Intro to Hugging Face
The Hugging Face Hub is a large machine learning community and platform with over 18,000 open-source and publicly available datasets, over 120,000 created models, and applications (called Spaces) that leverage AI to perform a task. This open and community-centric approach allows people to easily collaborate and build ML projects together. The Hub is a central place where anyone can explore, experiment, and work together to build projects with machine learning. Hugging Face Datasets are a library of high quality datasets curated by ML researchers and professionals. We will be using the beans dataset from Hugging Face Datasets in this project, and we’ll upload it to Edge Impulse to use for AI model training and then for deployment on an edge device.Working with the Dataset
First, open the dataset on the Hugging Face website. Next, download it to your local computer by following the instructions shown when clicking on the “Use in dataset library” option on the right side of the page.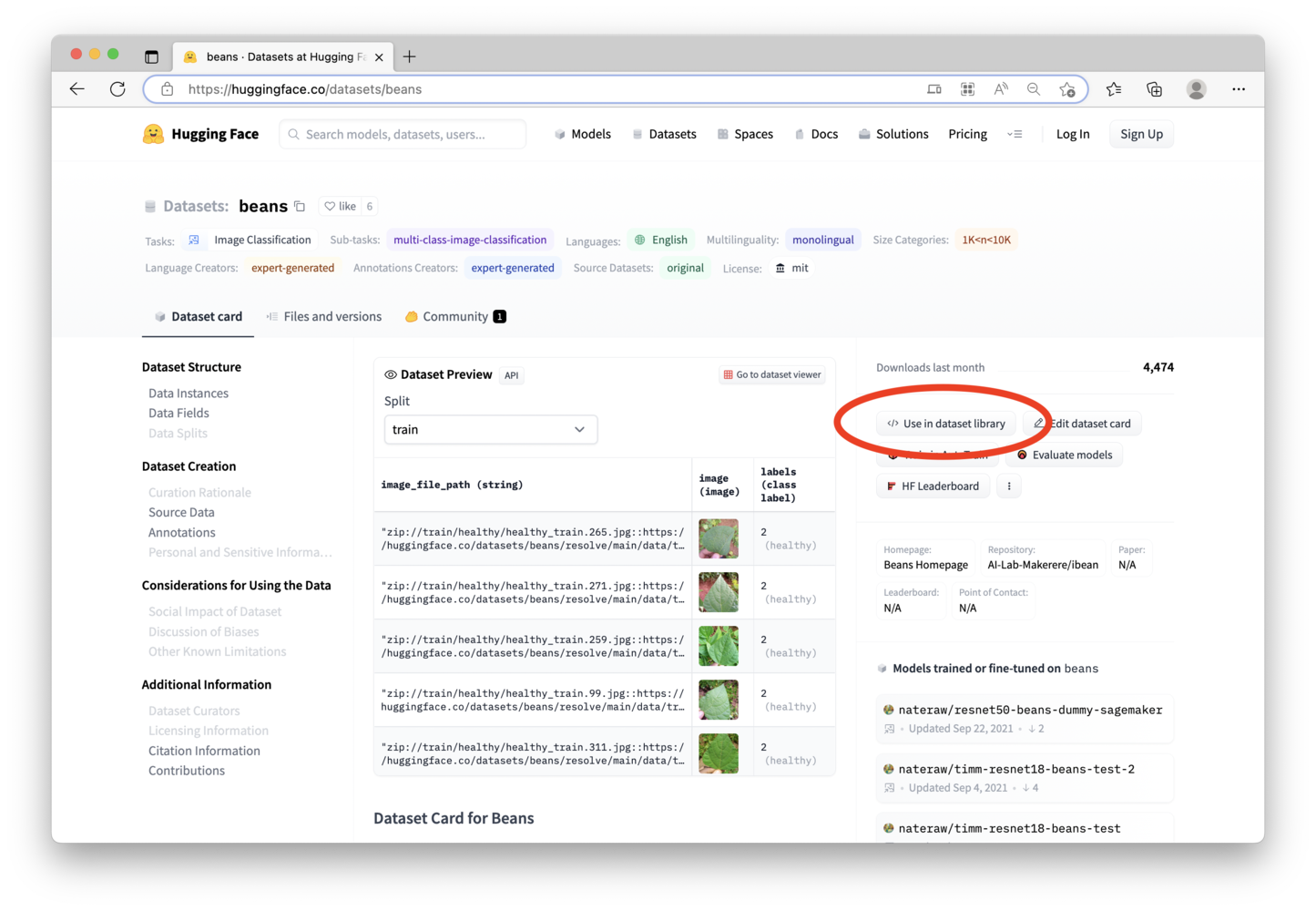
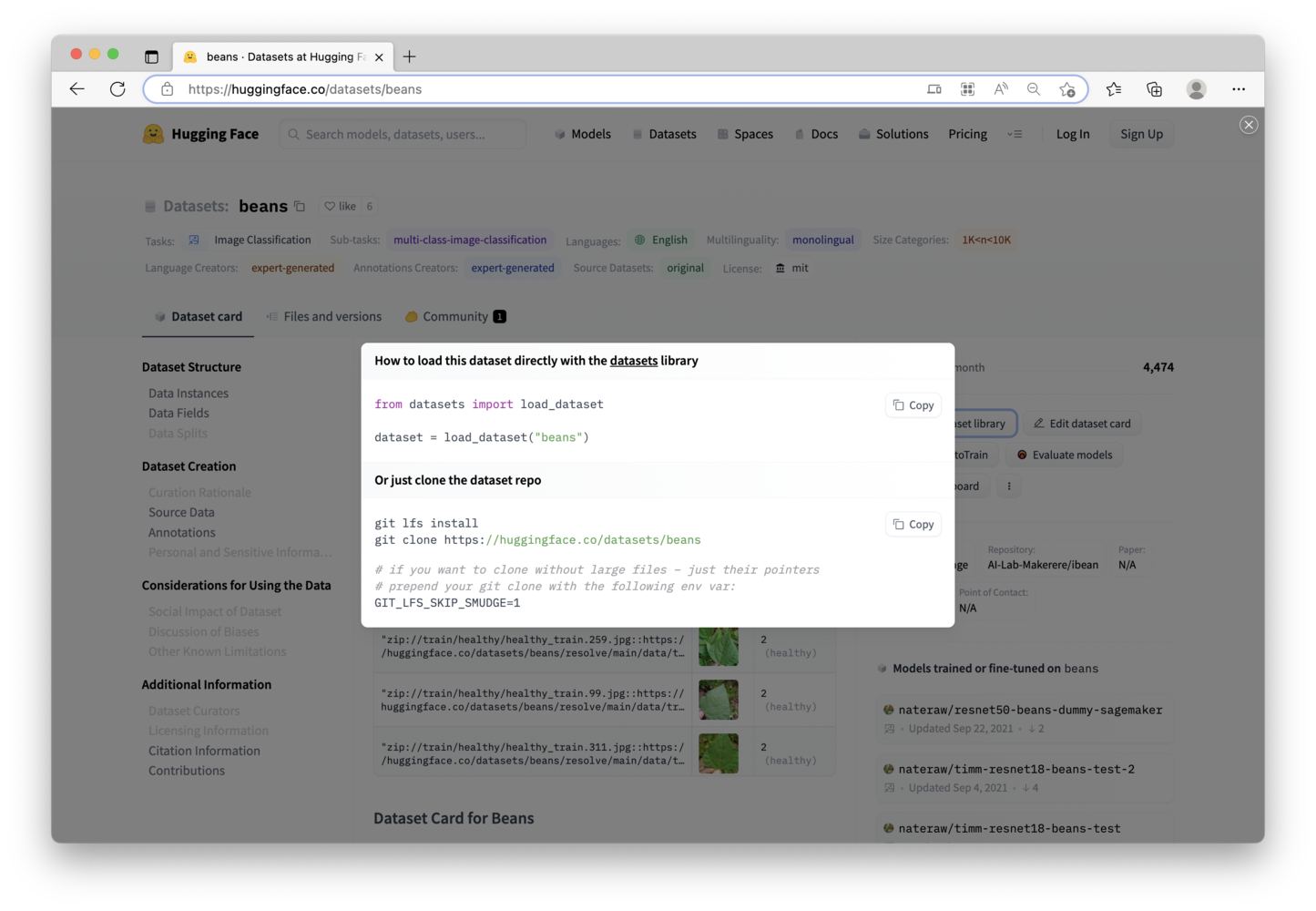
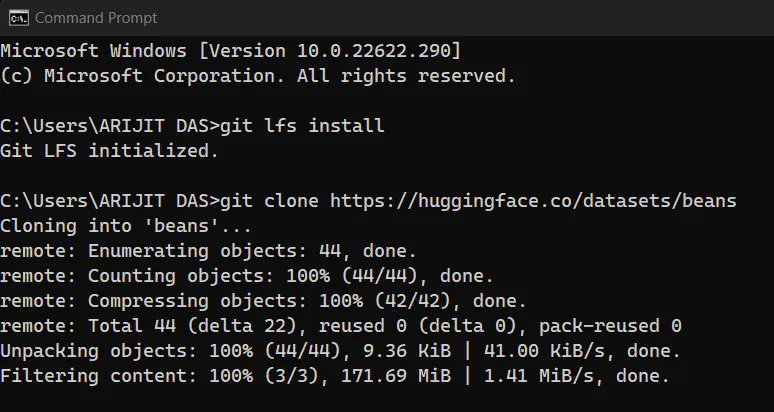
git clone, and you’ll have a .zip file there. Unzip that file, and you will then have a series of folders. Inside of the data folder, you will have 3 more folders, where the images are located for Training, Testing, and Validation. (We actually don’t need the Validation set of images for this project).
Uploading the Dataset to Edge Impulse
We’ll use the Edge Impulse CLI Uploader, which signs local files and uploads them to the ingestion service. This is useful to upload existing data sets, or to migrate data between Edge Impulse projects. The Uploader currently handles these type of files:.cbor- Files in the Edge Impulse Data Acquisition format. The uploader will not resign these files, only upload them..json- Files in the Edge Impulse Data Acquisition format. The uploader will not resign these files, only upload them..csv- Files in the Edge Impulse Comma Separated Values (CSV) format..wav- Lossless audio files. It’s recommended to use the same frequency for all files in your data set, as signal processing output might be dependent on the frequency..jpg- Image files. It’s recommended to use the same pixel ratio for all files in your data set.
--category option. For example:
--label option. For example:
Creating and Testing the Model
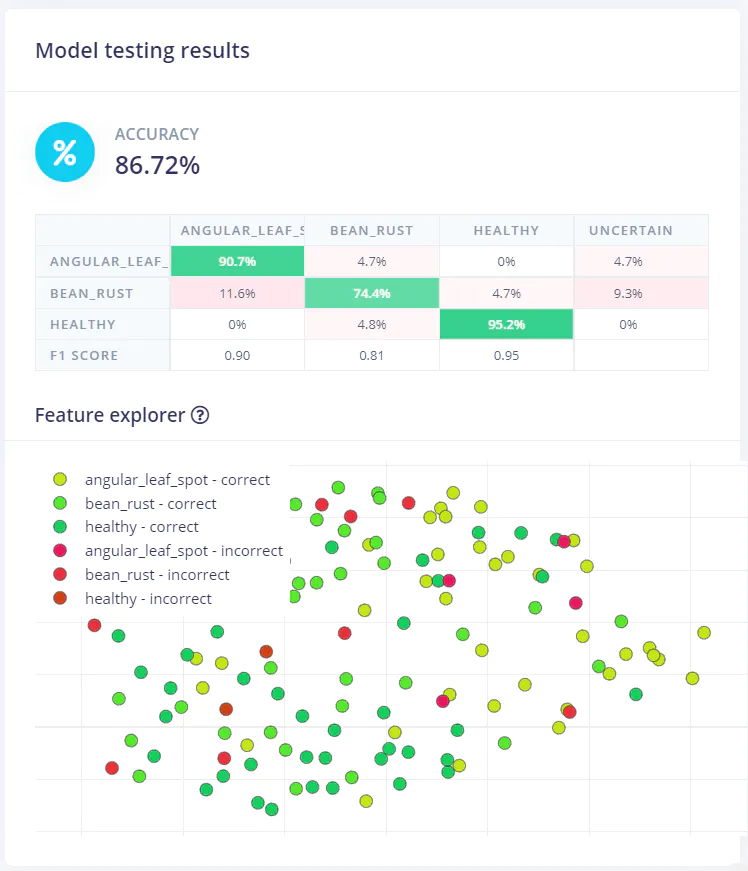
With the data uploaded to the Edge Impulse Studio, we can start training our model. I’m using MobileNet V2 160x160 0.75, with a training cycle of 20 epochs, and a learning rate of 0.0005. I’m able to achieve 91% accuracy, which is great (unoptimized float32).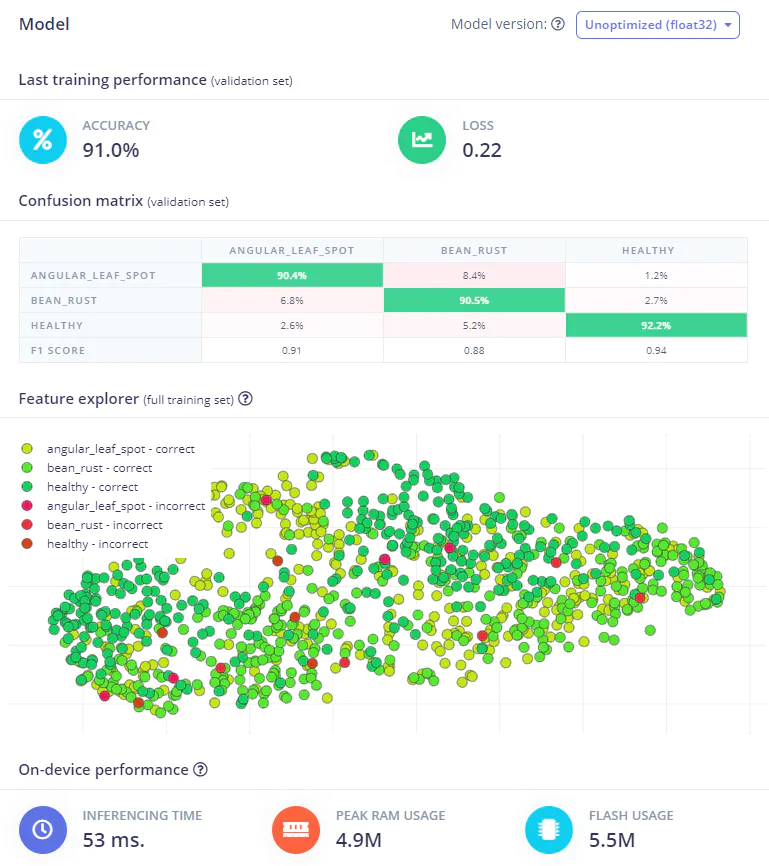
Deployment of the Model
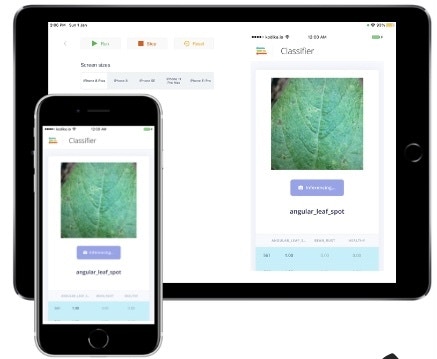
Edge Impulse supports model deployment for a wide variety of devices. There are microcontroller targets such as the Arduino Nicla, Portenta, and Nano, the Sony Spresense, Syntiant TinyML Board, and many more, there are linux-based devices such as the Raspberry Pi, Jetson Nano, and Renesas RZ/V2L, or you can deploy it directly to a phone or tablet. The Documentation for each device is located here, and because the instructions vary depending upon your chosen board, you’ll want to follow the official Docs. For a quick way to see if everything is working, you can actually deploy straight to your smartphone or tablet. Here I’ve deployed it on an iPhone and iPad using my previous project documentation.