
Introduction
Building an accurate and high-quality object detection model can be tricky since it requires a large dataset. Sometimes, data can be hard to acquire, or not diverse enough to train a robust model. Synthetic data offers an alternative to generating well-represented datasets to build a quality model. By applying domain randomization, we developed photorealistic datasets, trained a neural network, and validated the model using real-world data. To create a diverse dataset, we created a variety of simulated environments with randomized properties: changing lighting conditions, camera position, and material textures. We also show that synthetic, randomized datasets can help generalize a model to adapt to the real-world environment.Story
We wanted to replicate the object detection work done by Louis Moreau, but this time using synthetic data rather than real data. The project aims to demonstrate how to build and deploy an Edge Impulse object detection model using synthetic datasets generated by Nvidia Omniverse Replicator. The Replicator is an Nvidia Omniverse extension that provides a means of generating physically accurate synthetic data.Why Synthetic Data?
Computer vision tasks such as classification, object detection, and segmentation require a large-scale dataset. Data collected from some real-world applications tend to be narrow and less diverse, often collected from a single environment, and sometimes data is unchanged and stays the same. In addition, data collected from a single field tends to have fewer examples of tail-end scenarios and rare events, and we cannot easily replicate these situations in the real world.
Andrej Karpathy's presentation - (source: Tesla AI Day, 2021)
The purpose of domain randomization is to provide enough simulated variability at training time such that at test time the model is able to generalize to real-world data.” - Tobin et al, Domain Randomization for Transferring Deep Neural Networks from Simulation to the Real World, 2017

Domain Randomization for Transferring Deep Neural Networks - source: Tobin et al, 2017)
Data-Centric Workflow
Traditional machine learning workflow is often model-centric, focusing more on the model’s development by iteratively improving the algorithm design, etc. In this project, we chose the Data-centric approach, where we fixed the model and iteratively improved the quality of the generated dataset. This approach is more robust since we know our model is as good as the dataset. This method hence systematically changes the dataset performance on an AI task. At its core, it is thinking about ML in terms of data, not the model.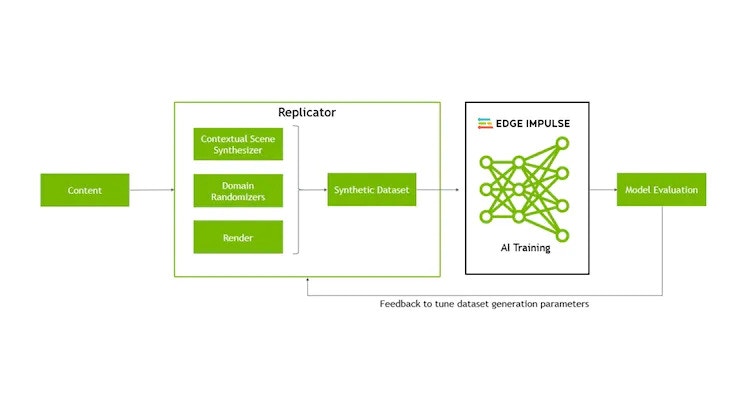
Data generation and model building workflow
Requirements
- Nvidia Omniverse Replicator
- Edge Impulse Studio
- USB Webcam (Logitech C920 is used in this project, but any camera attached and detected by the Edge Impulse CLI will work)
Hardware and Driver Setup
Nvidia Omniverse Replicator is a computation-intensive application requiring a moderate-size GPU and decent RAM. My hardware setup consists of 32GB RAM, 1TB storage space and an 8GB GPU with an Intel i9 processor.
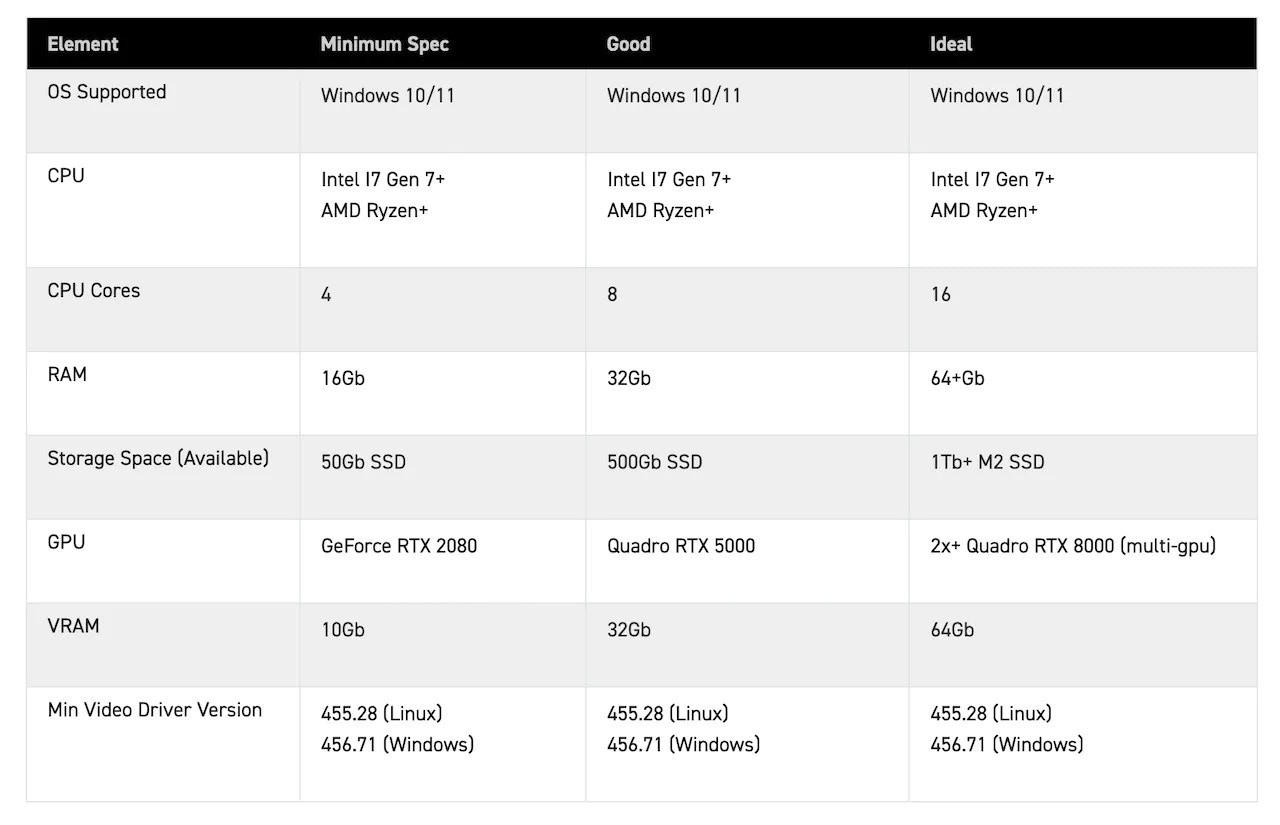
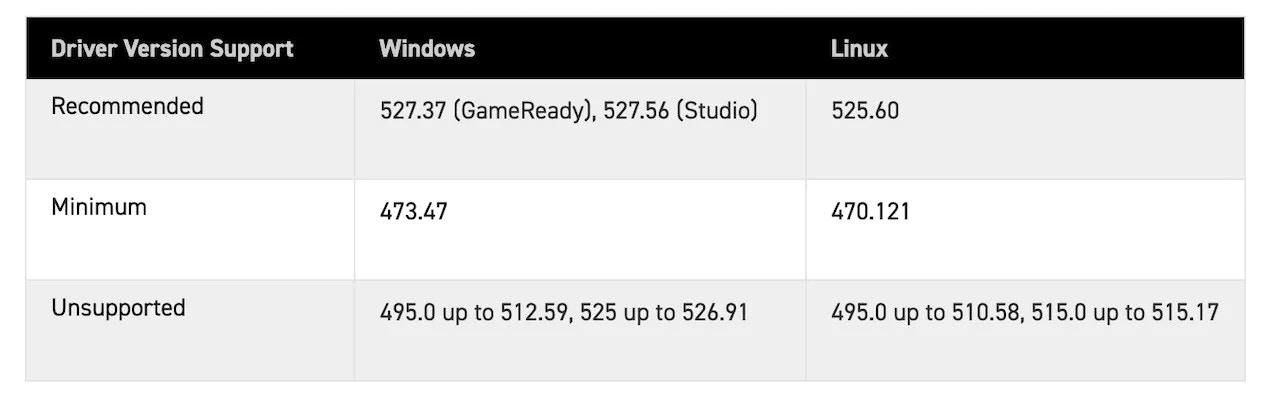
Experiment Setup and Data Generation
The environment for the experiment consists of movable and immovable objects (dynamic and static positioning objects). The immovable object consists of Lights, a Table and two Cameras. The movable objects are the cutlery, which is a spoon, fork and knife. We will use domain randomization to alter the properties of some of the movable and immovable objects. Assets which include objects and scenes are represented in the Replicator as USD.
.obj, .fbx, and .glif can be imported into the Replicator using Nvidia Omniverse’s CAD Importer extension. The extension converts the 3D files into USD. We imported our assets (table, knife, spoon, and fork) into the simulator by specifying the path of the assets.
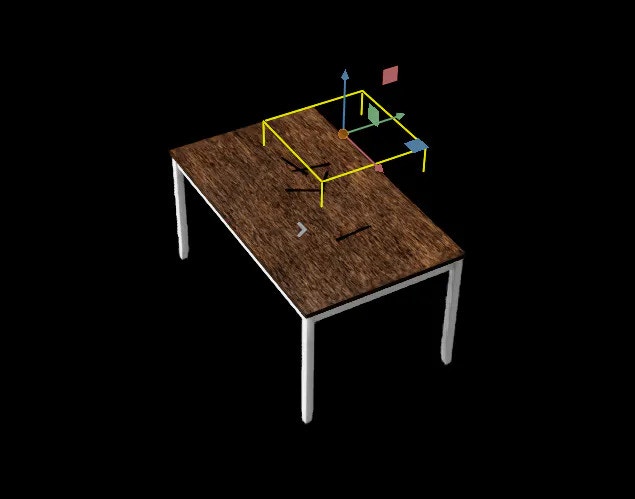

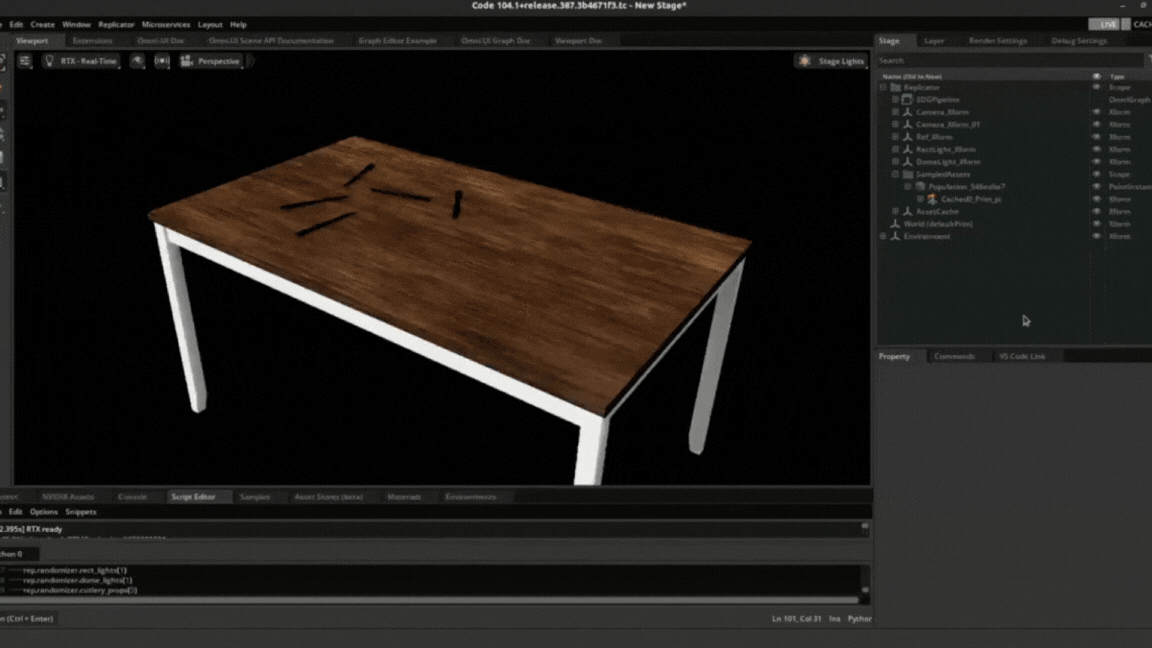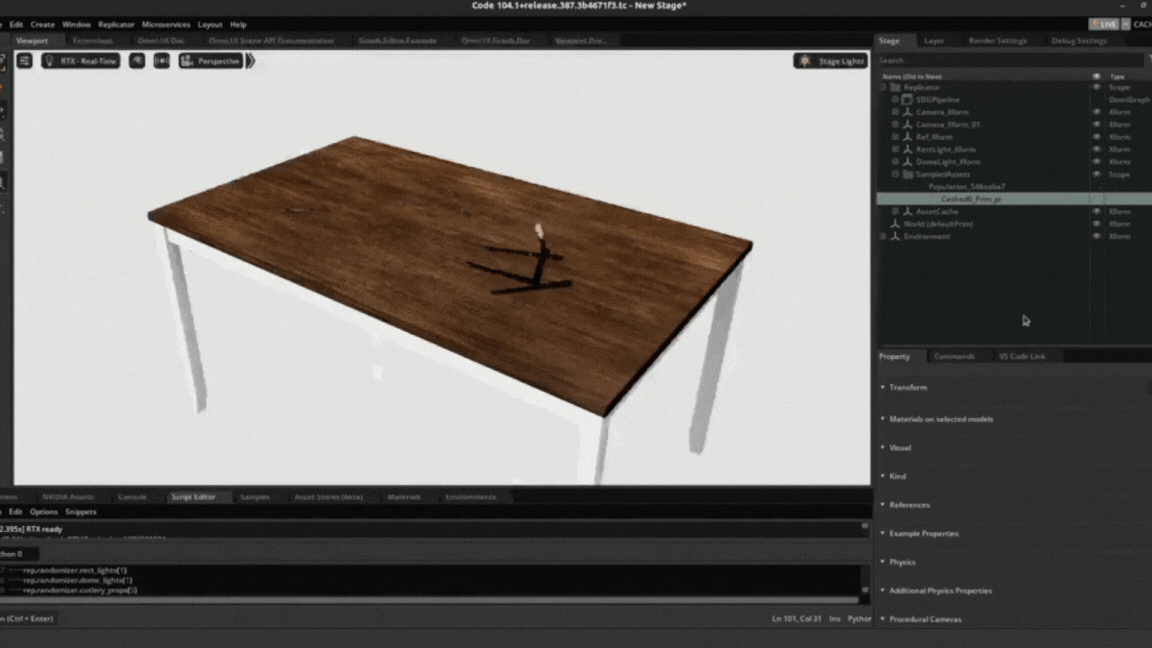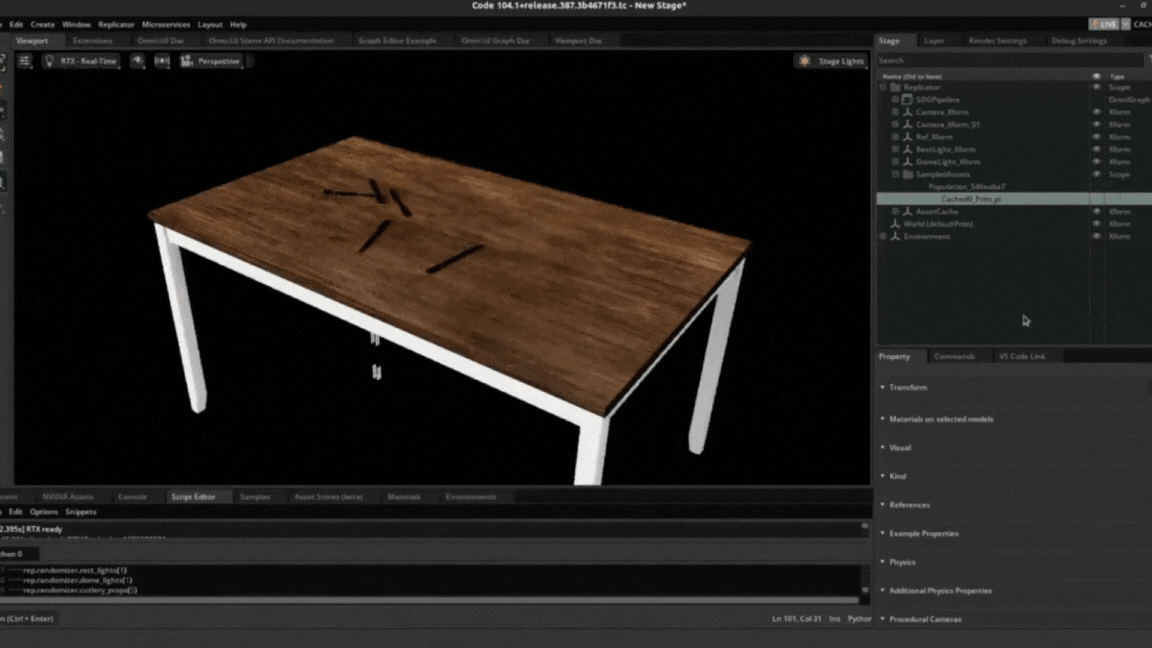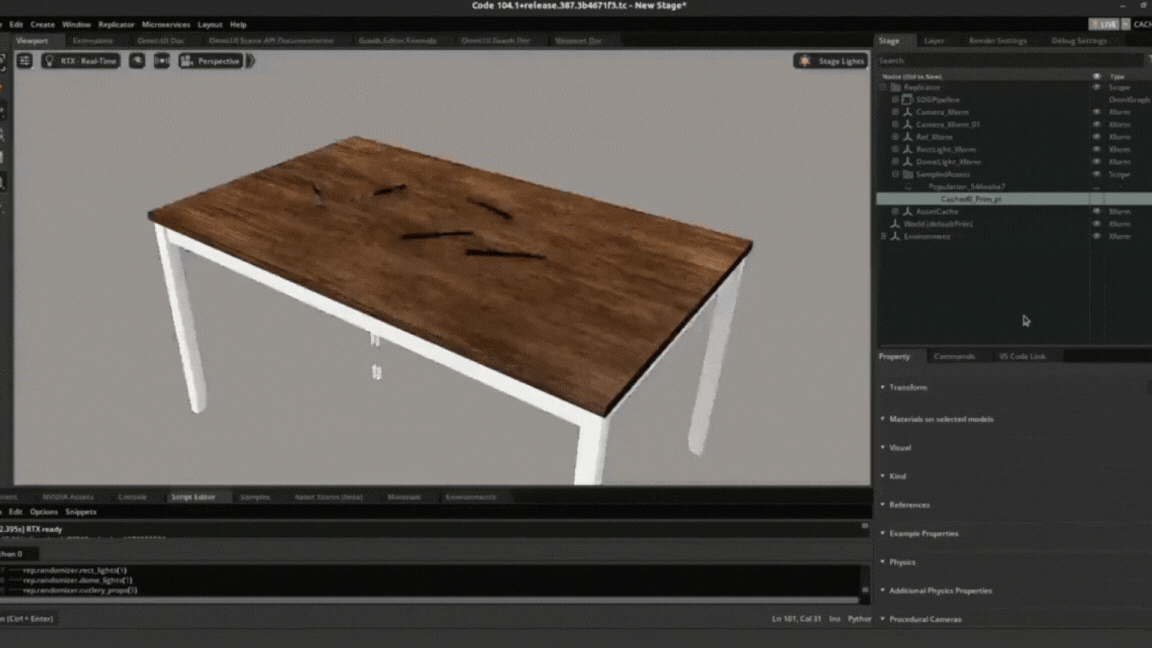
Data generation process
Data Distribution and Model Building
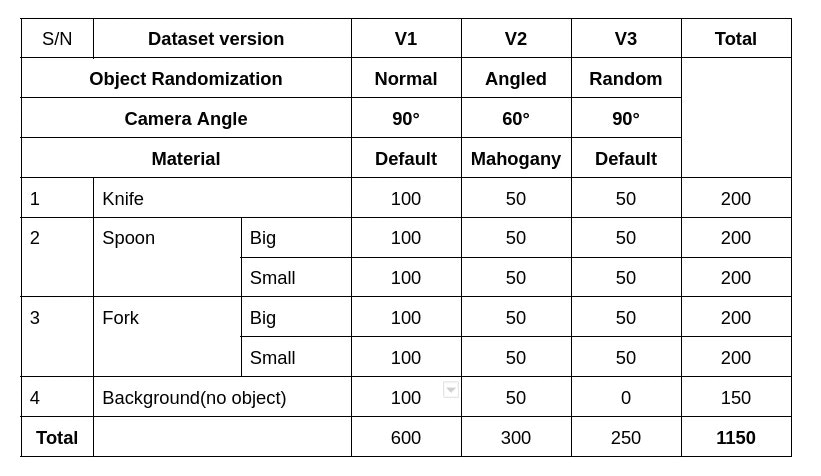
Data Distribution of different items

V1 - Normal to the object

V2 - Angled to the object

V3 - Normal to the object and object suspended in space
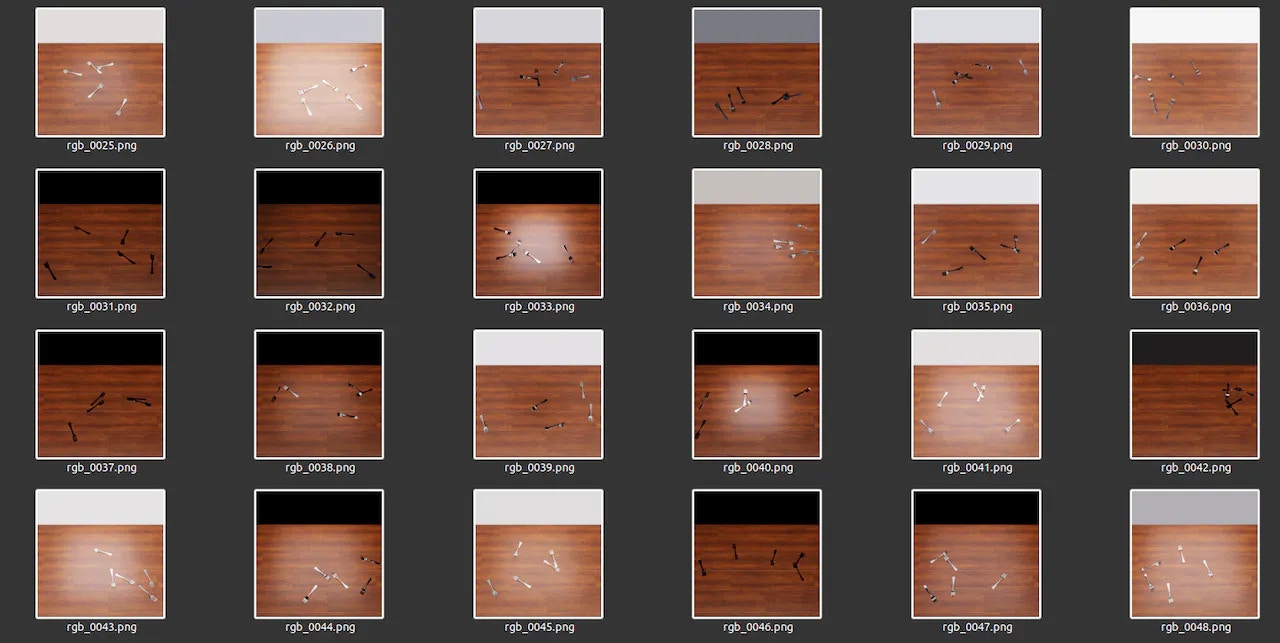
Generated Dataset - V3
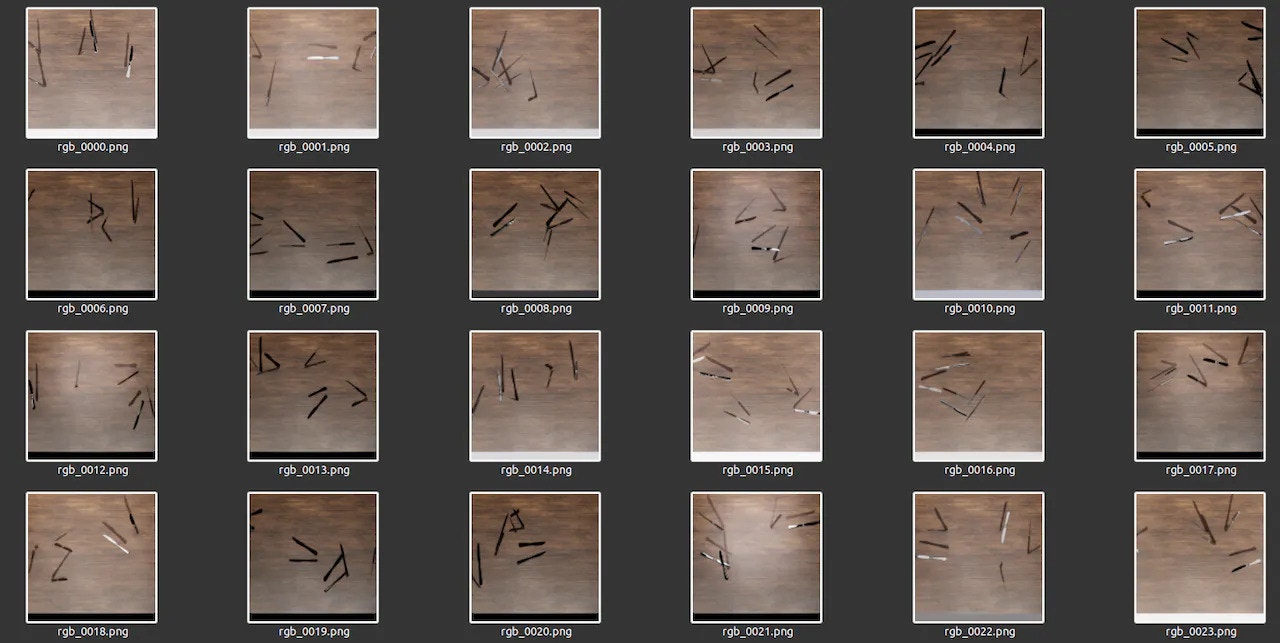
Generated Dataset - V3
Edge Impulse: Data Annotation and Model Building
| Data Labeler | Data Annotation |
|---|---|
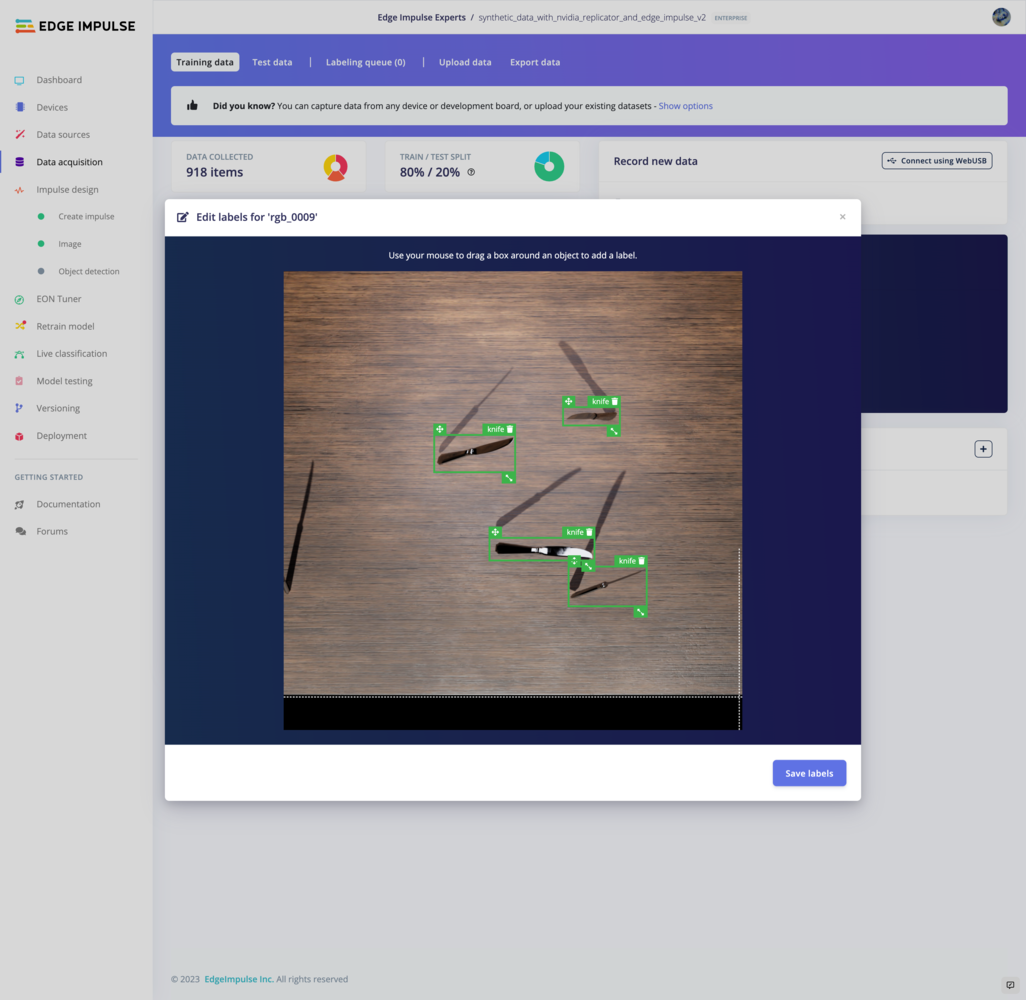 | 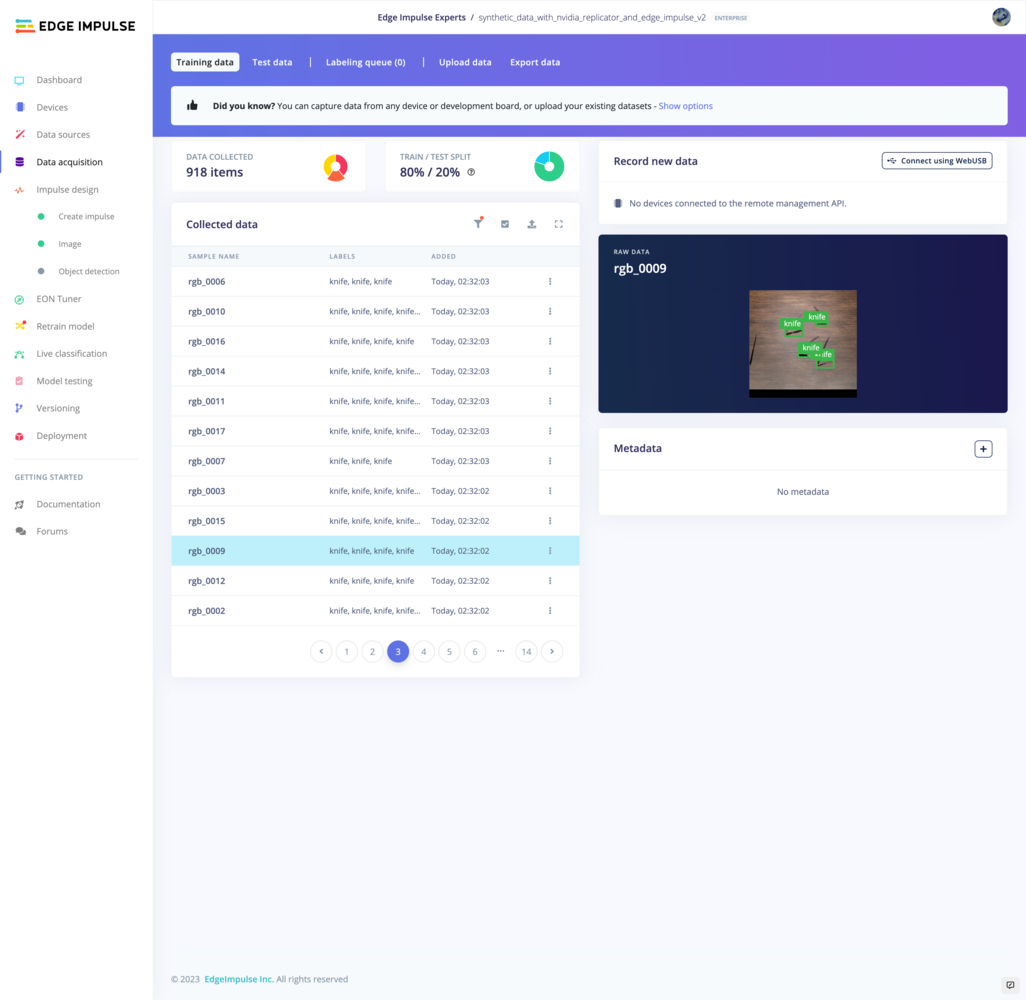 |
| Create Impulse | Generate Feature |
|---|---|
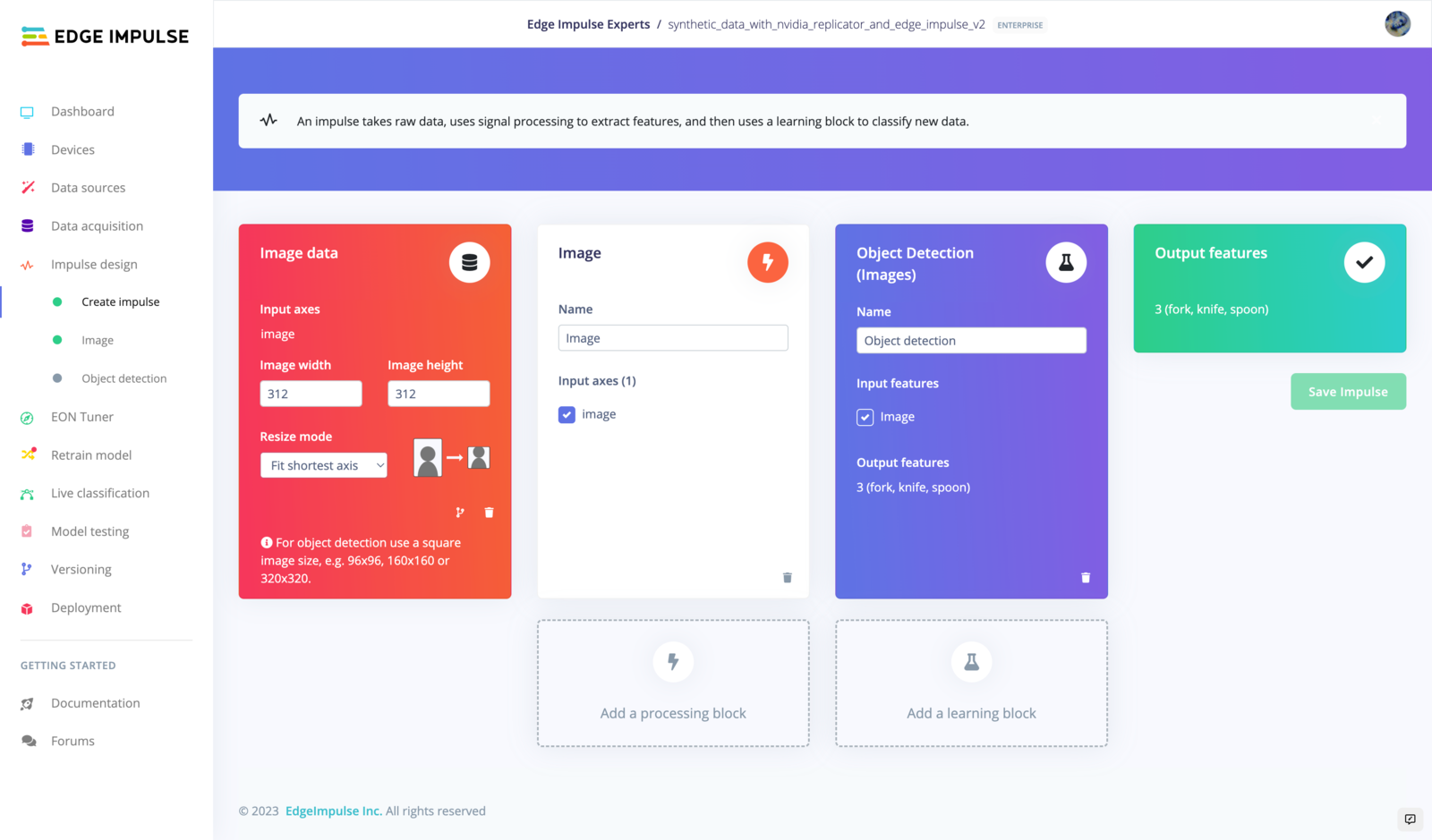 | 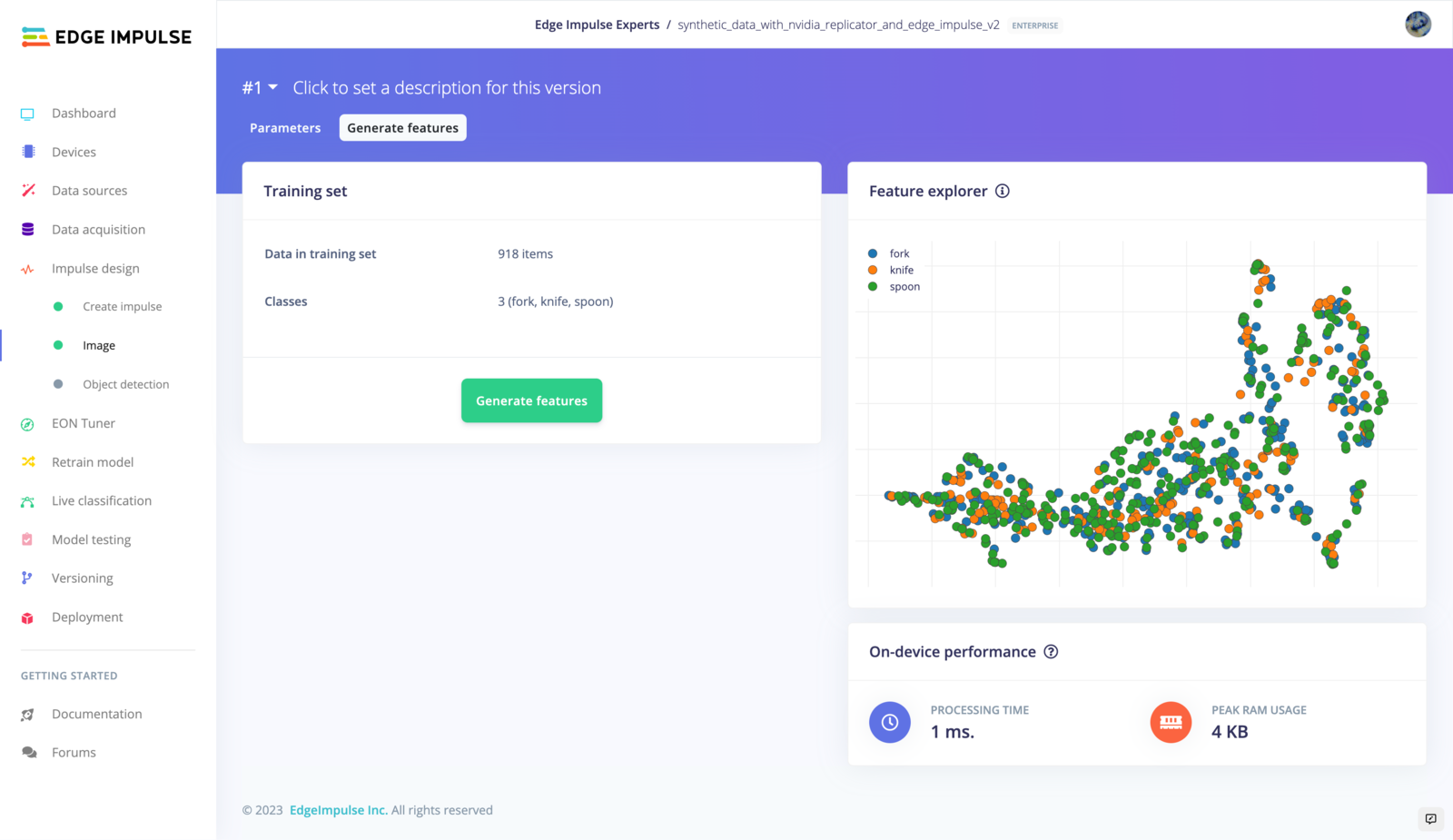 |
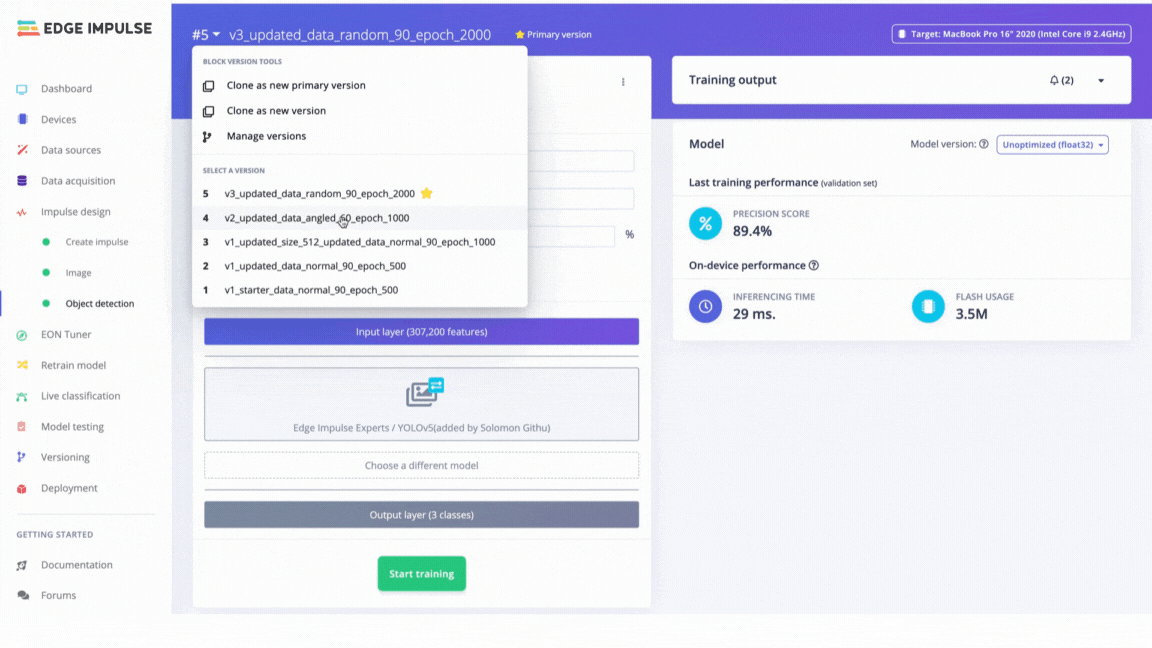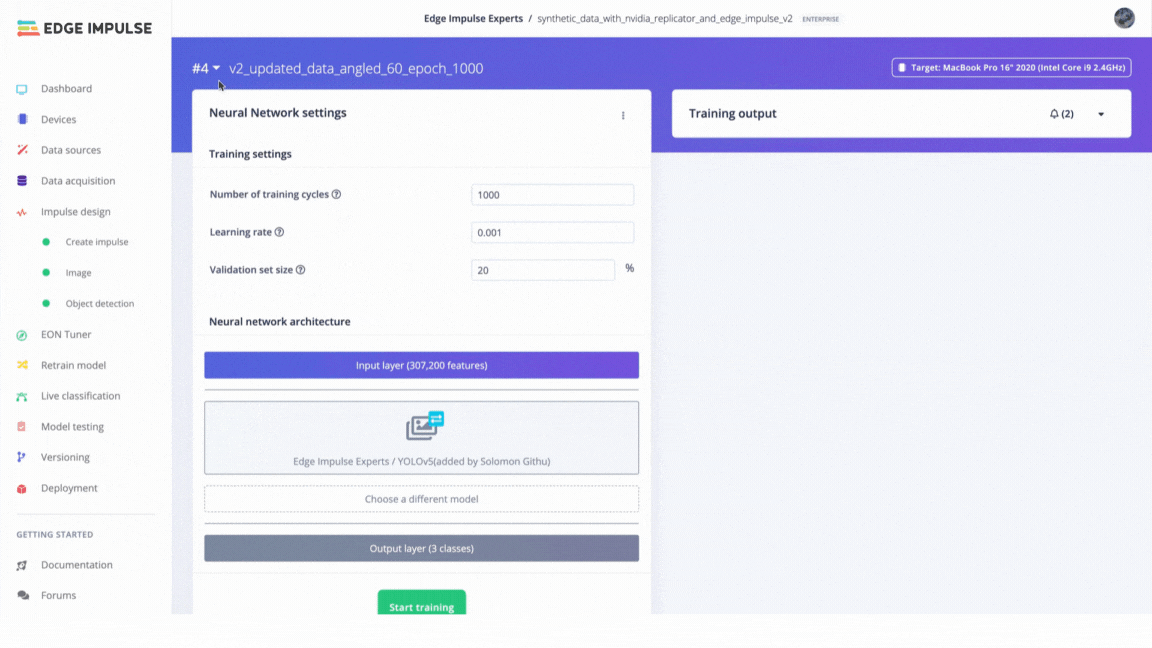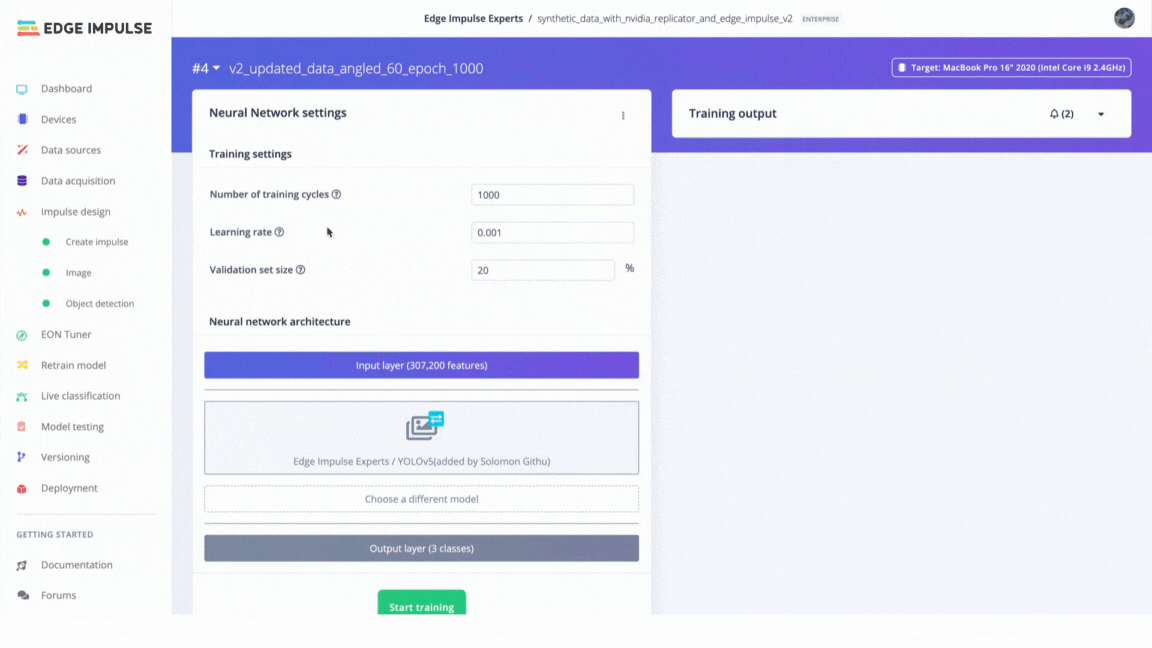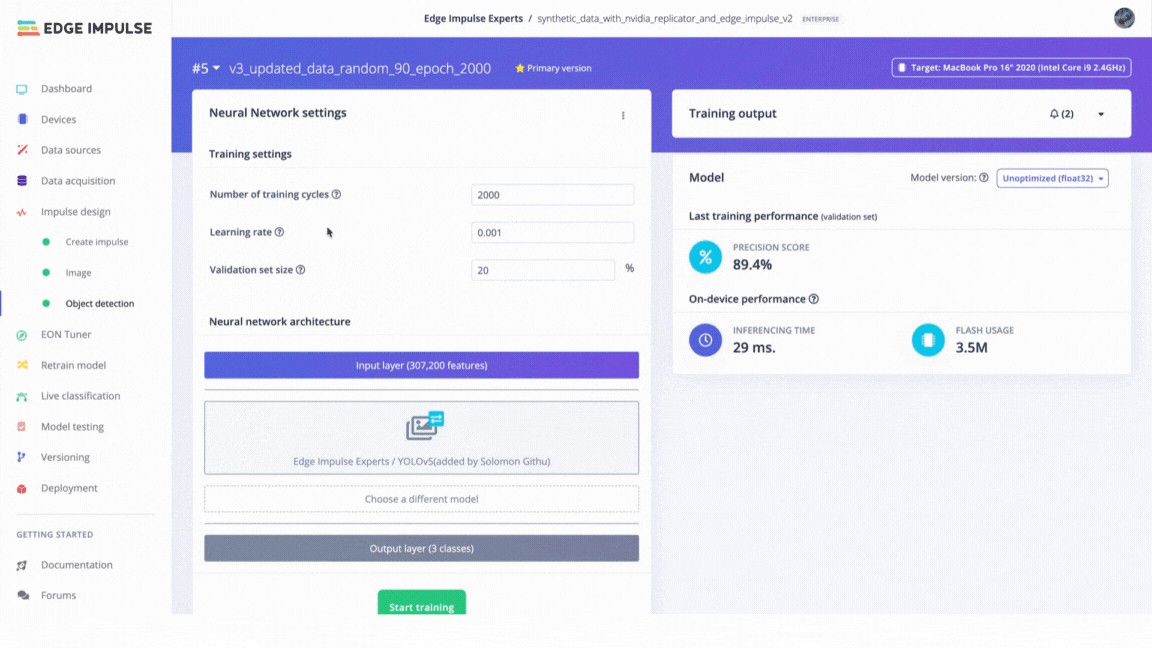
Version Control in Edge Impulse
Testing of Object Detection Models with Real Objects
We used the Edge Impulse CLI tool to evaluate the model’s accuracy by downloading, building and running the model locally. A Logitech C920 webcam streamed the live video of objects on a table from 50 cm to 80 cm from the camera. The position of the camera remains fixed during the experiment. The clips below show that the trained model does not generalize well to real-world objects. Thus we needed to improve the model by uploading, annotating and training the model with the V2 dataset.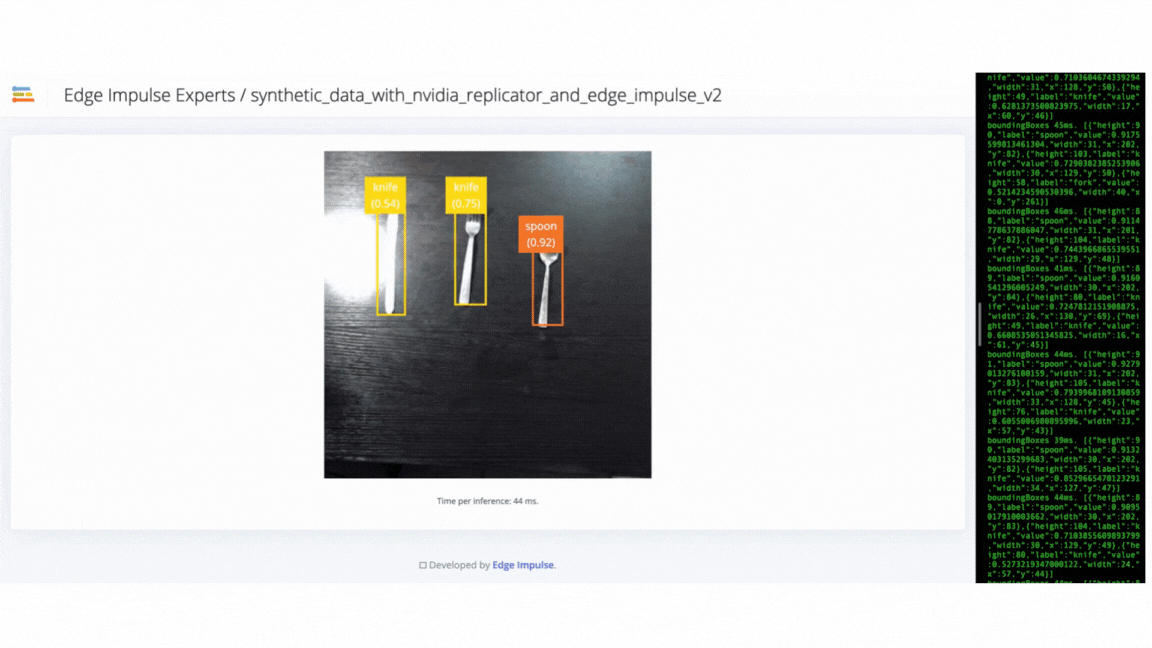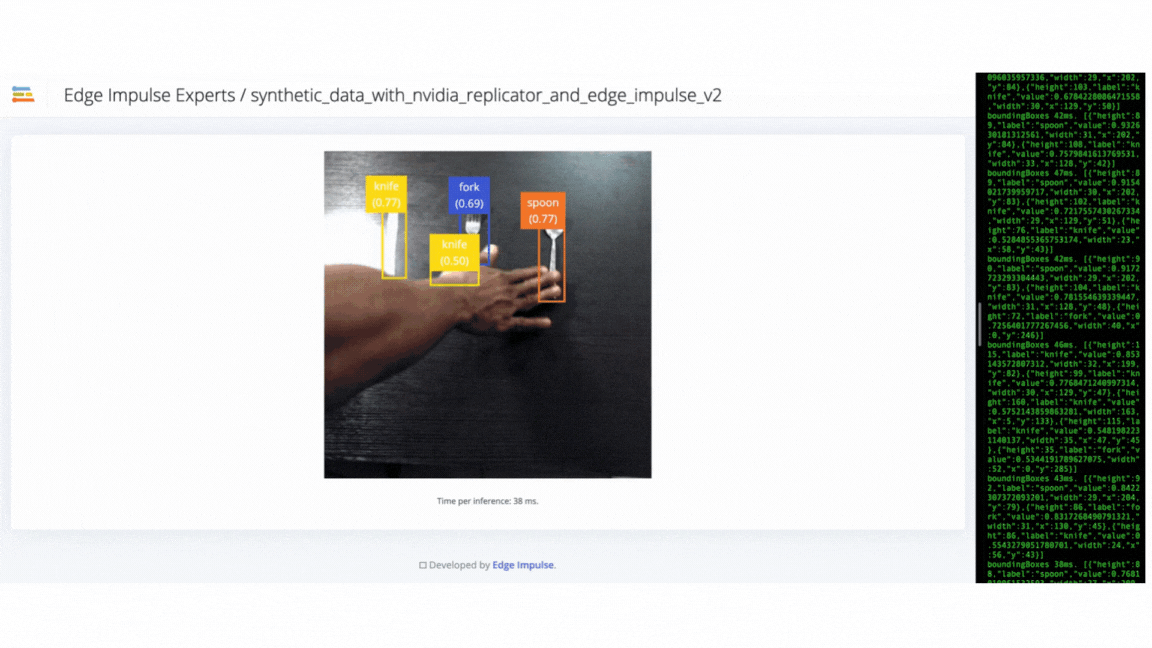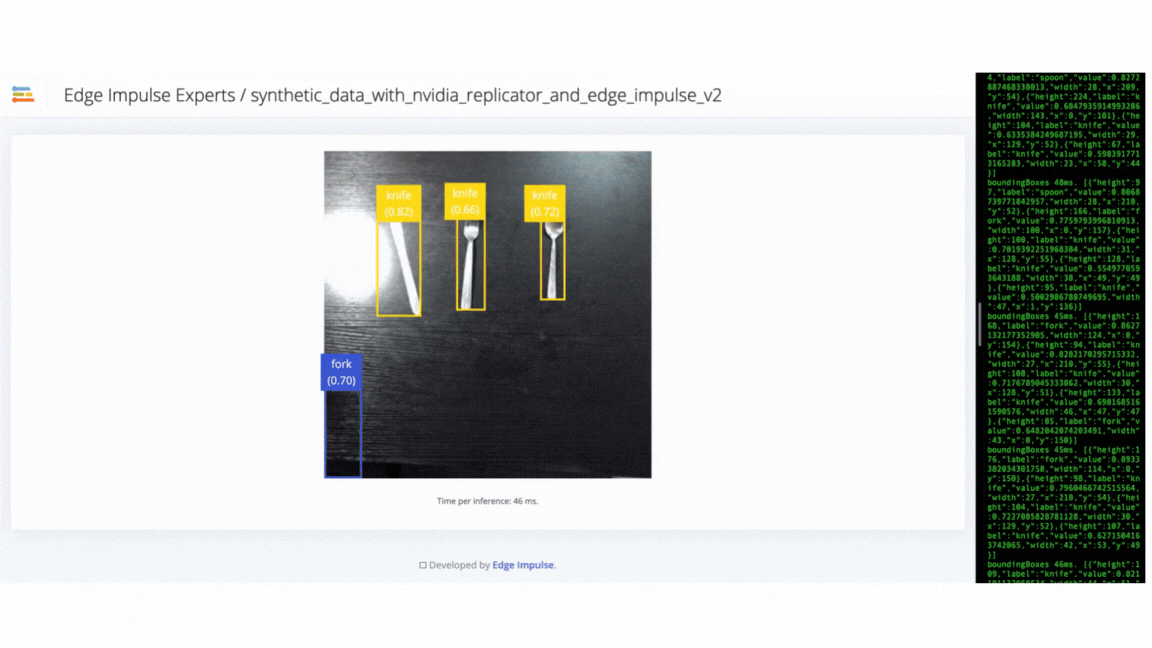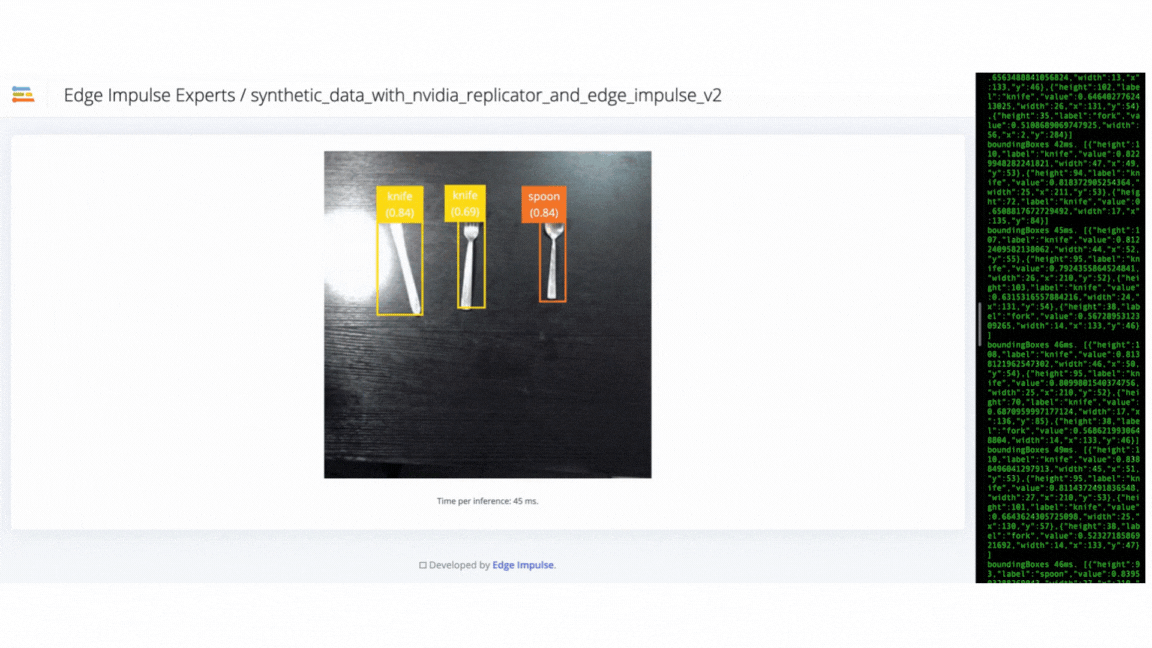
V1 failure - model failed to identify objects

V2 success - model can identify objects
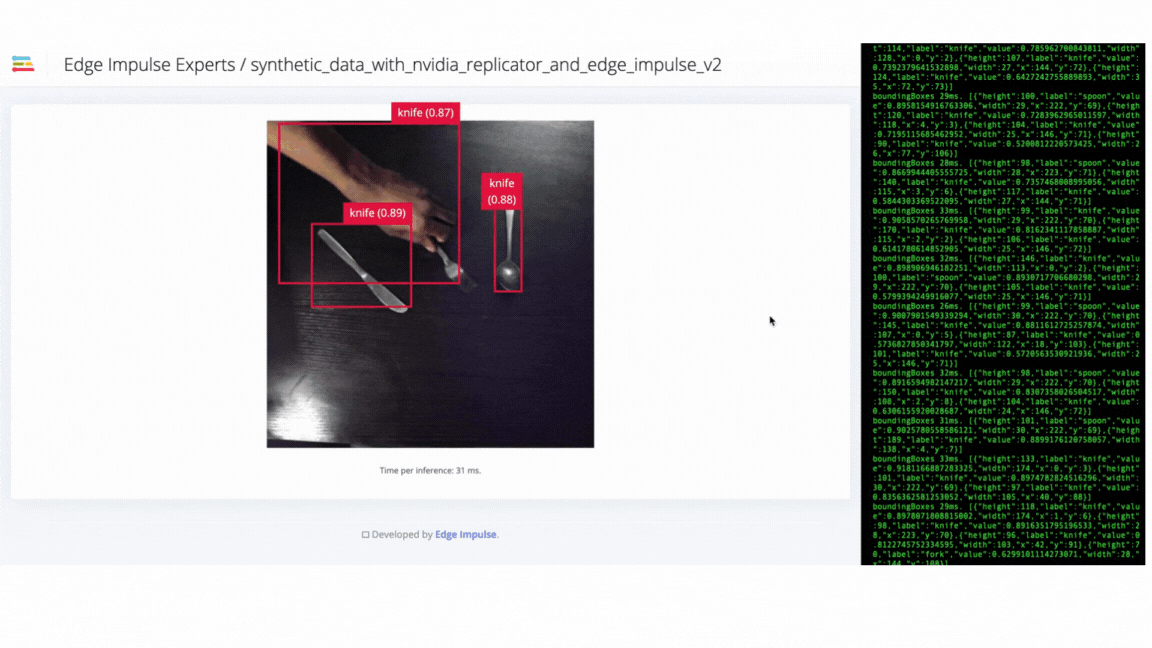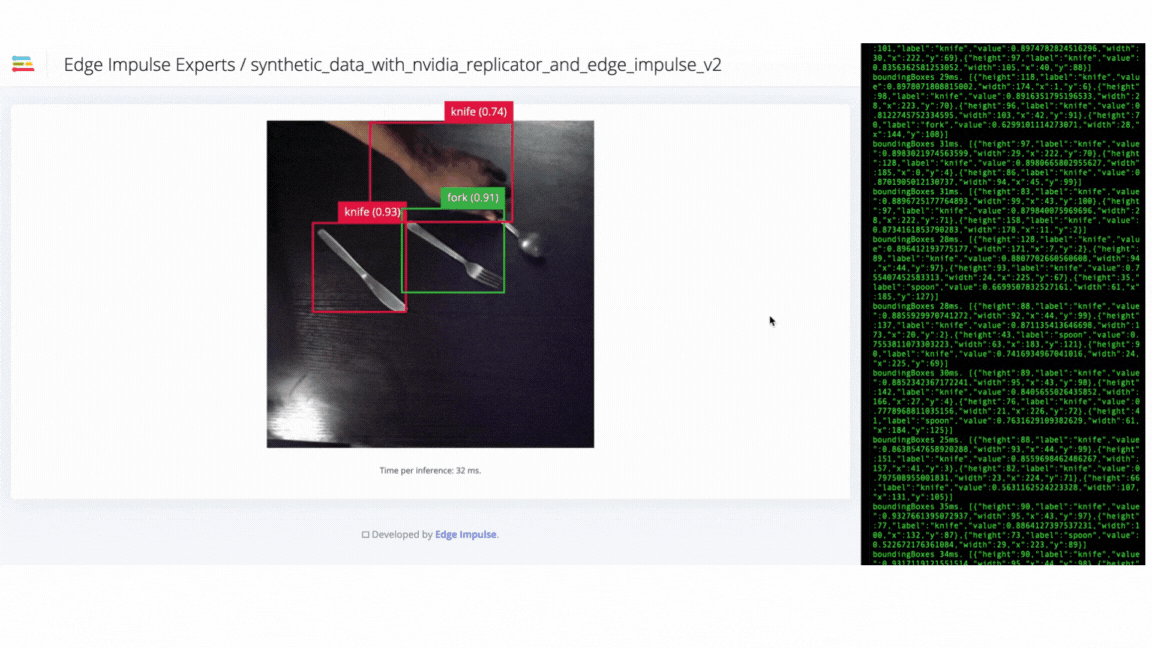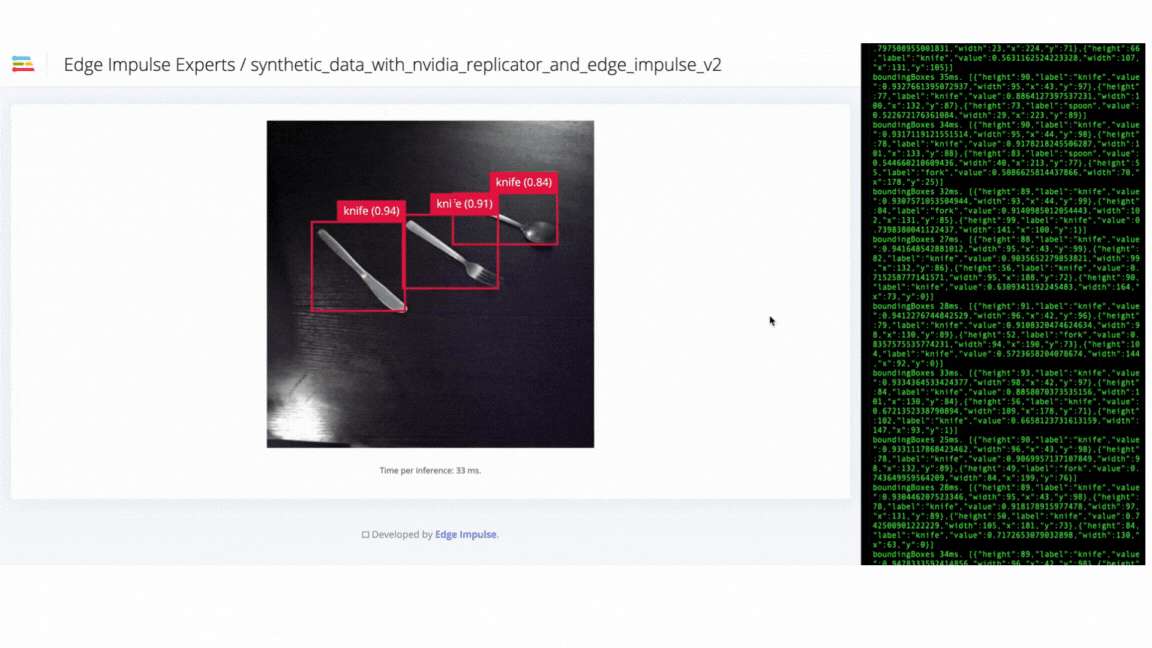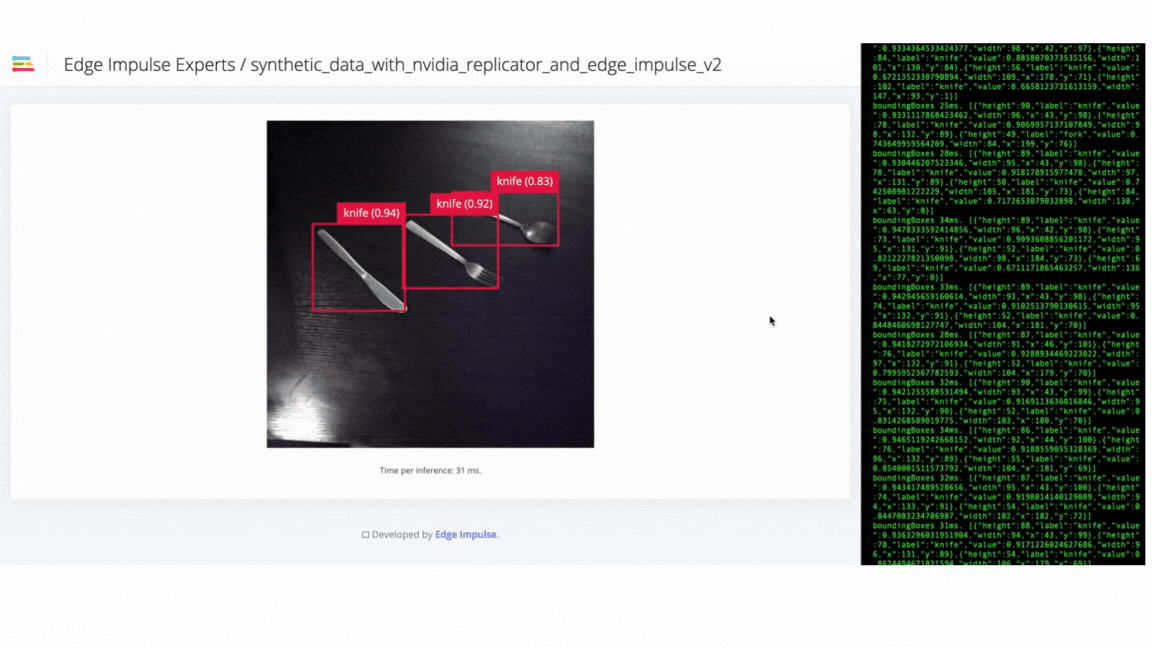
V2 failure - model failed to identify objects in different orientations
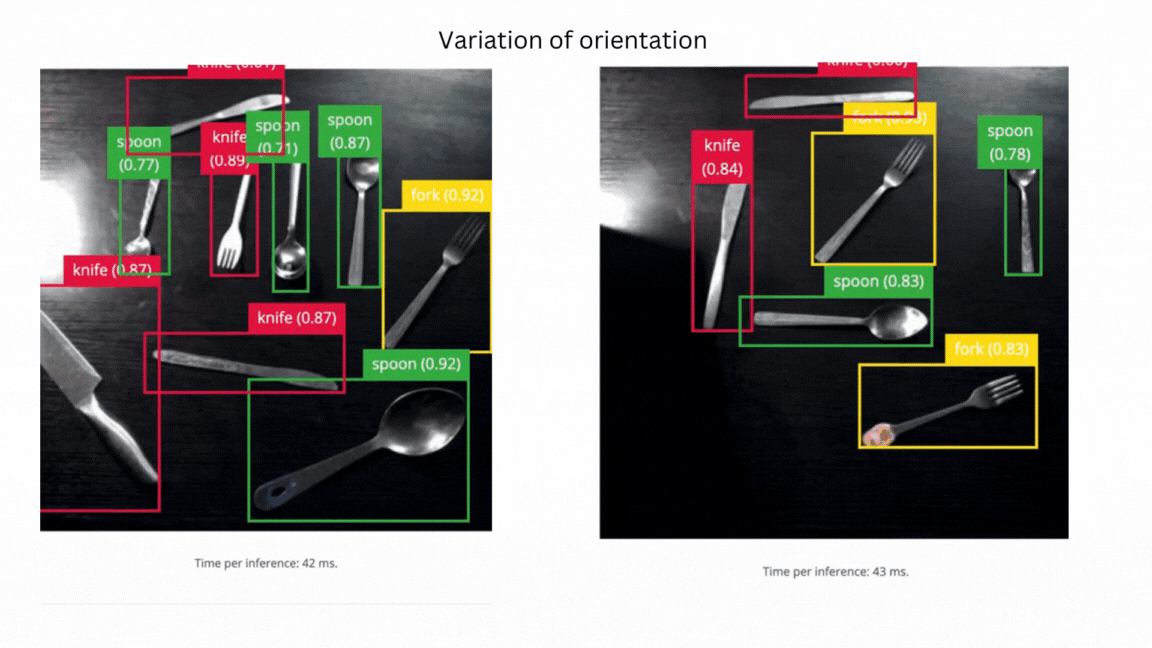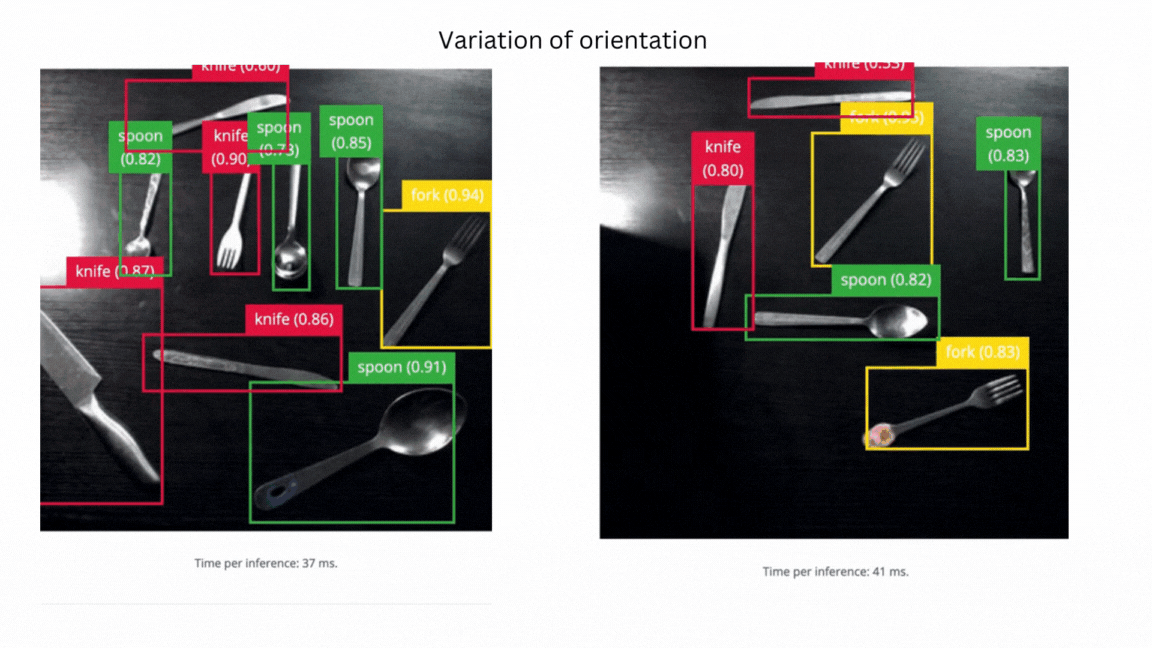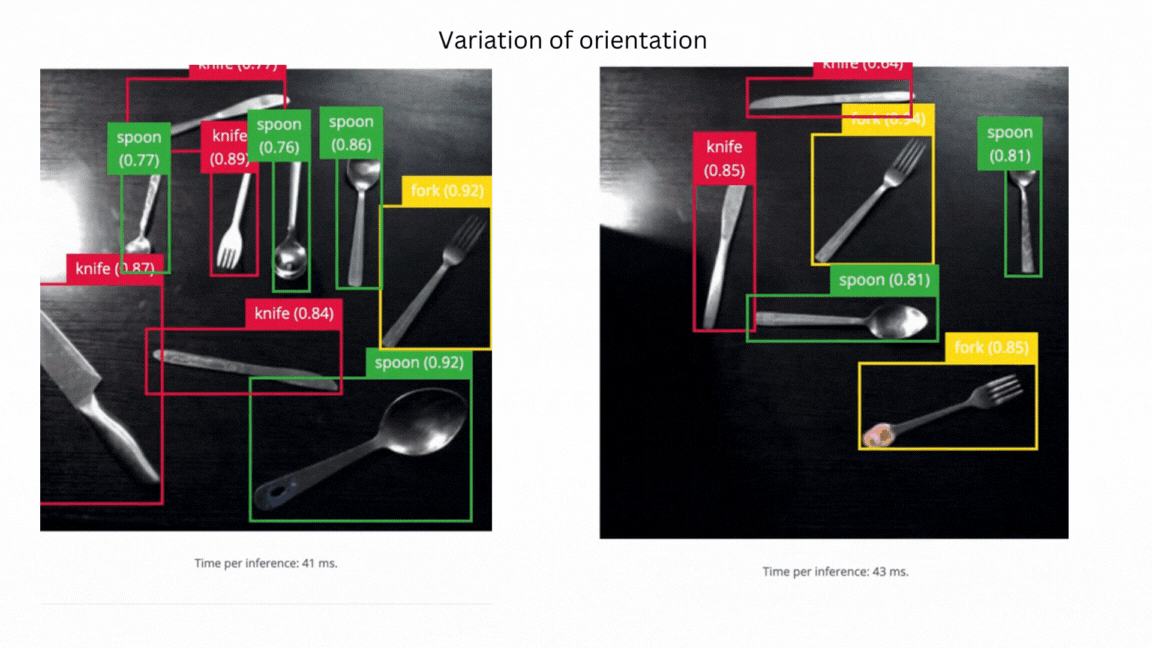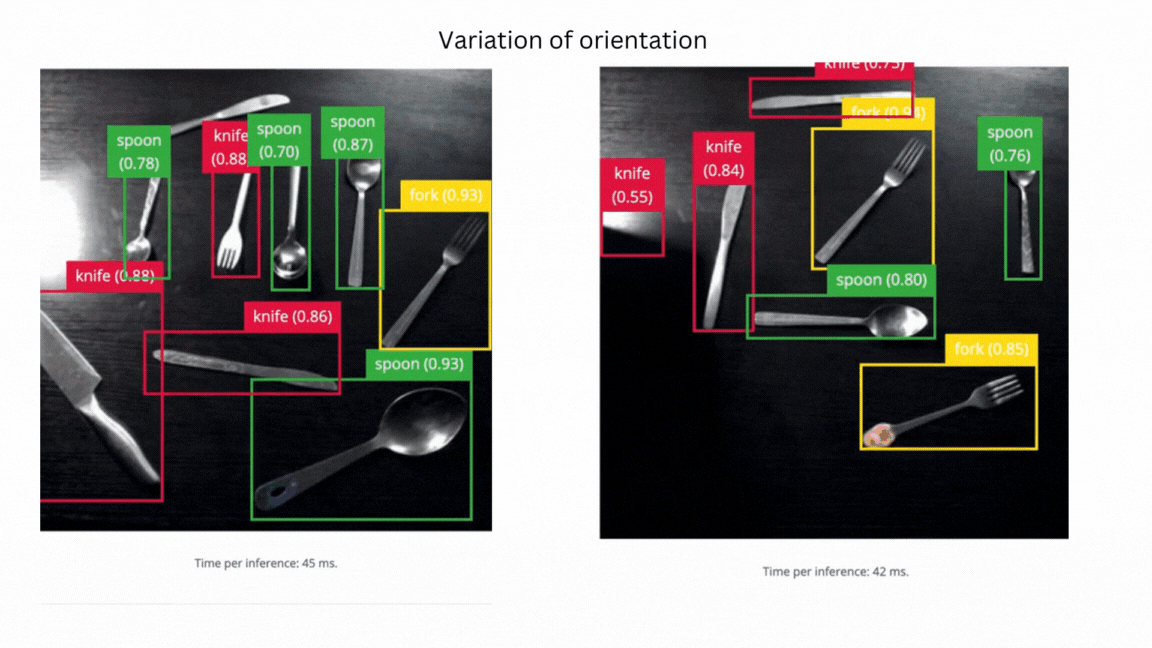
V3 success - model can identify objects in different orientations

V3 success - model can identify different materials
