from sagemaker import image_uris, model_uris, script_uris, hyperparameters
from sagemaker.estimator import Estimator
training_instance_type = "ml.m5.large"
# Retrieve the Docker image
train_image_uri = image_uris.retrieve(model_id=model_id,model_version=model_version,image_scope="training",instance_type=training_instance_type,region=None,framework=None)
# Retrieve the training script
train_source_uri = script_uris.retrieve(model_id=model_id, model_version=model_version, script_scope="training")
# Retrieve the pretrained model tarball for transfer learning
train_model_uri = model_uris.retrieve(model_id=model_id, model_version=model_version, model_scope="training")
# Retrieve the default hyper-parameters for fine-tuning the model
hyperparameters = hyperparameters.retrieve_default(model_id=model_id, model_version=model_version)
# [Optional] Override default hyperparameters with custom values
hyperparameters["epochs"] = "5"
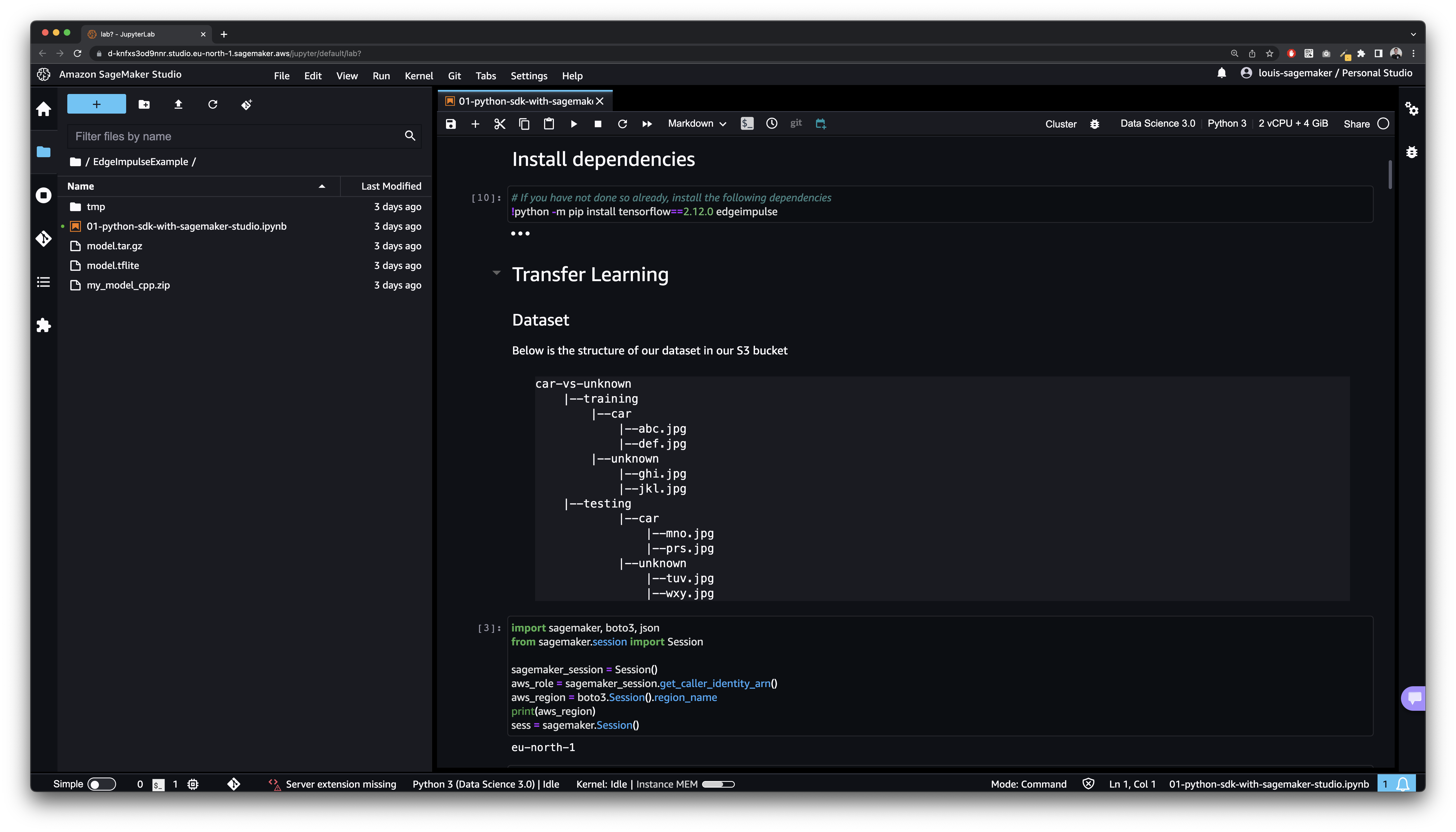
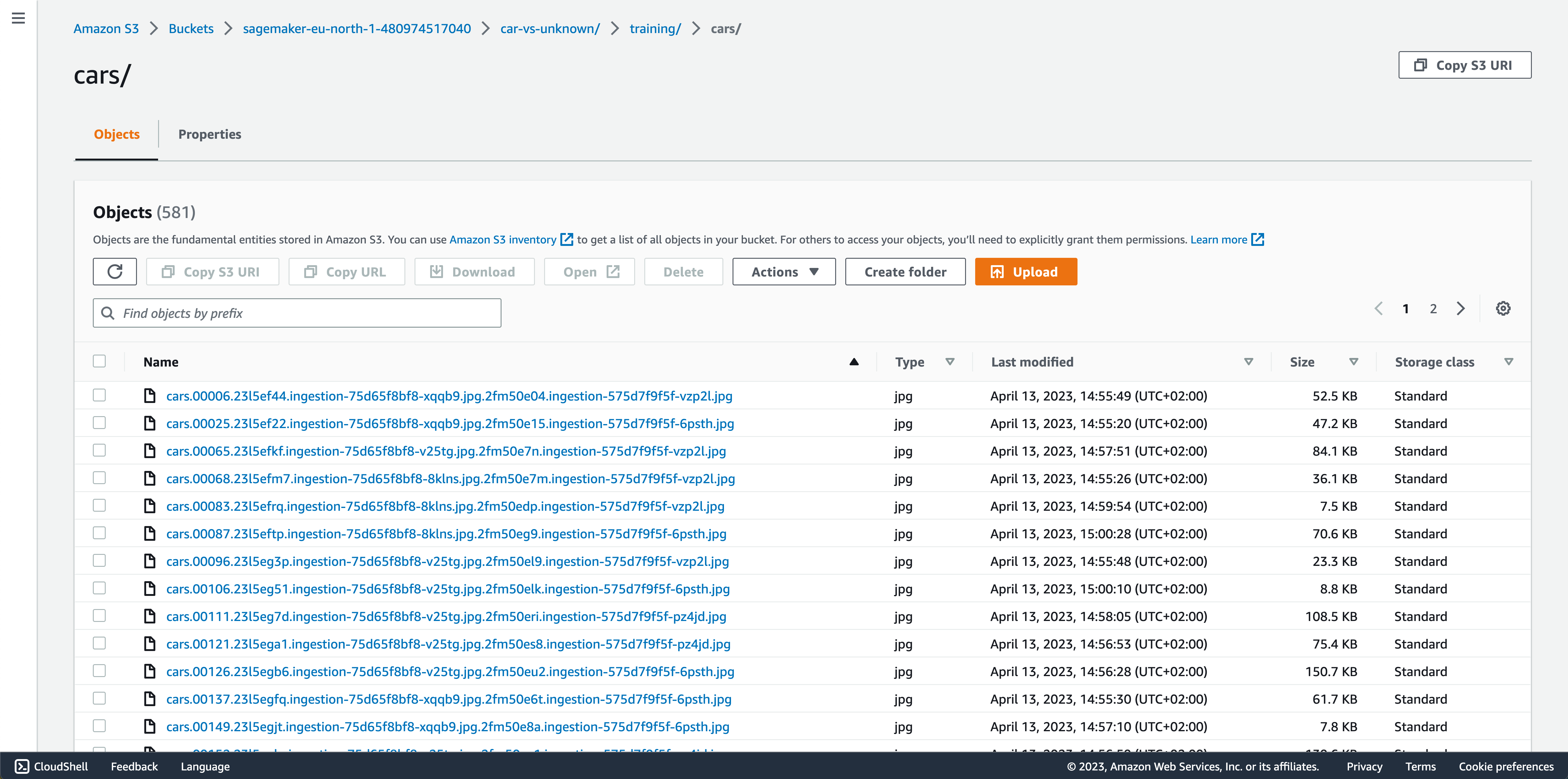
# The sample training data is available in the following S3 bucket
training_data_bucket = f"{bucket}"
training_data_prefix = f"{subfolder}"
# training_data_bucket = f"jumpstart-cache-prod-{aws_region}"
# training_data_prefix = "training-datasets/tf_flowers/"
training_dataset_s3_path = f"s3://{training_data_bucket}/{training_data_prefix}"
output_bucket = sess.default_bucket()
output_prefix = "ic-car-vs-unknown"
s3_output_location = f"s3://{output_bucket}/{output_prefix}/output"
# Create SageMaker Estimator instance
tf_ic_estimator = Estimator(
role=aws_role,
image_uri=train_image_uri,
source_dir=train_source_uri,
model_uri=train_model_uri,
entry_point="transfer_learning.py",
instance_count=1,
instance_type=training_instance_type,
max_run=360000,
hyperparameters=hyperparameters,
output_path=s3_output_location
)
# Use S3 path of the training data to launch SageMaker TrainingJob
tf_ic_estimator.fit({"training": training_dataset_s3_path}, logs=True)