Preface
NVIDIA has released a family of World Foundation Models (WFMs). All models have to some degree overlapping areas of use and can be combined for an efficient pipeline. This article is about Cosmos Predict, Cosmos Transfer and Cosmos Reason are covered in separate articles.- Cosmos Transfer can amplify text and video input to create variations of environment and lighting conditions for training data for visual AI. Multiple input signals enable control of physics-aware world generation. We can compose a 3D scene in NVIDIA Omniverse and have Cosmos Transfer create the variation needed to train robust models for visual computing.
- Cosmos Reason is capable of reasoning based on spatial and temporal understanding of multimodal input. It can interpret what a sensor is seeing and predict consequences. It can also be a helpful tool to automatically evaluate the quality of synthetic training data.
- Cosmos Predict can create training data, both single image and video clip, for visual AI based on text- and image input.
Prerequisites
- Python
- Optional: Access to NVIDIA GPU with at least 32 GB VRAM
- Optional: NVIDIA Omniverse Isaac Sim
What to expect
This tutorial shows how to use NVIDIA Cosmos-predict2, released June 2025 to generate physics aware synthetic images for training models for visual computing. The tutorial will show hands-on approaches on how to generate text- and image-prompted images and videos, automatically segment and label objects of interest and prepare data for model training in Edge Impulse Studio. We’ll start with a comparison of other methods and models, walk through an easy to perform web-based demo, dive into self-hosting the smaller models, use local AI-labeling models, take full advantage of single-image generation with batching and prompt enrichment with LLMs, before we move to the larger models and video generation.
In case of problems reproducing these walk-throughs, ComfyUI now supports Cosmos Predict2.
Alternative methods
The traditional method to create training data for visual computing is to manually capture images in the field and to label all objects of interest. As this can be a massive undertaking and it can be challenging to cover special circumstances, synthetic training data generation has become a popular supplement. Even with real-time path-tracing and domain randomization methods capable of generating highly controlled masses of data, covering sufficient variation to create robust models can be labor intensive.Generating Synthetic Images with GPT-4 (DALL-E)
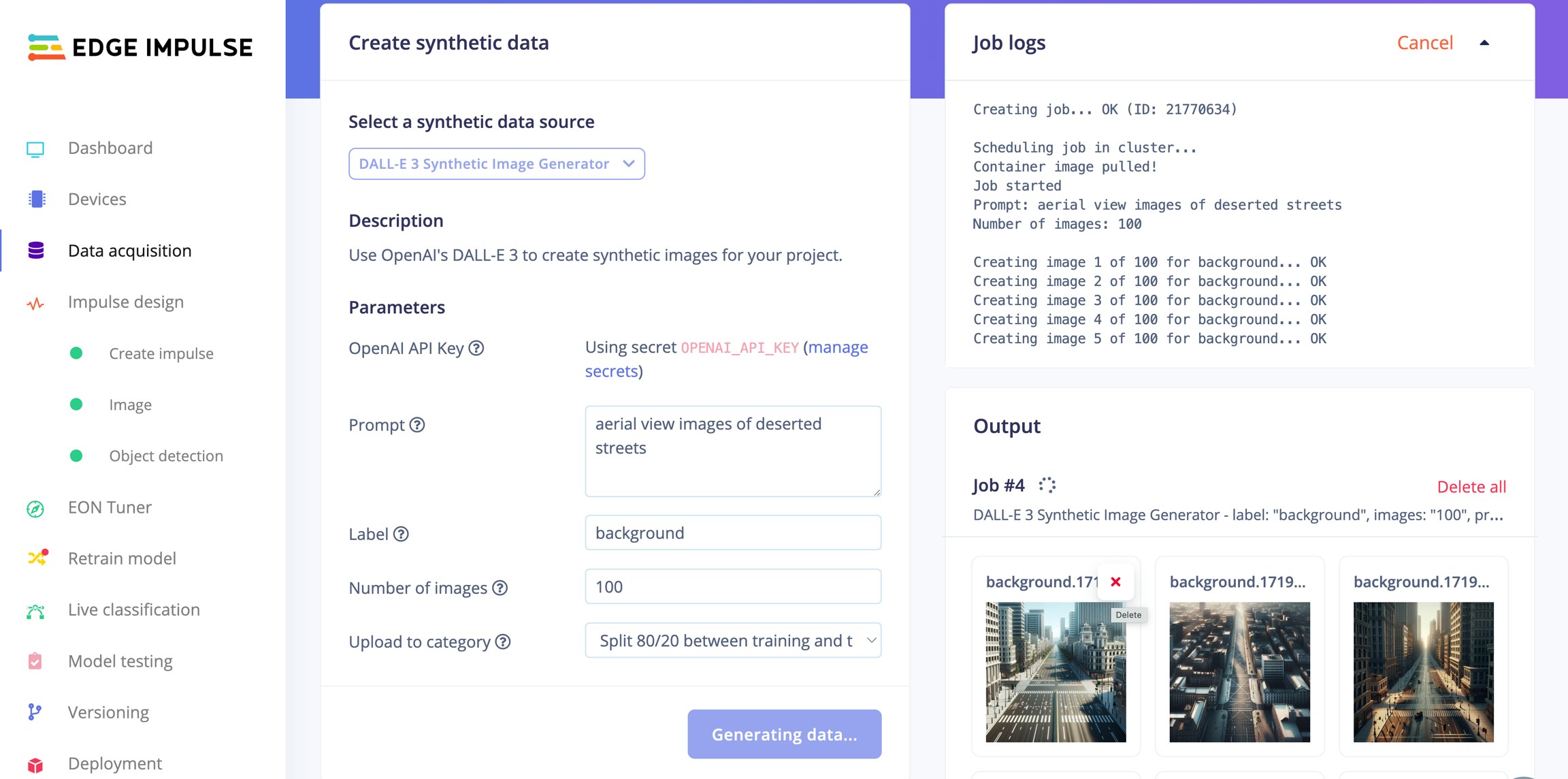
Generating Synthetic Images with GPT-4 (DALL-E)
Note about AI labeling Models used for labeling are trained on vast collections of manually labeled objects. They usually work great for common objects. For labeling uncommon objects, or even objects that are new, e.g. brand-new commercial products, these models fall short. In these cases Cosmos Transfer offer a novel architecture as label data from a 3D scene can be reused. This is due to the highly controllable nature of Cosmos Transfer, where certain aspects of the input signal data will be respected when a new variation of a Omniverse-created video sequence is generated. This can be achieved in a number of ways thanks to multimodal control signal input. In short - a new video clip is generated, for instance with a different background, but objects of interest stay at the same screen-space position as in the input clip. Bounding boxes therefore remain valid for both clips. Cosmos Transfer is not covered in this article, but this should be an important feature to consider when choosing among the different Cosmos models.Another variation is to use video generation, such as OpenAI Sora, Google Gemini Veo 3 or any high performing video generators. Text, image and video input can prompt generation of video sequences. The advantage of generating video clips over still images is that we get the objects of interest in many different angles with minimal effort. For object detection, these sequences can then be split into individual still frames, before labelling. Training image generation with these types of models have the disadvantages of being hard to control. Objects of interest will tend to morph out of form and strict camera control is hard to achieve. Generating training images of novel objects, say a new commercial product, is also currently hard to accomplish. These models have been trained for generalization, from movie stars eating pasta to presidents promoting unconventional vacation resorts. Some comparisons:
Sora:
Cosmos Predict:
The Sora videos are of great fidelity, but notice how Cosmos Predict defaults to a setting suitable for edge AI scenarios. We could achieve the same results with Sora, but it would require a lot of trial and error with targeted prompting. Without API access to Sora, ability to change seed or negative prompt, methodically generating 10.000s of variations for model training is impractical.
The NVIDIA Cosmos WFMs on the other hand are trained on a curated set of driving and robotics data. The ability to supply multimodal control data and to post-train the models for custom scenarios makes them further suitable for tailored training data generation. However, don’t expect perfect results each time, especially with Cosmos Predict Video2World. Depending on the complexity of the scene some misses should be expected, for this Cosmos has implemented a rejection sampling mechanism, briefly mentioned in this article and covered in-depth in a separate article about Cosmos Reason.
The Cosmos model’s advantages do however come with a cost - they require a lot of compute and require a bit of insight to harness. This article will cover a few different options in getting to know the capabilities of Cosmos Predict.
Method/model comparison
Quick-start
We can get an impression of the capabilities of Cosmos Predict with almost no effort. This approach does however severely limit options for synthesis customization. Be aware that the 20 request limit does not reset periodically. As of June 2025 cosmos-predict2 is not available for testing at NVIDIA Build, only the previous cosmos-predict1-7b.- Go to build.nvidia.com, register or log on.
- Enter a prompt, such as:
- Wait about 60 seconds to see the results.
To download the generated video we can enter the following JavaScript into Console in the browser developer tools:
A first person view from the perspective of a FPV quadcopter as it is flying over a harbor port. The FPV drone is slowly moving across the harbor, 20 meters above the ground, looking down at cargo containers, trucks and workers on the docks. The weather is cloudy, it is snowing lightly, the ground is covered in a 1 cm layer of snow. Wheel tracks are visible in the snow. Photorealistic
The API automatically returns a refined prompt; we can feed this back into the model (or an LLM) to iterate on scene detail:
In a breathtaking aerial journey, we soar above a bustling harbor, captured through the lens of a cutting-edge first-person view (FPV) quadcopter. The camera glides smoothly at a steady 20 meters above the ground, revealing a sprawling landscape of vibrant cargo containers stacked neatly on the docks, their bright colors contrasting against the deep blue of the water. Below, a lively scene unfolds as workers in high-visibility vests coordinate the loading and unloading of containers, while trucks and forklifts crisscross the area, their movements a testament to the port’s dynamic energy. The sun bathes the scene in a golden-hour glow, casting long shadows that dance across the ground, while the clear sky enhances the vivid hues of the containers and the shimmering water. This cinematic experience, enhanced by dynamic color grading and a steady, immersive perspective, invites viewers to feel the thrill of flight and the rhythm of the port’s industrious life.Another slight prompt change can dramatically change the output:
View directly underneath a first-person quadcopter as it is flying over a harbor port. The view is slowly moving across the harbor, 10 meters above the ground, looking straight down at cargo containers, trucks and workers on the docks. The weather is cloudy, it is raining heavily, the ground is wet. Photorealistic
We can easily achieve combined environmental factors that would require a lot of work if this was created as a 3D scene in Omniverse.
View directly underneath a first-person quadcopter as it is flying over a harbor port. The view is slowly moving across the harbor, 10 meters above the ground, looking straight down at cargo containers, trucks and workers on the docks. The weather is clear, it is midnight and dark. The ground and objects are illuminated by a full moon and powerful site flood lights. It is raining heavily, the ground is wet. Photorealistic
Extract stills
- Install FFmpeg (linux):
- Extract still images
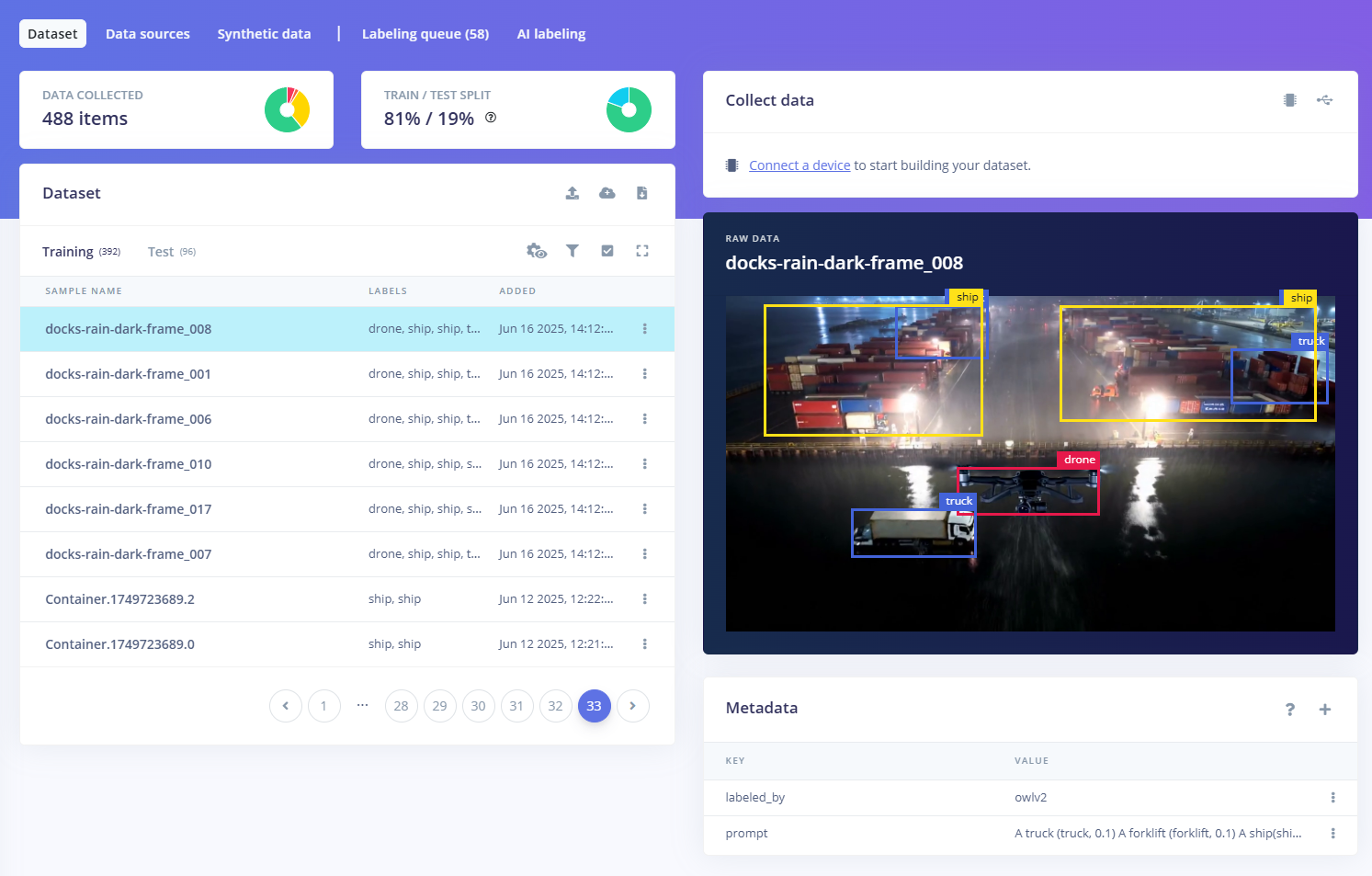
- Upload images to Edge Impulse Studio
- Use AI labelling
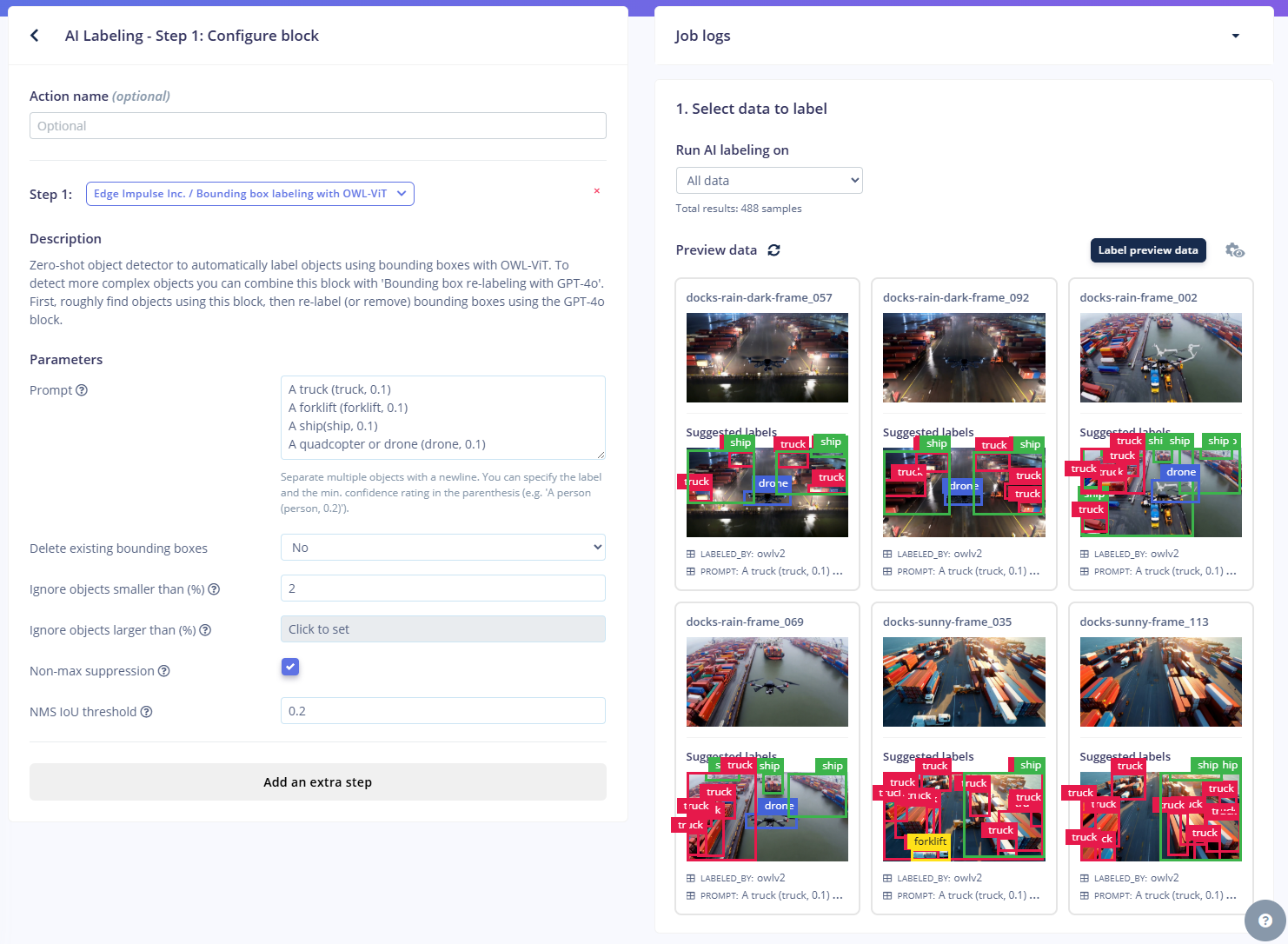
AI Labeling using OWL-ViT
- (Optional) Validate labels with GPT-4o
- Train model.
Deep dive
Now that we have acquired a sense of the capabilities of Cosmos Predict the next natural step is to host the models yourself so that we can further explore capabilities. First we need to be aware of the hardware requirements of different features: The following table shows the GPU memory requirements for different Cosmos-Predict2 models:
For optimal performance
- NVIDIA GPUs with Ampere architecture (RTX 30 Series, A100) or newer
- At least 32GB of GPU VRAM for 2B models
- At least 64GB of GPU VRAM for 14B models
Installing cosmos-predict2
Follow the repository instructions, the Docker container route is recommended to try to avoid complicated issues with Blackwell GPUs, CUDA and Torch.- Get a Hugging Face access token with
Readpermission - Login:
huggingface-cli login - The Llama-Guard-3-8B terms must be accepted. Approval will be required before the gated Llama Guard 3 checkpoints can be downloaded.
- Download models. Models for running Cosmos-Predict2-2B-Text2Image alone can run up near 200GB in checkpoint space.
Running cosmos-predict2
With any luck you will now be able to spin up the container and have the checkpoints you need:--negative_prompt="${NEGATIVE_PROMPT}"

Parking lot Text2Image-2B

Warehouse docking Text2Image-2B

Drainage pipe Text2Image-2B

Bikes Text2Image-2B

e-scooter Text2Image-2B
batch_can_factory.json:
- Save duplicate
batch_can_factory.jsonasbatch_can_factory_template.json. - Create a python program like this:
- Run with
python run_can_factory_batches.py --n 3

Batch output
Notes on prompting for realism Diffusion models like the one Cosmos Predict uses are currently achieving incredible image fidelity. When generating images for training object detection models intended to run on constrained hardware, or any type of hardware for that matter, best results are achieved by generating images of a quality that closest resembles the quality the device itself produces. This should in theory be possible to achieve by prompting e.g.or by adding —negative_prompt e.g.Experiments suggest that low‑fidelity camera‑noise prompts have limited impact on Cosmos Predict or Sora outputs—likely because the training corpus emphasises high‑quality footage. With the Cosmos models however, we have the option to fine-tune to our needs. Also note that adding “Photorealistic” is recommended in the documentation, but shows no significance in testing.
Advanced: LLM-augmented prompt generation for Text2Image
To further bend the limitations of batch prompting and seed iteration we can use an LLM to augment and multiply prompts. Experimentation has shown that using a web-search capable LLM with a detailed description of intended use provides useful results. A prompt might look like so:
Batch output

Batch
AI labeling with Grounded Segment Anything 2
In contrast to Cosmos-Transfer we have no way of producing bounding boxes or labels of our objects of interest with these image or video clip generators. Without labels our images are useless for machine learning. Manually drawing bounding boxes and classifying tens of objects per image requires a large amount of manual labor. Many AI segmentation models are available, but stand-alone they require some input on what objects we want to label. Manually selecting the objects of interest would still require a huge effort. Thankfully it is possible to combine segmentation models with multimodal Visual Language Models. This way we can use natural language to select only the objects of interest and discard the rest of the objects the segmentation model has identified. The following will walk through using one of many Open Vocabulary Object-Detection (OVD) pipelines, Grounded Segment Anything 2 with DINO 1.0. This repo supports many different pipeline configurations, many grounding models and can be a bit overwhelming. Grounding DINO 1.0 might not be the best performing alternative but it’s open source and works for common objects. For niche objects DINO 1.5, DINO-X might reduce false positives by 30-40%, but these models require API-access and might be rate limited.Note: SAM2 video predictor wants jpg-files as input.Clone the repo.

Labeled images with segmentation masks and bounding boxes
A note on thresholds
Grounded‑SAM‑2 inherits two key filtering knobs from Grounding DINO--box_threshold and --text_threshold. Both are cosine‑similarity cut‑offs in the range 0‑1, but they act at different stages of the pipeline:
How they work together
- Box screening The model predicts up to 900 candidate boxes. Any whose best token similarity is below box_threshold are discarded outright.
-
Label assignment For every surviving box, each prompt token is compared to the box feature; tokens scoring below
text_thresholdare dropped, so they never appear in the final phrase.
Practical effect
-
Raise thresholds → higher precision, lower recall. You get fewer false detections and fewer stray sub‑word labels such as
##liftorcanperson, due to tokenization ofcan,personandforklift, but you may miss faint objects. -
Lower thresholds → higher recall, lower precision. More boxes and more tokens survive, which can help in cluttered scenes but increases the need for post‑processing. A common starting point is
box_threshold 0.3,text_threshold 0.25as recommended in the Grounded‑SAM demo scripts.
--box_threshold decides whether a region is worth keeping at all, while --text_threshold decides which words (if any) are attached to that region. Tune them together to balance missed objects against noisy labels.
To be able to upload label data to Edge Impulse Studio we need to convert the output to one of the supported formats, in this case Pascal VOC XML.
Conversion program: json_to_pascal_voc.py
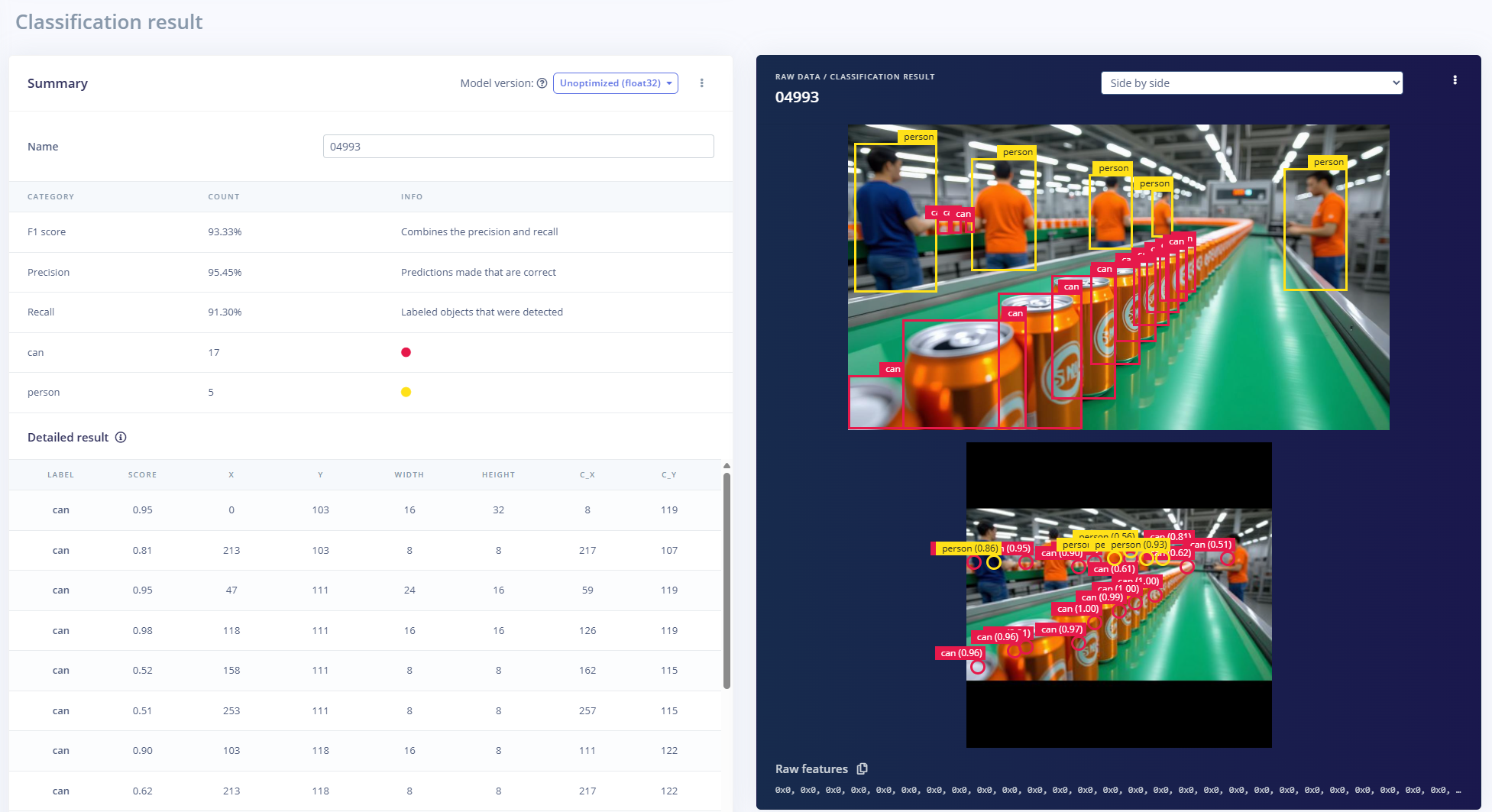
Classification results
Generating images and videos with 14B parameters models, Text2World and Video2World
To be able to run the larger models a home-GPU just won’t cut it. Luckily we can experiment with the models with beefier hardware with little commitment. Many services offer pay-per-use GPU resources. For the Cosmos models we need to keep in mind that we need rather updated NVIDIA drivers and that the platforms usually only allow access to a docker container with no possibility for upgrading said drivers. Uncovering this up-front is almost impossible, outside contacting support. Beware before investing a lot in prepaid tokens! For instance, when attempting to run the Cosmos-Predict2 docker container on a NVIDIA H100 80GB host at RunPod.io as of June 2025, one would get this warning:nvidia-smi and we need something like:
Lambda Cloud
Setup with Docker image
Inference with Text2World
The default model checkpoints will produce 720p, 16 fps videos that last 5 seconds.Inference with Video2World
As the name suggests Video2World can extend an existing video clip. However, it can be used as an alternative starting point to Text2World by taking a text prompt and an image as input. It is possible to chain clip generation to extend clip duration but that is a more advanced topic that should be run on a multi-GPU setup. Common usages would be to take a manually captured image and combine with a prompt to produce a video clip. We can also pick the best generated Text2Image results and generate clips. This is a low-effort way to generate many images of the same objects from slightly different angles. This is the same as using Text2World, but we get to be more selective on the input images. With Text2World we won’t know if the initial frame is any good before the whole process is complete (note, it is actually possible to view the temporarily created first frame, but this is not very practical when processing large batches over night).
NVIDIA Cosmos-Predict2-14B-Video2World demo 00092
As with Text2Image we can put this into system with batching.
--seed to create different variants.
Resulting videos:
For this use case the highest rate of success was achieved by generating images with the 2B parameters Text2Image model and then using the 14B parameters Video2World to generate video clips. When using 14B Text2Image and 14B Video2World the videos would have higher fidelity with regards to details, but in 3 out of 4 attempts there would be some sort of physical anomaly rendering the video looking strange. Out of 40 attempts the following compilation shows the only consistent results. For object detection however, most of the results would still be usable, as we would extract all frames individually and not care about weird movement.
Rejection Sampling for Quality Improvement
We can automatically combat undesired results with rejection sampling. We can specify a number of video generation attempts and use Cosmos Reason to score the results.Conclusion
Diffusion models have come a long way in a short time. Advanced computer graphics simulation phenomena such as reflections and color bleeding due to global illumination are now convincingly replaced by learned distributions in latent vector spaces.
NVIDIA Cosmos-Predict2-14B-Text2Image demo

NVIDIA Cosmos-Predict2-14B-Text2Image demo

NVIDIA Cosmos-Predict2-14B-Text2Image demo

NVIDIA Cosmos-Predict2-14B-Text2Image demo

NVIDIA Cosmos-Predict2-14B-Text2Image demo

NVIDIA Cosmos-Predict2-14B-Text2Image demo