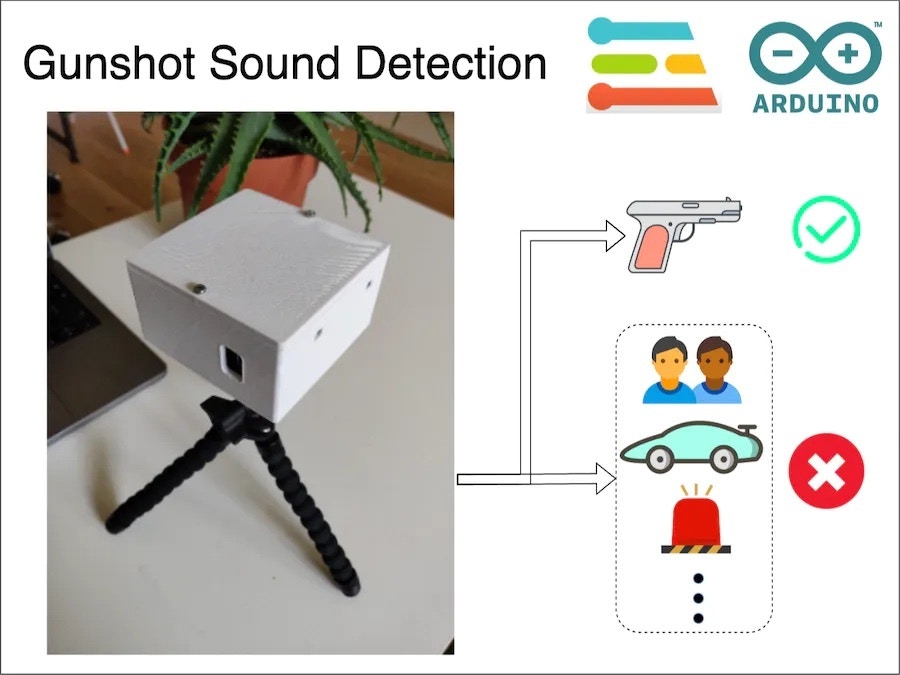
Intro Problem
On May 24, 2022, nineteen students and two teachers were fatally shot, and seventeen others were wounded at Robb Elementary School in Uvalde, Texas, United States[1]. An 18-year-old gunman entered the elementary school and started shooting kids and teachers with a semi-automatic rifle. The sad part is that it is not a one-off event. Gun violence including mass shootings is a real problem, especially in the USA.![Deaths due to gun violence in 2022 [2]](https://mintcdn.com/edgeimpulse/dNgo5Z6P3-vY-IBI/.assets/images/gunshot-audio-classification/problem1.jpg?fit=max&auto=format&n=dNgo5Z6P3-vY-IBI&q=85&s=f8f9a038762d0125ff25f0bb80586948)
![Deaths due to gun violence in 2022 [2]](https://mintcdn.com/edgeimpulse/dNgo5Z6P3-vY-IBI/.assets/images/gunshot-audio-classification/problem2.jpg?fit=max&auto=format&n=dNgo5Z6P3-vY-IBI&q=85&s=67d9ae6a6a206479024fc1e1a5e4c7f7)
What Can I Do About It?
Gun violence is a massive problem and I alone can not solve it, but I can definitely contribute an engineering solution toward hopefully minimizing casualties. Here I am proposing a proof of concept to identify gun sounds using a low-cost system and inform emergency services as soon as possible. Using this system, emergency services can respond to a gun incident as quickly as possible thus hopefully minimizing casualties.How Does It Work?
My low-cost proof of concept uses multiple microcontroller boards with microphones to capture sound. They use a TinyML algorithm prepared using Edge Impulse to detect any gunshot sound. Upon a positive detection, the system sends a notification to registered services via an MQTT broker.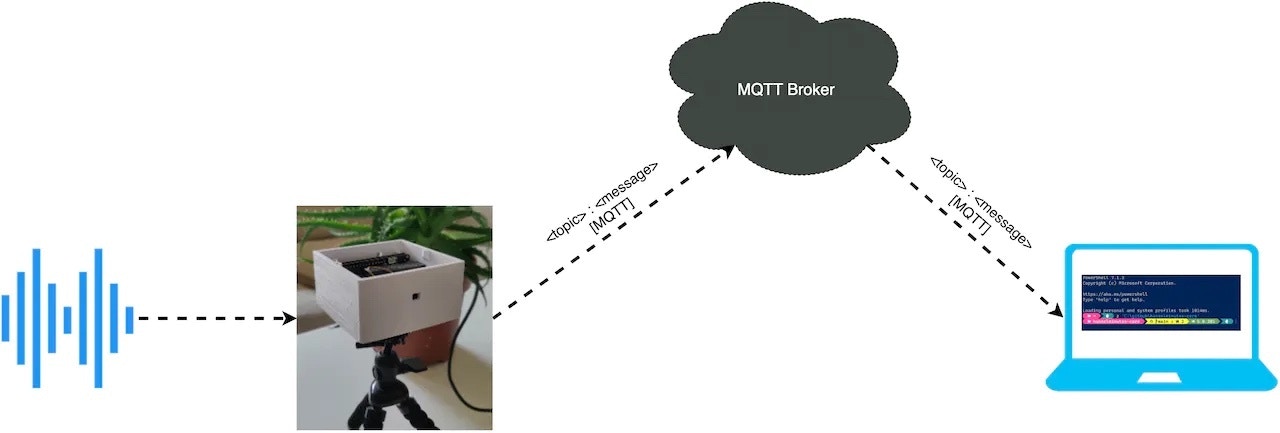
Hardware
The hardware I am using is:- Arduino Portenta H7
- Arduino Nano BLE Sense
- 9V Battery


Software
The software is divided into 2 main modules:- Machine Learning
- Communication
Machine Learning Module
The machine learning module uses a tinyML algorithm prepared using Edge Impulse. This module is responsible for identifying gunshot sounds. It takes sound as input and outputs its classification.Dataset
One of the most important parts of any machine learning model is its dataset. In this project, I have used a combination of two different datasets. For the gunshot class, I used the Gunshot audio dataset and for the other class, I used the UrbanSound8K dataset from Kaggle. Edge Impulse Studio’s Data acquisition tab provides useful features to either record your own data or upload already-collected datasets. I used the upload feature.
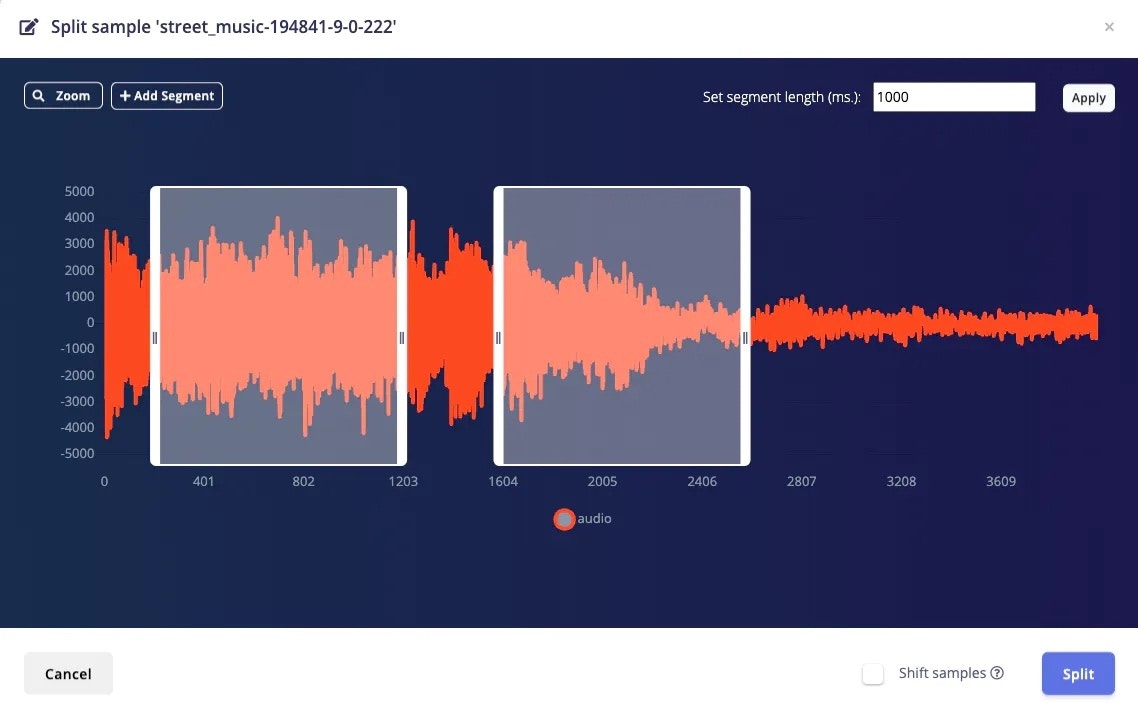

Training
After preparing the dataset, we need to design an Impulse. The Edge Impulse documentation explains the Impulse design in great detail so please check out their documentation page to learn about Impulse design.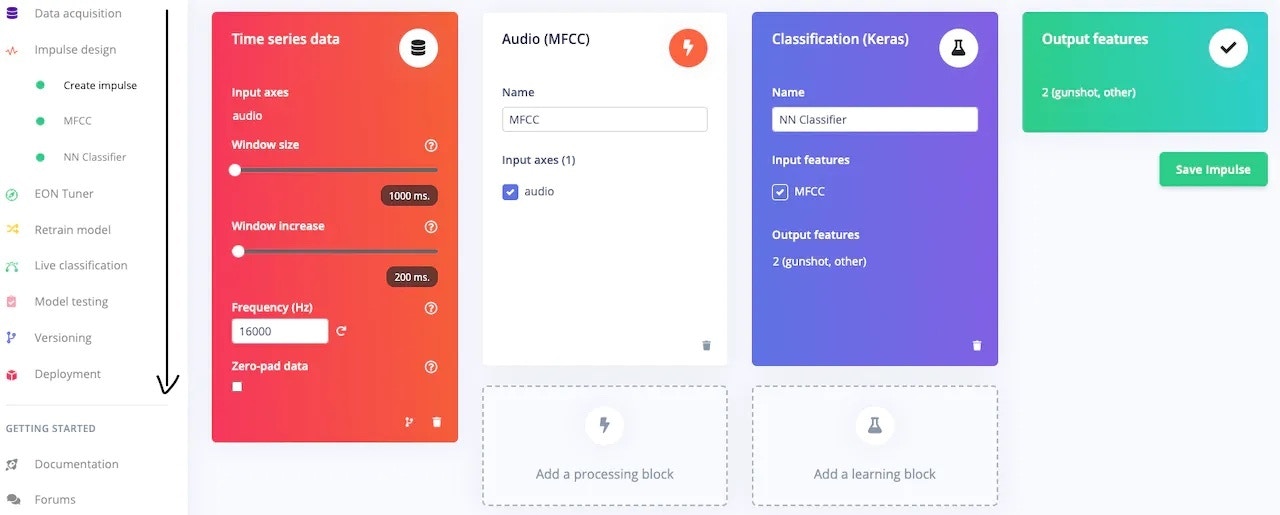
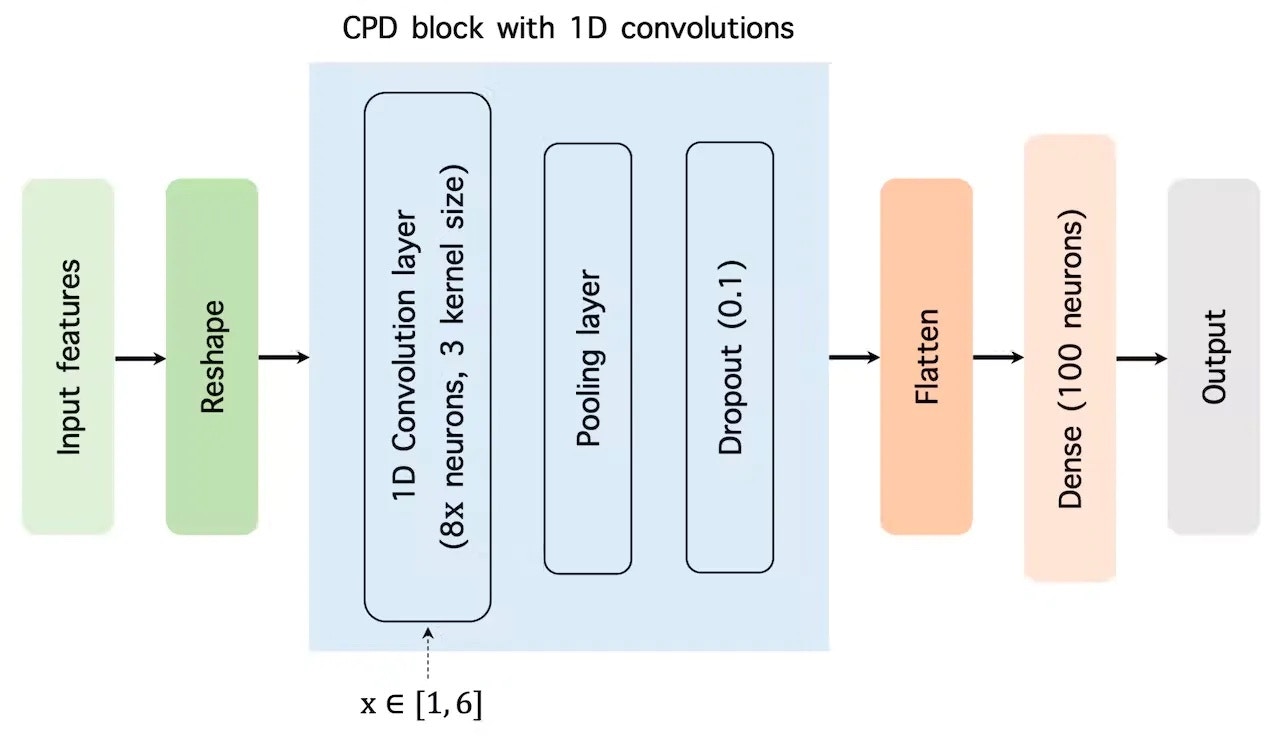
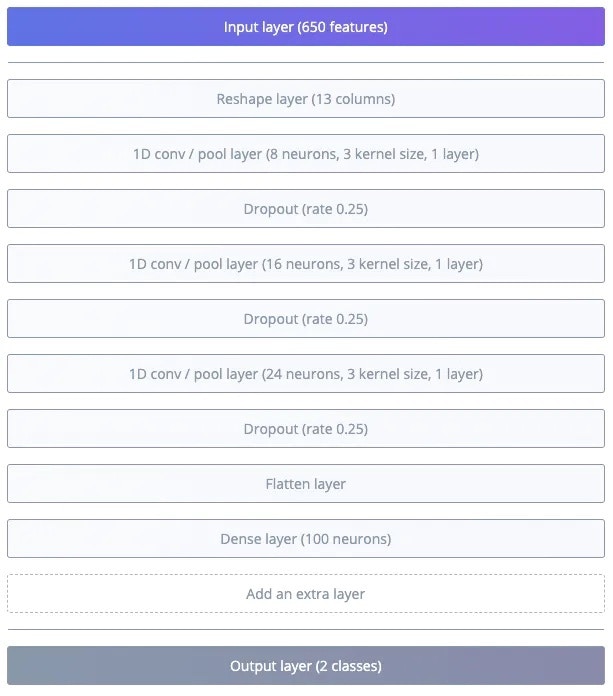
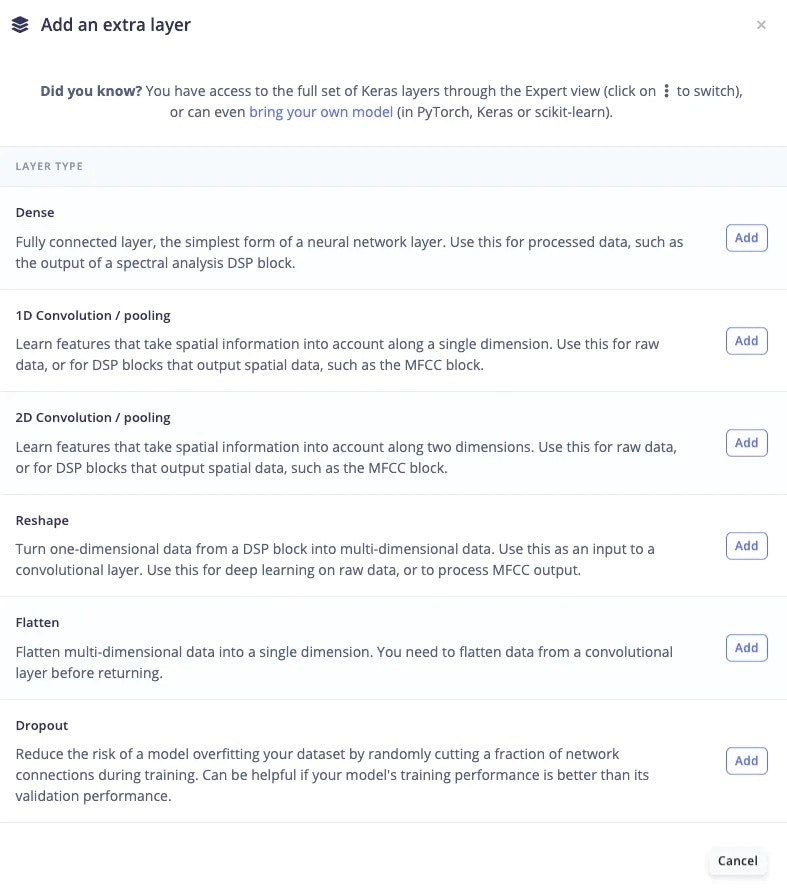
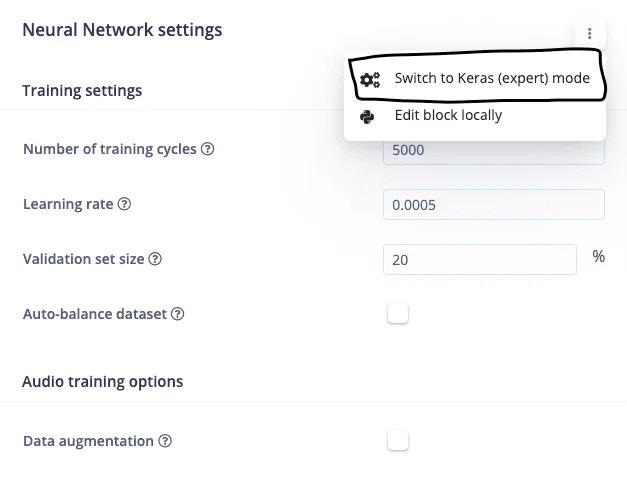
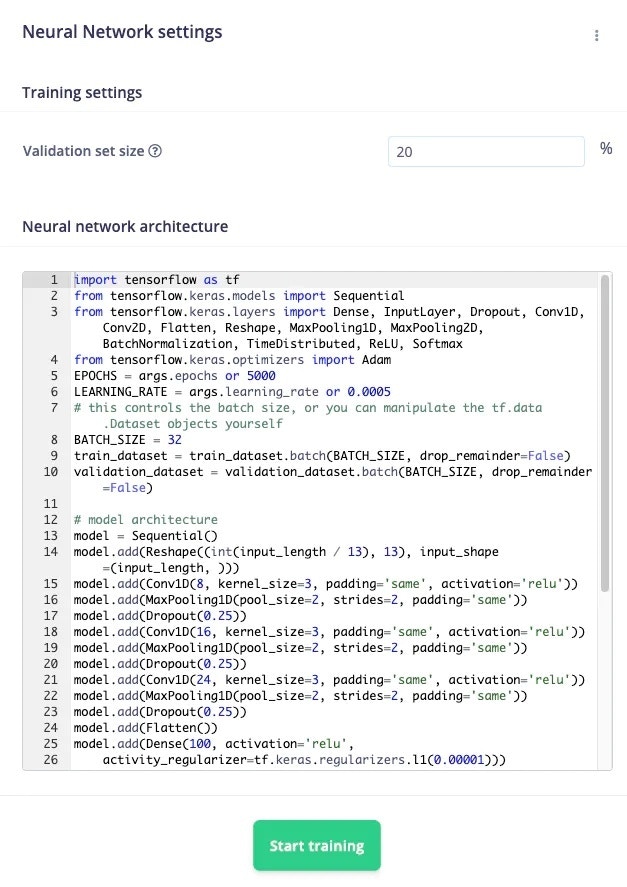
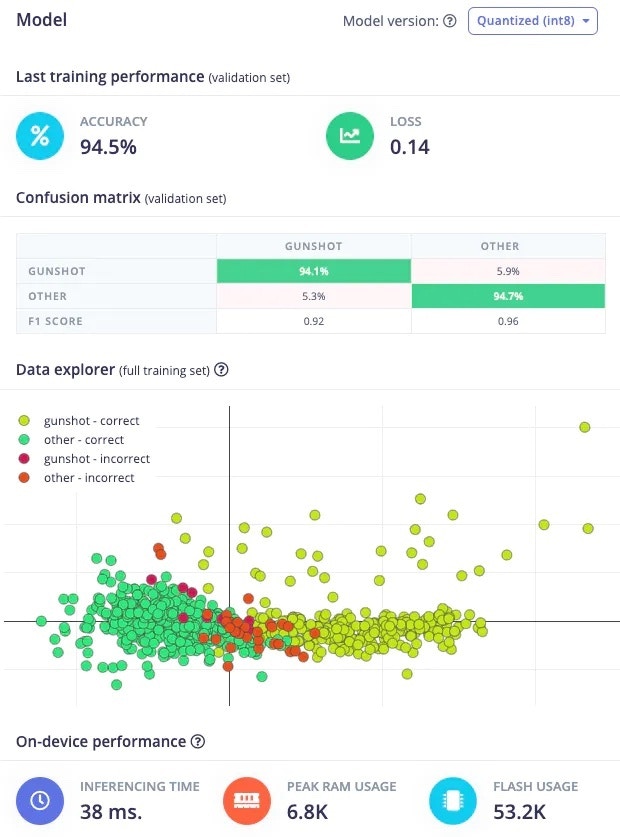
Testing
The Edge Impulse Studio’s Model testing tab enables a developer to test the model immediately. It uses the data from the test block and performs the inference using the last trained model. My model had 91.3% accuracy on the test data.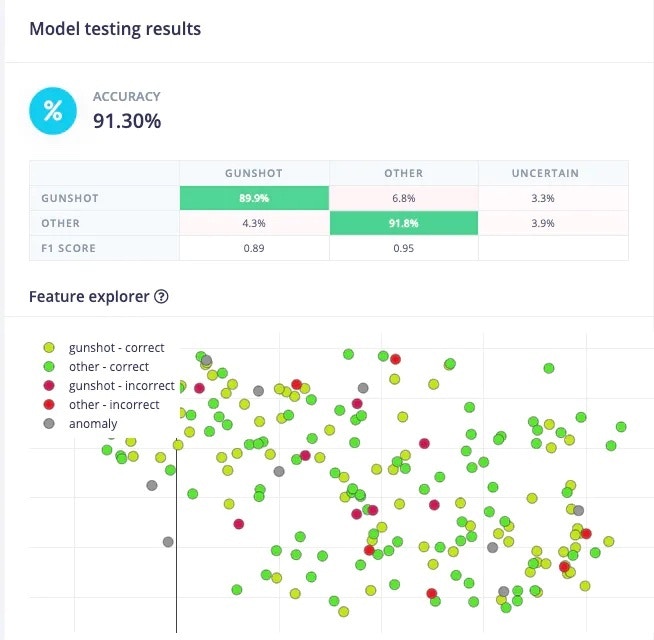
Versioning
One nice feature Edge Impulse provides is versioning. You can version your project (like Git) to store all data, configuration, intermediate results and final models. You can revert back to earlier versions of your impulse by importing a revision into a new project. I use this feature every time before changing the neural network architecture. That way I don’t have to retrain or keep a manual record of the previous architecture.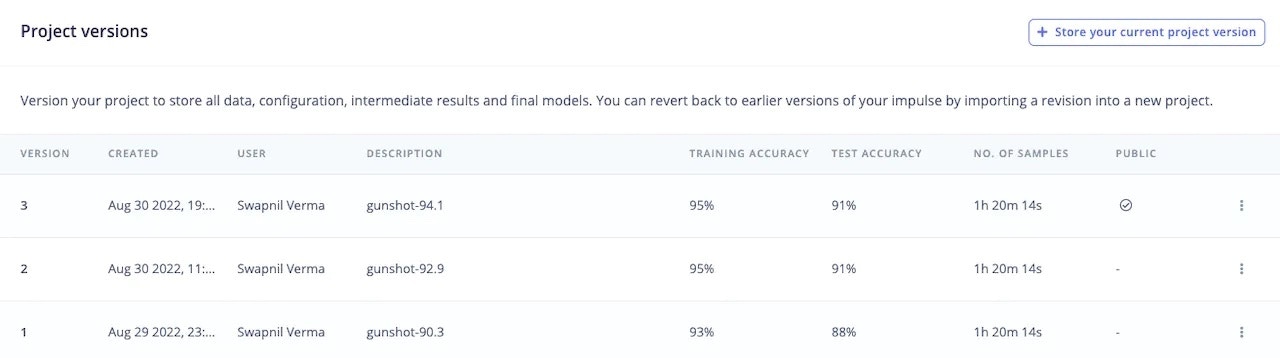
Deployment
After completing the training, it’s time for deployment. The Deployment tab of the Edge Impulse Studio provides three main ways of deploying the model onto hardware: (a) by creating a library (b) by building firmware, and (c) by running it on a computer or a mobile phone directly. I knew that I need more functionality from my Arduino hardware apart from inferencing, so I created a library instead of building firmware.

Inferencing
Inferencing is the process of running a neural network model to generate output. The image below shows the inference pipeline.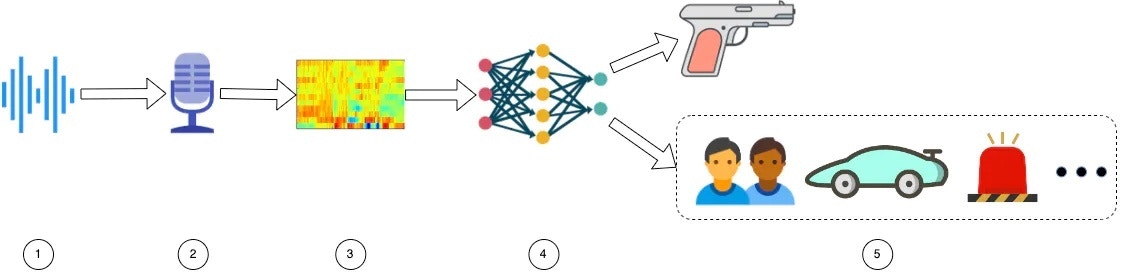
Project Link - https://studio.edgeimpulse.com/public/133765/latestThe output of the machine learning module is then processed before sending it to the cloud via the Communication module.
Communication Module
This module is responsible for sharing information between boards and sending positive predictions to the registered emergency services.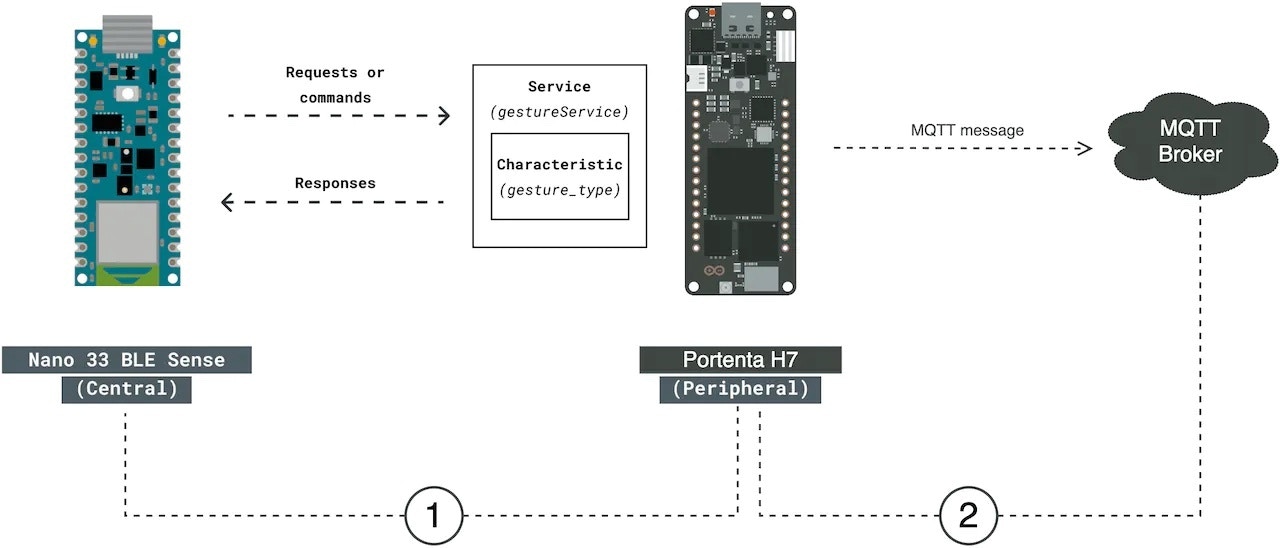
Software Link - https://github.com/sw4p/Gunshot_Detection
Testing
My testing setup and the result are illustrated in the video below. The system is connected to my laptop which is also performing the screen recording. On the upper left side, we have an Arduino serial window which is showing the output from the Portenta H7, and on the lower left hand, we have an audio player. On the right-hand side, we have cloudMQTT’s WebSocket UI, which shows the incoming notification via MQTT. The sound for this video is played and recorded using my laptop’s speaker and microphone.
In the video above I am playing different categories of sound and one of that categories is a gunshot. The system outputs the classification result to the Arduino serial port whenever it detects a sound from the other class but does not send it to the receiver. The moment it detects a gunshot sound, it immediately sends a notification to the receiver via CloudMQTT.