Story
In any industry with safety requirements, workers need to be able to report accidents that occur in the workplace. In this project, we are developing a device where employees can simply speak into a microphone to report an accident. The device will be loaded with a machine-learning model that can recognize an accident-reporting keyword. This “keyword spotting” implementation can speed up the reporting process, or make it easier for employees who may not be able to write due to work conditions or literacy. We are only focused on the capability of the device to learn and then recognize our selected keyword here, but future work could include the ability to log events, record audio reports of the incident that has occurred, or other applications.
Hardware
The development board used in this project is the Nordic Thingy:53. It allows you to create prototypes and proof of concept devices without building customized hardware. Its twin Arm Cortex-M33 processors provide enough processing power and memory to execute embedded machine learning (ML) models directly on the development platform. The Nordic Thingy:53 can be linked to an Edge Impulse Studio account using the nRF Edge Impulse app. It enables you to download trained ML models to the Thingy:53 for deployment and local inferencing, and wirelessly communicate sensor data to a mobile device through Bluetooth LE. It also supports a wired serial connection for to a computer, for use in Edge Impulse Studio. To learn more about configuring the Thingy:53, you can check out the Docs here.Data Collection
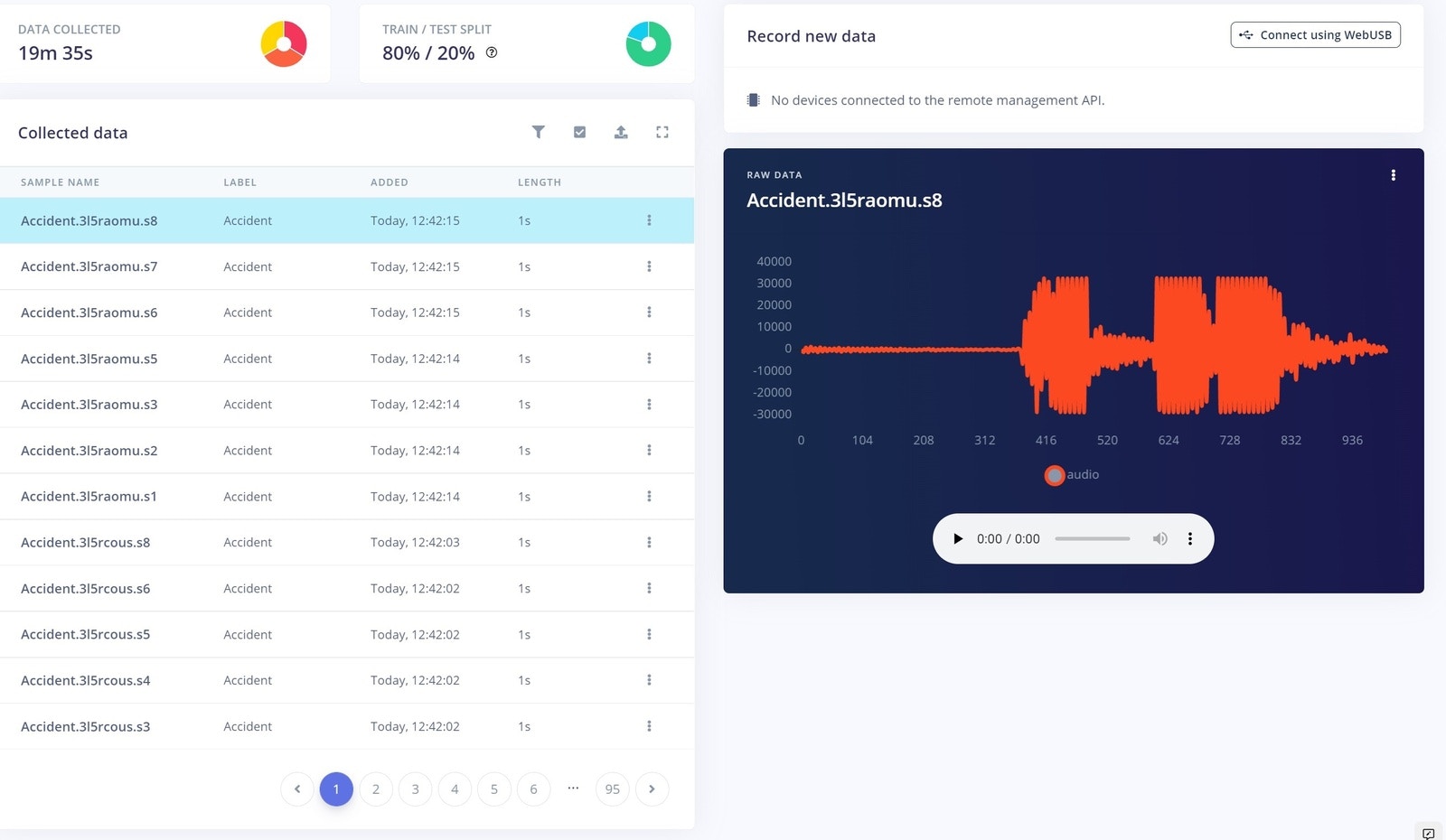
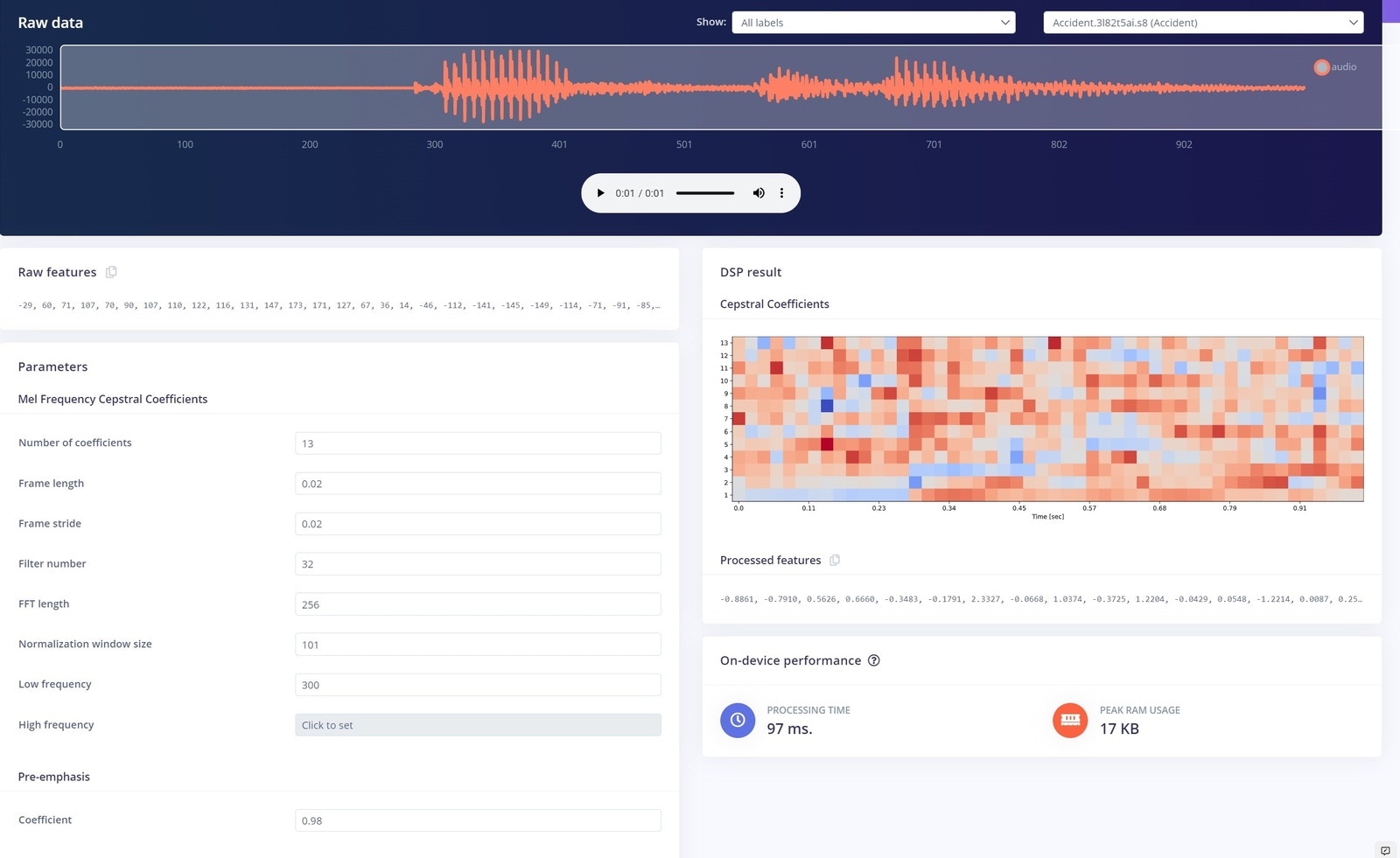
Data Collection is one of the most important steps in a machine learning project. In this project, we used the nRF Edge Impulse app for the Data collection, making it easy to capture input data. The main keyword used here for reporting an accident, is literally the word Accident itself. Below, you can see our data collection settings. We recorded 10 seconds of data, at 16Khz frequency.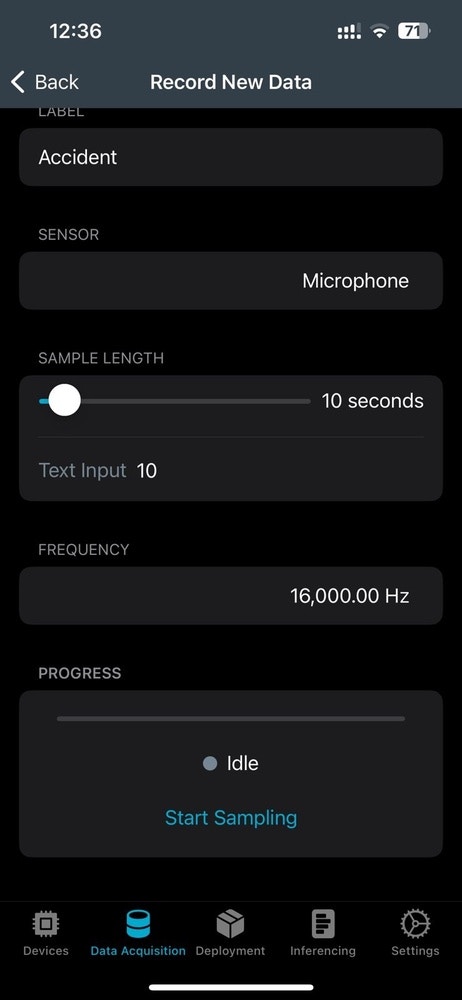
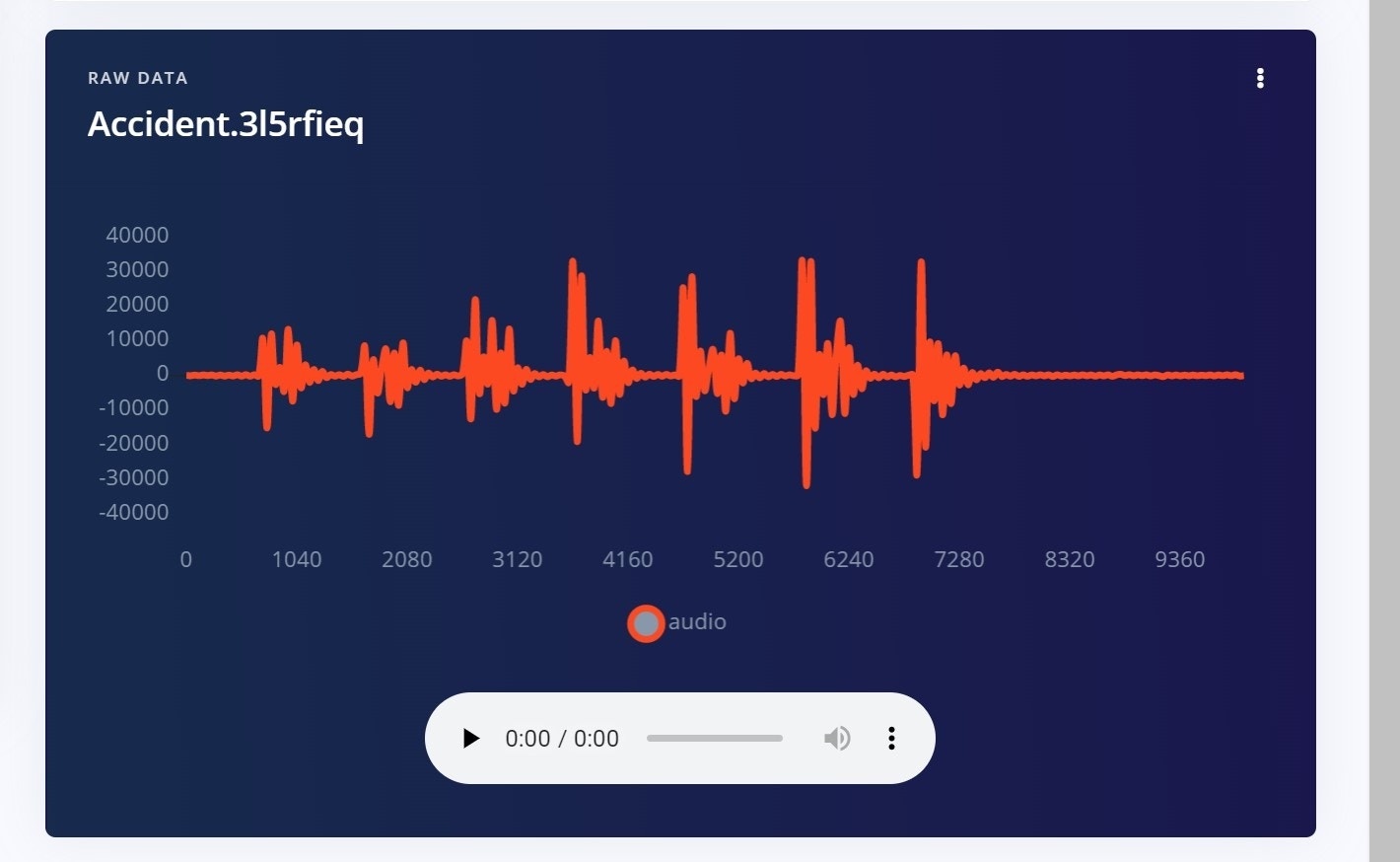
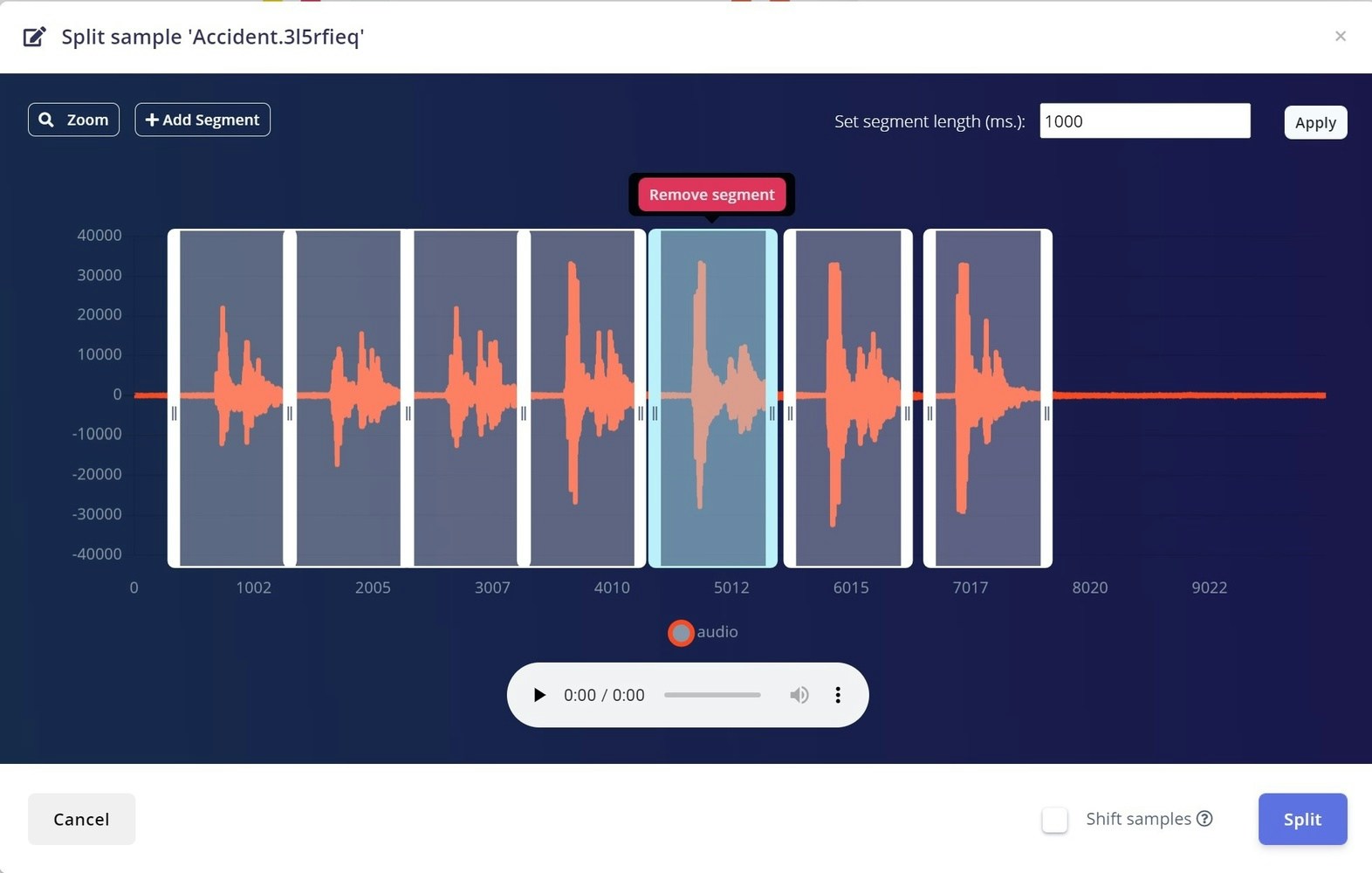
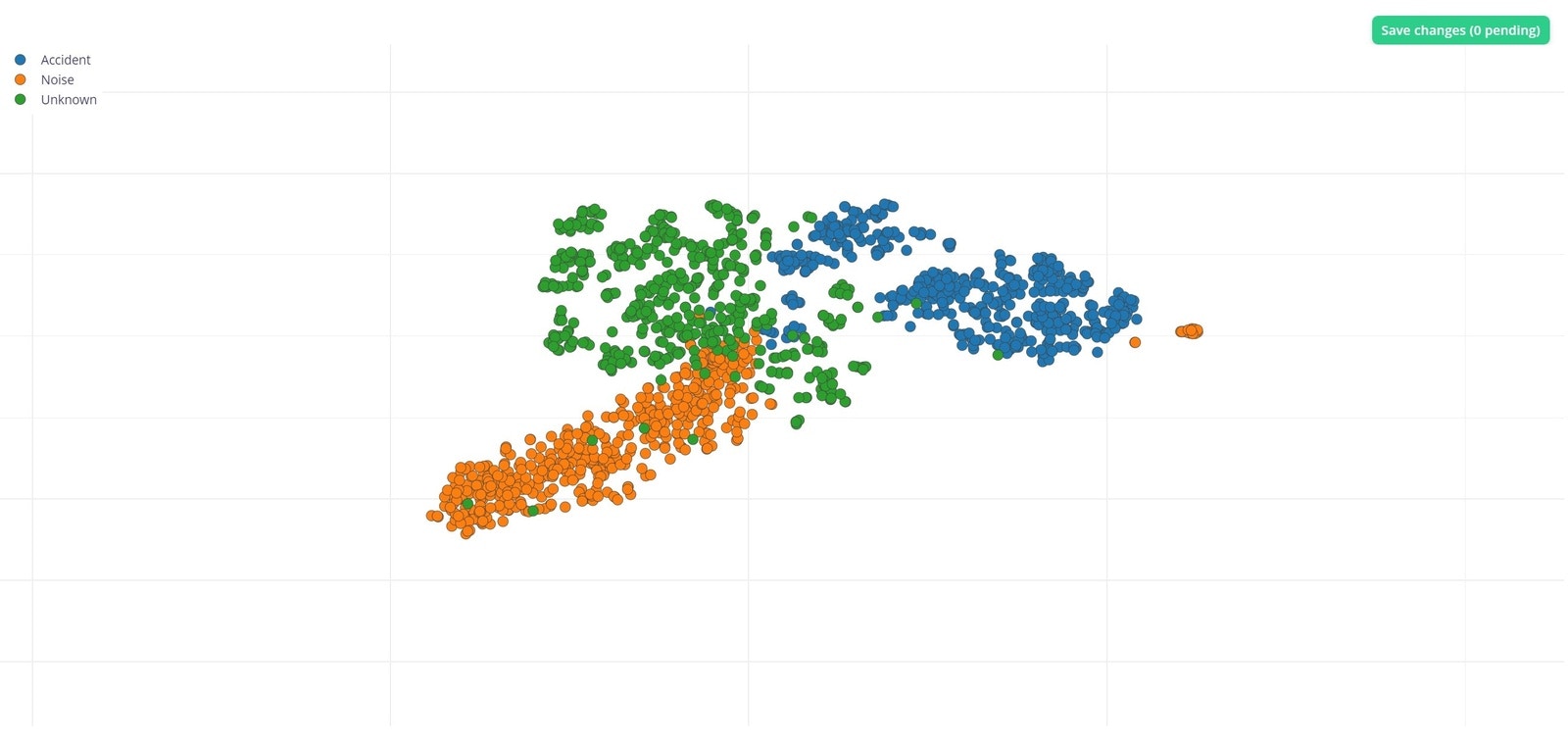
Data Explorer
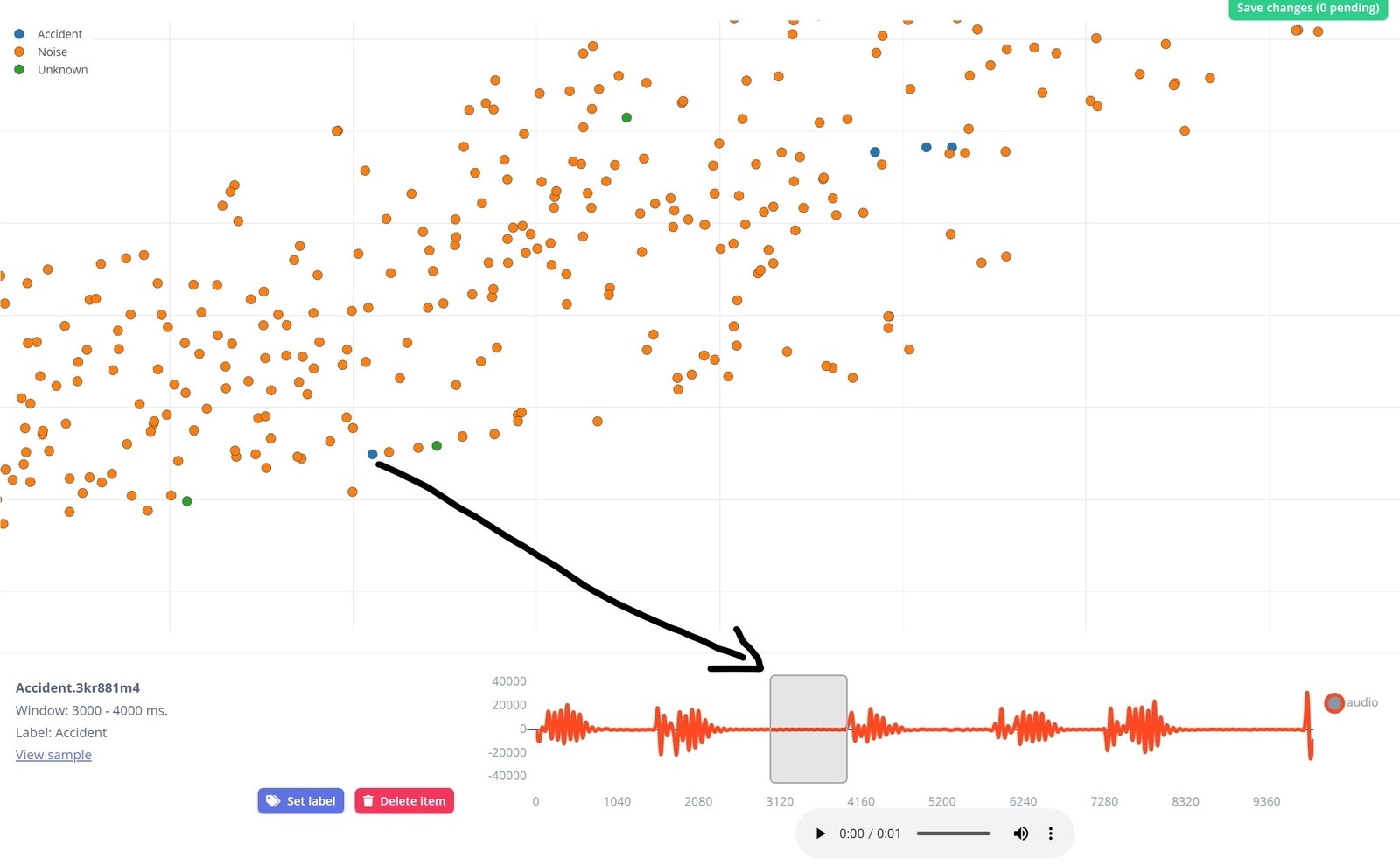
With the Edge Impulse Data explorer, you can represent your dataset visually, detect outliers, and label unlabeled data. This gives us a quick overview of our complete dataset. To learn more about the Data explorer, you can review the documentation here. This is our dataset visualization that was generated using the Data explorer.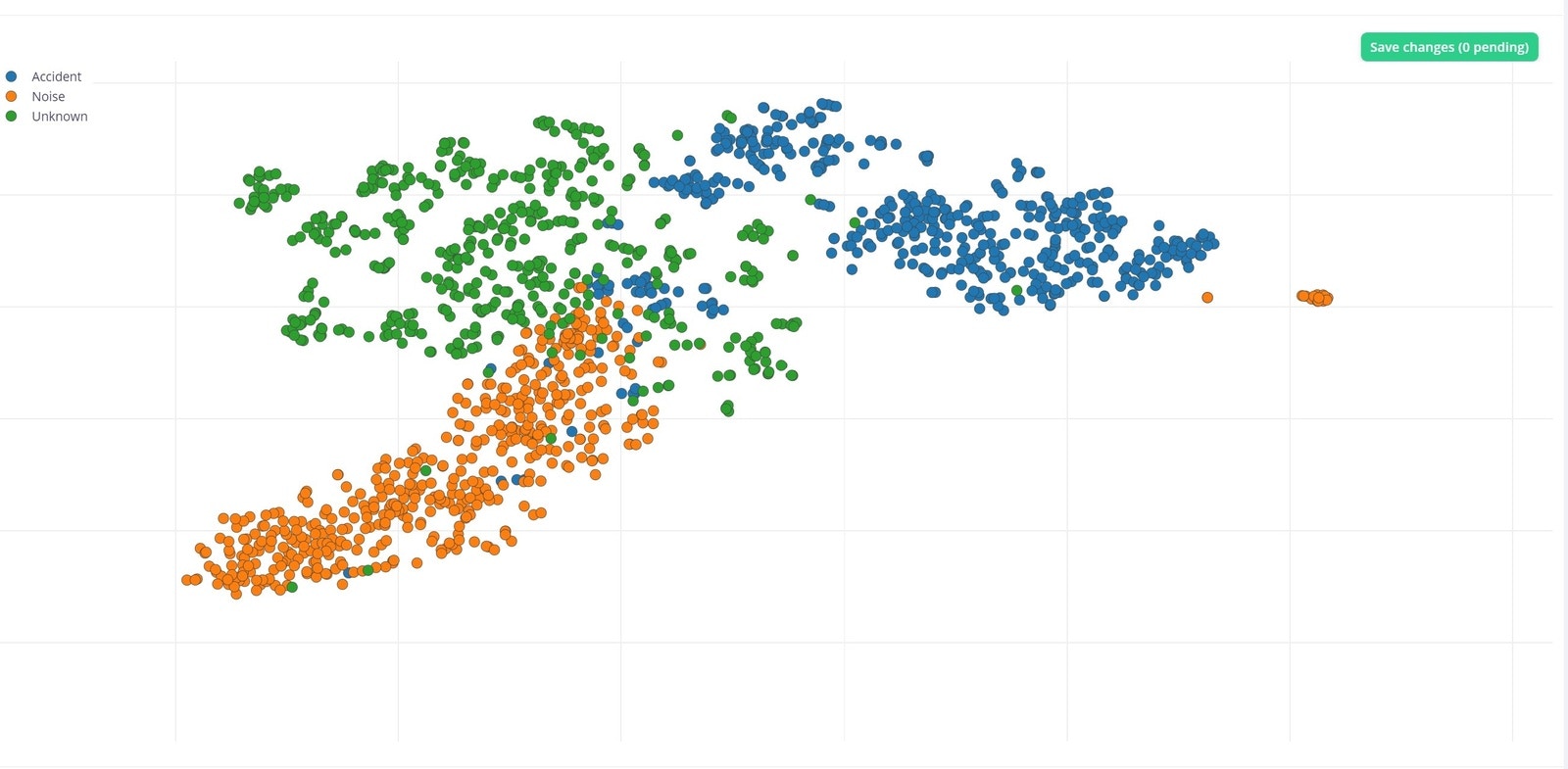
Impulse Design
Now it is time to create an Impulse, which is the machine learning pipeline built by Edge Impulse.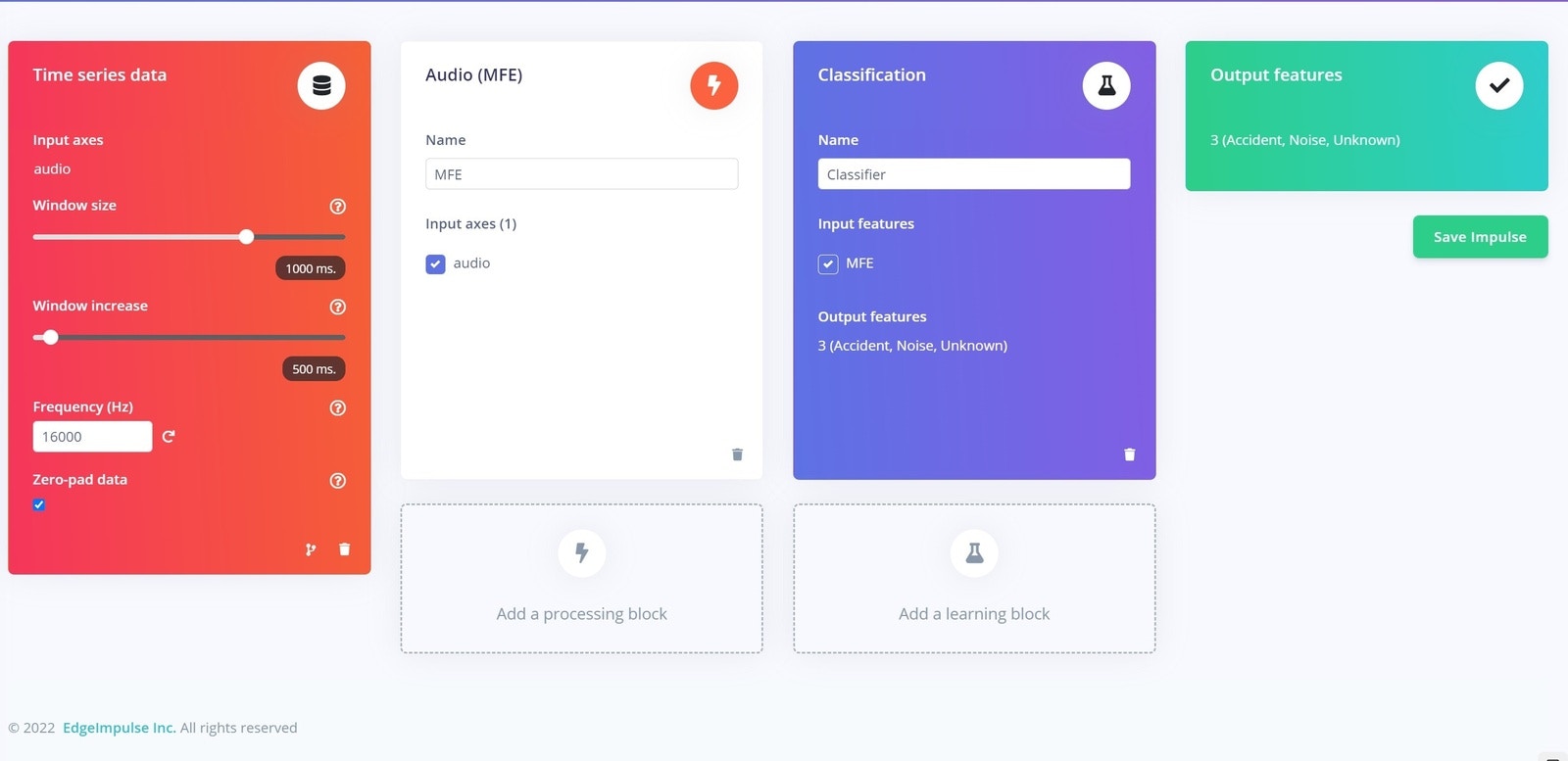
Neural Network
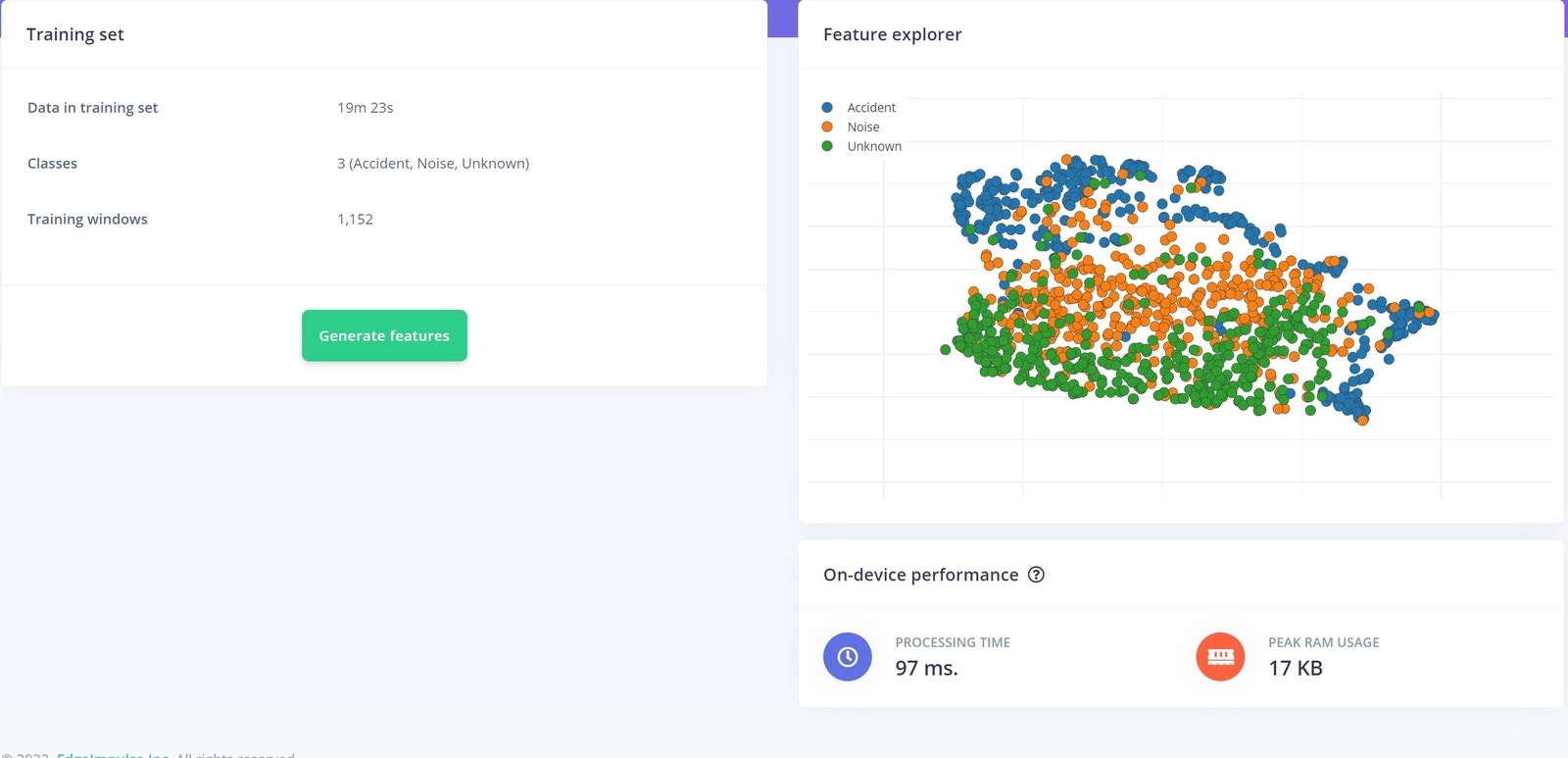
To build our neural network, we simply start by clicking Classifier on the left. The Neural Network default settings might work ok, but you can fine tune them if you need to. More information on the settings can be found in the documentation located here. Here are our neural network settings and architecture, which work very well for our data.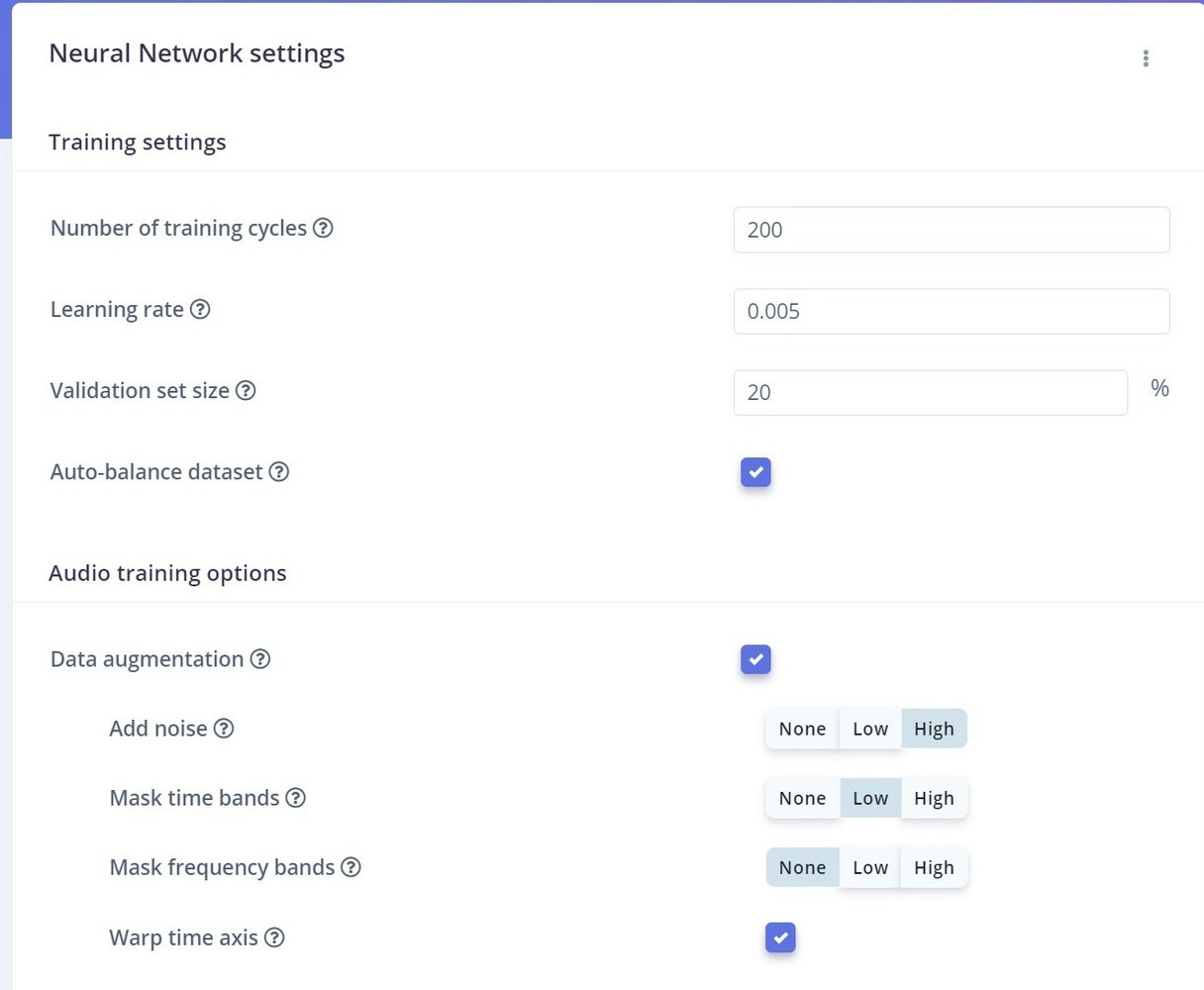
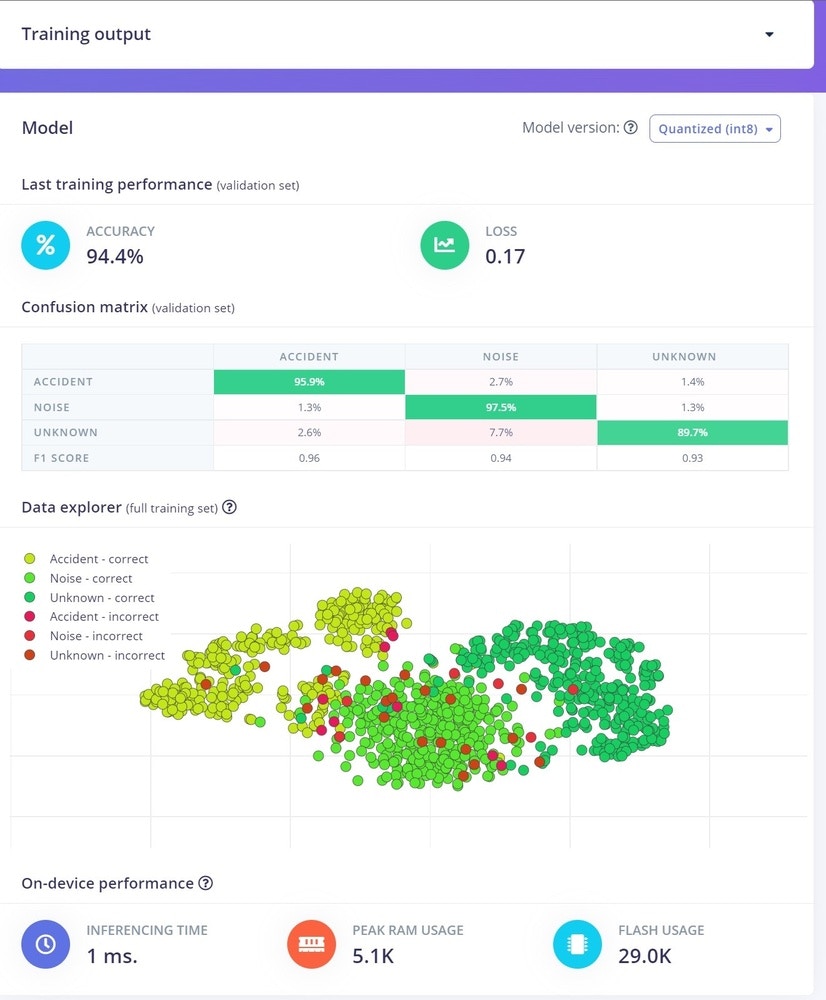
Classifying New Data
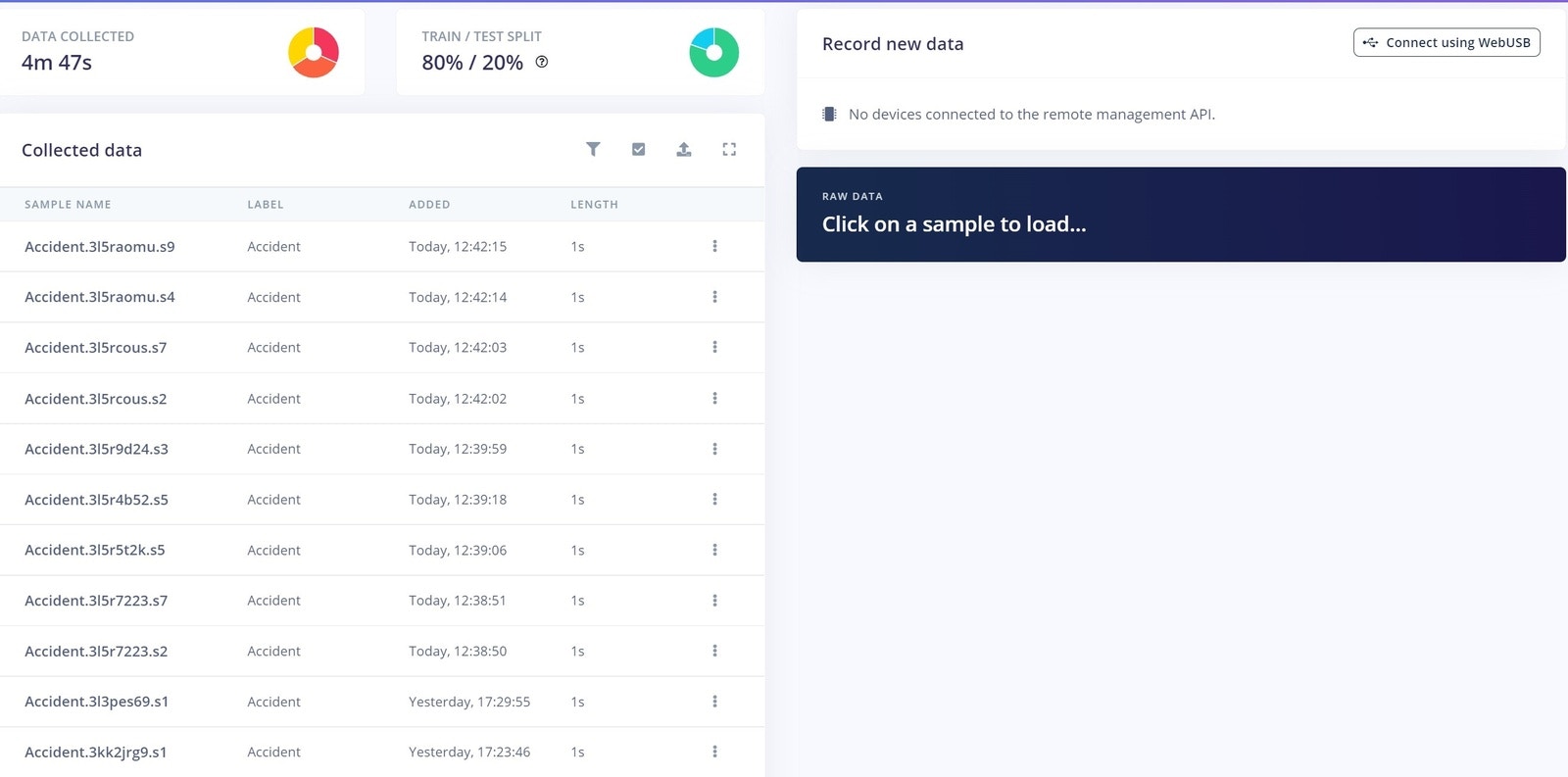
The next step in the process is to test the model on some new, unseen data before deploying it in the real world. When we collected data, we set aside that 4 minutes and 47 seconds of data for Testing, which was not used in the creation and training of the model. Now it can be used for Testing, by simply clicking on Model Testing on the left.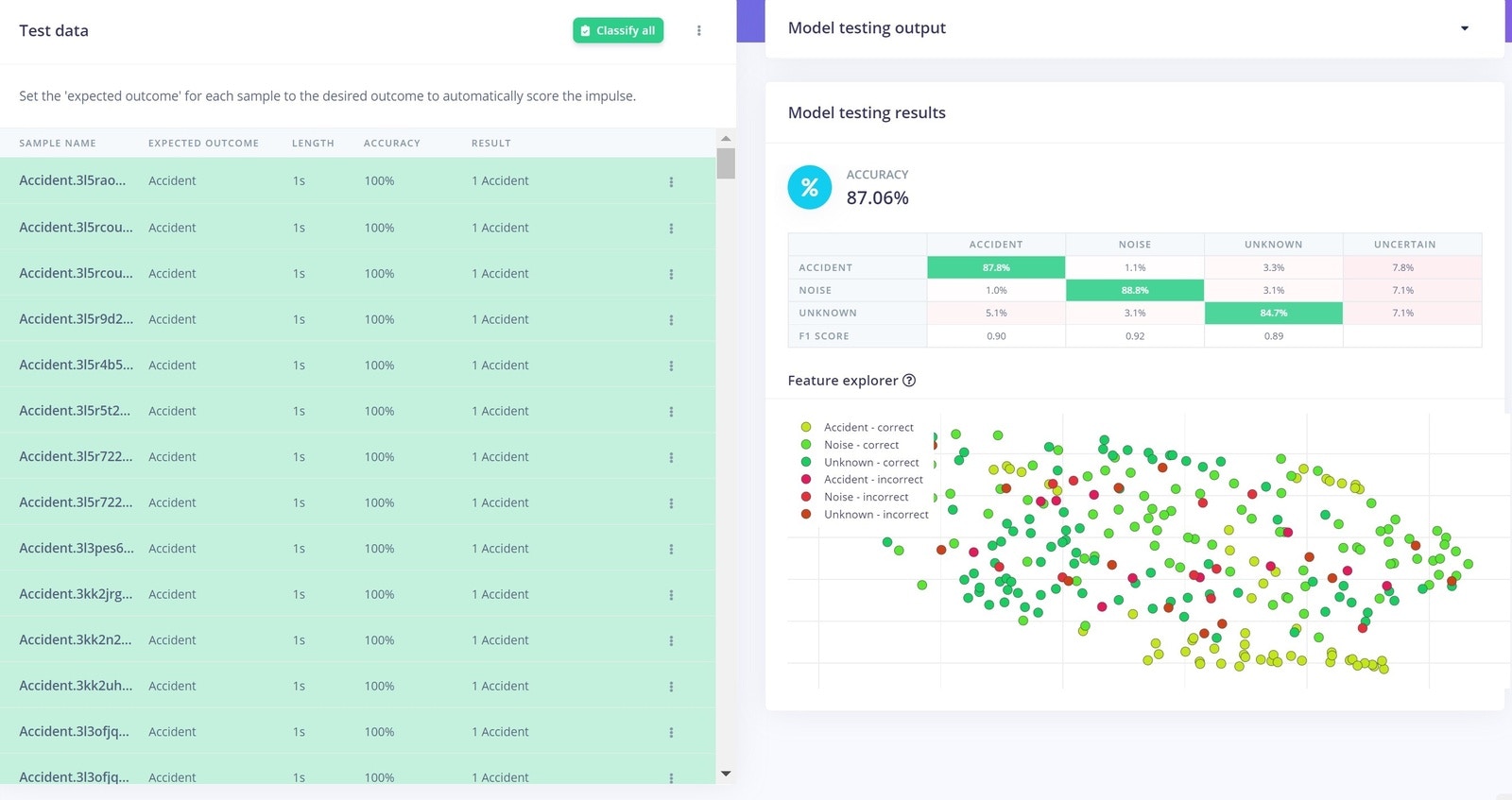
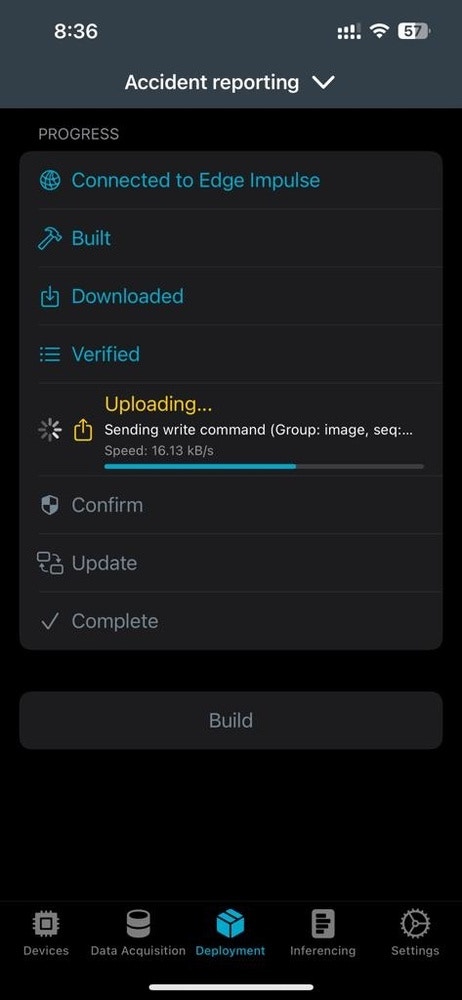
Deployment
To deploy our model onto the device, back in the mobile App you can simply go to the Deployment tab and click on the Build option. The App will start building our project, and then deploy the firmware directly to our Thingy:53 upon completion.