
Introduction
It’s said that a dog is man’s best friend and it is no secret that dogs are incredibly loyal animals. They are very effective when it comes to securing premises, and are also able to sense when things are not right, whether with a person or with a situation. Some examples of dog security are guidance for people with visual impairments, detection of explosives and drugs, search and rescue missions, and enhancing security at various places. Worker safety aims to foster a practice of ensuring a safe working environment by providing safe equipment and implementing safety guidelines that enable workers to be productive and efficient in their job. In this case, dogs are usually deployed to patrol and monitor areas around workplace. One of the reasons is because dogs have an extraordinary sensing ability of smell, vision and hearing; making them exceptional at detecting threats that may go unnoticed by humans or other security systems. However, workers may not always be able to interpret a dog’s barks in time. The workers may not be knowledgeable of how dog’s react, or they may be focusing on their tasks and fail to hear a dog. Failure to detect a dog’s bark may lead to fatalities, injuries or even accidents. Machine listening refers to the ability of computers to understand audio signals similarly to how humans hear and understand various sounds. Recently, labeling of acoustic events has emerged as an active topic covering a wide range of applications. This is because by analyzing animal sounds, AI can identify species more accurately and efficiently than ever before and provide unique insights into the behaviors and habitats of animals without disturbing them. Barking and other dog vocalizations have acoustic properties related to their emotions, physiological reactions, attitudes, or some other internal states. Historically, humans have relied on intuition and experience to interpret these signals from dogs. We have learned that a low growl often precedes aggression, while a high-pitched bark might indicate excitement or distress. Through this experience, we can train AI models to recognize dog sounds, and those who work with the animals— like security guards, maintenance staff, and even delivery people can use that insight. The AI model only requires to be trained to recognize the sounds one seeks to monitor based on recordings of the sound. However, creating an audio dataset of animal sounds is quite challenging. In this case, we do not disturb dogs, or other animals, to provoke reactions like barking. Fortunately, Generative AI is currently at the forefront of AI technology. Over the past decade, we have witnessed significant advancements in synthetic audio generation. From sounds to songs, with just a simple prompt, we can now use computers to generate dog sounds and in turn use the data to train another AI model.
AI generated image
Project Overview
This project aims to develop a smart prototype wearable that can be used by workers to receive alerts from security dogs. In workplaces and even residential areas, dog sounds are common, but we often overlook them, assuming there is no real threat. We hear the sounds but don’t actively listen to the warnings dogs may be giving. Additionally, workers at a site may be too far to hear the dogs, and in some cases, protective ear muffs further block out environmental sounds. Sound classification is one of the most widely used applications of Machine Learning. This project involves developing a smart wearable device that is able to detect dogs sounds specifically barking and howling. When these dogs sounds are detected, the wearable communicates about the dog’s state by displaying a message on a screen. This wearable can be useful to workers by alerting them of precautionary measures. A security worker may be alerted of a potential threat that a dog identified but they did not manage to see. A postal delivery person can also be alerted of an aggressive dog that may be intending to attack them as they may perceive the delivery person as a threat.
Wearable

Small device, huge potential
Use Case Explanation
Canine security refers to the use of trained security dogs and expert dog handlers to detect and protect against threats. The effectiveness in dogs lies in their unique abilities. Animals, especially dogs, have a keen sense of smell and excellent hearing. As a result, dogs are the ideal animal to assist security guards in their duties and also provide security to workplaces and homesteads. However, at the same time, according to the American Veterinary Medical Association, more than 4.5 million people are bitten by dogs each year in the US. And while anyone can suffer a dog bite, delivery people are especially vulnerable. Statistics released by the US Postal Service show that 5,800 of its employees were attacked by dogs in the U.S. in 2020. According to Sam Basso, a professional dog trainer, clients frequently admit they have more to learn about their dogs during his sessions. While humans have been able to understand how dogs act, there is still more learning that the average person requires so that they can better understand dogs. There are professional dog handlers that can be used to train owners but this comes at a great cost and also not everyone is ready to take the classes. To address these issues, we can utilize AI to develop a device that can detect specific dog sounds such as barking, and alert workers so that they can follow up on the situation that the dog is experiencing. In the case of delivery persons, an alert can inform them of a nearby aggressive dog. Audio classification is a fascinating field with numerous applications, from speech recognition to sound event detection. Training AI models has become easier by using pre-trained networks. The transfer learning approach uses a pretrained model which is already trained using a large amount of data. This approach can significantly reduce the amount of labeled data required for training, it also reduces the training time and resources, and improves the efficiency of the learning process, especially in cases where there is limited data available. Training a model requires setting up various configurations, such as data processing formats, model type, and training parameters. As developers, we experiment with different configurations and track their performance in terms of processing time, accuracy, classification speed, Flash and RAM usage. To facilitate this process, Edge Impulse offers the Experiments feature. This enables us to create multiple Machine Learning pipelines (Impulses) and easily view the performance metrics for all pipelines, helping us quickly understand how each configuration performs and identify the best one. Finally, for deployment, this project requires a low-cost, small and powerful device that can run optimized Machine Learning models. The wearable will also require ability to connect to an OLED display using general-purpose input/output (GPIO) pins. Power management is another most important consideration for a wearable. The ability to easily connect a small battery, achieve low power consumption, and have battery charging would be great. In this case, the deployment mode makes use of the XIAO ESP32S3 development board owing to it’s small form factor, high performance and lithium battery charge management capability.Components and Hardware Configuration
Software components:- Edge Impulse Studio account
- ElevenLabs account
- Arduino IDE
- A personal computer
- Seeed Studio XIAO ESP32S3 (Sense) development board with the camera detached
- SSD1306 OLED display
- 3.7V lithium battery. In my case, I used a 500mAh battery.
- 3D printed parts for the wearable. Available to download on Printables.com
- Some jumper wires and male header pins
- Soldering iron and soldering wire
- Super glue. Always be careful when handling glues!
Data Collection Process
To collect the data to be used in this project, we will use the Synthetic data generation tool on the platform. At the time of writing this documentation in October 2024, Edge Impulse has integrated three Generative AI platforms for synthetic data generation: Dall-E to generate images, Whisper for creating human speech elements, and ElevenLabs to generate audio sound effects. In our project, we will use ElevenLabs since it is great for generating non-voice audio samples. There is an amazing tutorial video that demonstrates how to use the integrated ElevenLabs audio generation feature with Edge Impulse. If we were instead capturing sounds from the environment, Edge Impulse also supports collecting data from various sources such as uploading files, using APIs, smartphone/computers, and even connecting development boards directly to your project so that you can fetch data from sensors. The first step was to create a free account on ElevenLabs. You can do this by signing up with an email address and a password. However, note that with the current ElevenLabs pricing the free account gives 10,000 credits which can be used to generate around 10 minutes of audio per month. Edge Impulse’s synthetic audio generation feature is offered in the Enterprise plan. You can request an expert-led trial to explore the functionality. Once we have an account on both ElevenLabs and EdgeImpulse, we can get started with data creation. First, create a project (with the Enterprise plan) on Edge Impulse Studio. On the dashboard, navigate to “Data acquisition” and then “Synthetic data”. Here, we will need to fill the form with our ElevenLabs API key and also parameters for the data generation such as the prompt, label, number of samples to be generated, length of the each sample, frequency of the generated audio files, and also prompt influence parameter.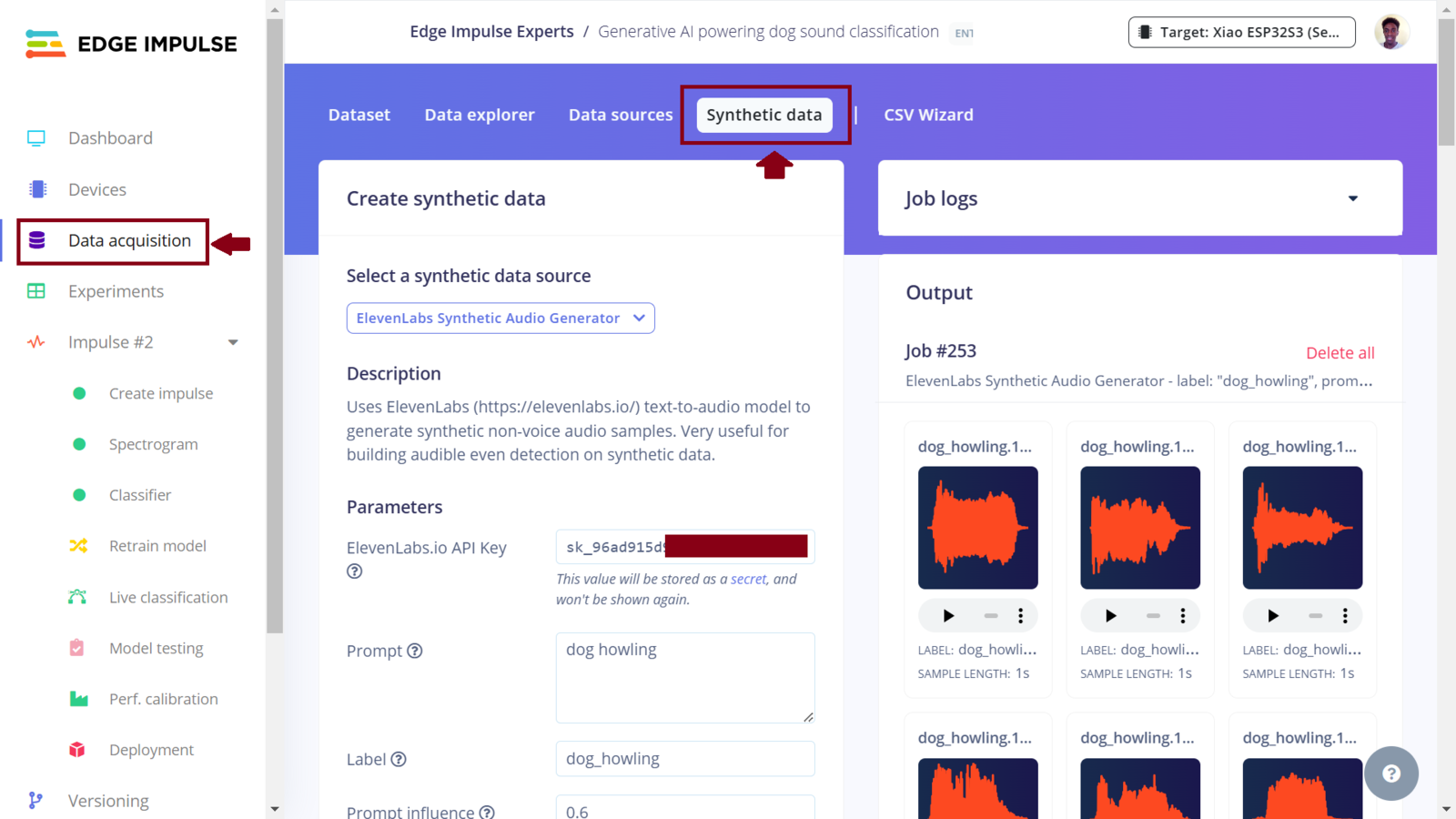
EI data acquisition
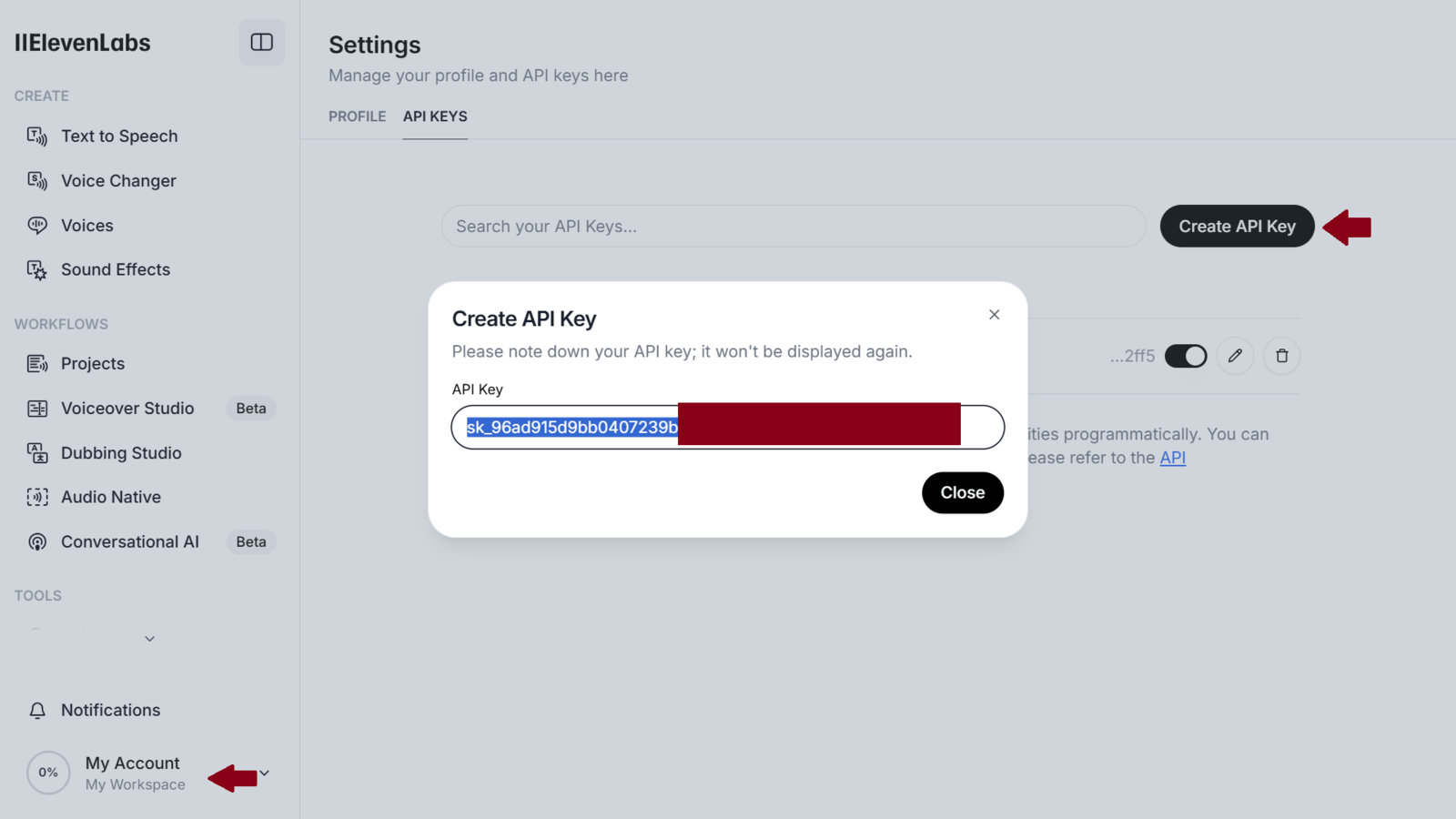
ElevenLabs API Key
dog_howling, dog_barking and environment respectively. For each prompt, I used a prompt influence of 0.6 (this generated the best sounds), “Number of samples” as 6, “Minimum length (seconds)” as 1, “Frequency (Hz)” as 16000 and “Upload to category” as training. With these configurations, when we click the “Generate data” button on Edge Impulse Studio, this will generate 6 audio samples each of 1 second for one class. To generate sound for another class, we can simply put the prompt for it and leave the other fields unchanged. I used this configuration to generate around 39 minutes of audio files consisting of dogs barking, dogs howling and environment (e.g., city streets, construction sites, people talking) sounds.
However, later on after experimenting with various models, I noticed significant bias in the dog barking class, leading the models to classify any unheard sounds as dog barks (in other words, the models were overpredicting the dog bark class). In this case, I created another class, noise, consisting of 10 minute recordings from quiet environments with conversations, silence, and low machine sounds like a refrigerator and a fan. I uploaded the recordings to the Edge Impulse project and used the split data tool to extract 1 second audio samples from the recording. After several experiments, I observed that the model actually performed best when I only had 3 classes: dog barking, dog howling and noise sounds. Therefore, I disabled the environment class audio files in the dataset and this class was ignored in the pre-processing, model training and deployment.
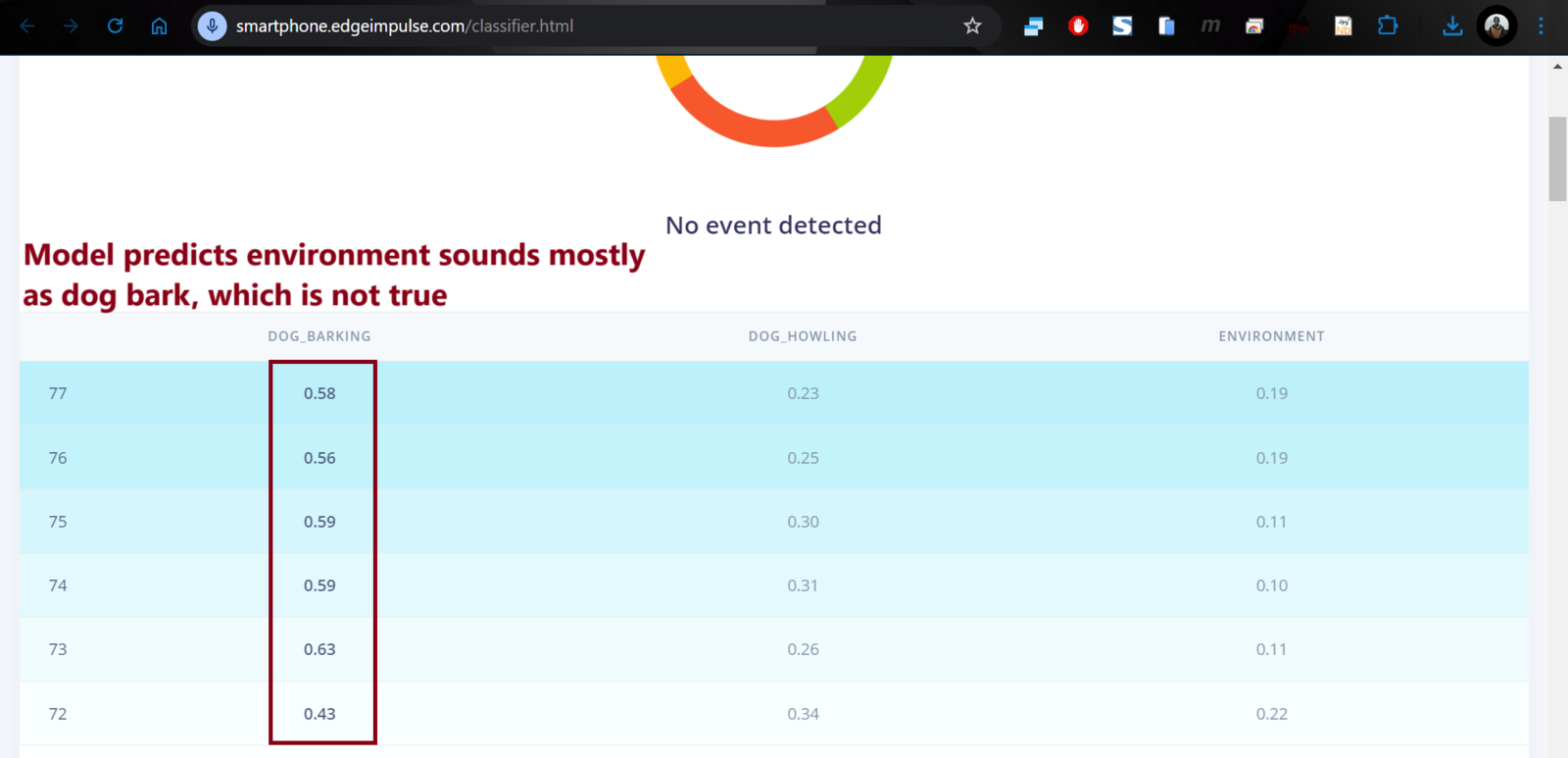
Wrong predictions from the model, bias
noise sound recording, I had around 36 minutes of sound data for both training and testing. In AI, the more data, the better the model will perform. For this demonstration project, I found the dataset size to be adequate.
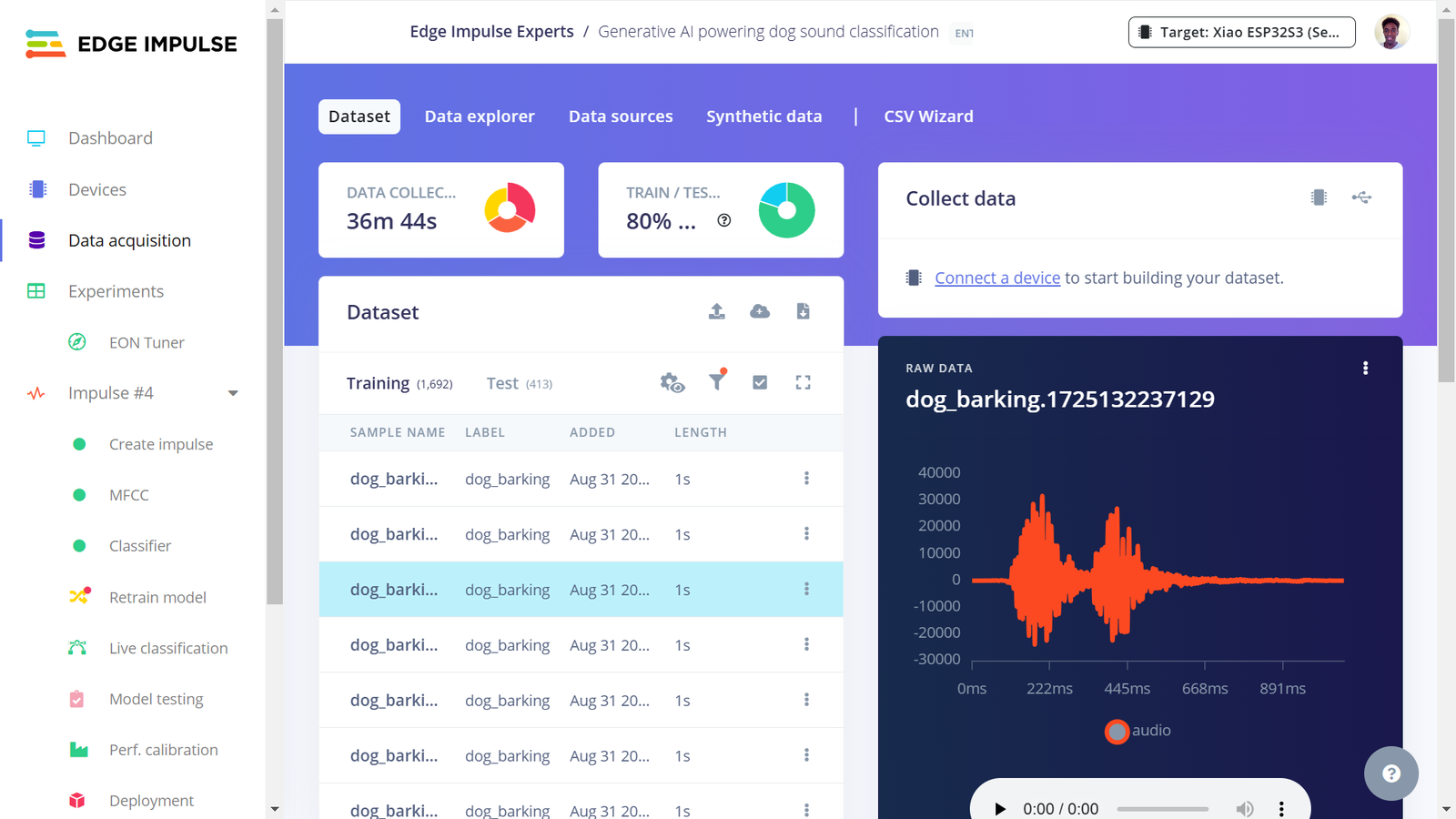
Dataset
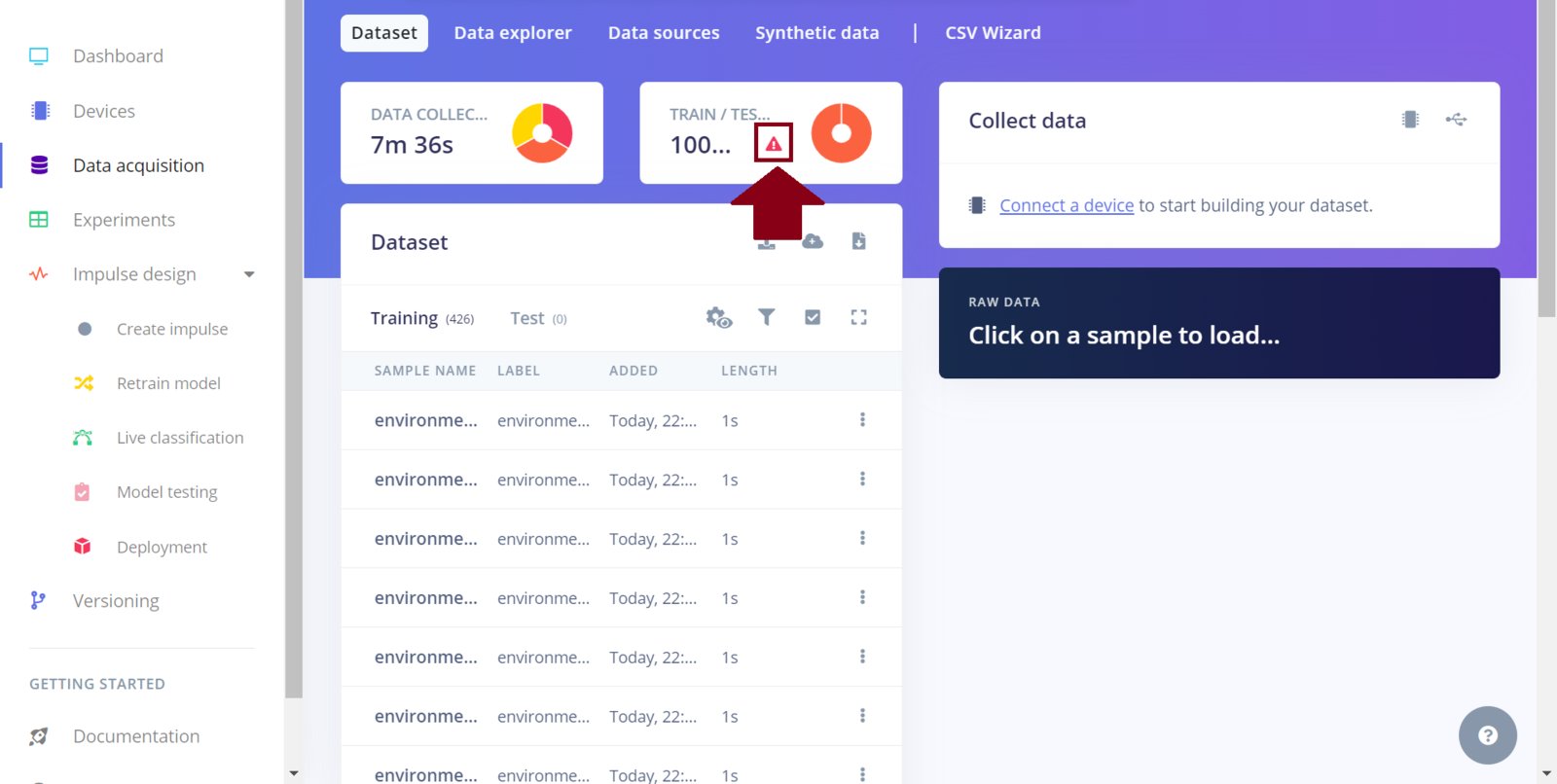
EI project dataset
Training the Machine Learning Model, with Experiments
After collecting data for our project, we can now train a Machine Learning model for the required sound classification task. To do this, on Edge Impulse we need to create an Impulse. An Impulse is a configuration that defines the input data type, data pre-processing algorithm and the Machine Learning model training. In our project, we are targeting to train an efficient sound classification model and “fit” inside a microcontroller (ESP32S3). In this case, there are a great number of parameters and algorithms that we need to choose accurately. One of the great features of the Edge Impulse platform is the powerful tools that simplify the development and deployment of Machine Learning. Edge Impulse recently released the Experiments feature which allows projects to contain multiple Impulses, where each Impulse can contains either the same combination of blocks or a different combination. This allows us to view the performance for various types of learning and processing blocks, while using the same input training and testing datasets.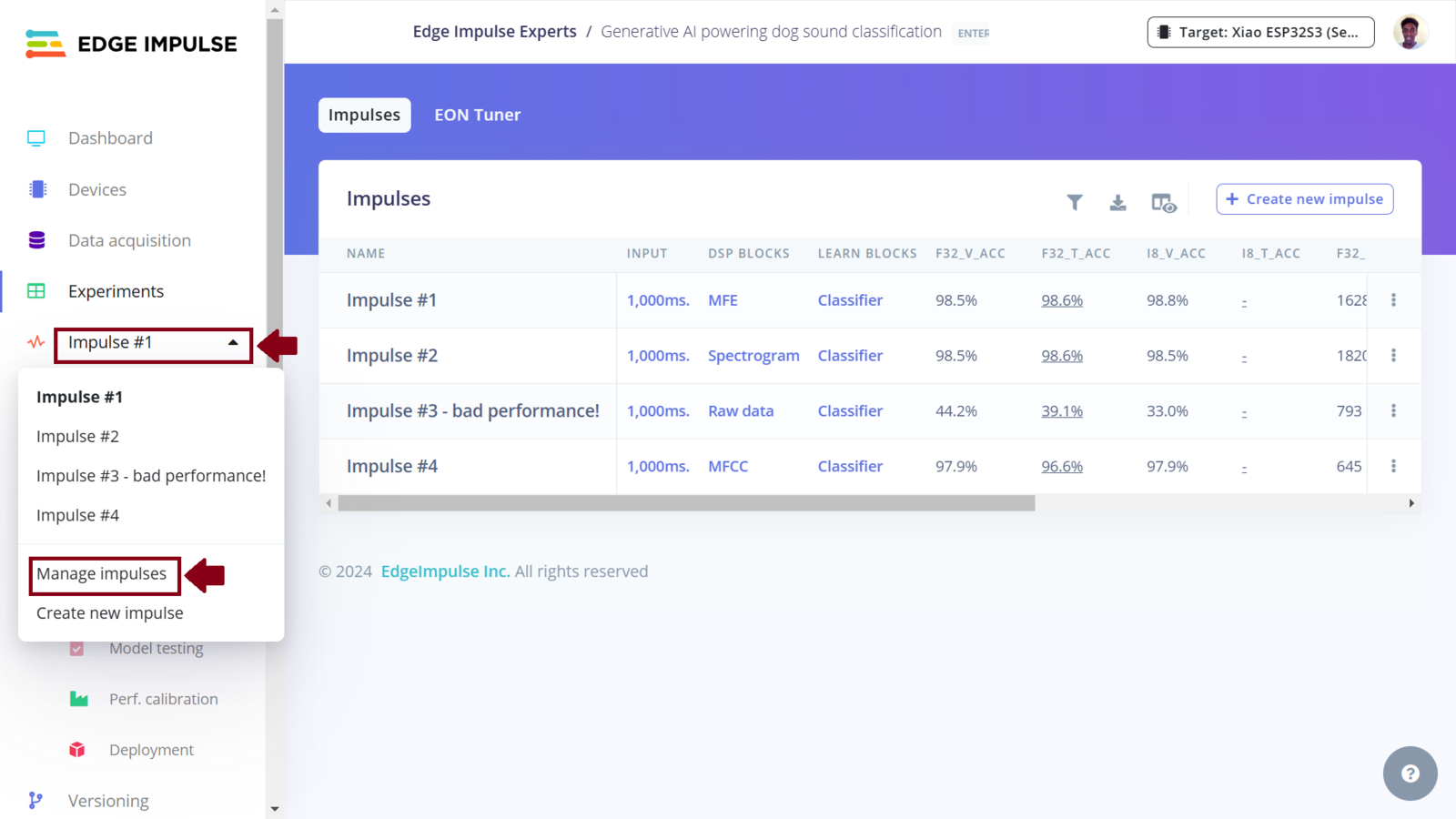
Edge Impulse Experiments
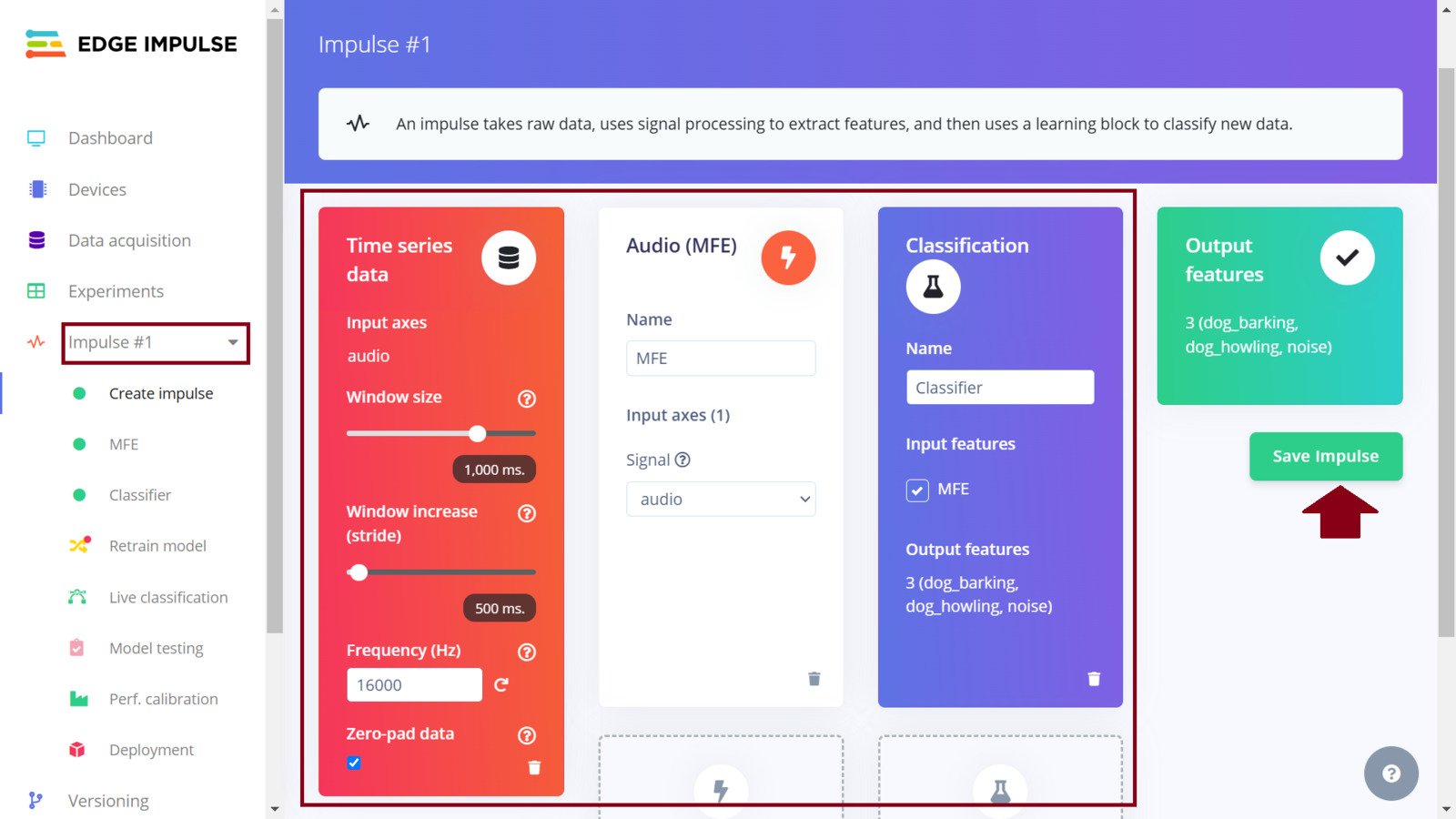
First Impulse design
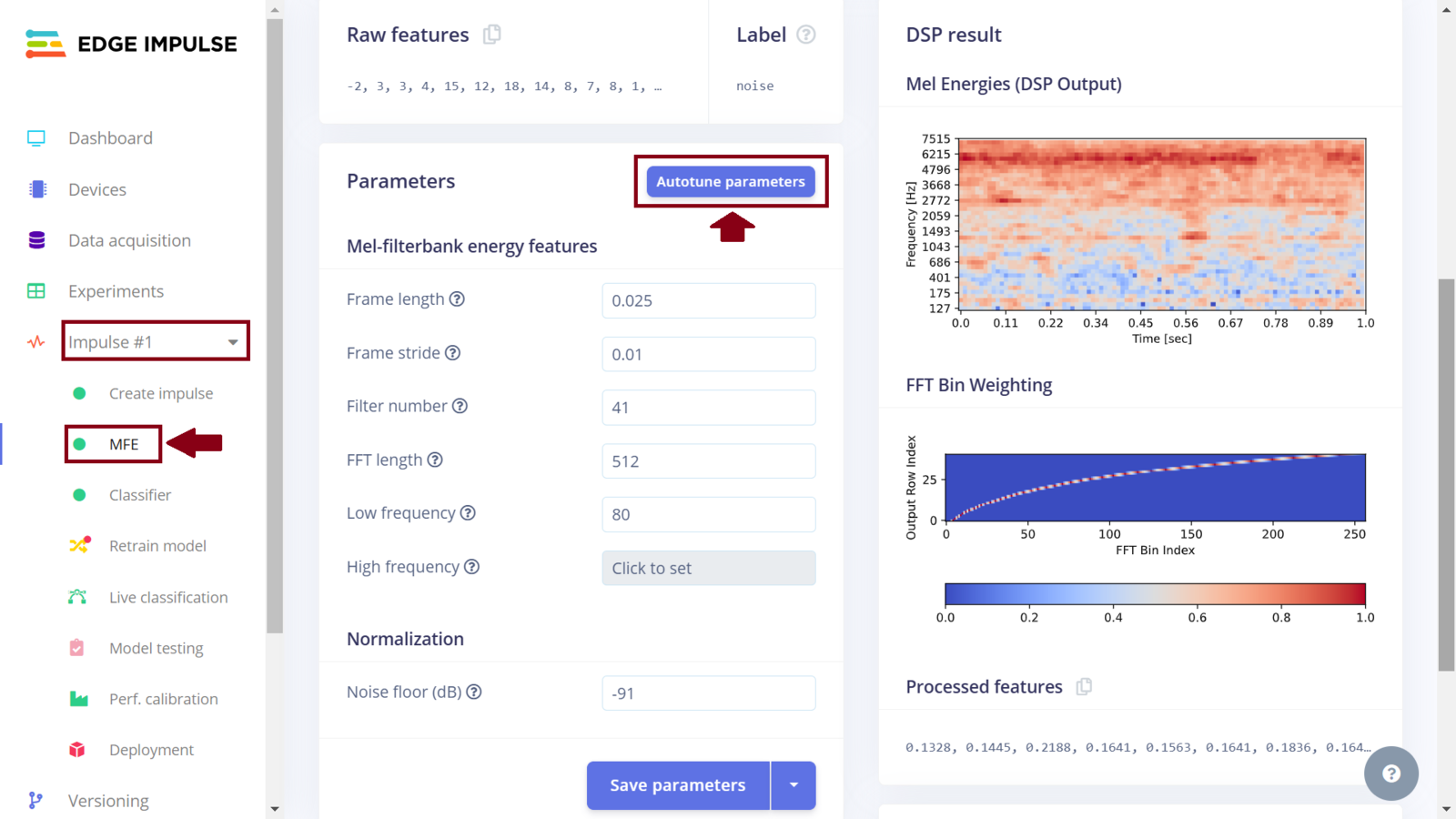
Autotune parameters
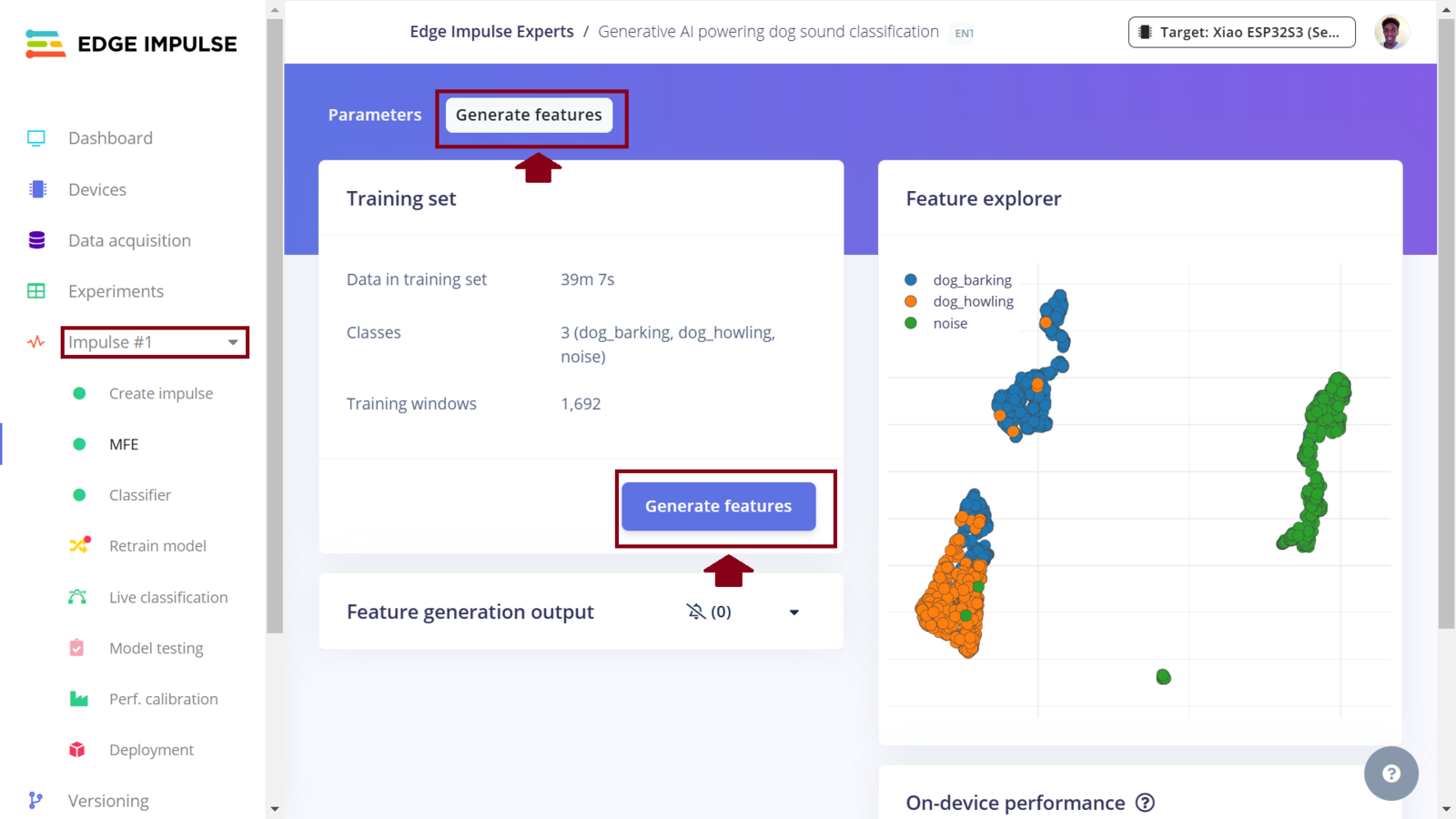
First Impulse features
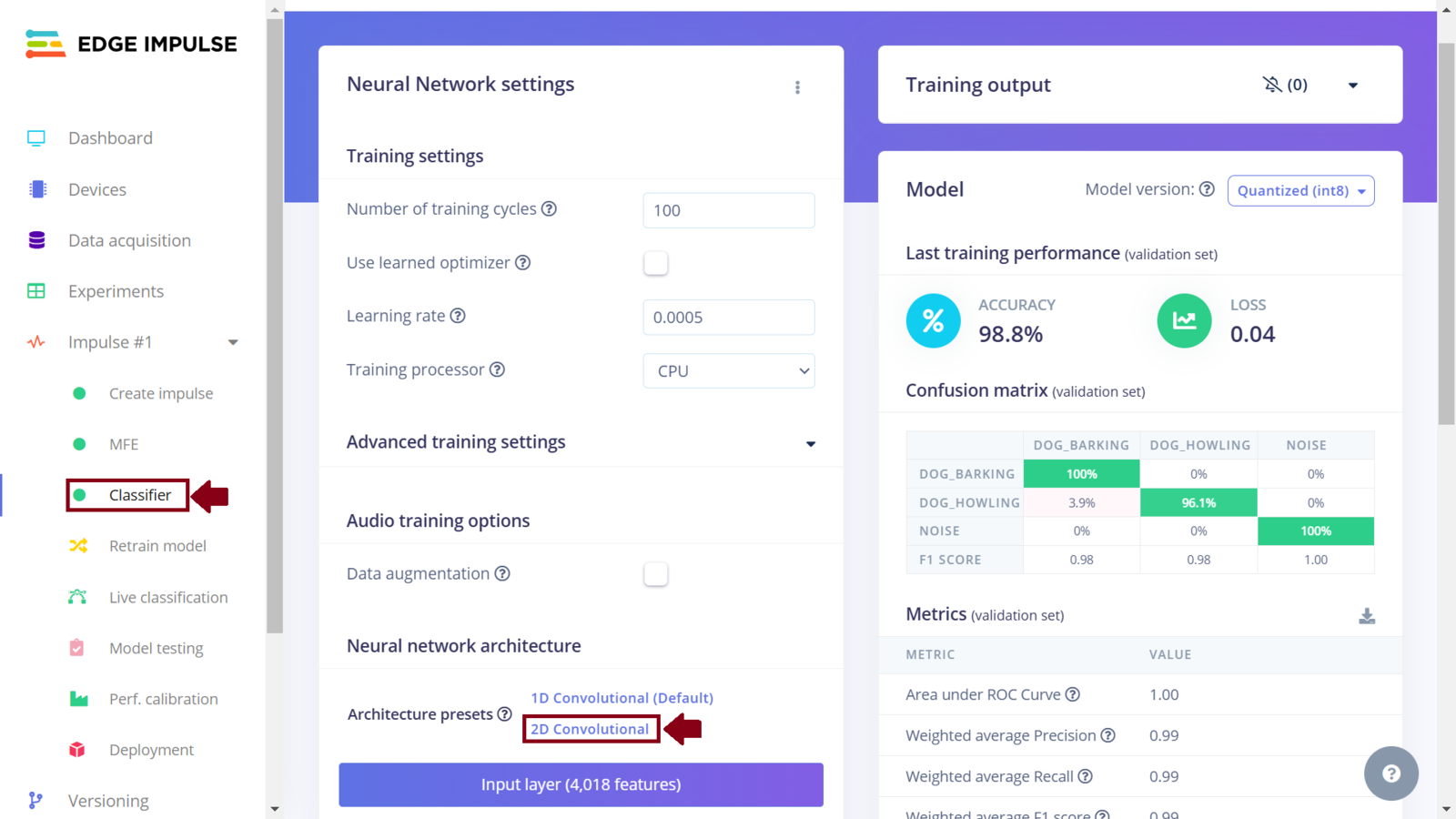
First Impulse model training
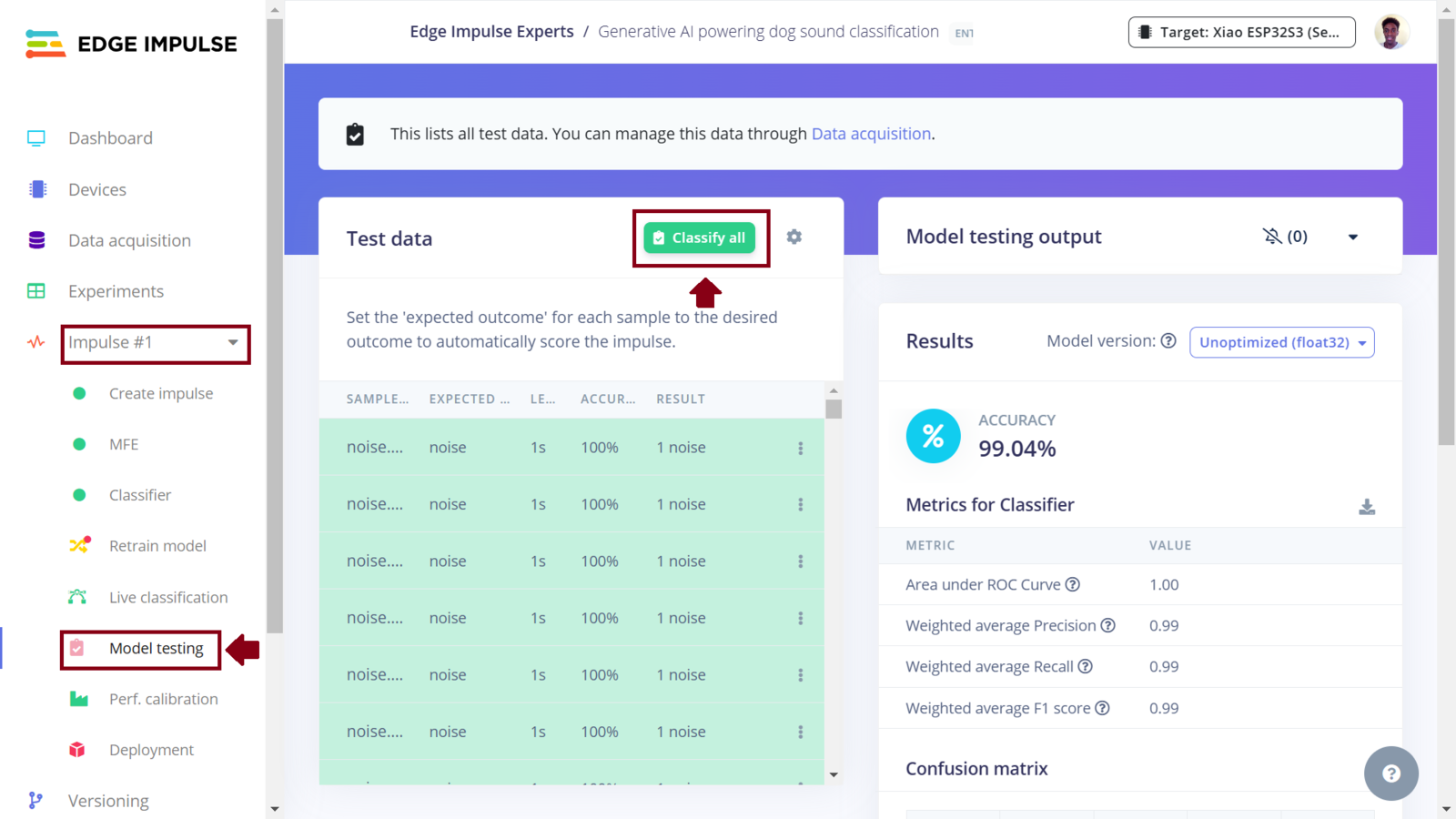
First Impulse model testing
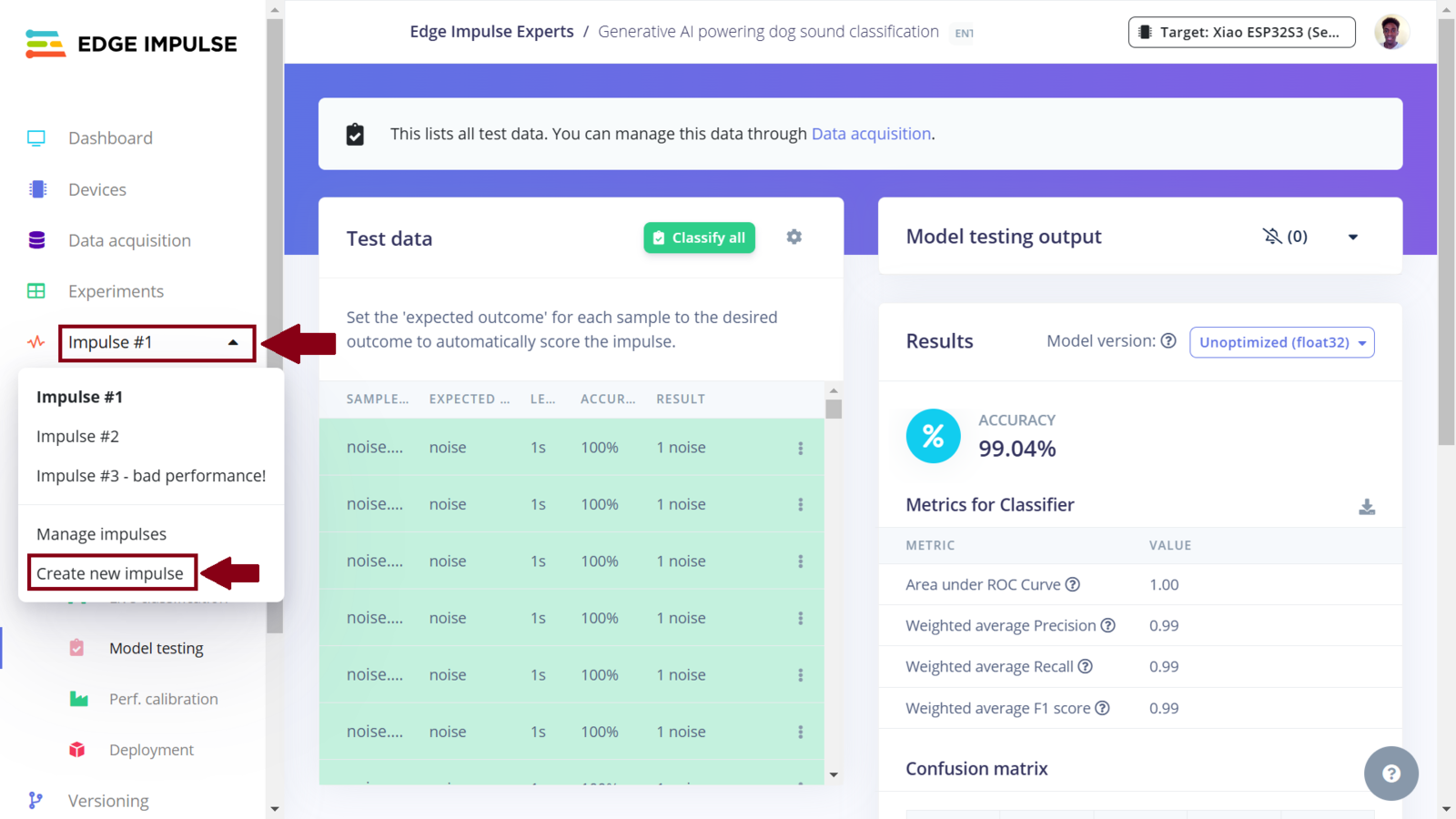
Create new impulse
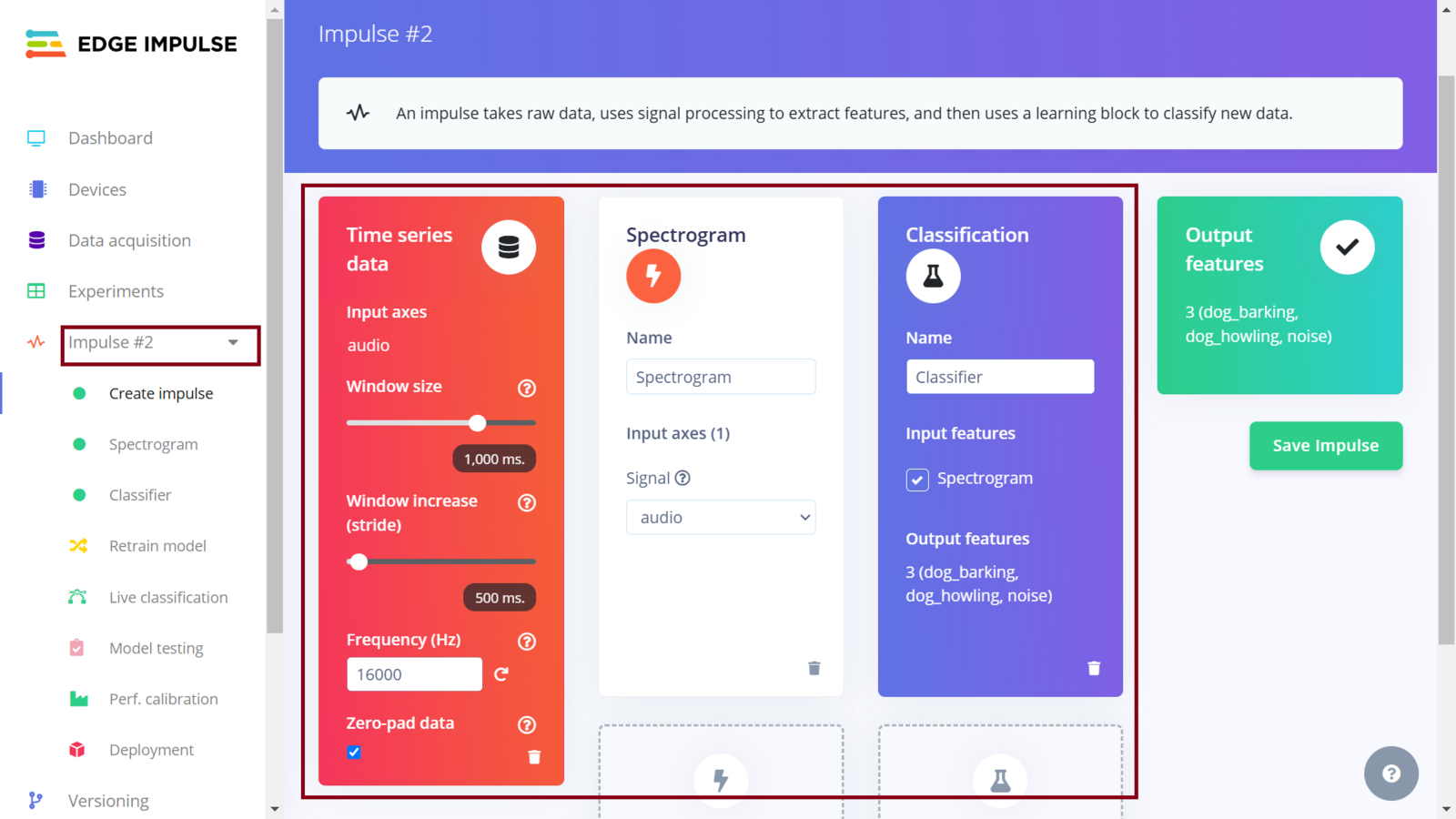
Second Impulse design
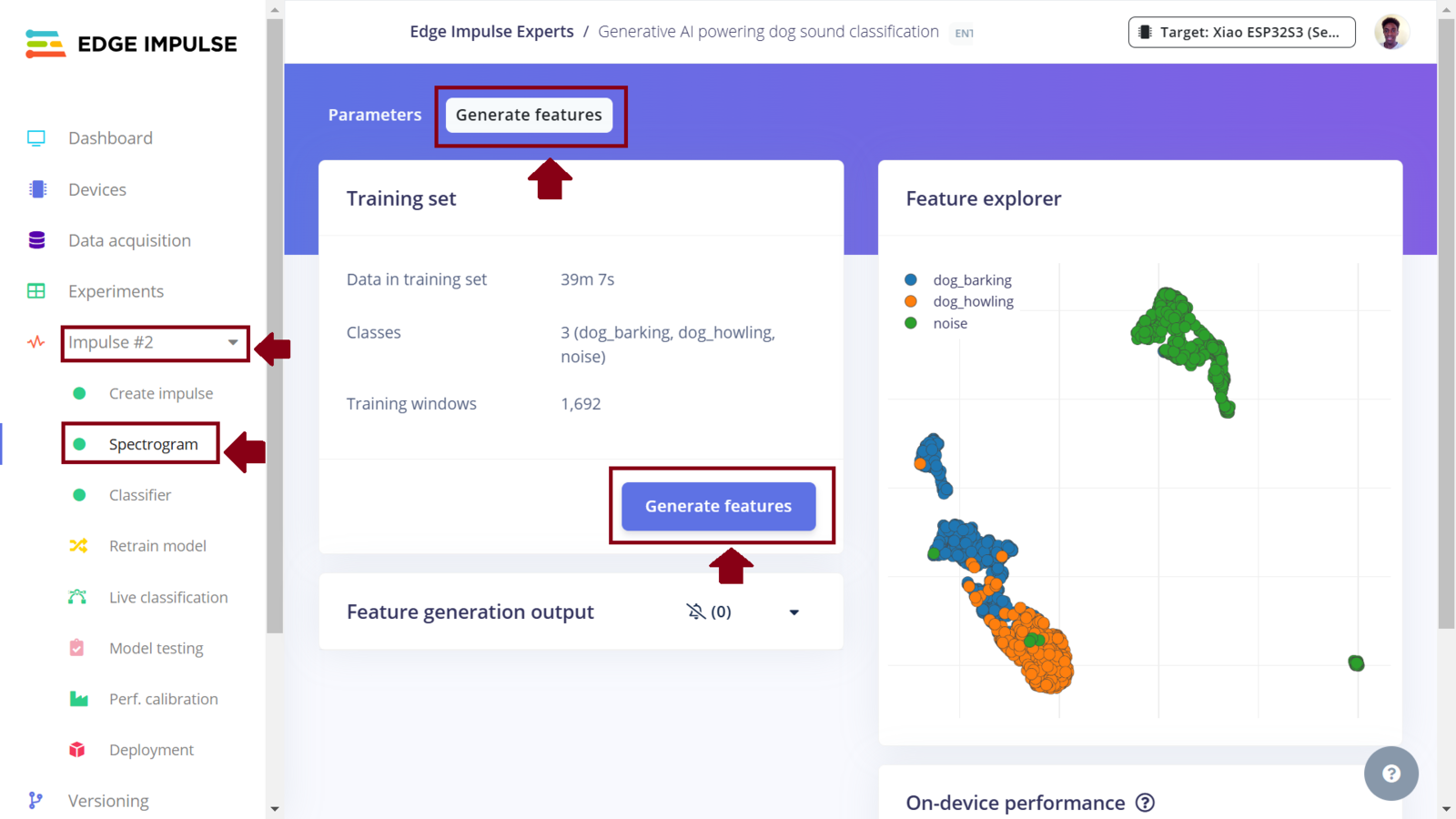
Second Impulse features
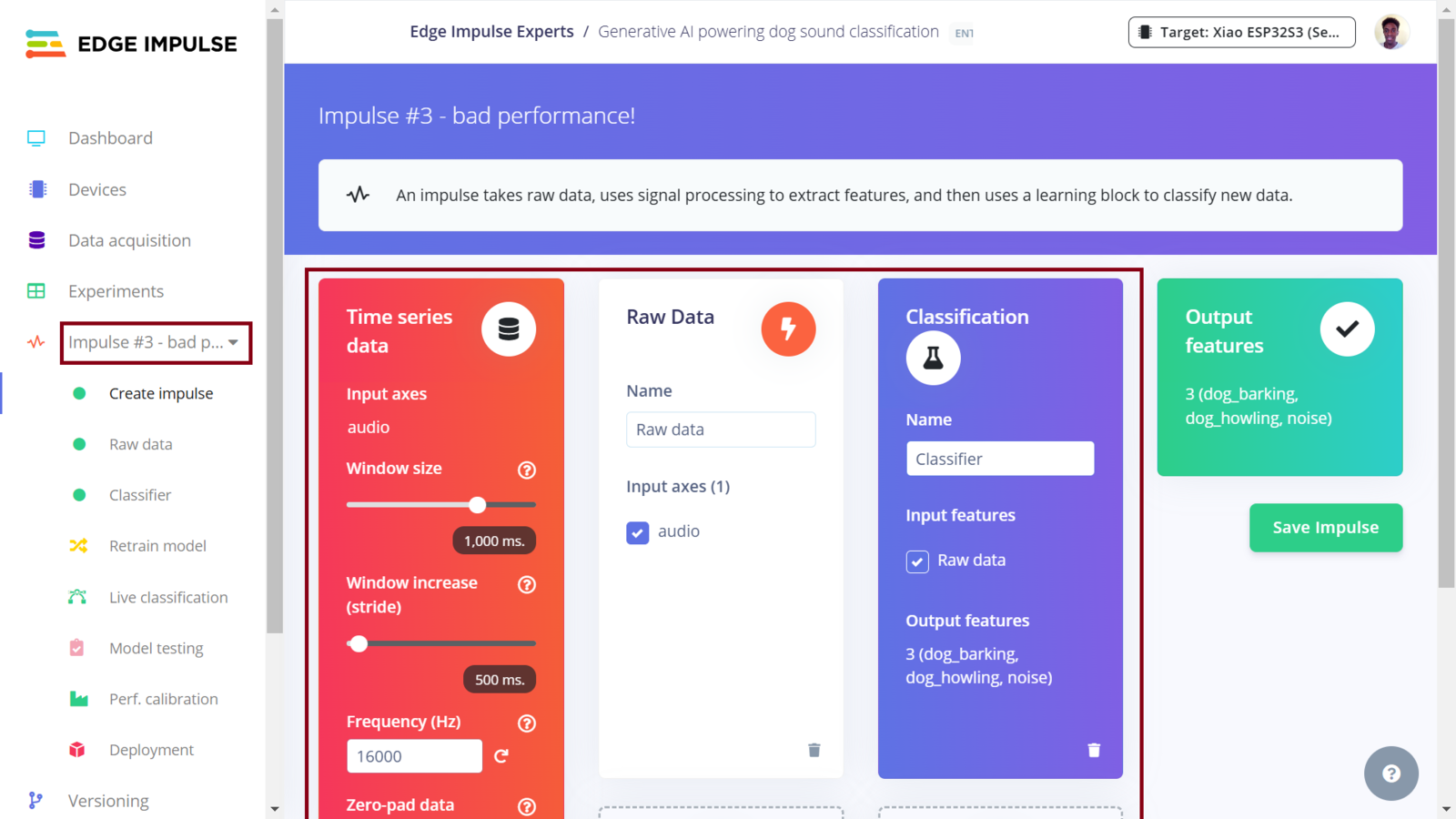
Third Impulse design
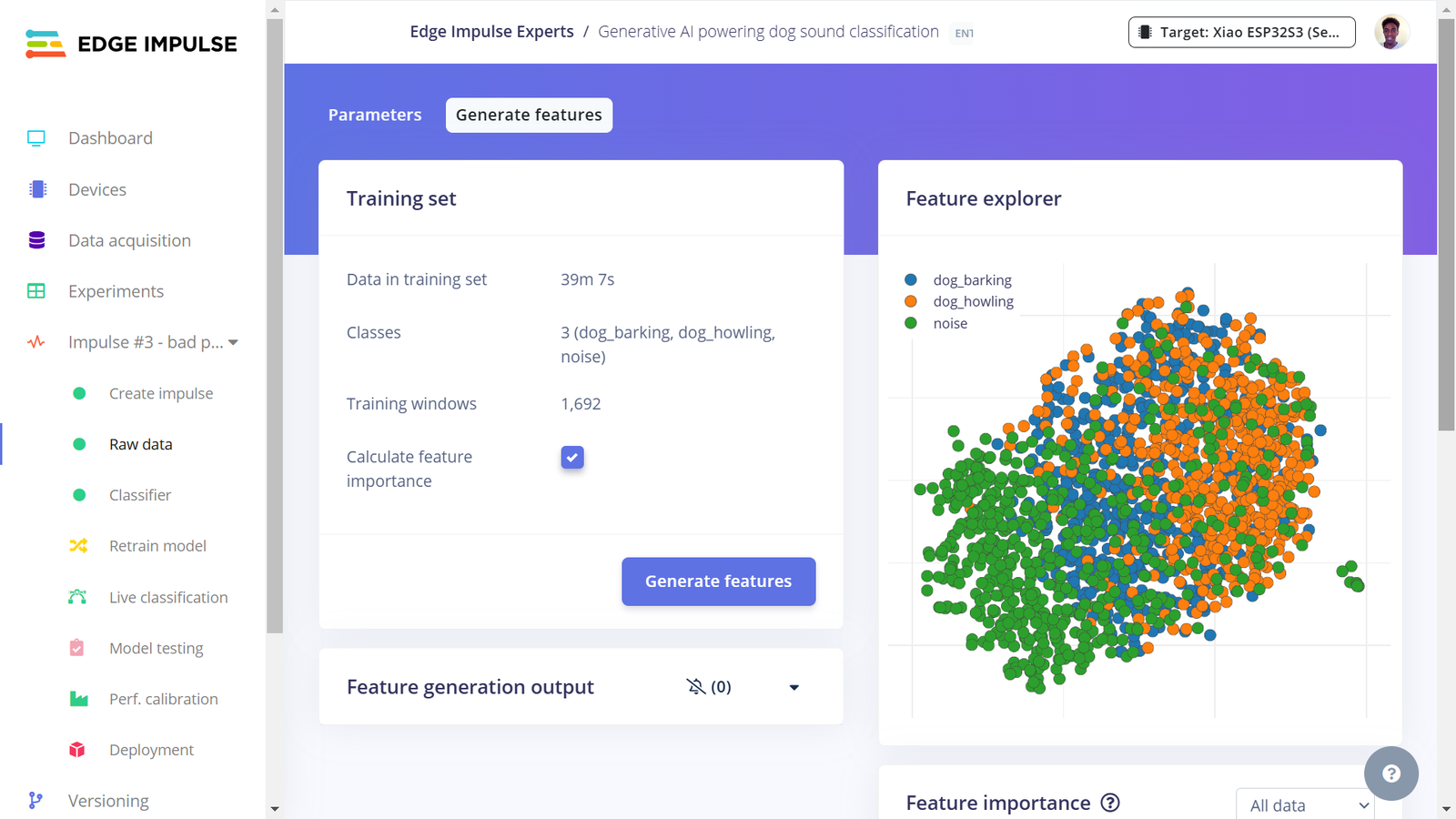
Third Impulse features
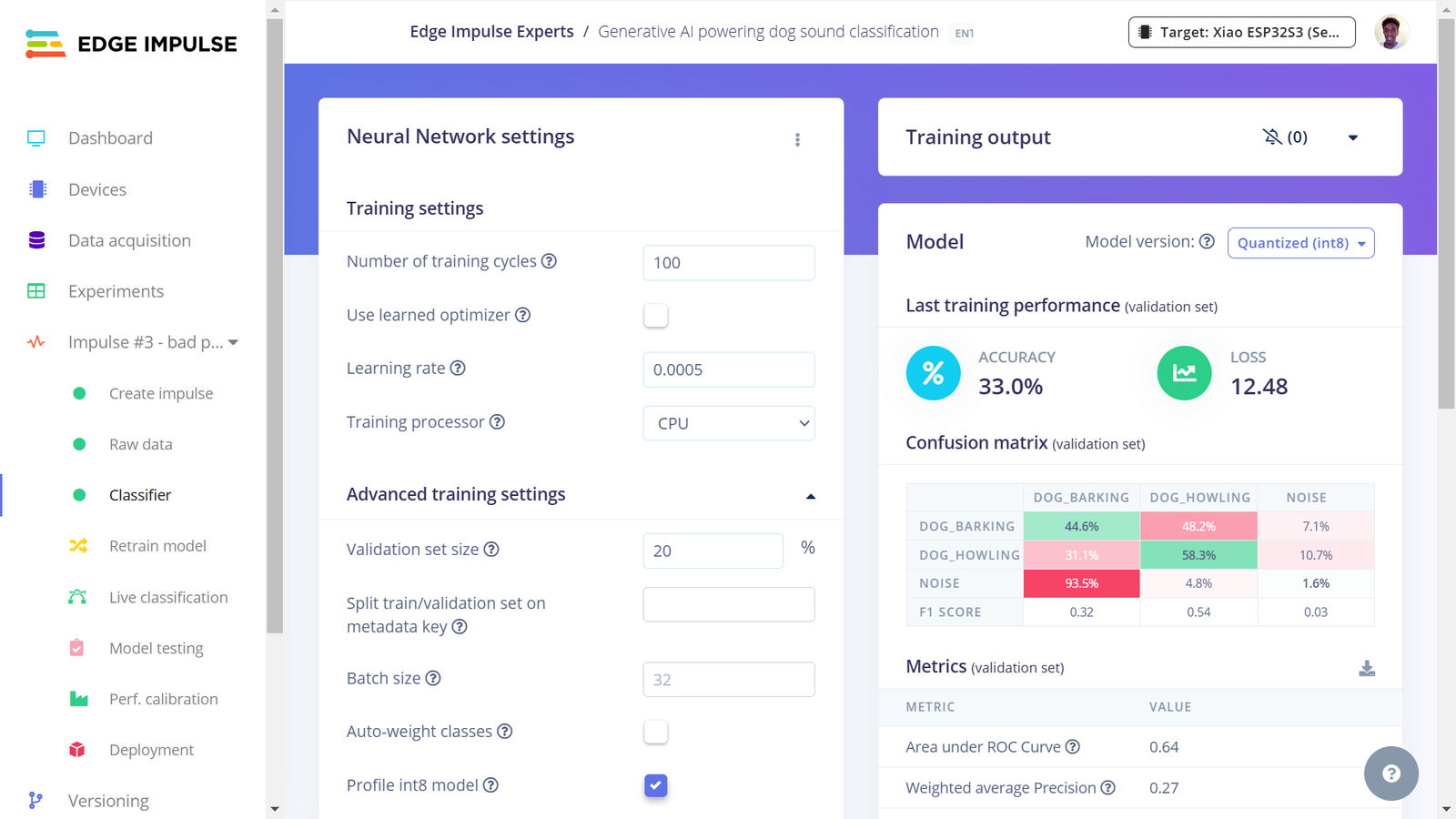
Third Impulse model training
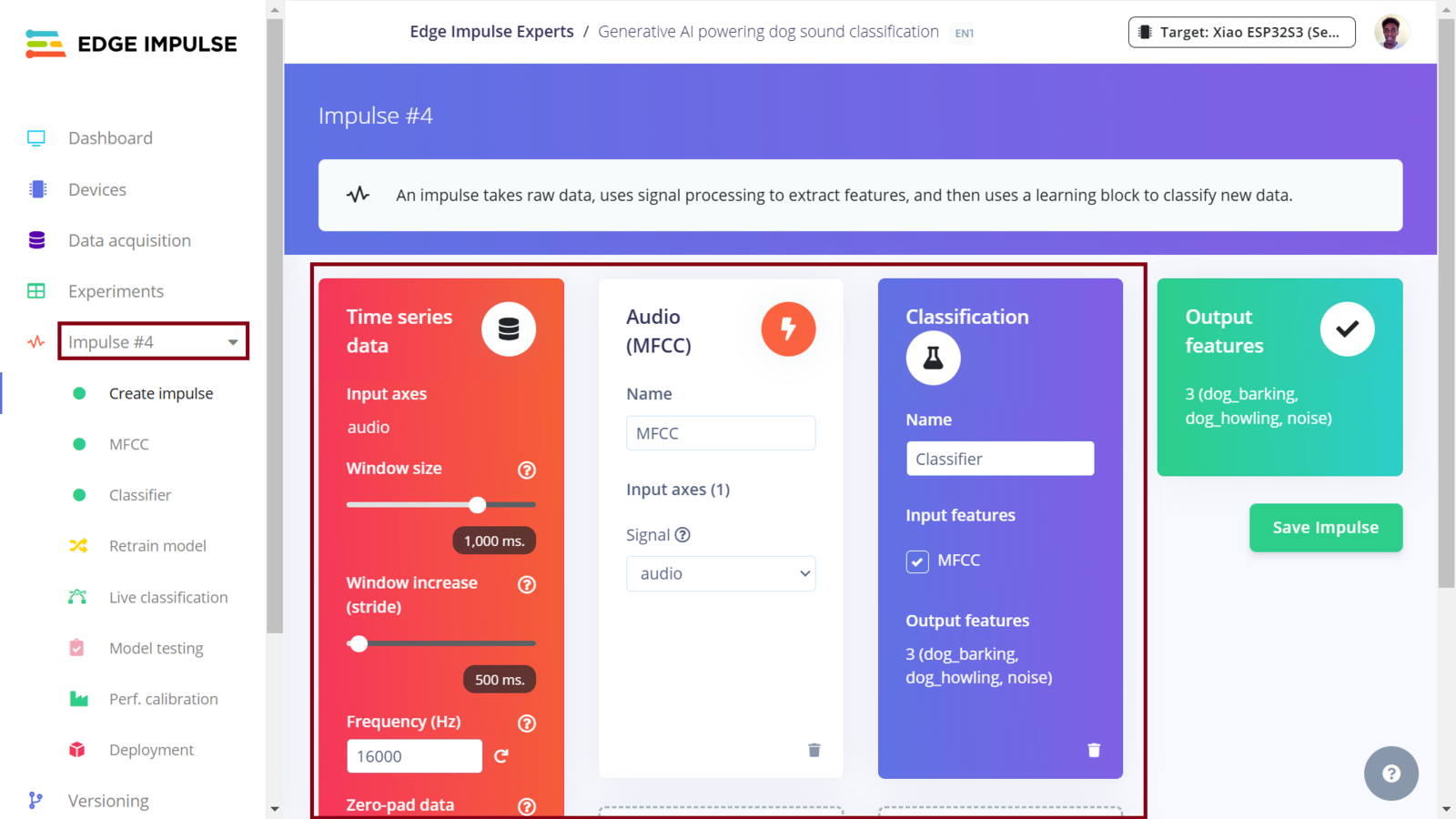
Fourth Impulse design
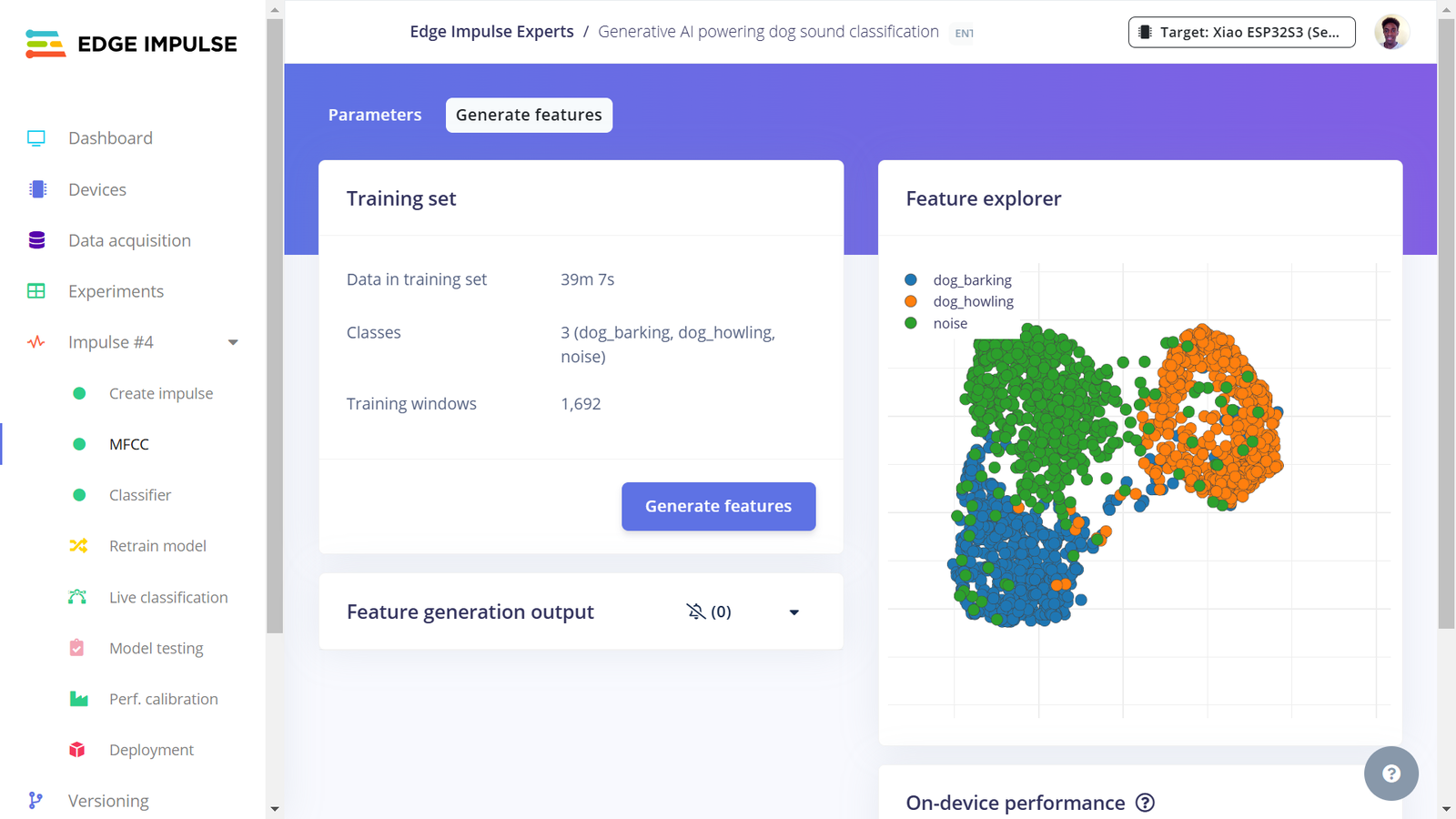
Fourth Impulse features
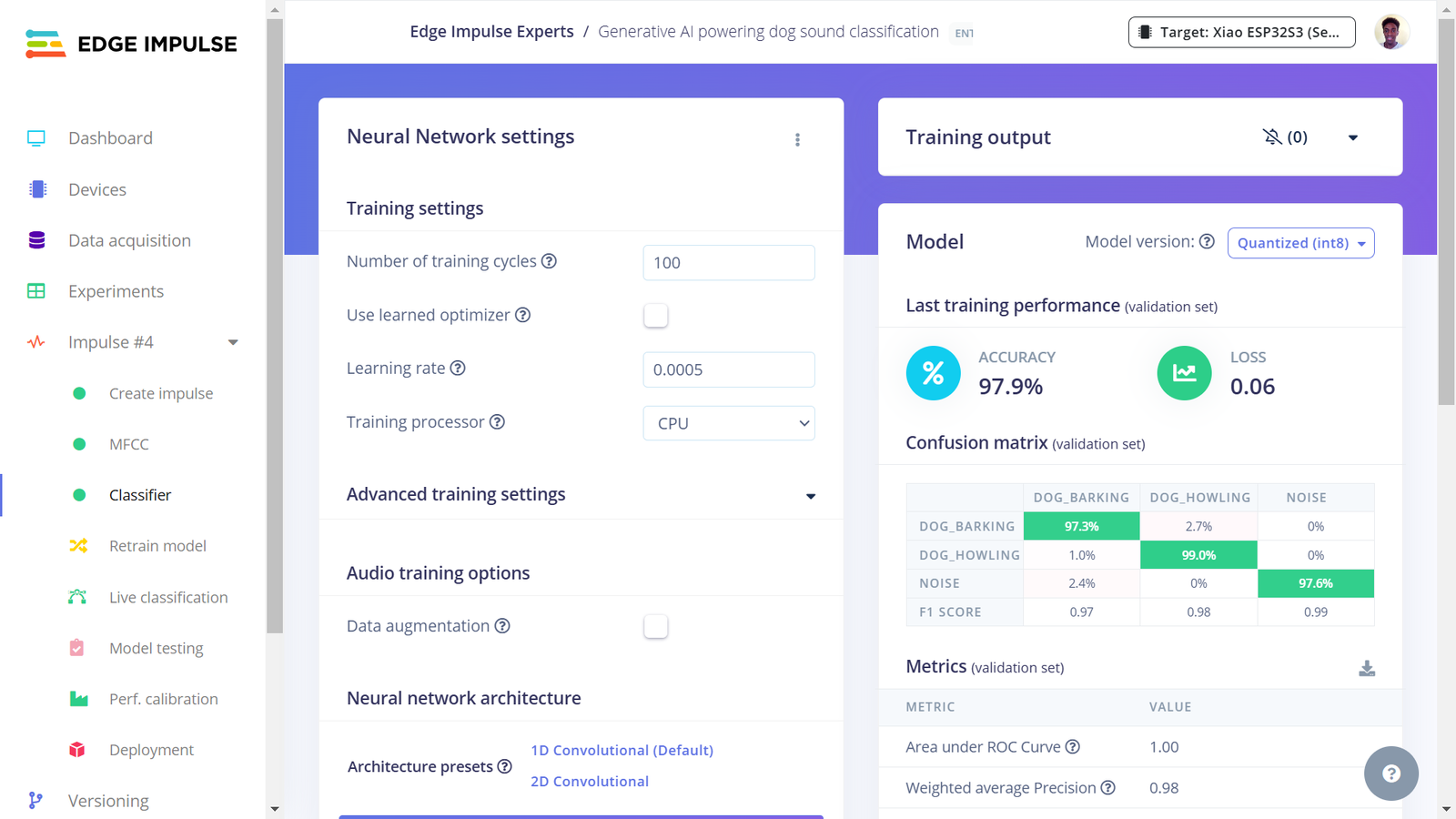
Fourth Impulse model training
Deploying the Impulses to XIAO ESP32S3
In this project, we now have four Impulses. The Experiments feature not only allows us to setup different Machine Learning processes, but it also allows us to deploy any Impulse. The MFE, Spectrogram and MFCC Impulses seem to perform well according to the model training and testing. I decided to skip deploying the Raw data Impulse since using raw data as the model input does not seem to yield good performance in this use case. Edge Impulse have documented how to use the XIAO ESP32S3. We will deploy an Impulse as an Arduino library - a single package containing the signal processing blocks, configuration and learning blocks. You can include this package (Arduino library) in your own sketches to run the Impulse locally on microcontrollers. To deploy the first Impulse to the XIAO ESP32S3 board, first we ensure that it is the current Impulse and then click “Deployment”. In the field “Search deployment options” we need to select Arduino library. Since memory and CPU clock rate are limited for our deployment, we can optimize the model so that it can utilize the available resources on the ESP32S3 (or simply, so that it can fit and manage to run on the ESP32S3). Model optimization often has a trade-off whereby we decide whether to trade model accuracy for improved performance, or reduce the model’s memory (RAM) usage. Edge Impulse has made model optimization very easy with just a click. Currently we can get two optimizations: EON compiler (gives the same accuracy but uses 27% less RAM and 42% less ROM) and TensorFlow Lite. The Edge Optimized Neural (EON) compiler is a powerful tool, included in Edge Impulse, that compiles machine learning models into highly efficient and hardware-optimized C++ source code. It supports a wide variety of neural networks trained in TensorFlow or PyTorch - and a large selection of classical ML models trained in scikit-learn, LightGBM or XGBoost. The EON Compiler also runs far more models than other inferencing engines, while saving up to 65% of RAM usage. TensorFlow Lite (TFLite) is an open-source machine learning framework that optimizes models for performance and efficiency, making them to be able to run on resource constrained devices. To enable model optimizations, I selected the EON Compiler and Quantized (int8).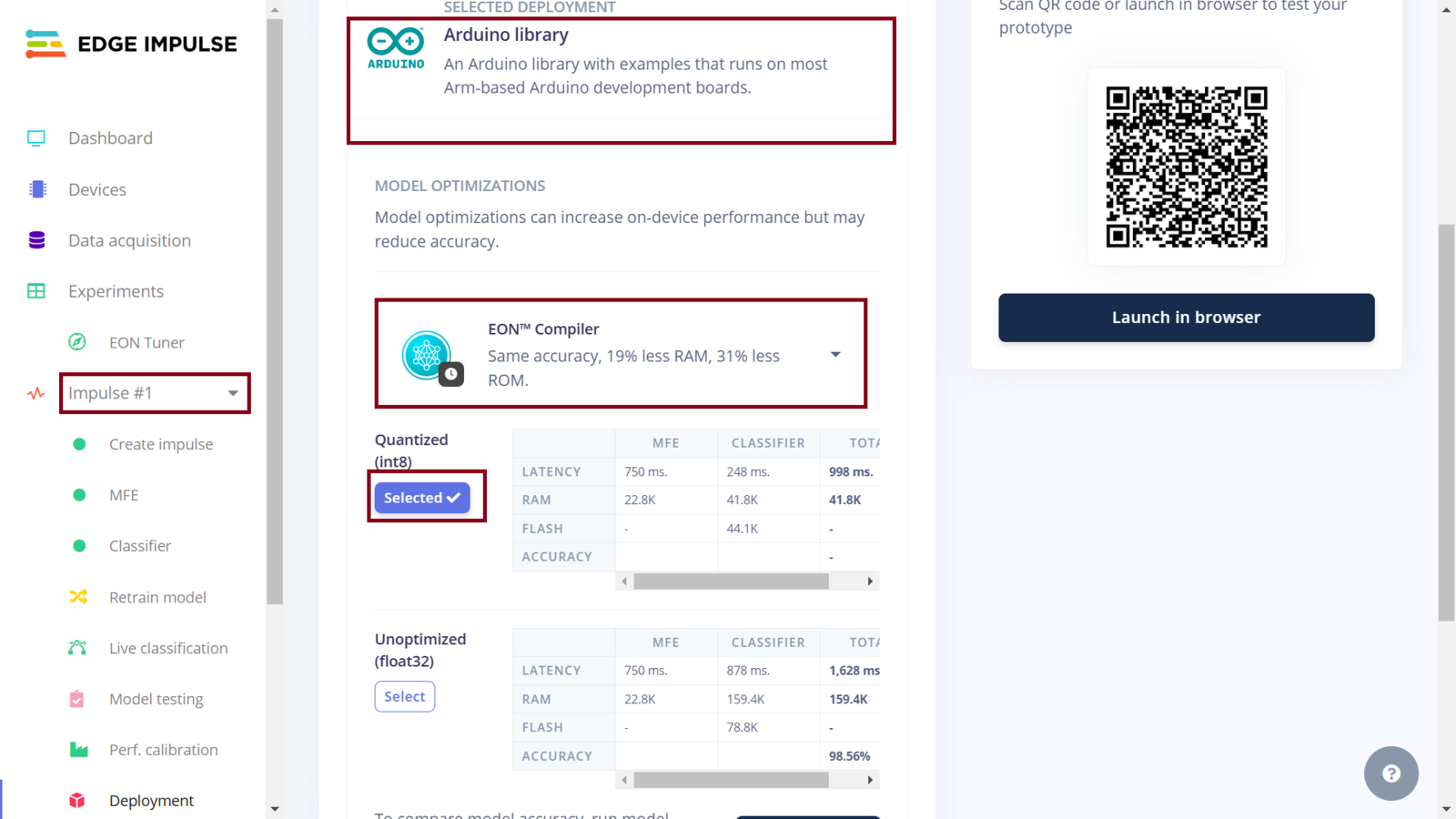
Impulse 1 deployment
esp32_microphone example code. The deployment steps are also documented on the XIAO ESP32S3 deployment tutorial. Once we open the esp32_microphone sketch, we need to change the I2S library, update the microphone functions, and enable the ESP NN accelerator as described by MJRoBot (Marcelo Rovai) in Step 6. You can also obtain the complete updated code in this GitHub repository. Before uploading the code, we can follow the Seeed Studio documentation to download the ESP32 board on the Arduino IDE and then select the XIAO ESP32S3 board for uploading. With the XIAO ESP32S3 board still connected to the computer, we can open the Serial Monitor and see the inference results. We can see that the Digital Signal Processing (DSP) takes around 475ms (milliseconds) and the model takes around 90ms to classify the sound - which is very impressive. However, when I played YouTube videos of dog sound in front of the XIAO ESP32S3, like this one, the model did not correctly classify dog barks and we can see most of the confidence was on noise. Although this appears to be an issue, it may actually stem from the difference in sound quality between training and inference - the test using synthetic data performed well but deployment performance was not the same. In this case, the sounds captured during inference have noise, the volume of dog sounds is different, and overall the recordings are not clear as compared to the dataset samples.
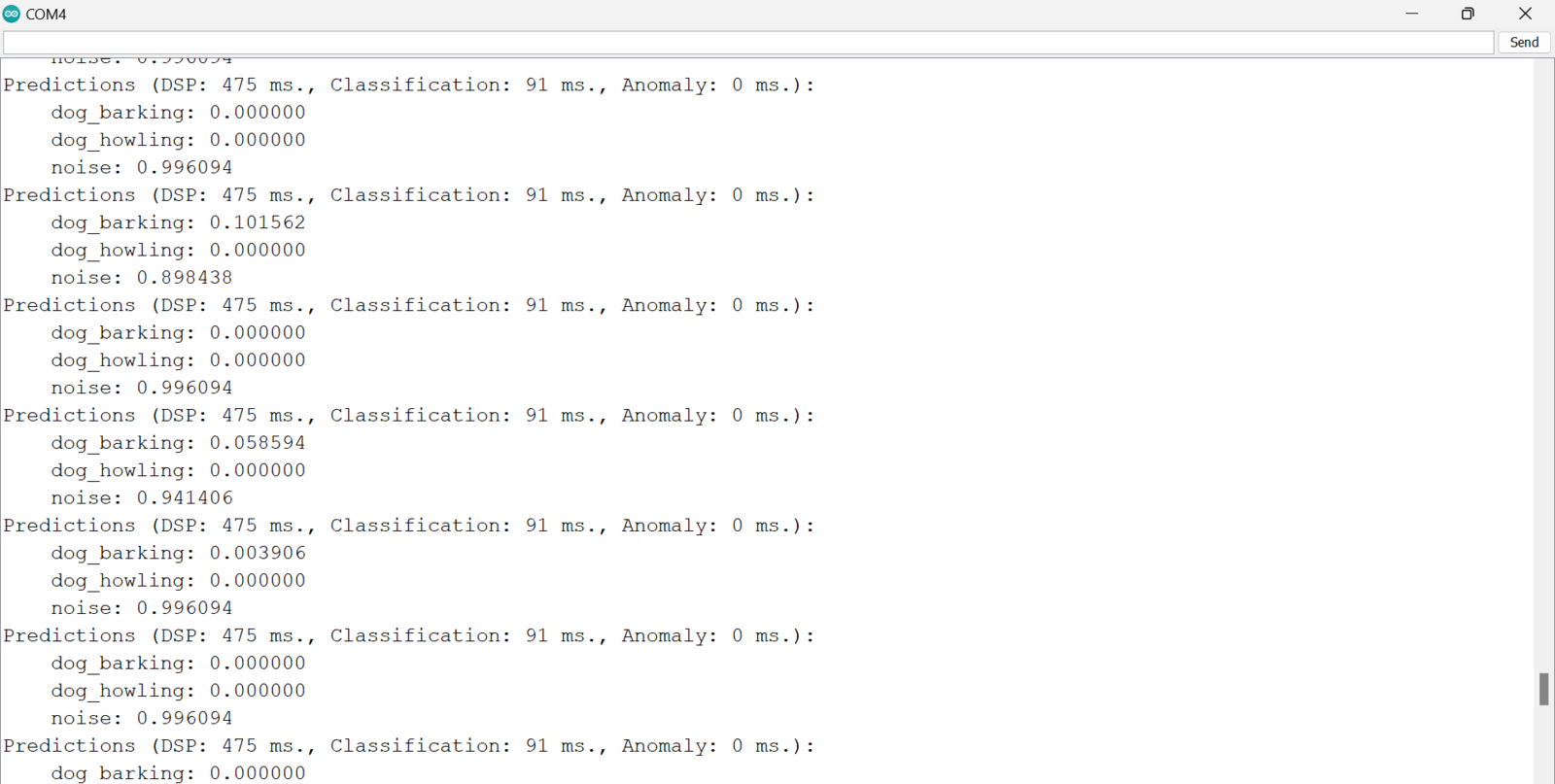
Impulse 1 inference results
model-parameters and tflite-model folders to the first Impulse’s Arduino library folder, overwriting the existing files with the updated model parameters. Unfortunately, the model is not able to run on the ESP32S3 board and we get an error failed to allocate tensor arena. This error means that we have run out of RAM on the ESP32S3.
Lastly, I experimented with deploying the MFCC Impulse. This algorithm works best for speech recognition but the model training and testing show that it performs well for detecting dog sounds. Following similar steps, I deployed the fourth Impulse using the EON Compiler and Quantized (int8) model optimizations. Surprisingly, this Impulse (using the MFCC processing algorithm) delivers the best performance even compared to the MFE pre-processing block. The Digital Signal Processing (DSP) takes approximately 285ms, with classification taking about 15ms. For detecting dog sounds, this Impulse accurately identifies with great confidence, demonstrating the positive impact of a DSP block on model performance!
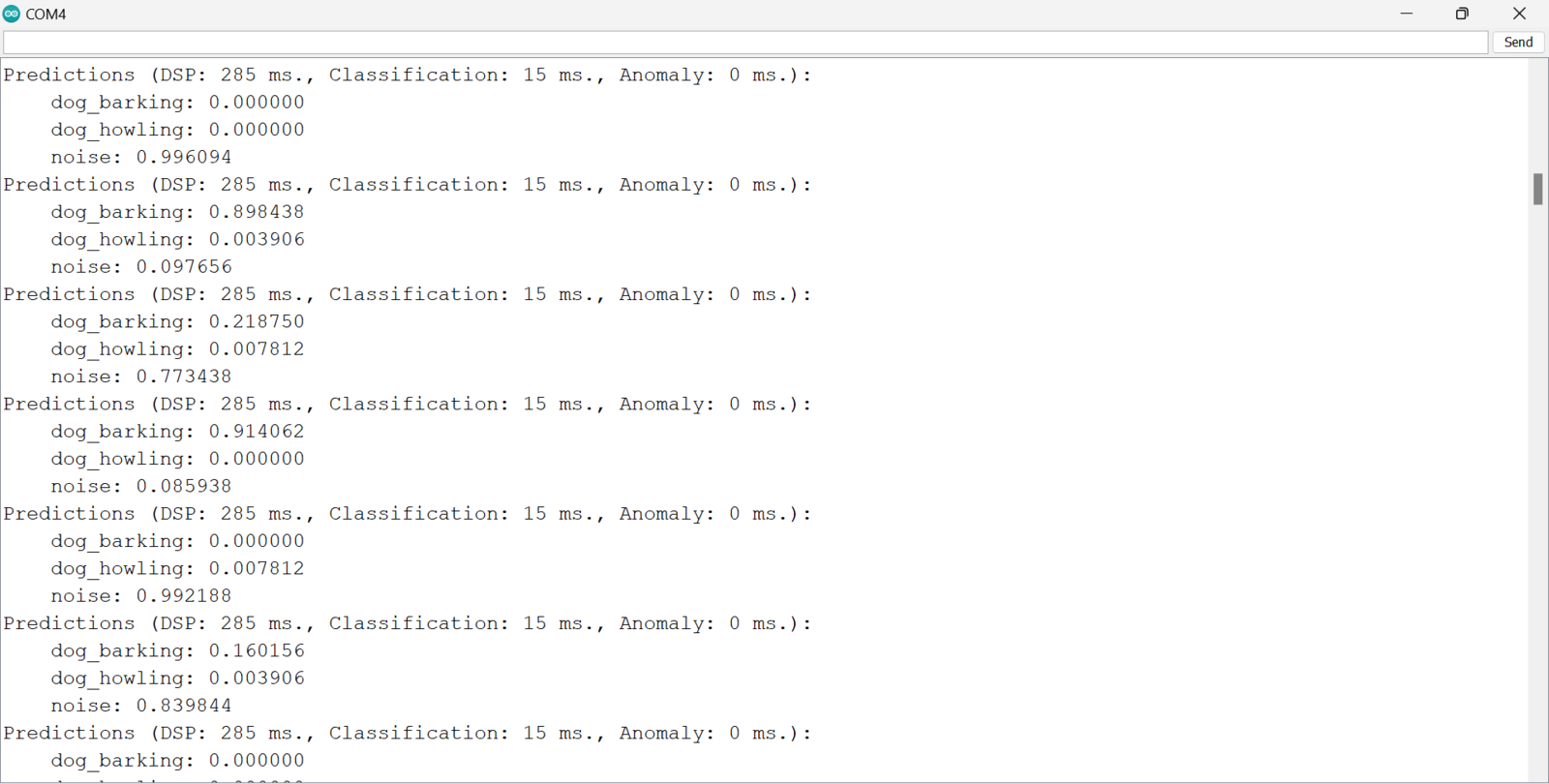
Impulse 4 inference results
Assembling the Wearable
A solid gadget needs a solid case! We are close, so its time to put our wearable together. The wearable’s components can be categorized into two parts: the electronic components and the 3D printed components. The 3D printed component files can be downloaded from printables.com. The wearable has a casing which is made up of two components: one holds the electrical components while the other is a cover. I 3D printed the housing and cover with PLA material.
Wearable parts

Attaching straps using super glue

Wearable on stand
- Seeed Studio XIAO ESP32S3 (Sense) development board with the camera detached
- SSD1306 OLED display
- 3.7V lithium battery. In my case, I used a 500mAh battery.
- Some jumper wires and male header pins

Soldering battery wires

Connection OLED to XIAO ESP32S3

Using wearable case

Assembled electronics

Wearable classifying safe environment

Wearable classifying dog barking sound

Wearable classifying dog howling sound
Result
At last, our dog sound detection wearable is ready. We have successfully trained, tested, optimized, and deployed a Machine Learning model on the XIAO ESP32S3 Sense board. Once the wearable is powered on, the ESP32S3 board continuously samples sound of 1 second and predicts if it has heard dog sounds or noise. Note that since there is a latency of around 300 milliseconds (285ms for Digital Signal Processing and 15ms for classification) between the sampling and inference results. Some sounds may not be captured in time since other processes of the program will be executed. In this case, to achieve a smaller latency, we can target another hardware, such as the Syntiant TinyML board which features an always-on sensor and speech recognition processor, the NDP101.
Wearable
Conclusion
This low cost and low-power environmental sensing wearable is one of the many solutions that embedded AI has to offer. The presence of security dogs provides a sense of security and an unmatched source of environment state feedback to us humans. However, there is a great need to also understand how these intelligent animals operate so that we can understand and treat them better. The task at hand was very complicated, to capture sounds without causing disturbance to dogs, train a dog sound detection model, and optimize the model to run on a microcontroller. However, by utilizing the upcoming technologies of synthetic data generation and powerful tools offered by the Edge Impulse platform; we have managed to train and deploy a custom Machine Learning model that can help workers. The new Experiments feature of Edge Impulse is a powerful tool and it comes in very handy in the Machine Learning development cycle. There are numerous configurations that we can utilize to make the model more accurate and reduce hardware utilization on edge devices. In my experiments, I tried other configuration combinations and chose to present the best and worst performing ones in this documentation. Are you tired of trying out various Impulse configurations and deployment experimentation? Well, Edge Impulse offers yet another powerful tool, the EON Tuner. This tool helps you find and select the best embedded machine learning model for your application within the constraints of your target device. The EON Tuner analyzes your input data, potential signal processing blocks, and neural network architectures - and gives you an overview of possible model architectures that will fit your chosen device’s latency and memory requirements. First, make sure you have data in your Edge Impulse project. Next, select the “Experiments” tab and finally the “EON Tuner” tab. On the page, configure your target device and your application budget, and then click the “New run” button.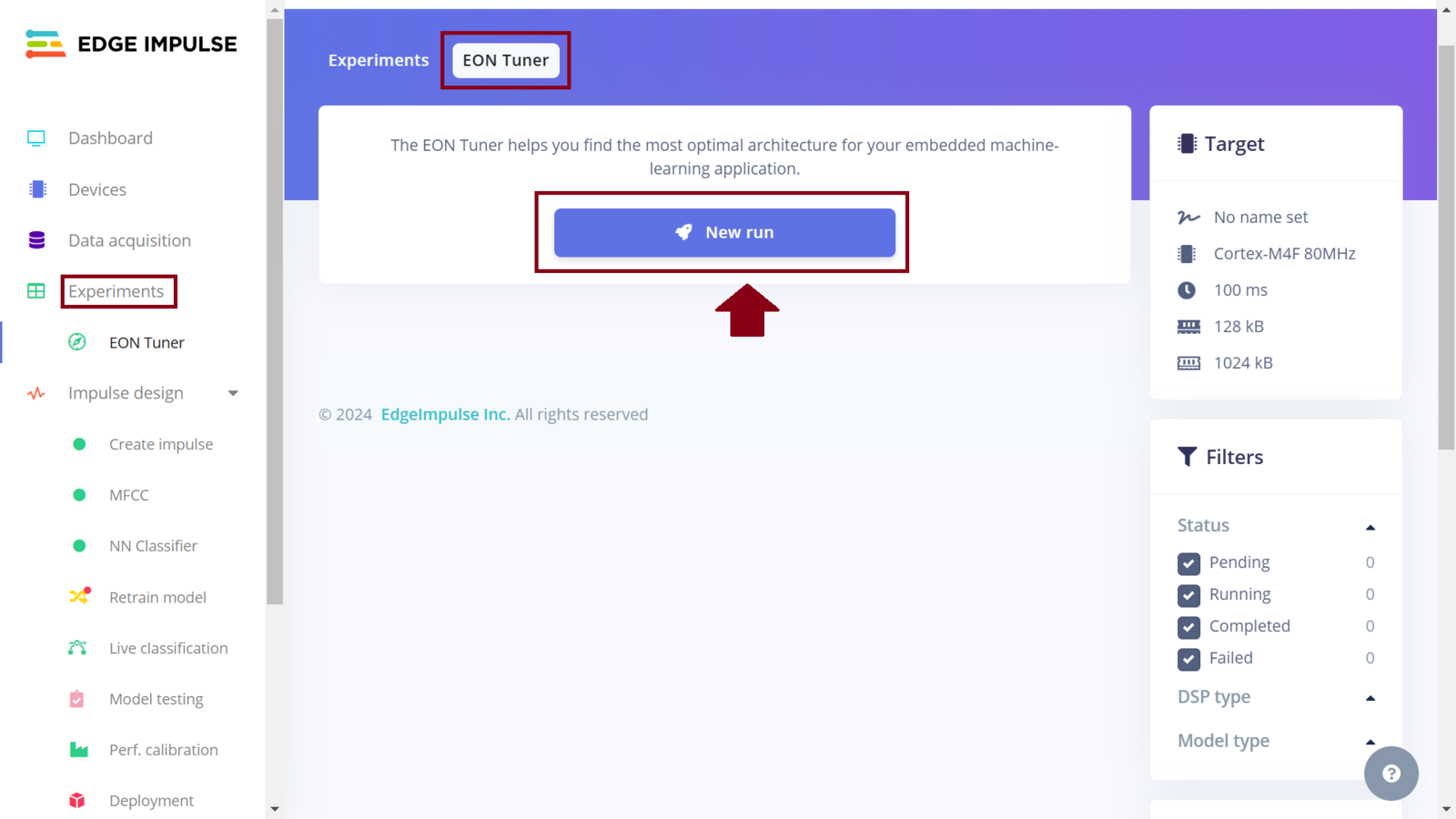
EON Tuner