This tutorial builds on the Camera Inference tutorial. You’ll add QNN hardware acceleration to leverage Qualcomm’s Hexagon NPU for significantly faster inference.
Reference code: https://github.com/edgeimpulse/qnn-hardware-acceleration
Reference code: https://github.com/edgeimpulse/qnn-hardware-acceleration
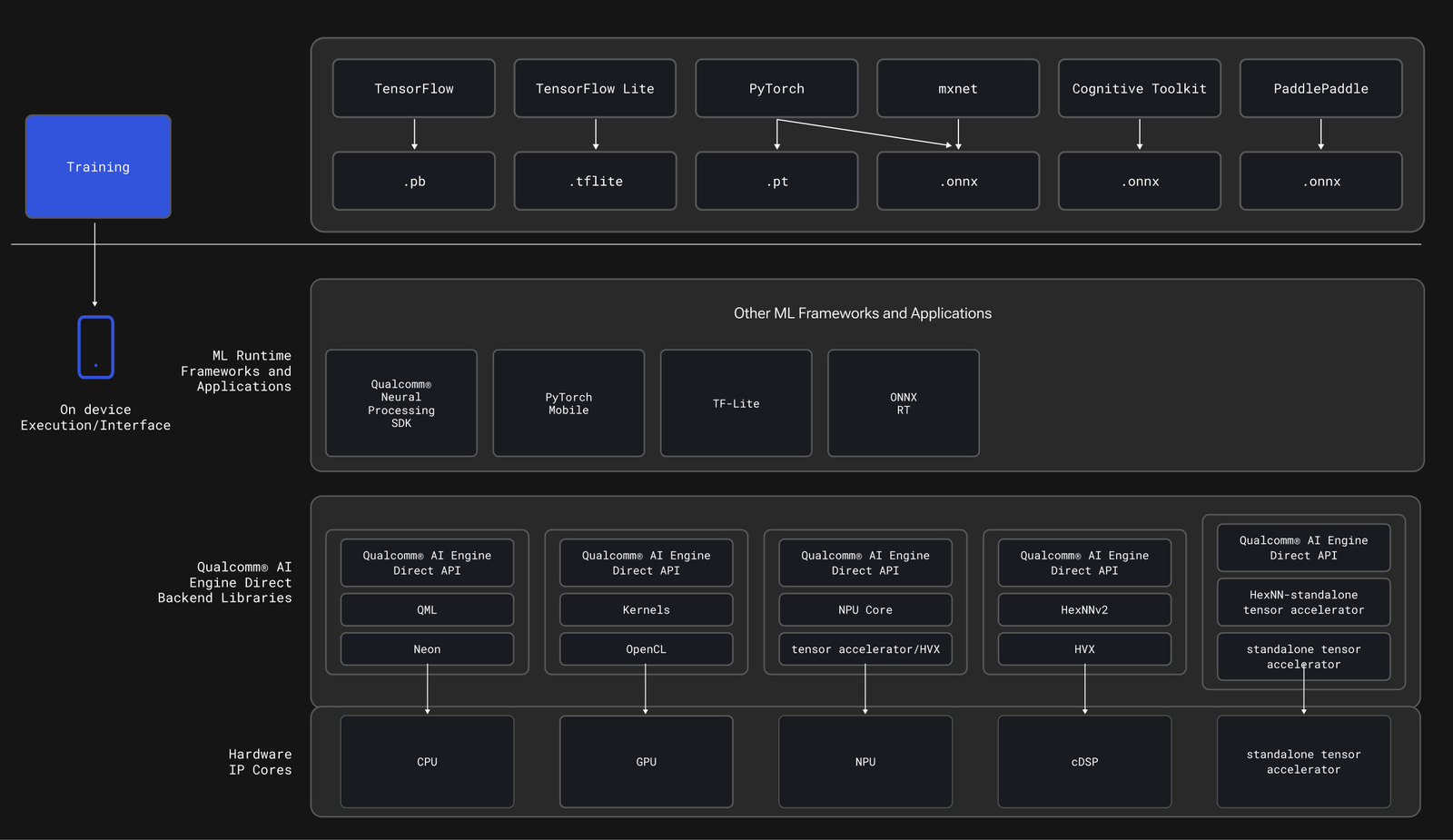
Where the QNN TFLite delegate fits in the Qualcomm AI Engine Direct stack
What you’ll build
An Android application that:- Runs Edge Impulse object detection models with Camera2 API
- Accelerates inference using Qualcomm’s HTP/DSP via QNN delegate
- Displays real-time bounding boxes with overlay
- Logs detailed performance metrics to Logcat
Performance expectations
Results from YOLOv5 small (480×480 quantized) on Qualcomm RB3 Gen 2 (6490):
Conservative gains:
- Before (CPU-only)
- After (QNN delegate)
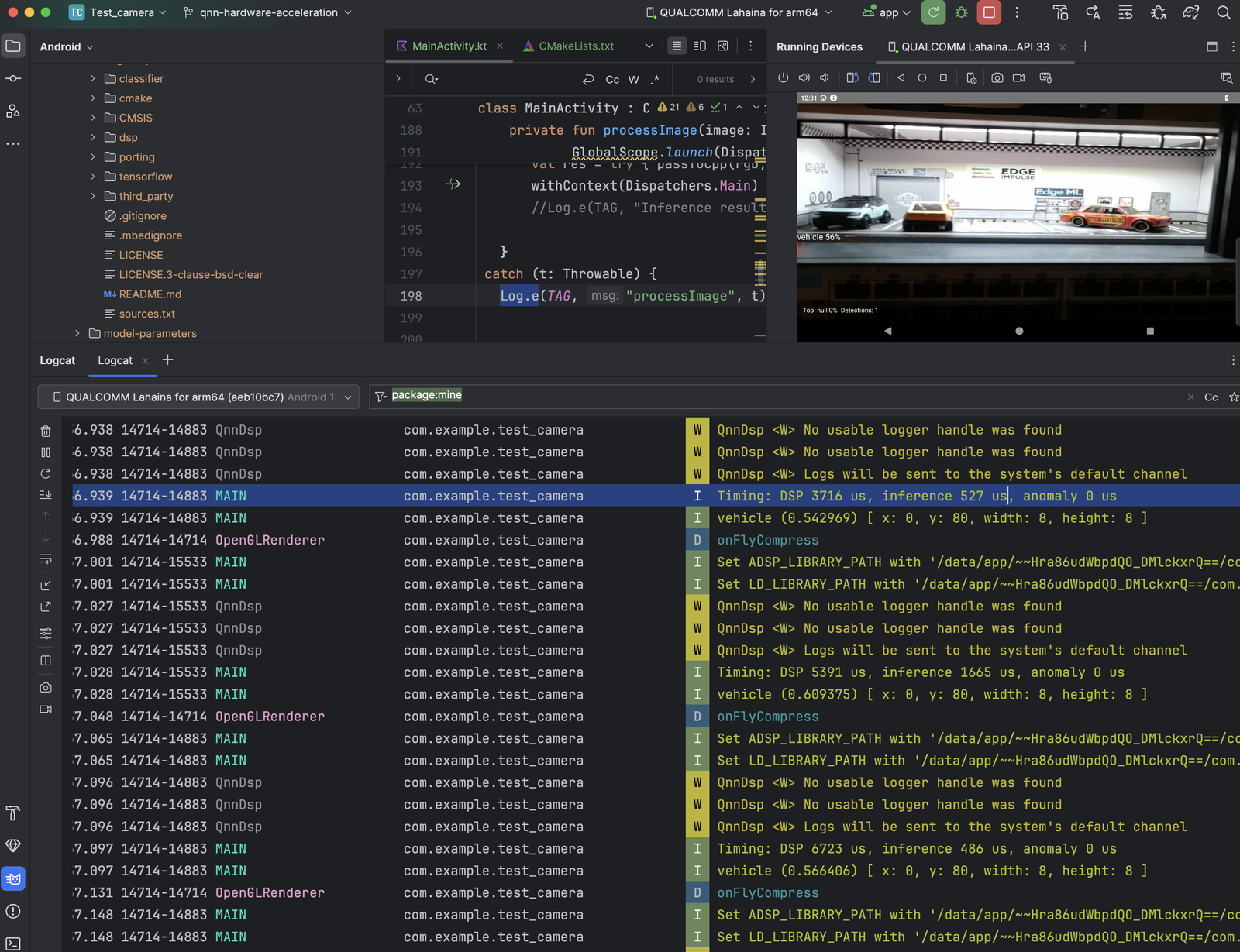
Logcat timing without QNN acceleration
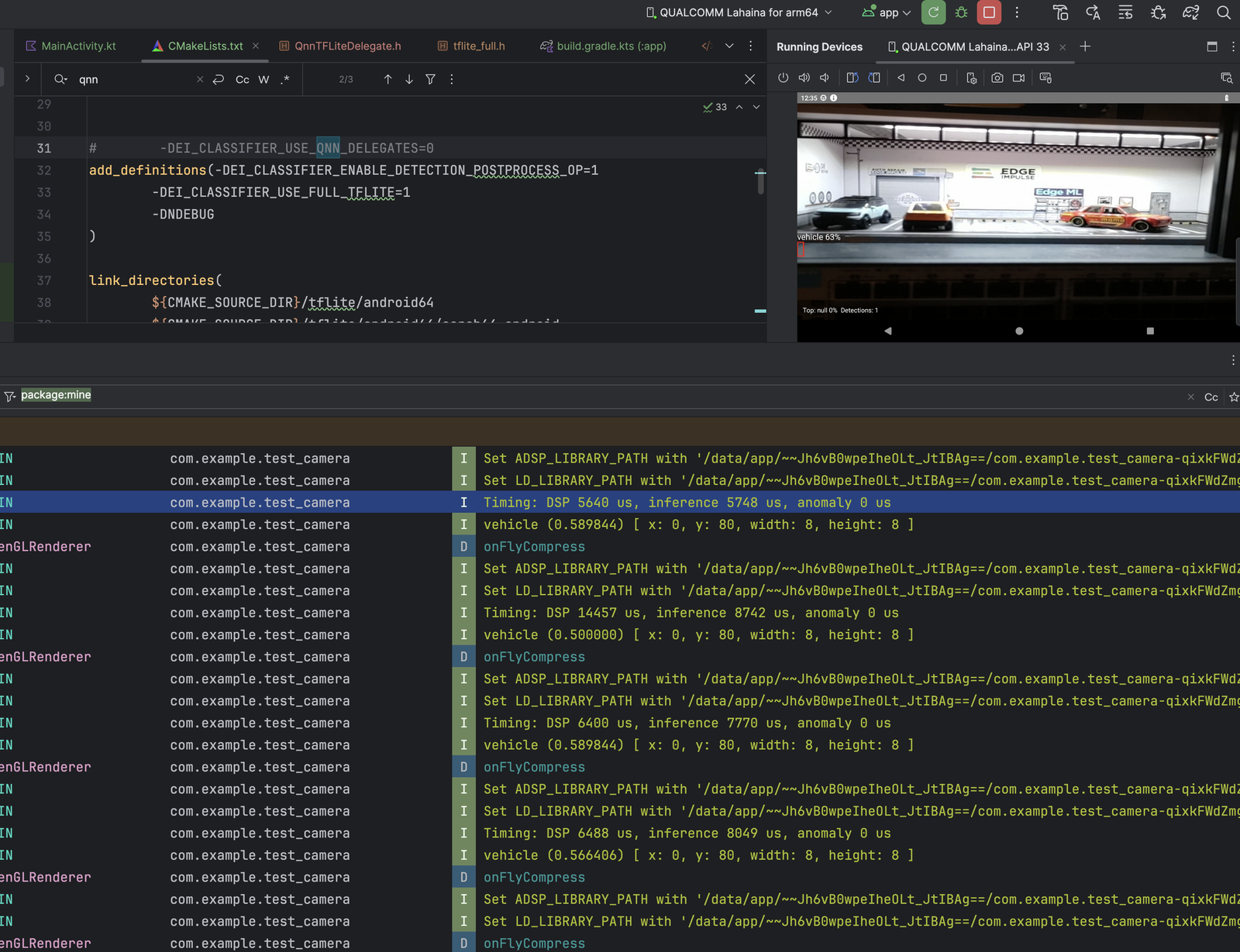
- Inference: 5,748 → 527 µs ≈ 10.9× faster
- DSP stage: 5,640 → 3,748 µs ≈ 1.5× faster
- Smoother frame times with dedicated accelerator
- Lower power consumption
Prerequisites
- Edge Impulse account: Sign up
- Trained object detection model
- Android Studio: Ladybug 2024.2.2 or later
- Snapdragon device real or Qualcomm Device Cloud with Hexagon NPU:
- Snapdragon 8 Gen 1/2/3 (mobile)
- Snapdragon 6/7 series (mid-range)
- QRB series (embedded: RB3, RB5, Dragonwing)
- Qualcomm AI Engine Direct SDK: Download from Qualcomm
- Tools: Android API 35, NDK 27.0.12077973, CMake 3.22.1
Supported devices
Devices with Qualcomm Hexagon NPU Gen 2 or later: Mobile:
Example Snapdragon reference device used for testing
- Snapdragon 8 Gen 3/2/1
- Snapdragon 7+ Gen 2/3
- Snapdragon 6 Gen 1
- QRB6490 (Rubik Pi 3)
- QRB5165 (RB5)
- Dragonwing platforms
Don’t have hardware? Try the Qualcomm Device Cloud with pre-configured Snapdragon devices.
1. Clone the repository
2. Locate Qualcomm AI Engine Direct SDK
Download and install the Qualcomm AI Engine Direct SDK. Common installation paths:libQnnTFLiteDelegate.so for Android arm64.
Find the delegate directory
macOS/Linux:C:\qairt\<version>\ and search for libQnnTFLiteDelegate.so.
The parent folder of that file is your source directory (it also contains other libQnn*.so runtime libs).
3. Copy QNN libraries
Create the destination directory in your project:Automated script (experimental)
Automated script (experimental)
The repository includes a fetch script:You’ll need to configure the script with your QAIRT SDK path first.
4. Deploy your model
In Edge Impulse Studio:- Go to Deployment
- Select Android (C++ library)
- Enable Quantized (int8) for best QNN performance
- Click Build
- Download the
.zip
5. Configure Android manifest
Updateapp/src/main/AndroidManifest.xml:
6. Build and run
Build in Android Studio
- Connect your Snapdragon device via USB
- Enable USB debugging in Developer Options
- Click Run (green play button)
- Select your device
Monitor performance
Open Logcat and filter byMainActivity:
Verify QNN acceleration
Check if QNN libraries are loaded:How it works
QNN TFLite delegate integration
Environment configuration
The app automatically sets required environment variables on startup:Project structure
Customization
Adjust HTP performance mode
Innative-lib.cpp, modify QNN options:
burst: Maximum speed, higher power (default)high_performance: Sustained high performancebalanced: Balance between speed and powerlow_power: Minimize power consumption
Enable profiling
/sdcard/qnn_profile.json.
Optimize model for QNN
In Edge Impulse Studio:- Use quantization: INT8 models leverage HTP better than FP32
- Supported operations: Check QNN operator support
- Enable EON Compiler: Optimizes for Qualcomm hardware
Change detection threshold
Performance tuning tips
Model optimization
- Use INT8 quantization - Essential for HTP acceleration
- Reduce input resolution - 320×320 vs 640×640 can be 4× faster
- Simplify architecture - Fewer layers = better HTP utilization
- Test operator coverage - Check which ops run on HTP vs CPU
Runtime optimization
Frame rate optimization
Benchmark results
Real-world performance on different devices:Google Tensor processors don’t include Hexagon NPU. QNN acceleration only works on Qualcomm Snapdragon devices.
Next steps
Qualcomm Device Cloud
Test without hardware