Overview

Hardware Selection
Our system utilizes the Arduino Nicla Voice, which is designed with the Syntiant NDP120 Neural Decision Processor. This processor allows for embedded machine-learning models to be run directly on the device. Specifically designed for deep learning, including CNNs, RNNs, and fully connected networks, the Syntiant NDP120 is perfect for always-on applications with minimal power consumption. Its slim profile also makes it easily portable, which suits our needs.
nicla_voice

Hardware
Setup Development Environment
To set this device up in Edge Impulse, we will need to install two command-line interfaces by following the instructions provided at the links below. Please clone the Edge Impulse firmware for this specific development board.pyserial package required to update the NDP120 chip, execute the commands below.
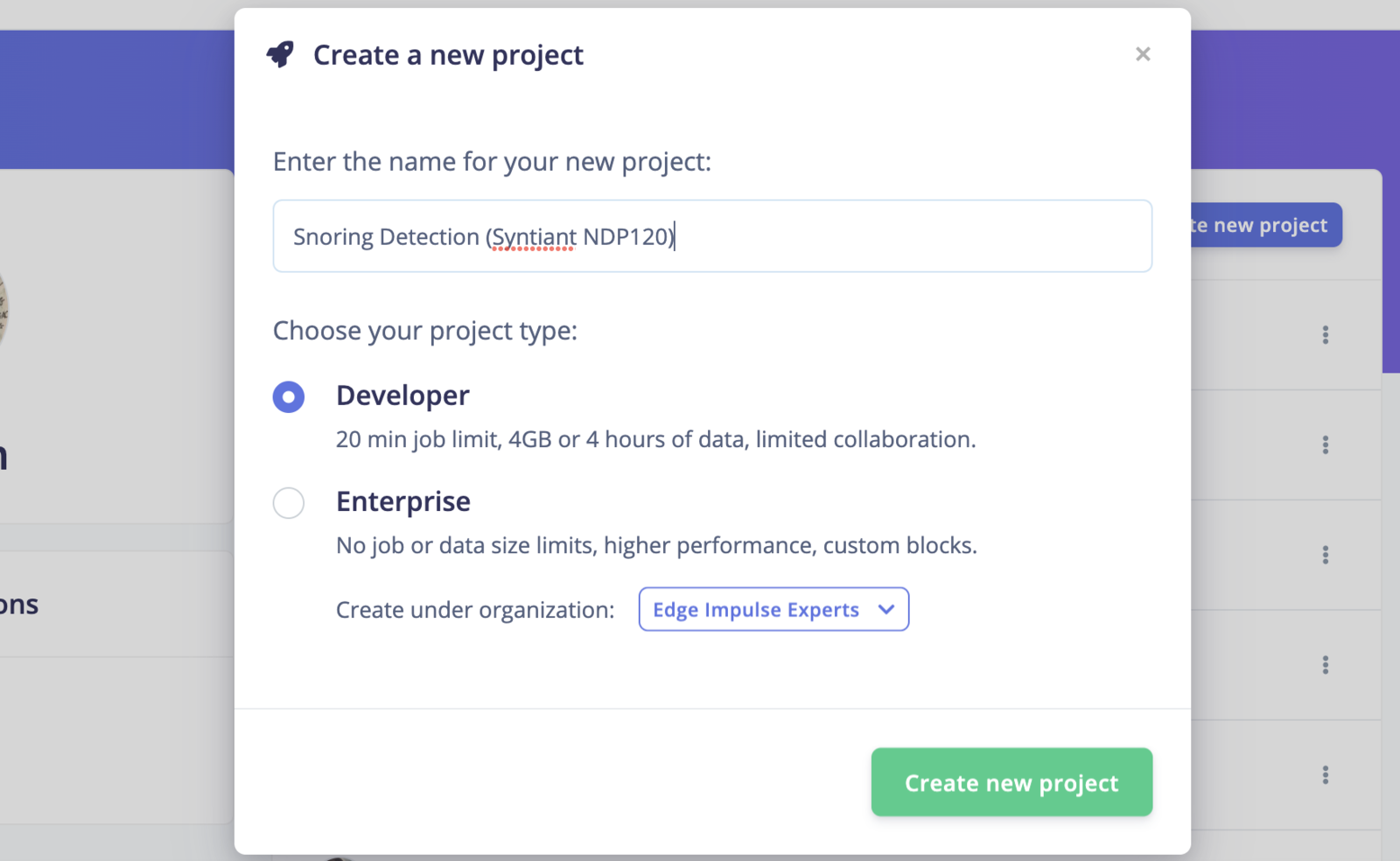
New Project
Data Collection
We have used a dataset available at https://www.kaggle.com/datasets/tareqkhanemu/snoring. Within the dataset, there are two separate directories; one for snoring and the other for non-snoring sounds. The first directory includes a total of 500 one-second snoring samples. Among these samples, 363 consist of snoring sounds created by children, adult men, and adult women without any added background noise. The remaining 137 samples include snoring sounds that have been mixed with non-snoring sounds. The second directory contains 500 one-second non-snoring samples. These samples include background noises that are typically present near someone who is snoring. The non-snoring samples are divided into ten categories, each containing 50 samples. The categories are baby crying, clock ticking, door opening and closing, gadget vibration motor, toilet flushing, emergency vehicle sirens, rain and thunderstorm, street car sounds, people talking, and background television news. The audio files are in the 16-bit WAVE audio format, with a 2-channels (stereo) configuration and a sampling rate of 48,000 Hz. However, we require a single-channel (mono) configuration at a sampling rate of 16,000 Hz, so we need to convert it accordingly using FFmpeg.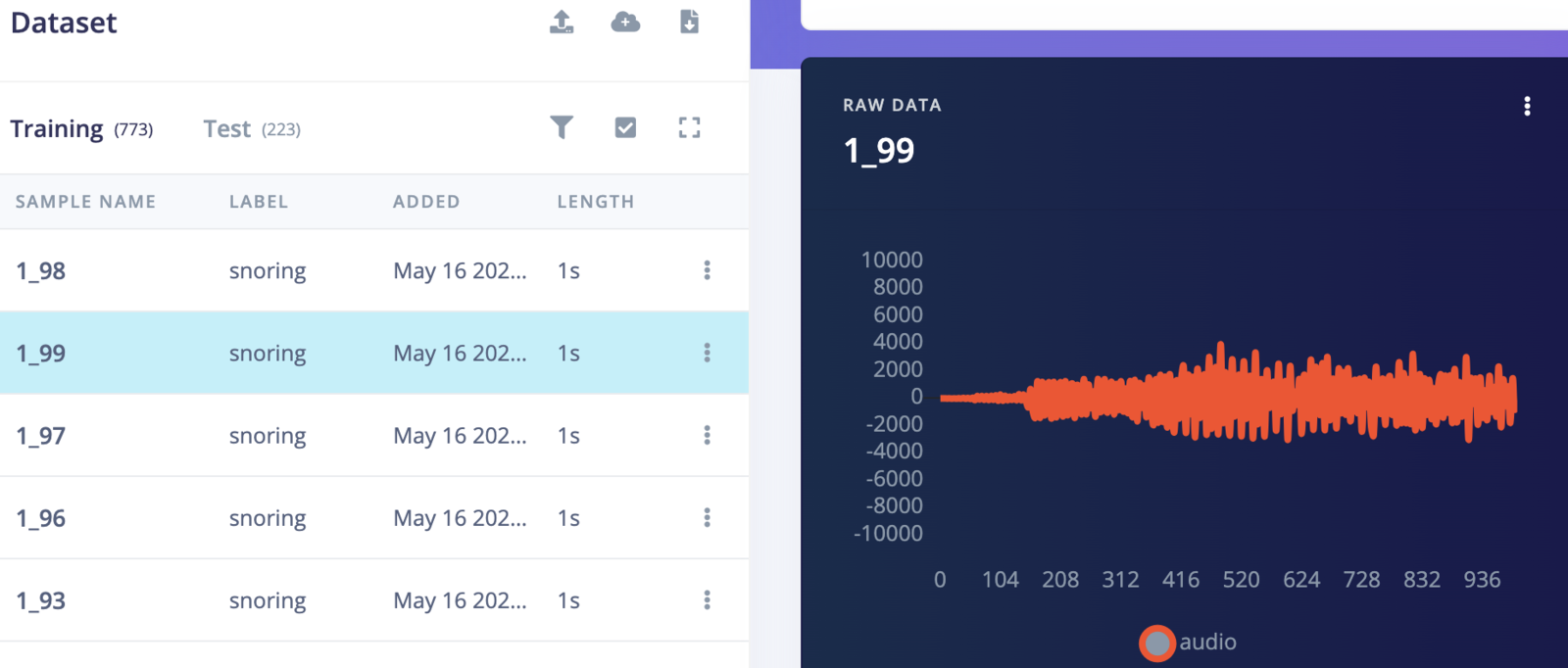
Data Acquisition
Model Training
Go to the Impulse Design > Create Impulse page and click on the Add a processing block and choose Audio (Syntiant) which computes log Mel-filterbank energy features from an audio signal specific to the Syntiant audio front-end. Also, on the same page click on the Add a learning block and choose Classification which learns patterns from data, and can apply these to new data. We opted for a default window size of 968 ms and a window increase of 32 ms, which allows for two complete frames within a second of the sample. Now click on the Save Impulse button.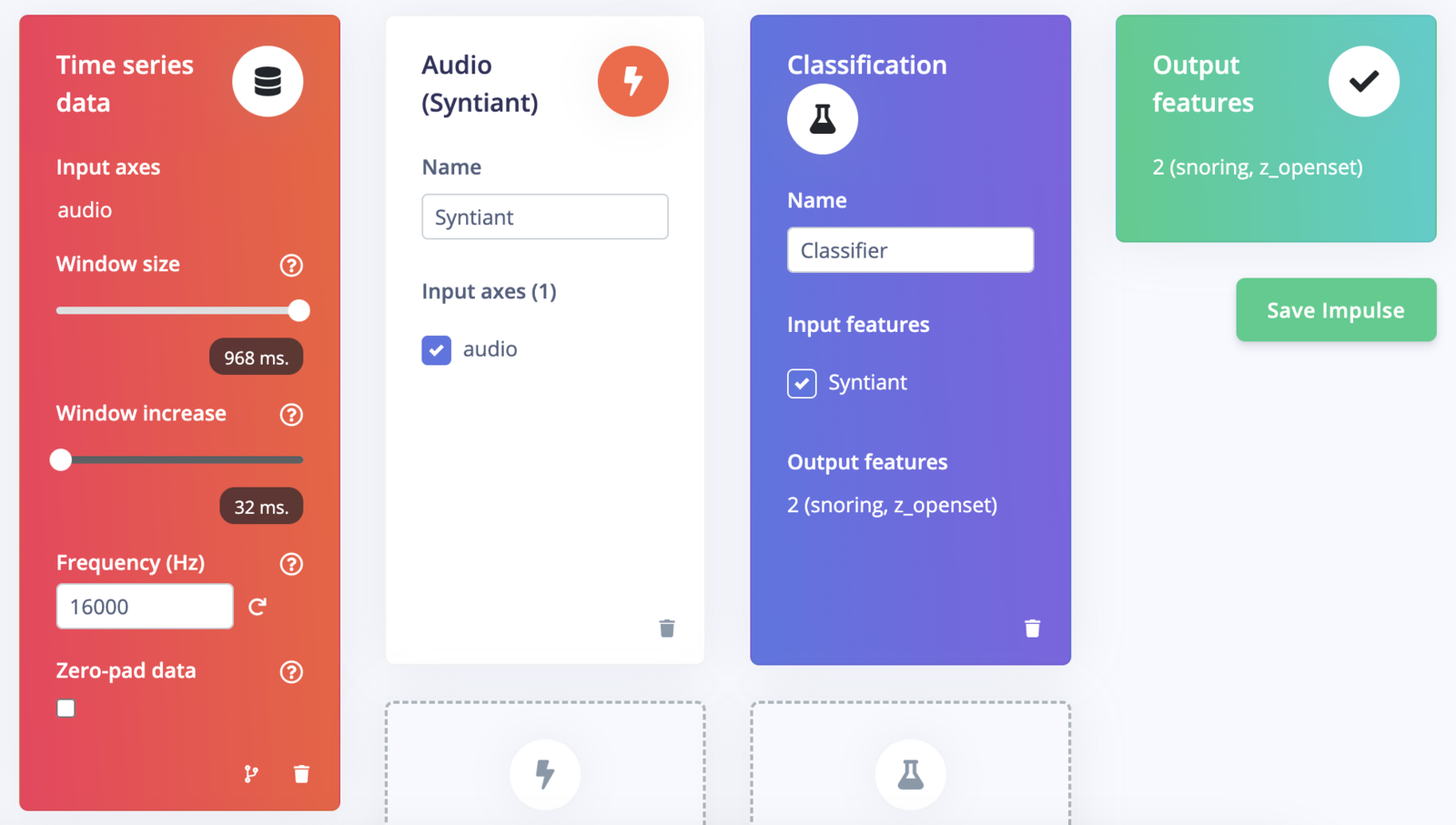
Create Impulse
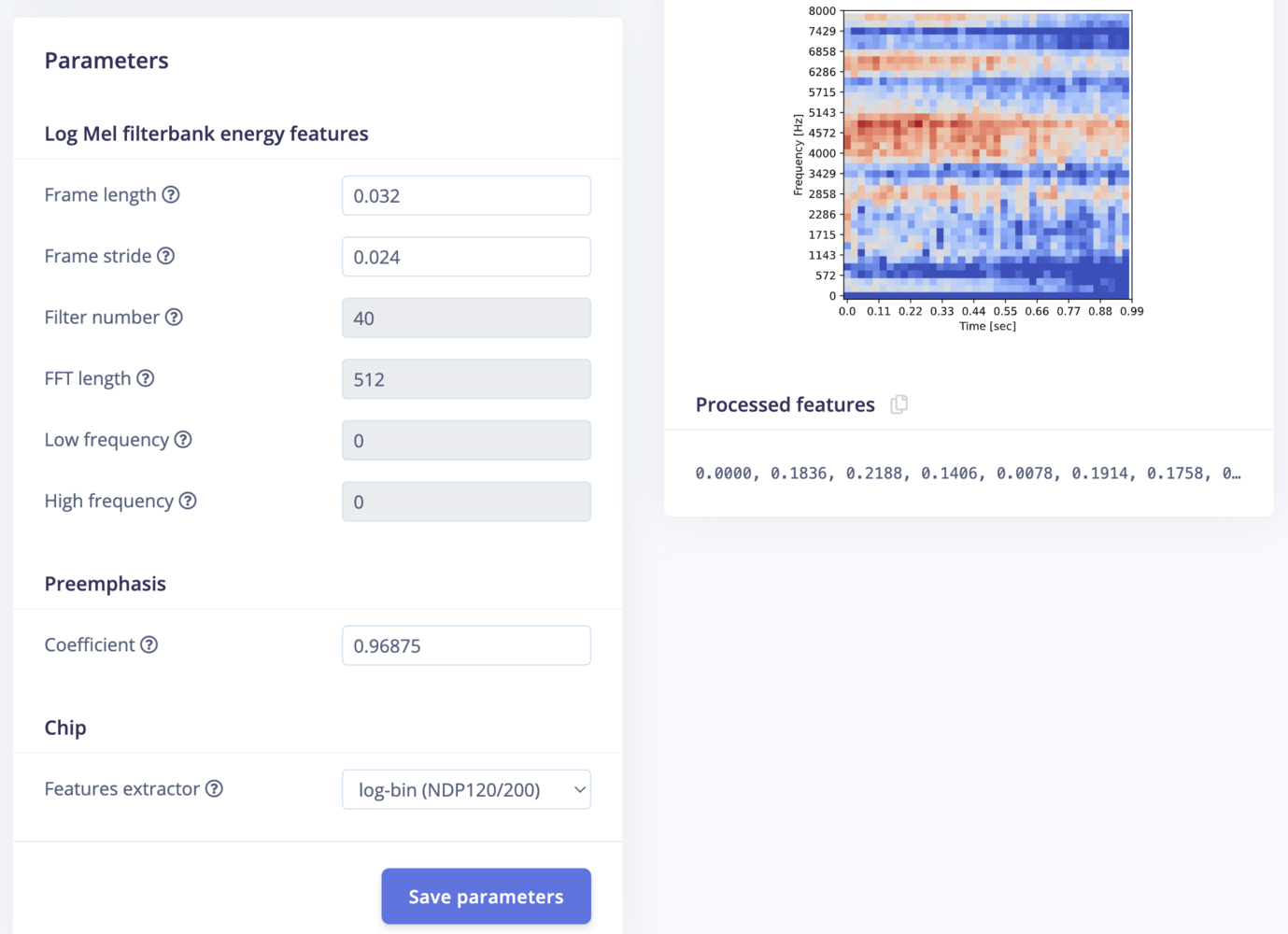
syntiant_block_1
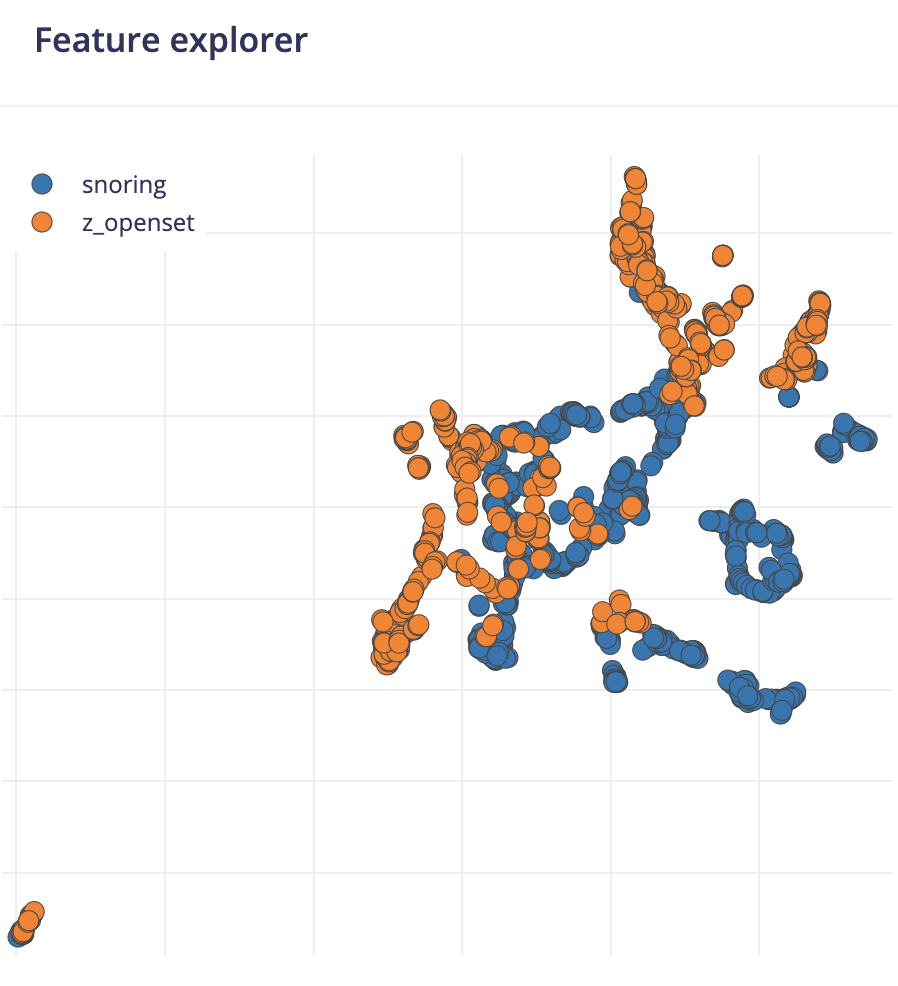
feature_explorer
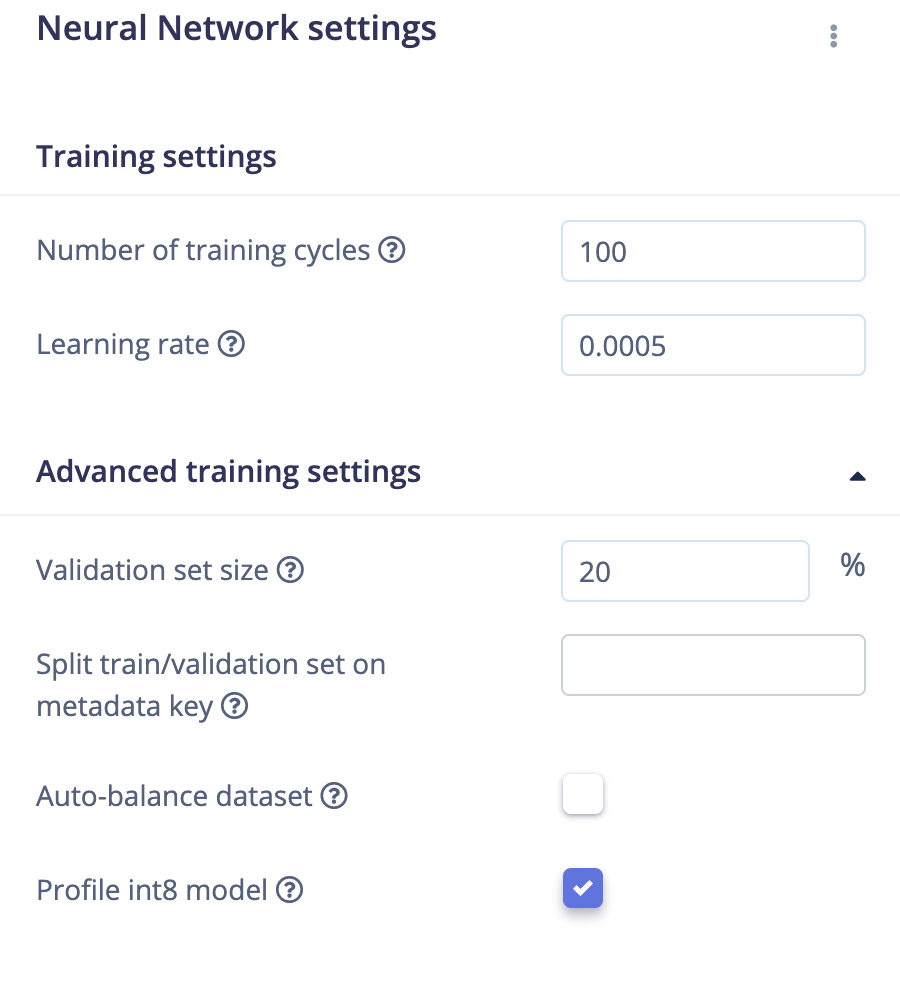
neural_network_settings

neural_network_architecture
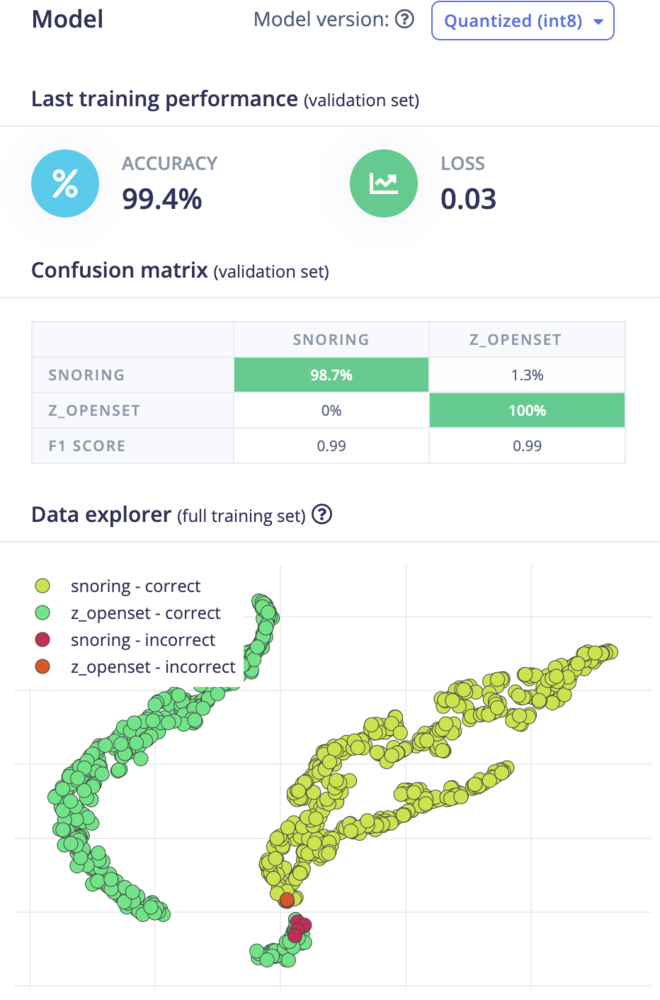
training_output
Model Testing
To assess the model’s performance on the test datasets, navigate to the Model testing page and select the Classify all button. We can be confident in the model’s effectiveness on new, unseen data, with an accuracy rate of 94.62%.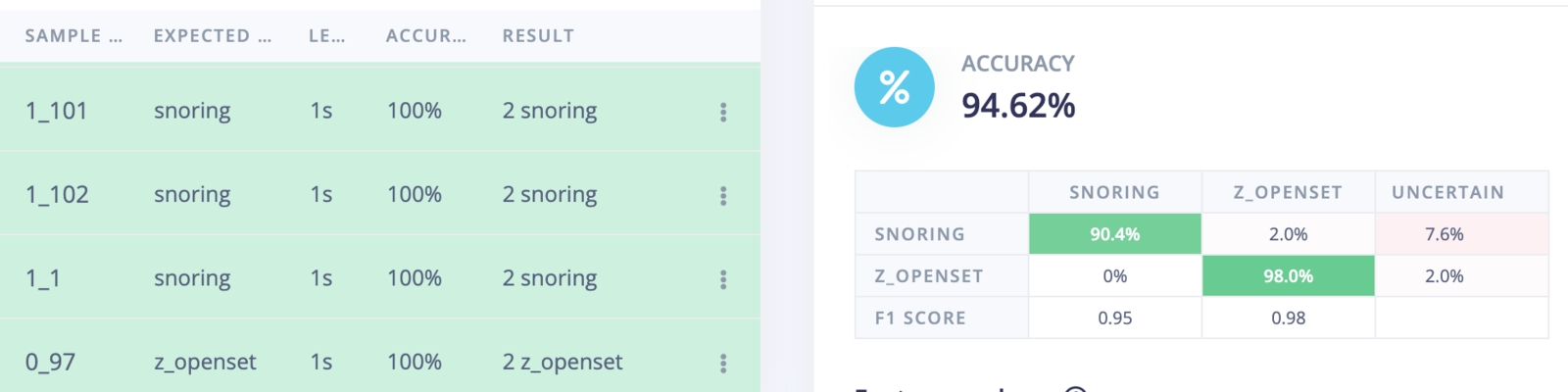
Model Testing
Model Deployment
When deploying the model on Nicla Voice, we must choose the Syntiant NDP120 library option on the Deployment page.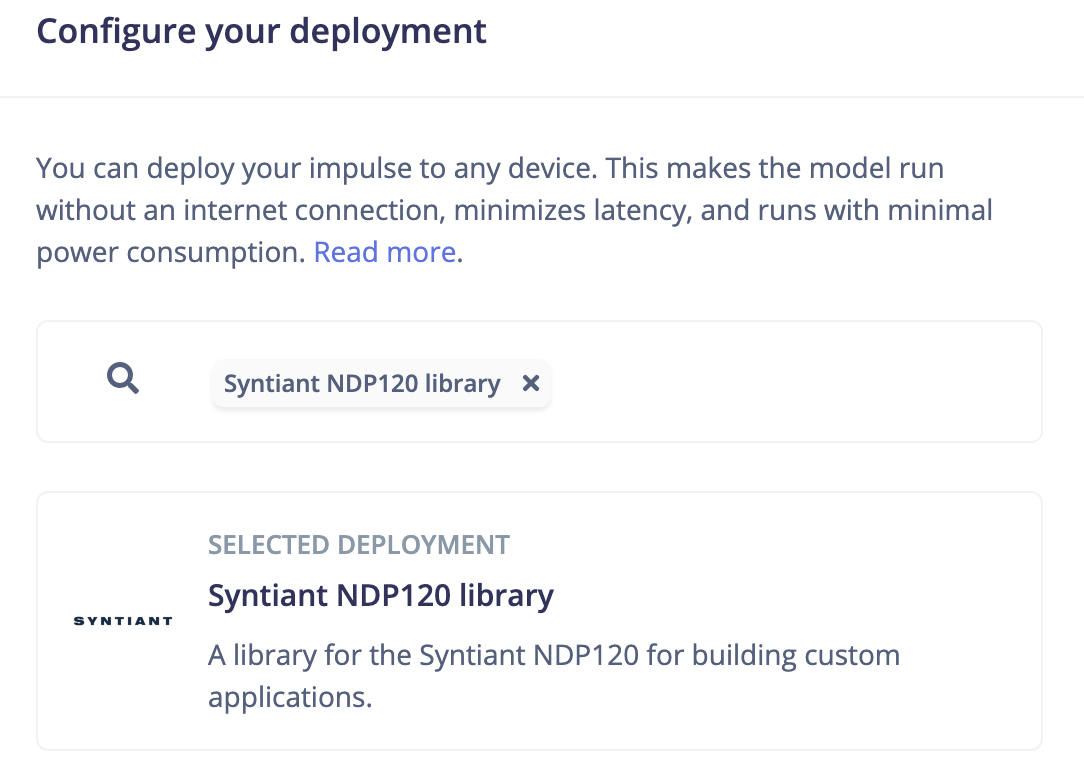
deployment_configure
deployment_configure
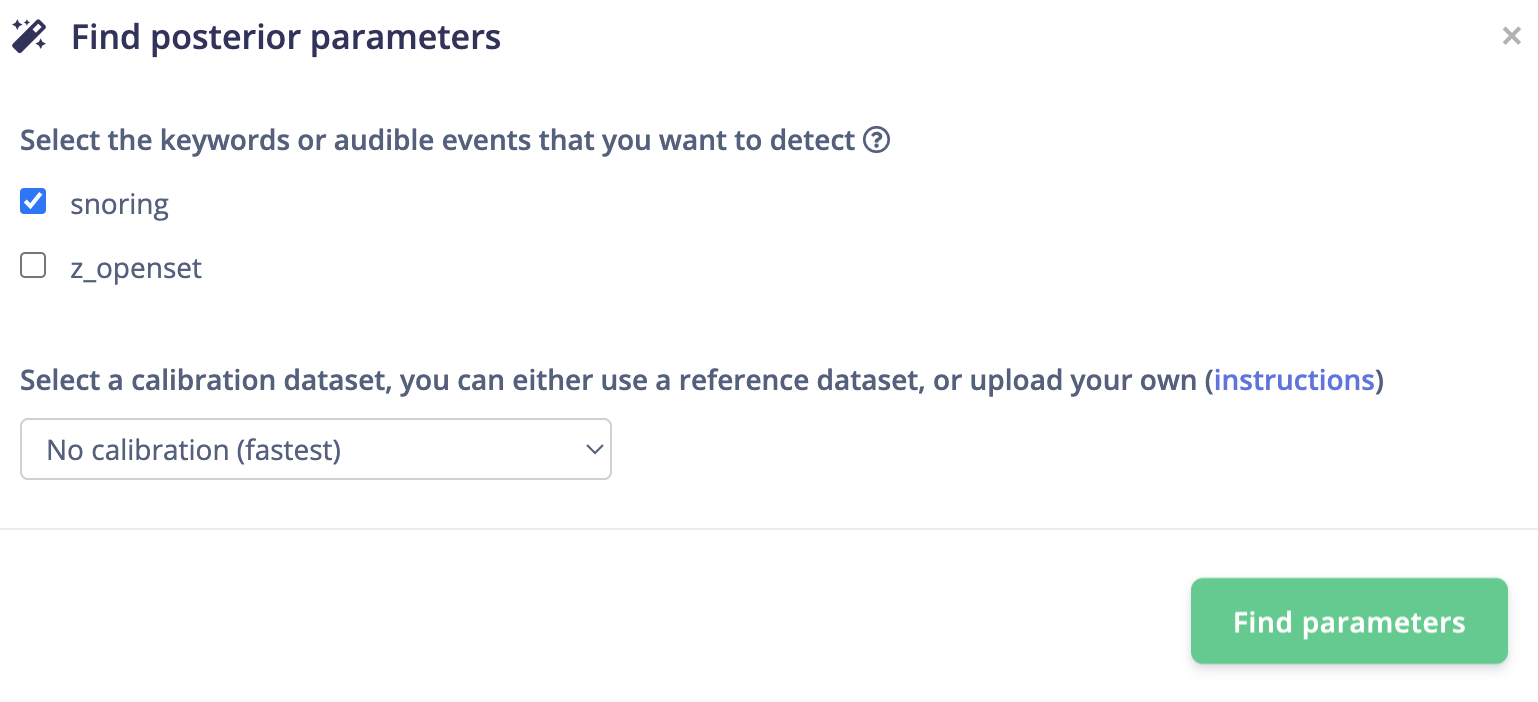
Deployment Post Parameter
- Take the .elf file output by Arduino and rename it to firmware.ino.elf.
- Replace the firmware.ino.elf from the default firmware
- Replace the ei_model.synpkg file in the default firmware by the one from the downloaded Syntiant library.