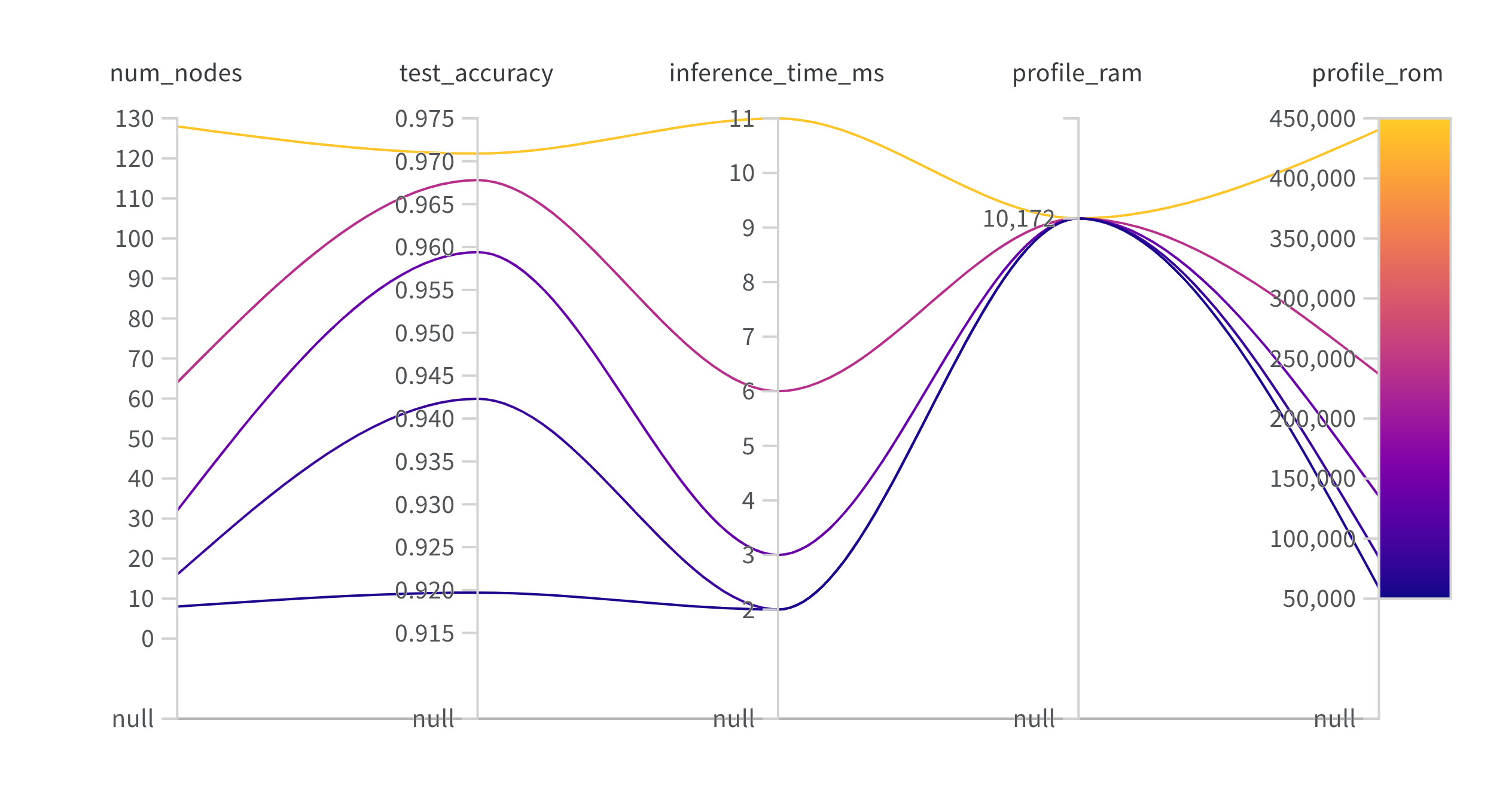
Deploy Your Model
Once you are happy with the performance of your model, you can then deploy it to your target hardware. We will assume that 32 nodes in our hidden layer provided the best trade-off of RAM, flash, inference time, and accuracy for our needs. To start, we will retrain the model:output_directory argument in the .deploy() function. Your deployment file(s) will be downloaded to that directory.