
Introduction
In the era of smart devices and voice-controlled technology, developing effective keyword spotting (KWS) systems is crucial for enhancing user experience and interaction. This documentation provides a comprehensive guide for creating a portable LED product with KWS capabilities, using Edge Impulse’s end-to-end synthetic data pipeline. Synthetic voice/speech data, generated artificially rather than collected from real-world recordings, offers a scalable and cost-effective solution for training machine learning models. By leveraging AI text-to-speech technologies, we can create diverse and high-quality datasets tailored specifically for our KWS applications. This guide not only serves as a blueprint for building a responsive LED product but also lays the groundwork for a wide range of voice-activated devices, such as cameras that start recording on command, alarms that snooze with a keyword, or garage doors that respond to voice prompts.Problem Exploration
Traditional methods of training keyword spotting models often rely on extensive datasets of human speech, which can be time-consuming and expensive to collect. Moreover, ensuring diversity and representation in these datasets can be challenging, leading to models that may not perform well across different accents, languages, and speaking environments. Synthetic data addresses these challenges by providing a controlled and flexible means of generating speech data. Using AI text-to-speech technology, we can produce vast amounts of speech data with varied voices, tones, and inflections, all tailored to the specific keywords we want our models to detect. This approach opens up numerous possibilities for product development. For instance, a smart LED light can be designed to turn on or off in response to specific voice commands, enhancing convenience and accessibility. A camera can be programmed to start recording or take a group photo when a designated keyword is spoken, making it easier to capture moments without physical interaction. Similarly, an alarm system can be configured to snooze with a simple voice command, streamlining the user experience. By utilizing synthetic data, developers can create robust and versatile KWS models that power these innovative applications, ultimately leading to more intuitive and responsive smart devices.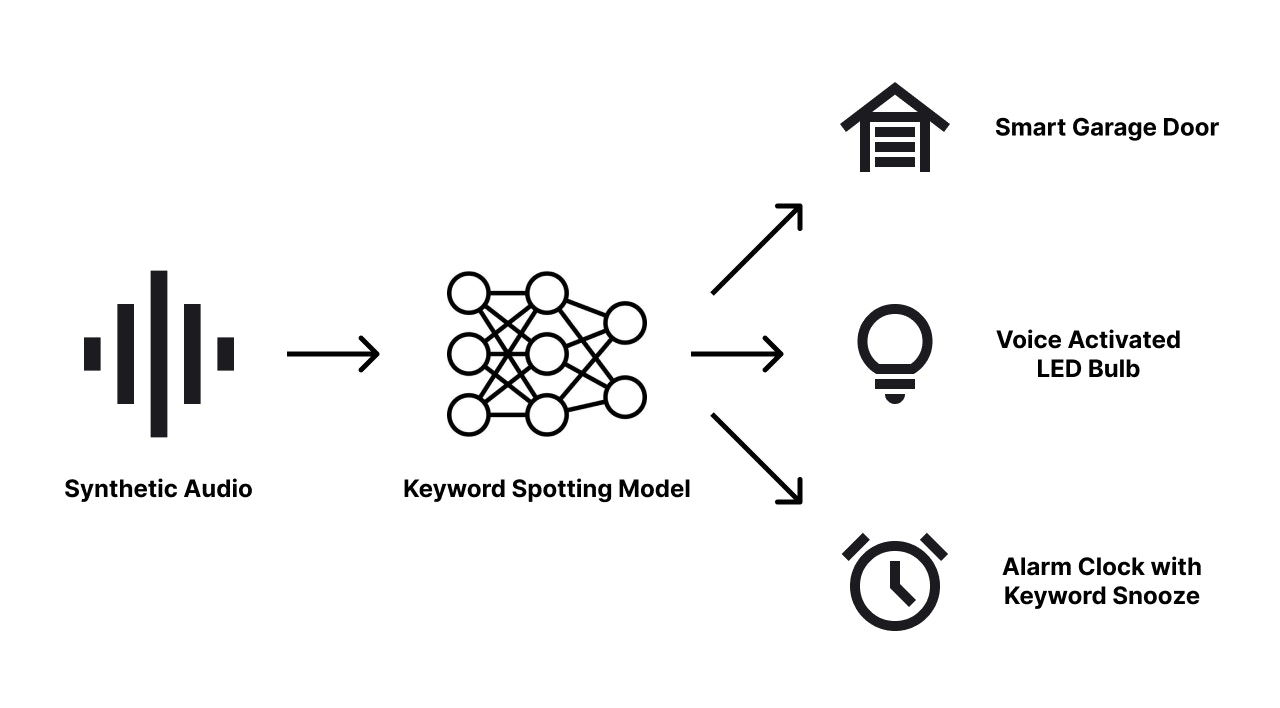
Project Overview
This project outlines the creation of a keyword spotting (KWS) product using Edge Impulse’s synthetic data pipeline. The process involves generating synthetic voice data with OpenAI’s Whisper text-to-speech model via Edge Impulse Studio and training the KWS model using Syntiant’s audio processing blocks for the NDP120 on the Arduino Nicla Voice. The phrase ‘illuminate’ and ‘extinguish’ will be generated and used for training the model. After training, the model is deployed onto the Arduino Nicla Voice hardware. A custom PCB and casing are designed to incorporate LED lights and power circuitry, ensuring portability and ease of use. This guide serves as a practical resource for developers looking to implement KWS functionality in voice-activated devices, demonstrating the efficiency of synthetic data in creating responsive and versatile products.
Hardware selection: Arduino Nicla Voice
The Arduino Nicla Voice is an ideal choice for this project due to its use of the Syntiant NDP120, which offers great power efficiency for always-on listening. This efficiency allows the NDP120 to continuously monitor for keywords while consuming minimal power, making it perfect for battery-powered applications. Upon detecting a keyword, the NDP120 can notify the secondary microcontroller, Nordic Semiconductor nRF52832, which can then be programmed to control the lighting system. The compact size of the Nicla Voice also makes it easy to integrate into a small case with a battery. Furthermore, the Nicla Voice’s standardized footprint simplifies the prototyping process, allowing for the easy creation of a custom PCB module with LED circuitry that can be easily connected.
Hardware Requirements
- Arduino Nicla Voice (or other Edge Impulse supported MCU with mic)
- PCB and SMD components (parts breakdown explained later)
Software Requirements
- Edge Impulse CLI
- Arduino IDE
- OpenAI API account
Dataset Collection
Creating an OpenAI API Secret Key
To create an OpenAI API secret key, start by visiting the OpenAI website. If you don’t have an account, sign up; otherwise, log in. Once logged in, navigate to the API section by clicking on your profile icon or the navigation menu and selecting “API” or “API Keys.” In the API section, click on “Create New Key” or a similar button to generate a new API key. You may be prompted to name your API key for easy identification. After naming it, generate the key and it will be displayed to you. Copy the key immediately and store it securely, as it might not be visible again once you navigate away from the page. You can now use this API key in your applications to authenticate and access OpenAI services, for this project we will use the API key for generating synthetic voice data via Edge Impulse’s transformation blocks. Ensure you keep your API key secret and do not expose it in client-side code or public repositories. You can manage your keys (regenerate, delete, or rename) in the API section of your OpenAI account. For more detailed instructions or troubleshooting, refer to the OpenAI API documentation or the help section on the OpenAI website.
Generating TTS Synthetic Data
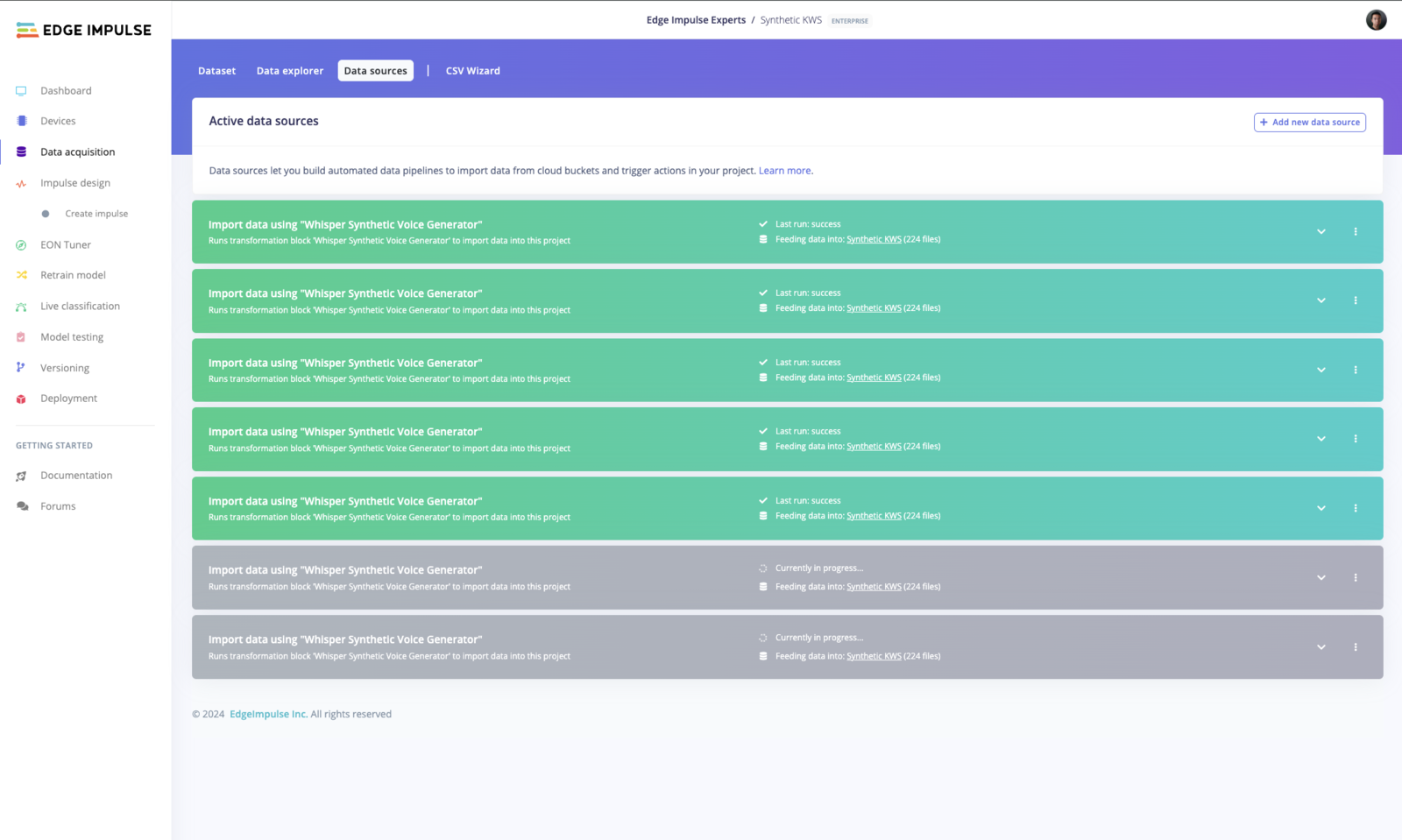
Now that we have the environment configured, and our OpenAI API saved in the Edge Impulse Studio, we are ready to start a new project and begin generating some synthetic voice data. On your project’s page select Data acquisition —> Data sources —> + Add new data source —> Transformation block —> Whisper Synthetic Voice Generator —> Fill out the details as follow: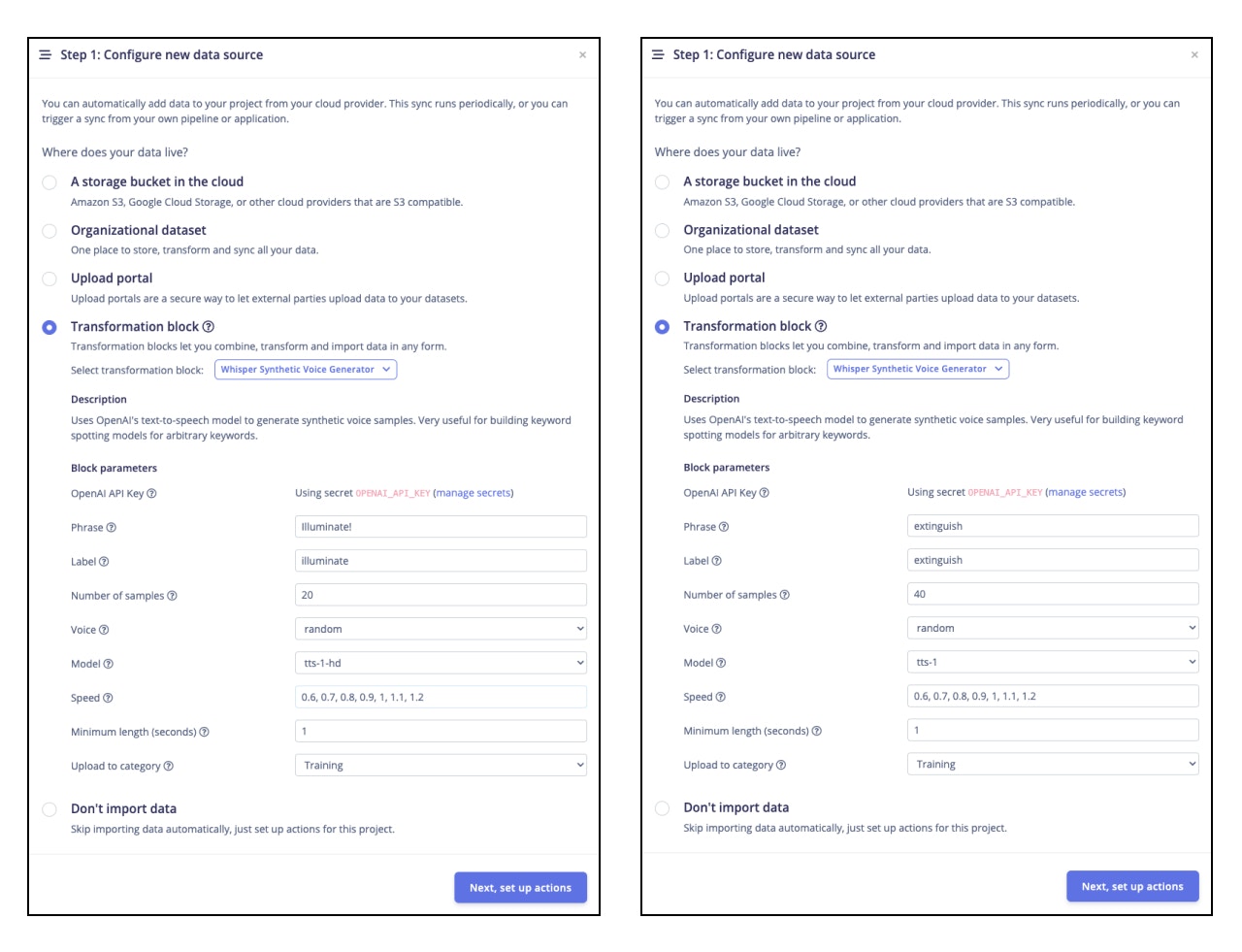
Impulse Design
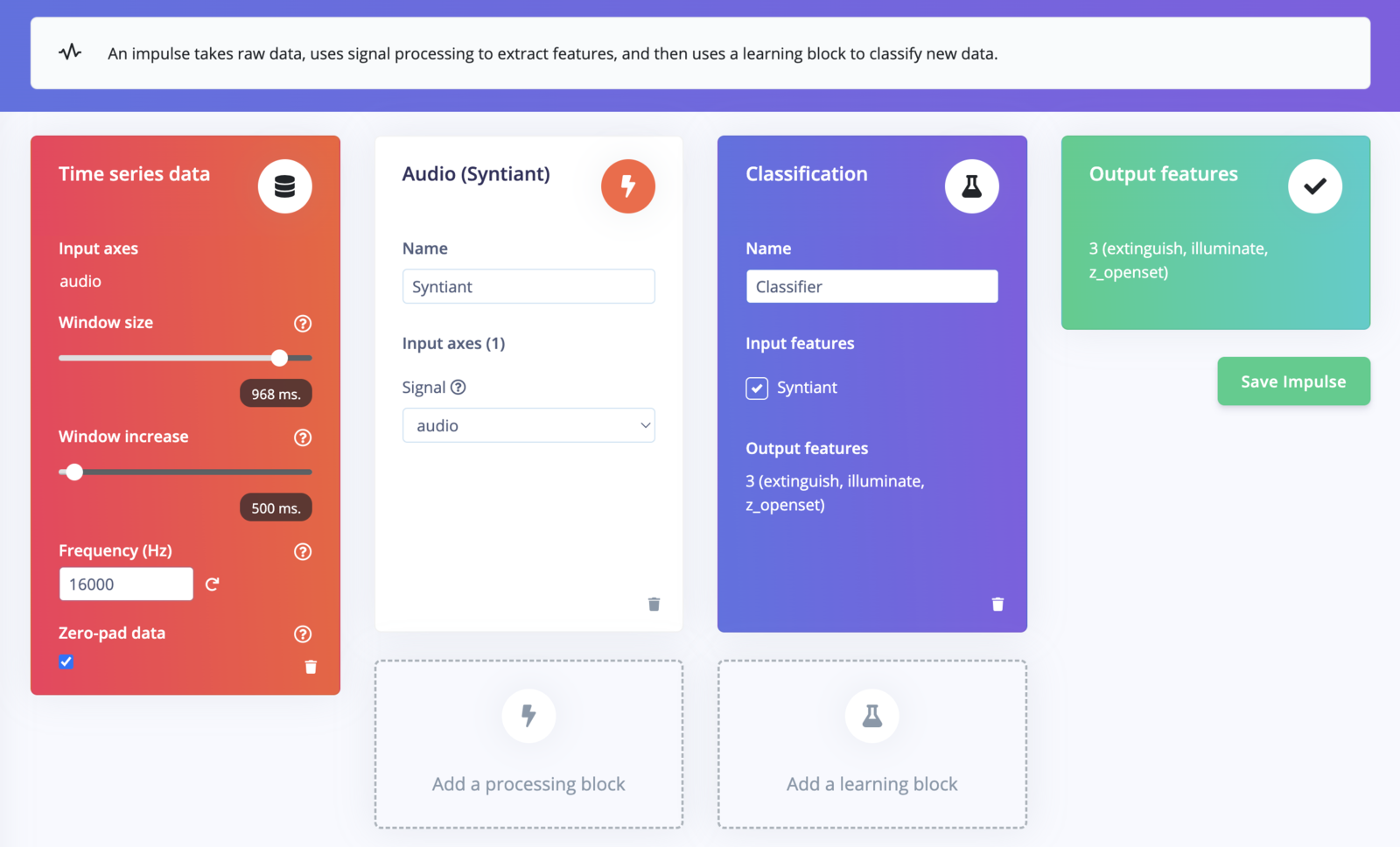
- Window size: 968 ms
- Window increase: 500 ms
- Frequency: 16000 Hz
- Audio (Syntiant)
- Classification
- Output: extinguish, illuminate, z_openset
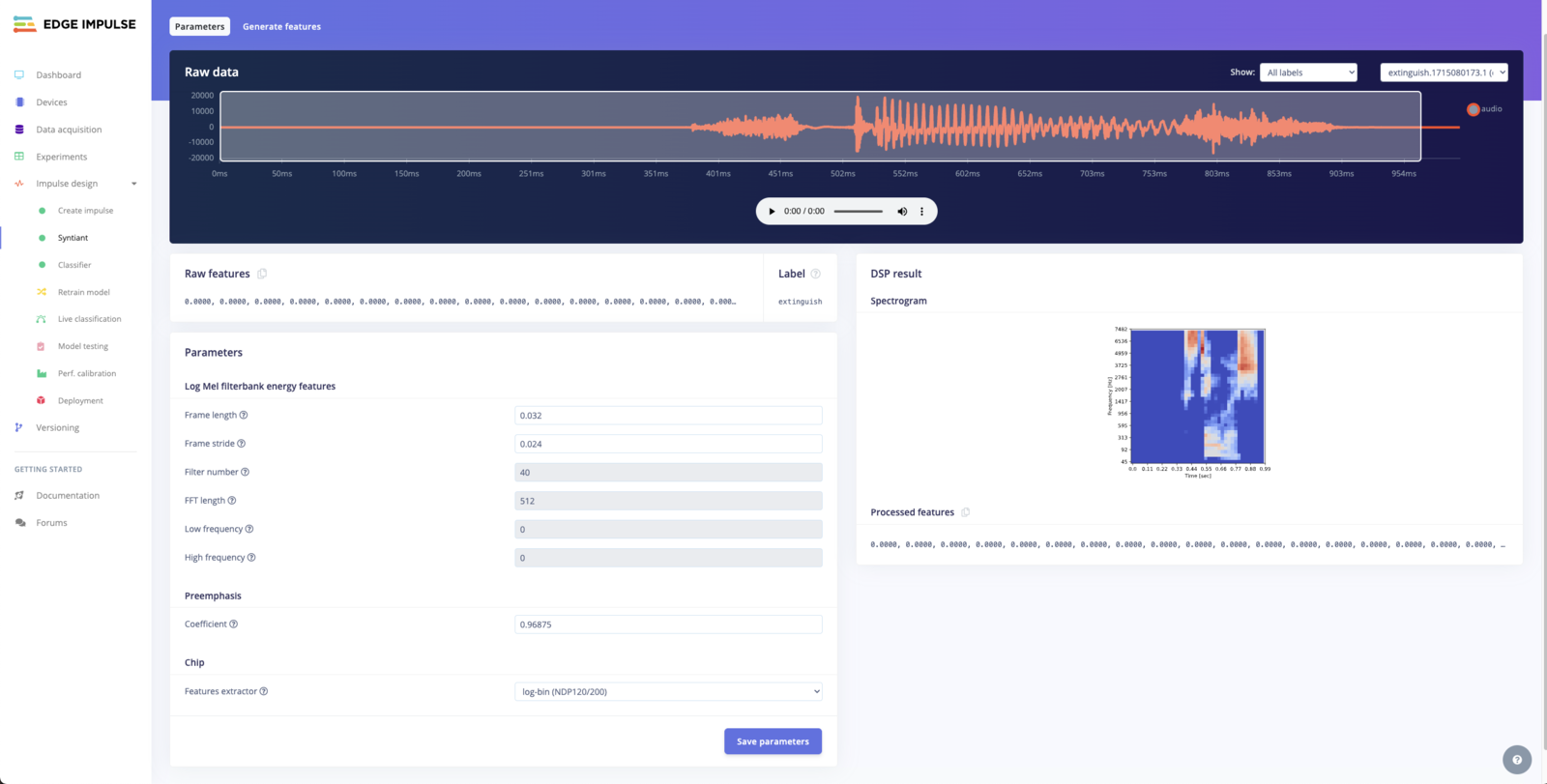
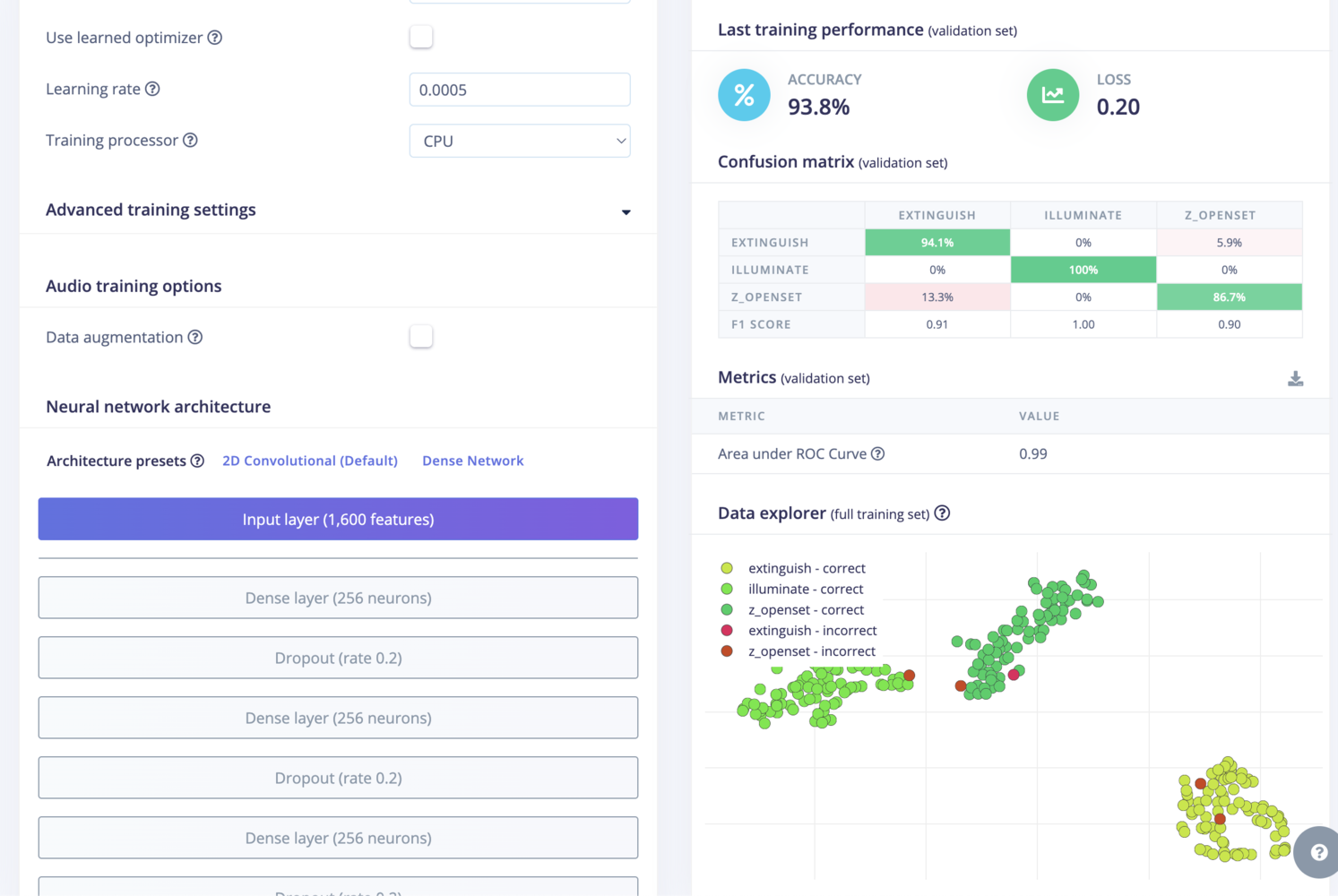
Deployment
Now the AI model is ready to be deployed to the Arduino Nicla Voice. Let’s select the Arduino Nicla Voice deployment.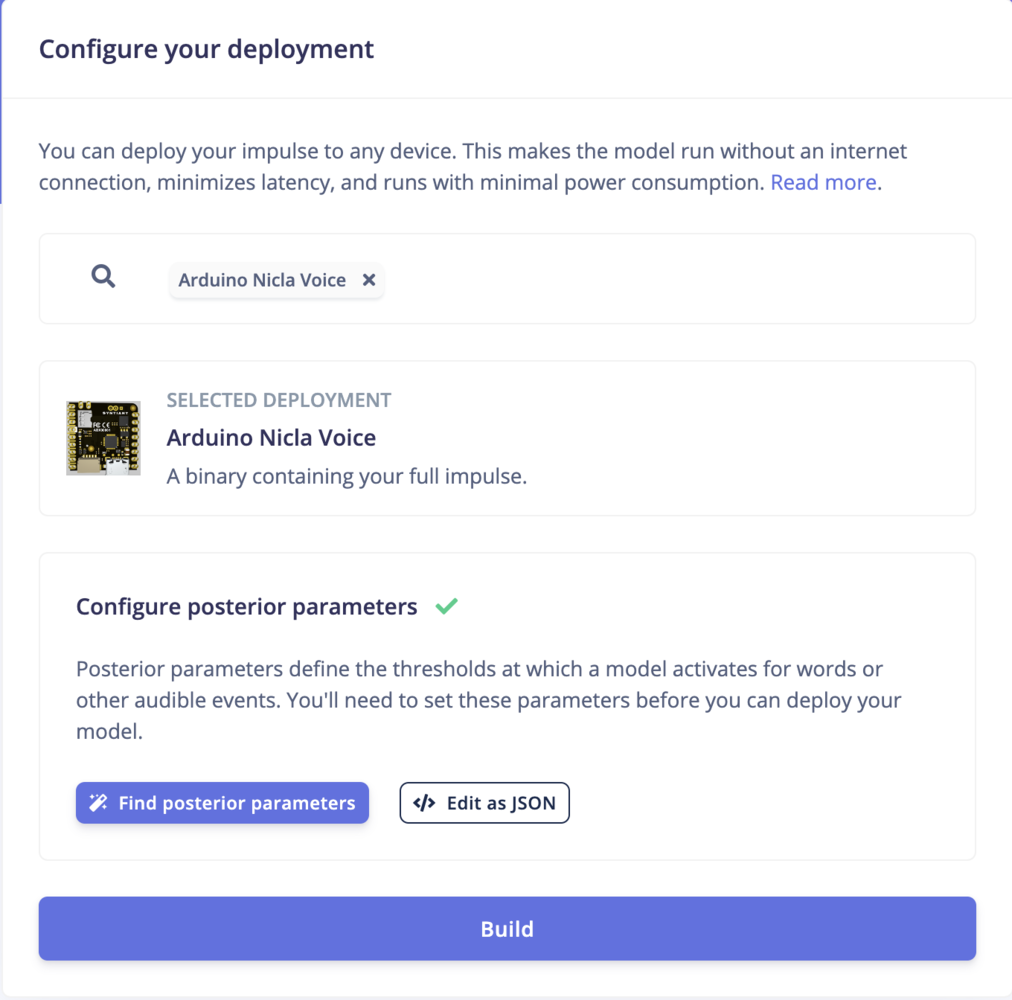
Designing and Building the KWS Product
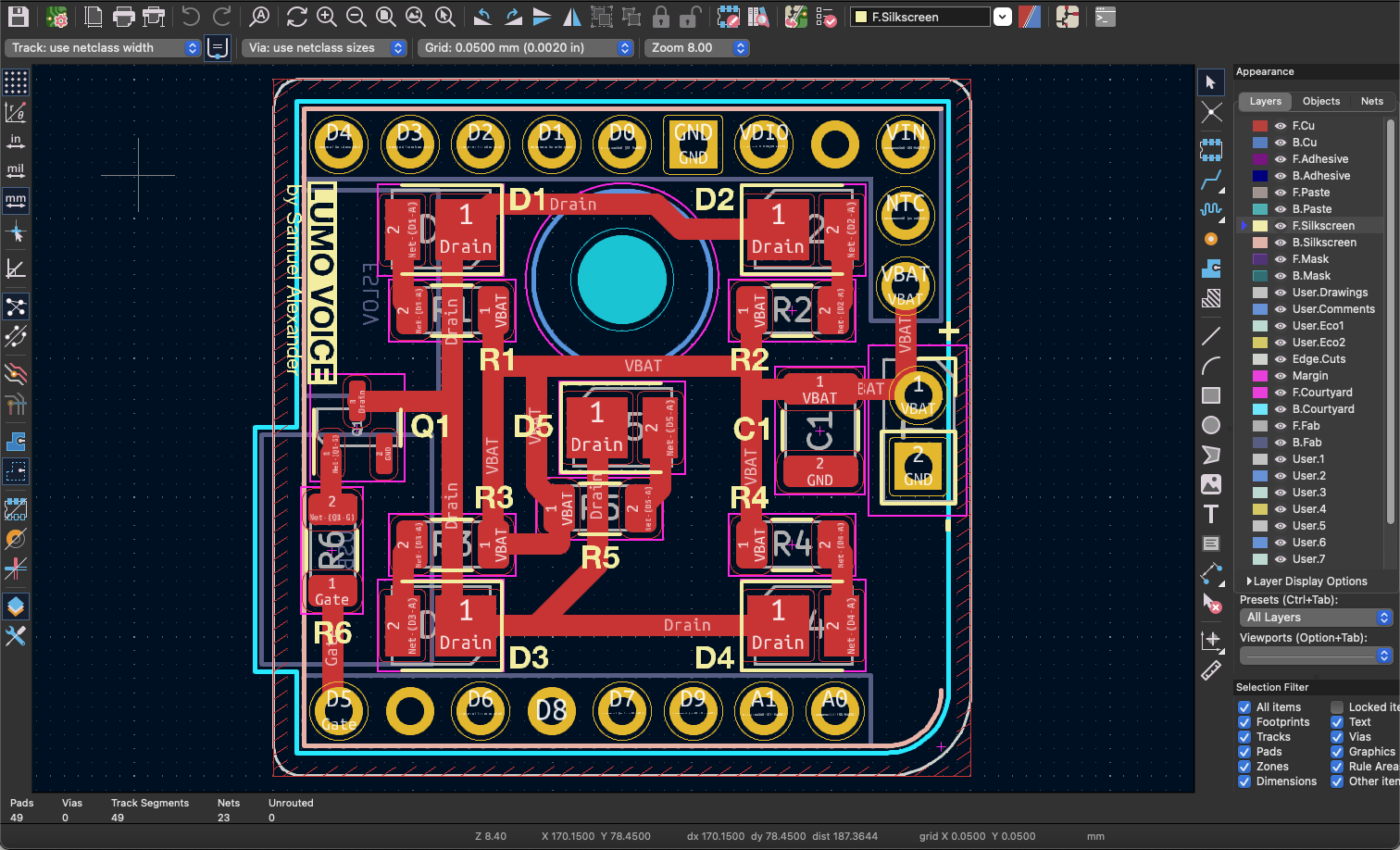
The schematic and PCB is designed using KiCAD. A single sided aluminum PCB is selected for this project due to its excellent thermal conductivity, which helps dissipate heat generated by the LEDs and other components, ensuring reliable performance and longevity. The design of this PCB is simple enough to make it possible to route using one side only. The schematic, pcb, and gerber (manufacturing) files are accessible in the project’s github page.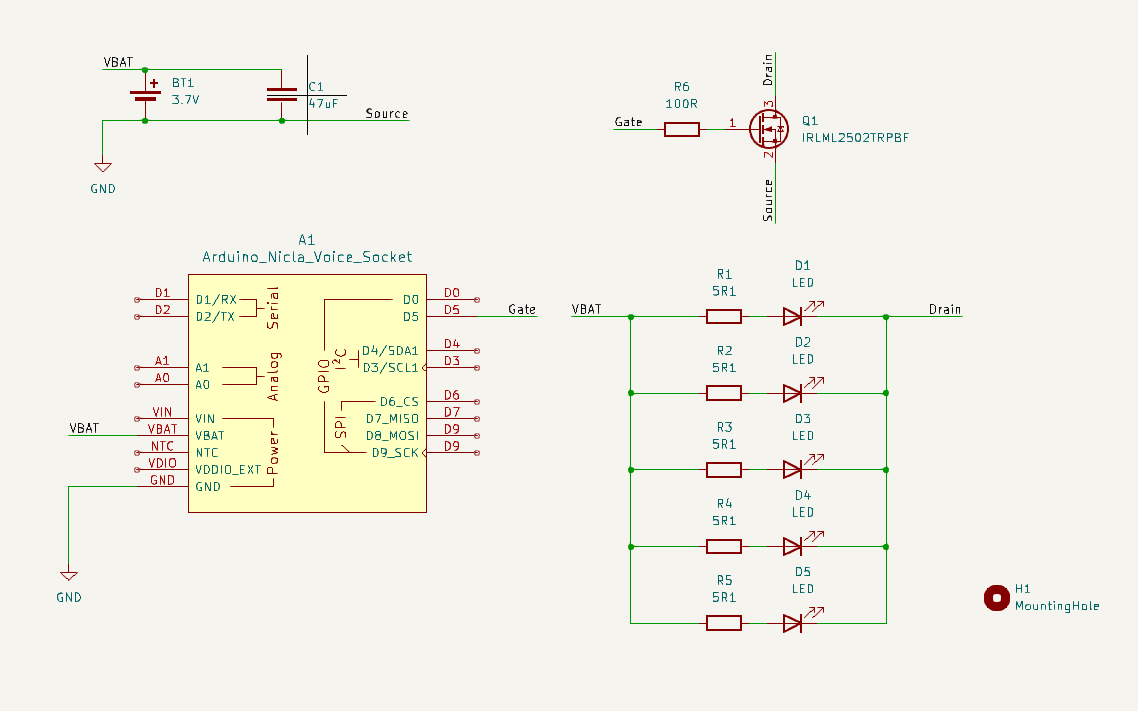
| LCSC Part Number | Manufacture Part Number | Manufacturer | Package | Description | Order Qty. | Unit Price($) | Order Price($) |
|---|---|---|---|---|---|---|---|
| C176224 | QR1206F5R10P05Z | Ever Ohms Tech | 1206 | 250mW Thick Film Resistors 200V ą1% ą400ppm/? 5.1? 1206 Chip Resistor - Surface Mount ROHS | 50 | 0.0156 | 0.78 |
| C516126 | HL-AM-2835H421W-S1-08-HR5(R9) (2800K-3100K)(SDCM<6,R9>50) | HONGLITRONIC(Hongli Zhihui (HONGLITRONIC)) | SMD2835 | 60mA 3000K Foggy yellow lens -40?~+85? Positive Stick White 120° 306mW 3.4V SMD2835 LED Indication - Discrete ROHS | 50 | 0.0144 | 0.72 |
| C2589 | IRLML2502TRPBF | Infineon Technologies | SOT-23 | 20V 4.2A 1.25W 45m?@4.5V,4.2A 1.2V@250uA 1 N-Channel SOT-23 MOSFETs ROHS | 5 | 0.1838 | 0.92 |
| C5440143 | CS3225X7R476K160NRL | Samwha Capacitor | 1210 | 16V 47uF X7R ą10% 1210 Multilayer Ceramic Capacitors MLCC - SMD/SMT ROHS | 5 | 0.0765 | 0.38 |
| C153338 | FCR1206J100RP05Z | Ever Ohms Tech | 1206 | 250mW Safety Resistor 200V ą5% 100? 1206 Chip Resistor - Surface Mount ROHS | 10 | 0.0541 | 0.54 |
