How can I make sure these layers will work on edge device?
In Edge AI applications, these layers need to be optimized not just for accuracy, but also for computational and memory efficiency to perform well within the constraints of edge devices. Some architectures may not be suitable for constrained devices because of the computational complexity, resource availability or unsupported operators.If you don’t know where to start, try out the EON Tuner, our device-aware Auto ML tool.Also, feel free to profile your models for edge deployments using our BYOM feature or using our Python SDK.Input layer
The input Layer serves as the initial phase of the neural network. It is responsible for receiving all the input data for the model. This layer does not perform any computation or transformation. It simply passes the features to the subsequent layers. The dimensionality of the Input Layer must match the shape of the data you’re working with. For instance, in image processing tasks, the input layer’s shape would correspond to the dimensions of the image, including the width, height, and color channels.Dense layer (or fully connected layer)
A Dense layer, often referred to as a fully connected layer, is the most basic form of a layer in neural networks. Each neuron in a dense layer receives input from all the neurons of the previous layer, hence the term “fully connected”. It’s a common layer that can be used to process data that has been flattened or transformed from a higher to a lower dimension.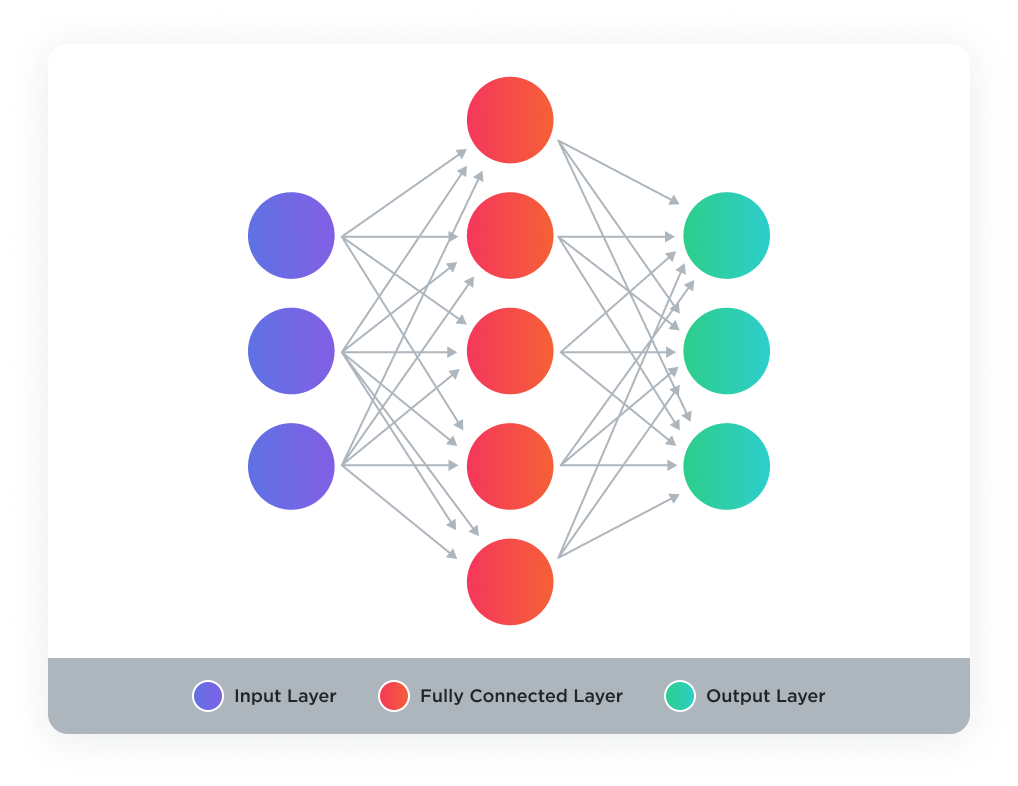
Reshape layer
The reshape layer is used to change the shape of the input data without altering its contents. It’s particularly useful when you need to prepare the dataset for certain types of layers that require the input data to be in a particular shape.Flatten layer
Flatten layers are used to convert multi-dimensional data into a one-dimensional array. This is typically done before feeding the data into a Dense layer.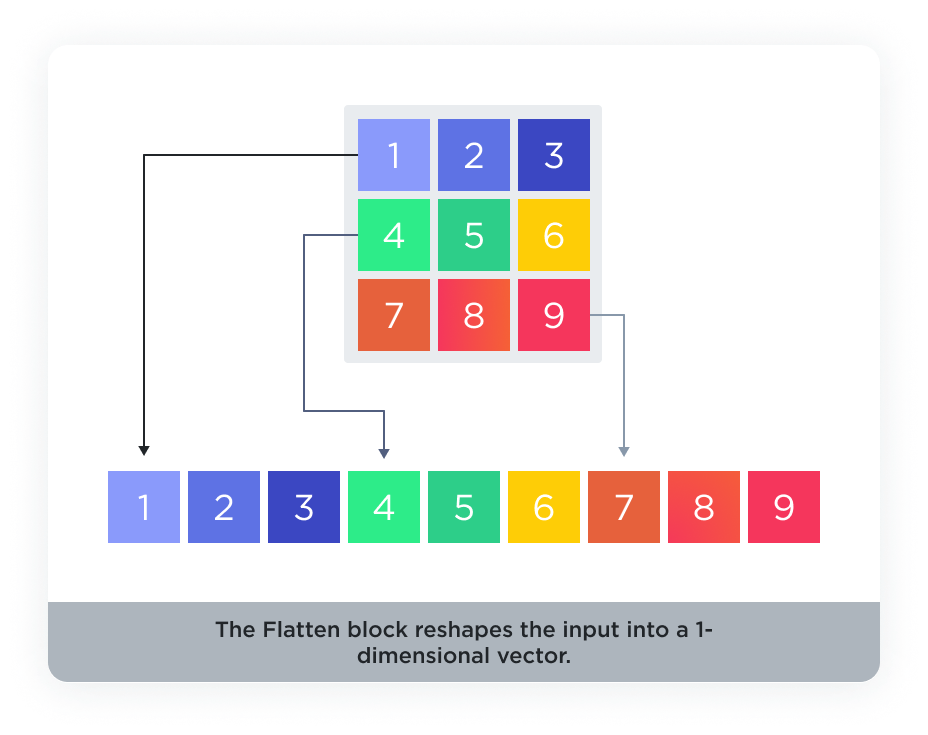
Dropout layer
The dropout layer is a regularization technique that reduces the risk of overfitting in neural networks. It does so by randomly setting a fraction of the input units to zero during each update of the training phase, which helps to make the network more robust and less sensitive to the specific weights of neurons.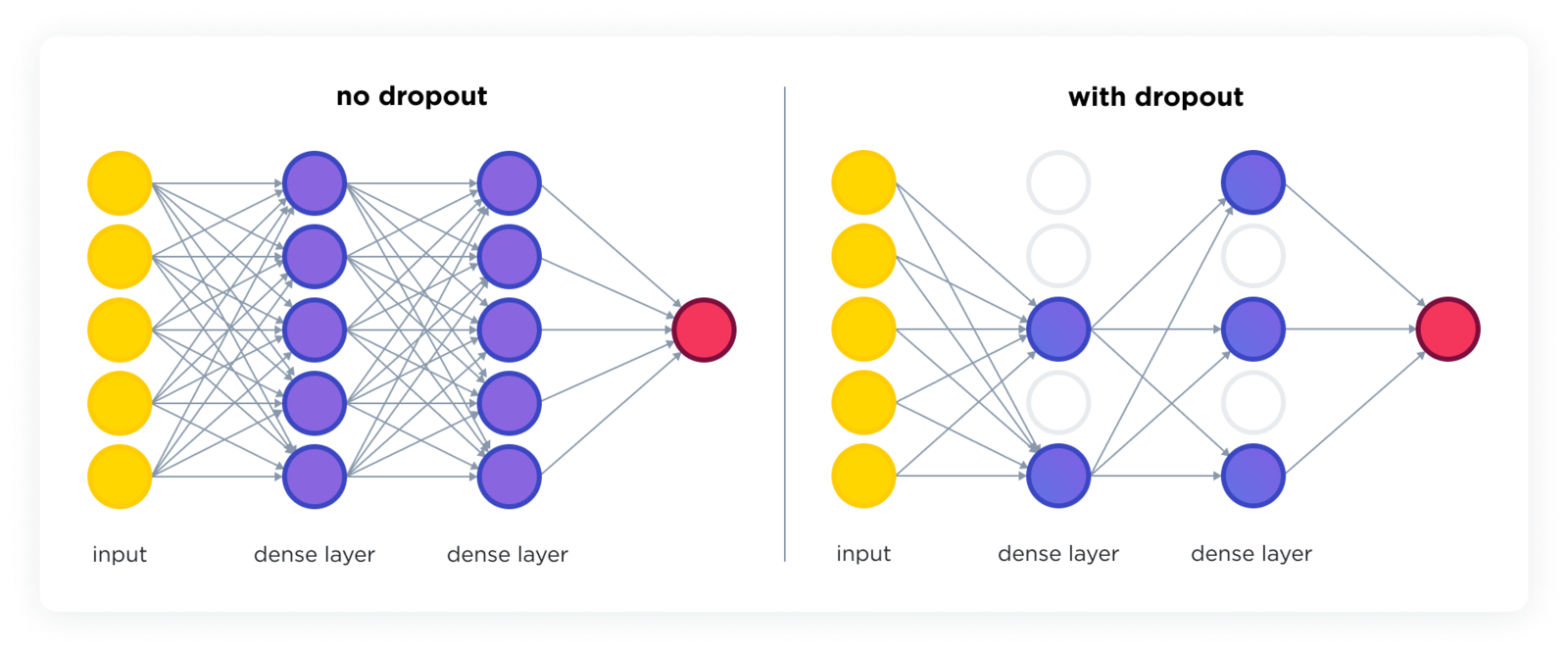
1D convolution layer
The 1D convolution layer is specifically designed for analyzing sequential data, such as audio signals or time-series data. This type of layer applies a series of filters to the input data to extract features. These filters slide over the data to produce a feature map, capturing patterns like trends or cycles that span over a sequence of data points.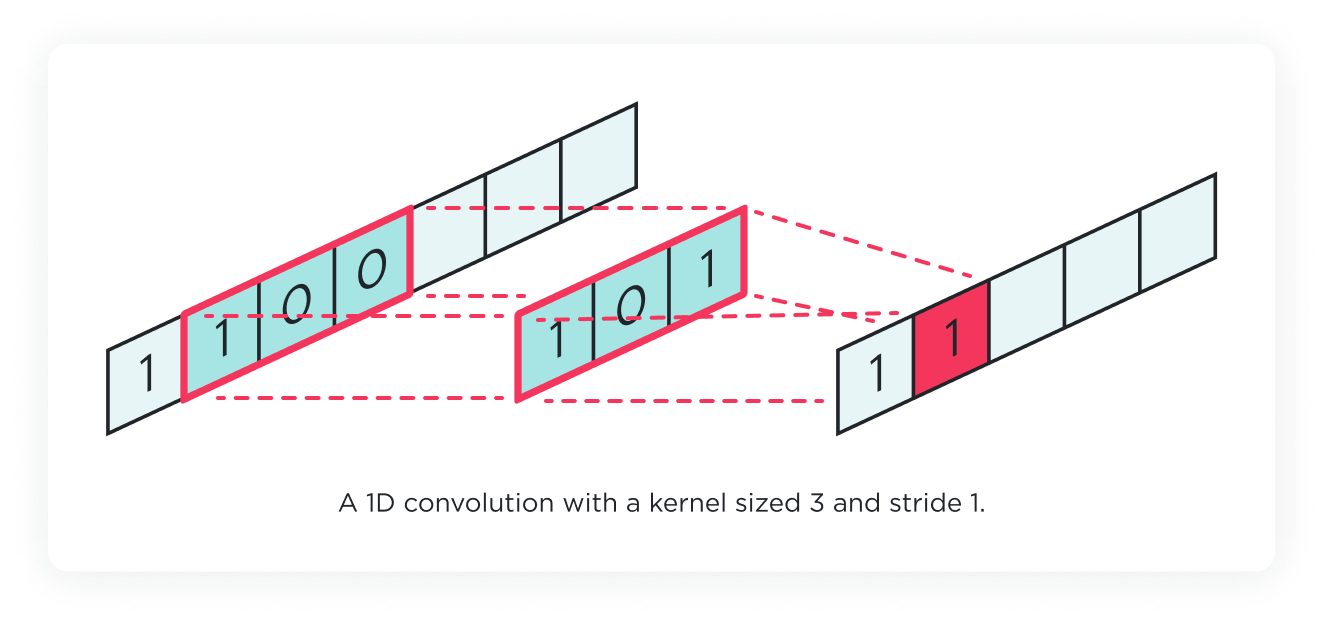
1D pooling layer
Complementing the 1D convolution layer, the 1D pooling layer aims to reduce the spatial size of the feature maps, thus reducing the number of parameters and computation in the network. It works by aggregating the information within a certain window, usually by taking the maximum (Max Pooling) or the average (Average Pooling) of the values. This operation also helps to make the detection of features more invariant to scale and orientation changes in the input data.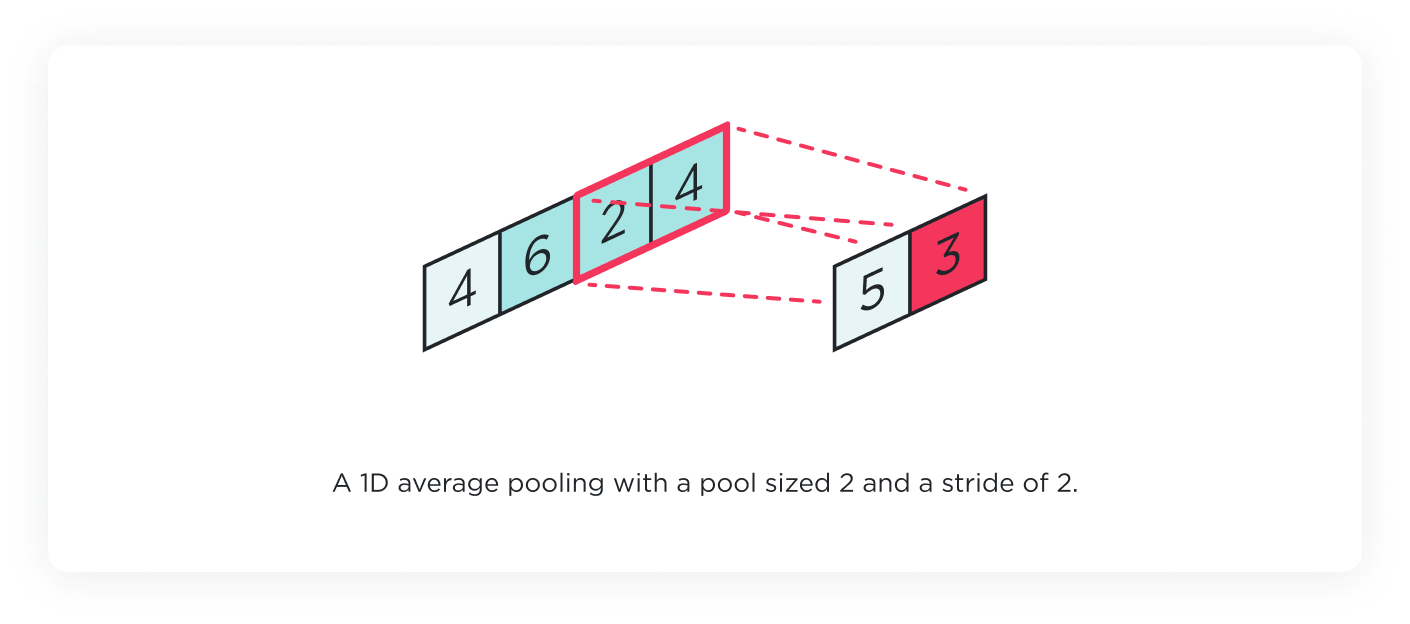
2D convolution layer
The 2D convolution layer is used primarily for image data and other two-dimensional input (like spectrograms). This layer operates with filters that move across the input image’s height and width to detect patterns like edges, corners, or textures. Each filter produces a 2D activation map that represents the locations and strength of detected features in the input.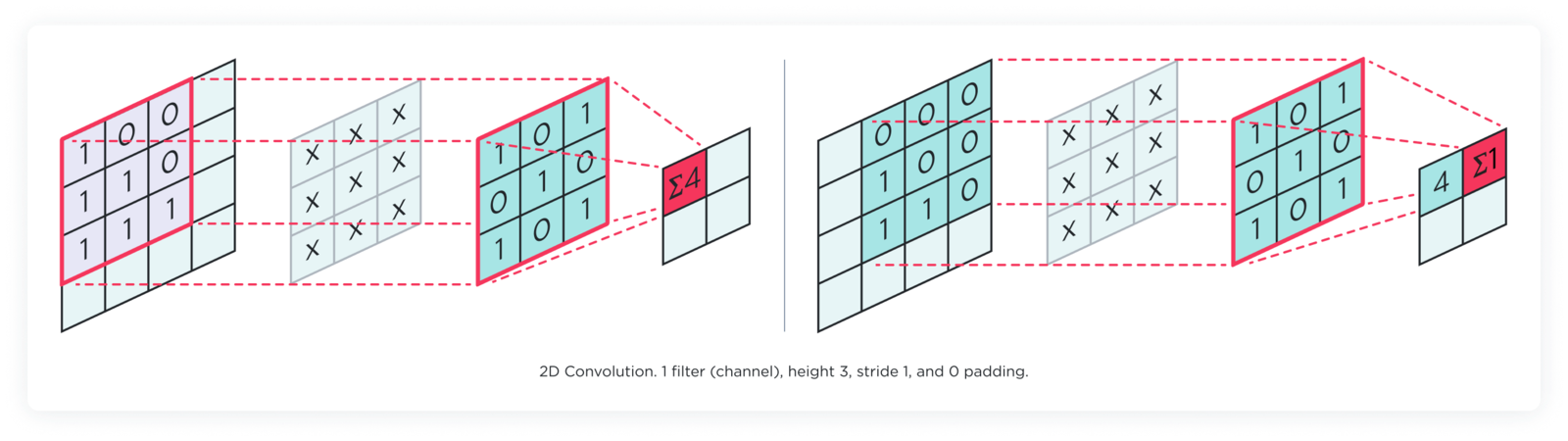
2D pooling layer
The 2D Pooling layer serves a similar purpose as its 1D counterpart but in two dimensions. After the convolution layer has extracted features from the input, the pooling layer reduces the spatial dimensions of these feature maps. It summarizes the presence of features in patches of the feature map and reduces sensitivity to the exact location of features. Max Pooling and Average Pooling are common types of pooling operations used in 2D Pooling layers.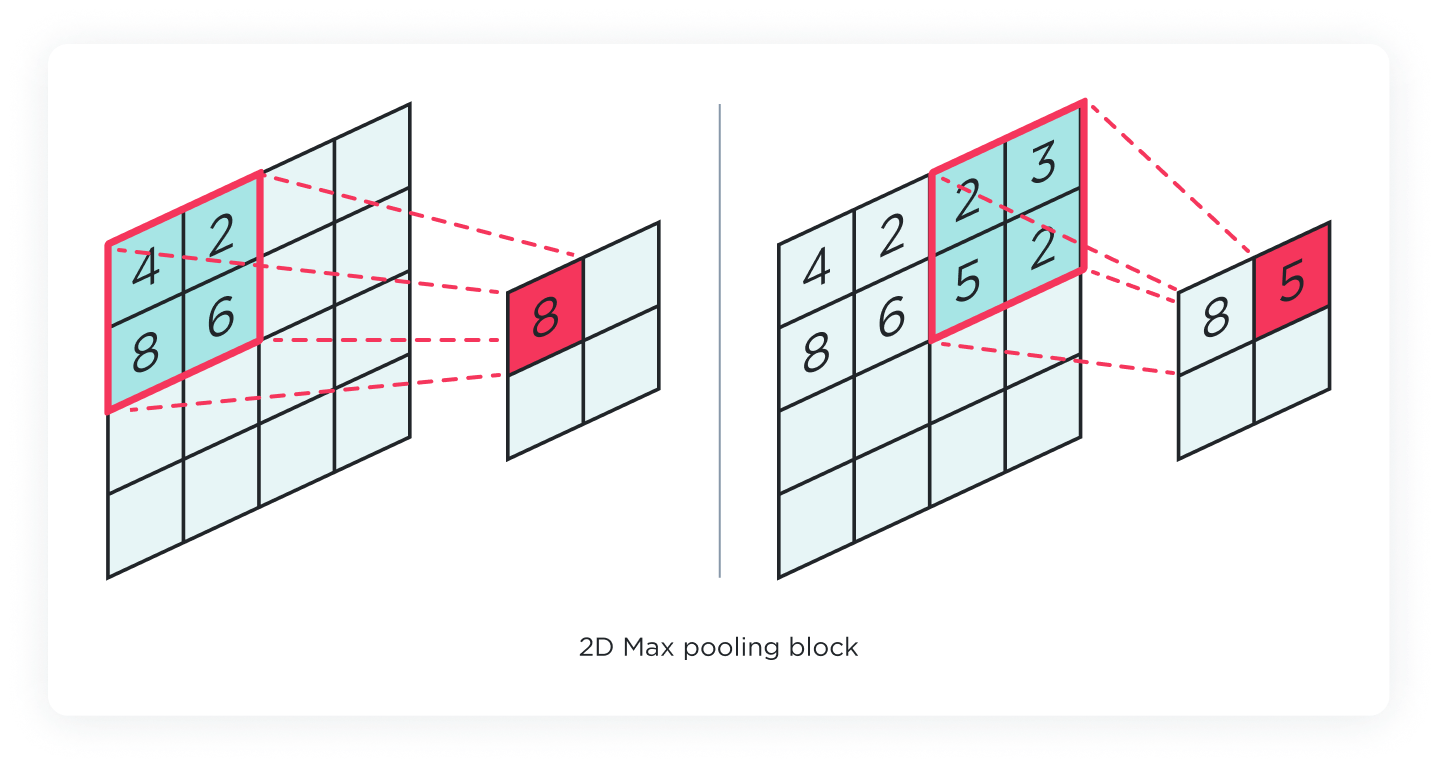
Output layer
The Output Layer is the final layer in a neural network architecture, responsible for producing the results based on the learned features and representations from the previous layers. Its design is closely aligned with the specific objective of the neural network, such as classification, regression, or even more complex tasks like image segmentation or language translation.Customizing layers in Edge Impulse
There are two options to modify the layers with Edge Impulse Studio. Either directly from the Neural Network Architecture panel where you can choose from a wide range of predefined layers, or using the expert mode to access the TensorFlow/Keras APIs. See below to understand how to build a model with multiple layers in Expert Mode.If you are an experienced ML practitioner, you can also bring your own model or bring your own architecture.Building a model with multiple layers in Expert Mode
- Import the necessary libraries
- Define your neural network architecture
- Compile and train your model