Differences between human and artificial intelligence
One way to understand AI is to compare it to human intelligence. In general, we consider human intelligence in terms of our ability to solve problems, set and achieve goals, analyze and reason through problems, communicate and collaborate with others, as well as an awareness of our own existence (consciousness). AI is the ability for machines to simulate and enhance human intelligence. Unlike humans, AI is still a rules-based system and does not need elements of emotions or consciousness to be useful. In their 2016 book, Artificial Intelligence: A Modern Approach, Stuart Russell and Peter Norvig define AI as “the designing and building of intelligent agents that receive precepts from the environment and take actions that affect that environment.”Machine learning vs. artificial intelligence
Machine learning is a subset of artificial intelligence. AI is a broad category that covers many systems and algorithms.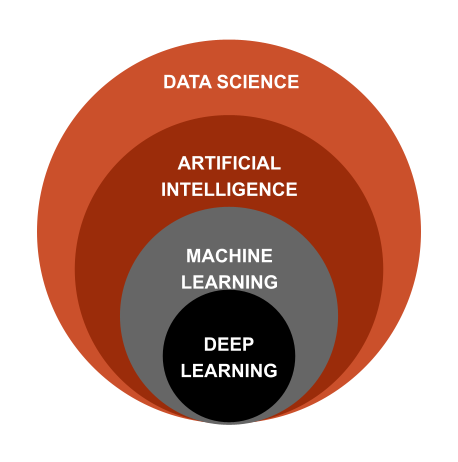
A brief history of AI
While AI seems like a recent invention, the study of mathematical models that can update themselves dates back to the 1700s.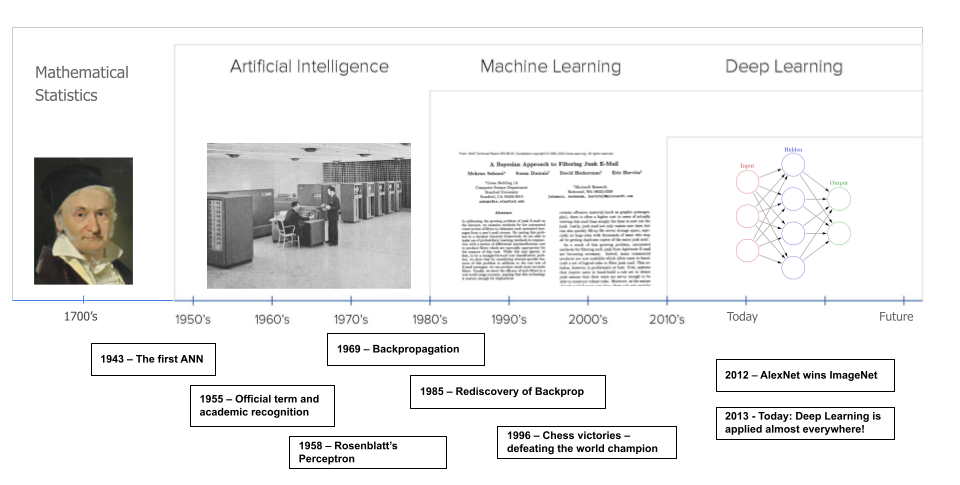
- Massive amounts of data is being generated from personal computers easily accessible via the internet
- Computers, including accelerators like graphics processing units (GPU), became powerful enough to run deep learning models with relative ease
- New, complex deep learning models were developed that surpassed classical, non-neural-network algorithms in accuracy
- Public interest surged with renewed vigor after several high-profile media publications, including Microsoft’s Kinect for Xbox 360 released in 2010, IBM Watson winning on Jeopardy in 2011, and Apple unveiling Siri in 2011
Categories of ML
Machine learning can be broadly categorized into supervised learning, unsupervised learning, and reinforcement learning.
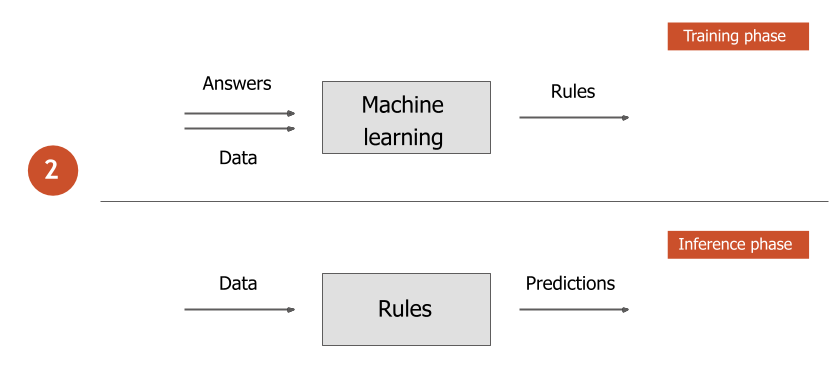
Traditional vs. machine learning algorithms
When developing traditional algorithms, the parameters and rules of the system are designed by a human. Such algorithms accept data as input and produce results.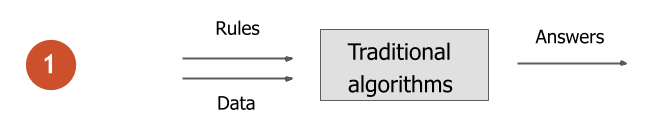
- Edge detection filters are used to extract meaning from images
- Sorting algorithms are popular with search engines to present web search results
- The Fourier transform is used in signal processing to convert a time-series data sample into its various frequency components
- Advanced Encryption Standard (AES) is a popular encryption protocol to keep data secret during transmission