Introduction
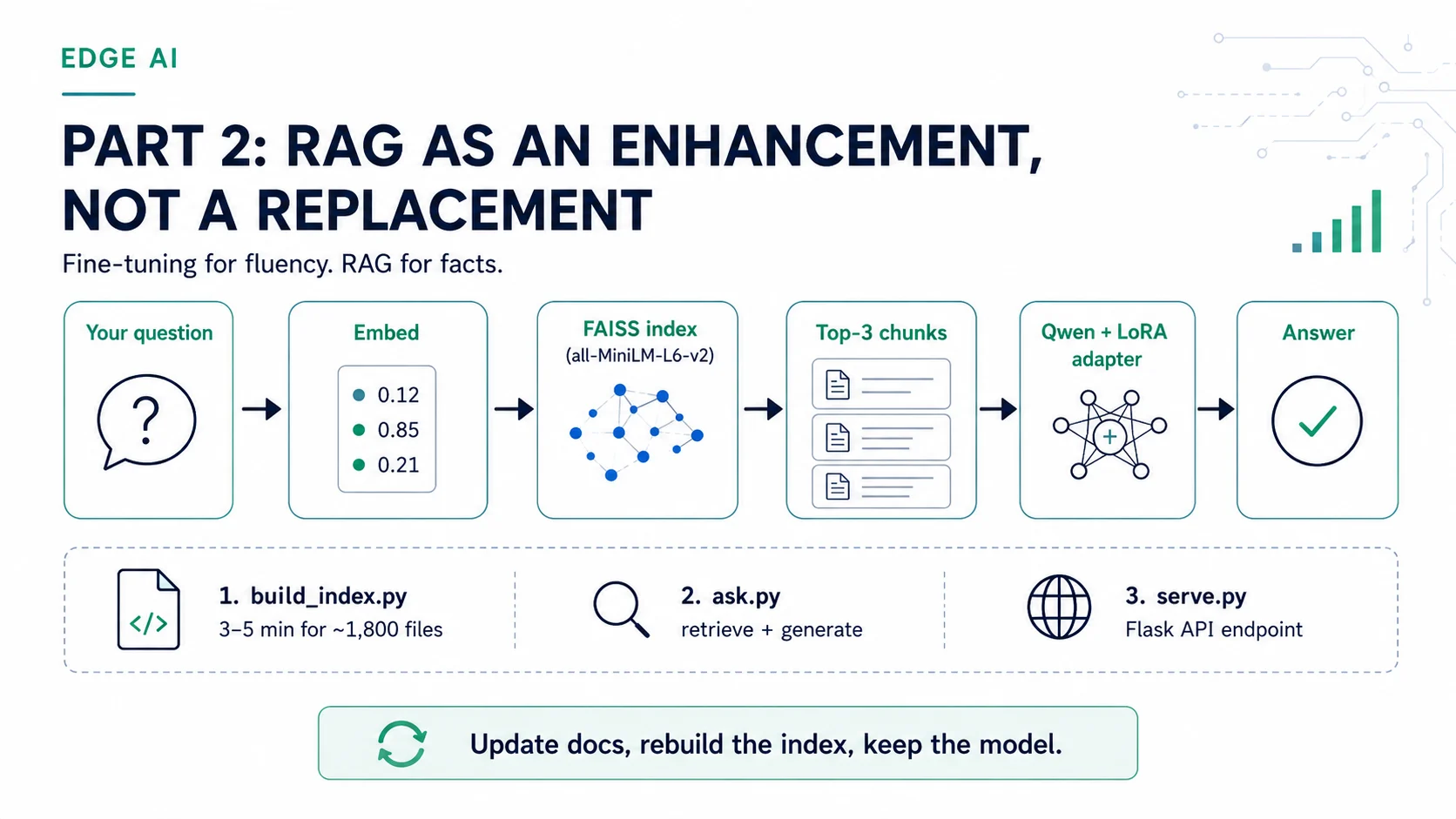
The Part 1 guide showed how to load a fine-tuned Qwen2.5-Coder LoRA adapter and query it directly on a Raspberry Pi or Rubik Pi 3. That gives you a self-contained offline assistant whose domain knowledge — Edge Impulse Studio workflows, SDK methods, deployment targets — is baked into its weights at training time. This guide pairs that same adapter with a FAISS retrieval index built from the live documentation source files. The result is a system that combines a fine-tuned adapter with document retrieval so your assistant can use current docs content while running fully offline on the same hardware.How it works
This guide walks through the rag-docs-demo companion repository, which pairs:- A FAISS inner-product index built from the Edge Impulse
.mdxdocumentation source files - The
eoinedge/edgeai-docs-embedding-qwen1.5-0.5b-instructLoRA adapter on top ofQwen/Qwen2.5-Coder-0.5B-Instruct - A minimal Flask HTTP server so other tools and scripts on the same device can query the assistant over HTTP
At query time,
ask.py encodes the question with the same all-MiniLM-L6-v2 model used at index time, runs a nearest-neighbour search over the FAISS index, and concatenates the top three matching chunks into a context block that prefixes the generation prompt. This keeps the language model’s output grounded in actual documentation text rather than in general world knowledge.
Prerequisites
- A Raspberry Pi 4 / Pi 5, a Thundercomm Rubik Pi 3, or an NVIDIA Jetson Orin running a 64-bit Linux distribution
- A local clone of the Edge Impulse documentation repository at
~/documentation(or any folder of.md/.mdxfiles) - Python 3.10 or later with
pipandvenvavailable - ~1.5 GB free disk space for the base model cache (
~/.cache/huggingface) and the FAISS index
The base model is
Qwen/Qwen2.5-Coder-0.5B-Instruct. It is a ~1 GB download on first run and is cached in ~/.cache/huggingface for all subsequent runs.Clone the repo and install dependencies
requirements.txt includes: torch, transformers, peft, sentence-transformers, faiss-cpu, and flask.
On a Raspberry Pi or other ARM Linux device, install the CPU-only PyTorch wheel first to avoid a failed CUDA build attempt:
Step 1 — Build the FAISS index
build_index.py scans your local documentation folder, encodes every file with all-MiniLM-L6-v2, and saves the resulting index alongside a pickle of the raw text chunks.
~/documentation/**/*.mdx. Override the path with --docs if your docs clone is somewhere else or if you want to index a different set of files:
By default each file is encoded using its first 2048 characters. This keeps memory use predictable on devices with limited RAM. You can raise the limit with
--chunk-size 4096, but on a Pi 4 with 4 GB RAM the default is a safe starting point..mdx files takes around 3–5 minutes on a Raspberry Pi 5 and around the same on the Rubik Pi 3 thanks to its eight Kryo 670 cores.
Step 2 — Ask a question (CLI)
With the index built, you can ask questions directly from the terminal:- Loads the Qwen2.5-Coder base model and the LoRA adapter from cache (or downloads them on first run)
- Loads the FAISS index and the text chunk store
- Encodes the question with
all-MiniLM-L6-v2and retrieves the top 3 most relevant documentation chunks - Builds a grounded prompt from those chunks and generates an answer with up to 300 new tokens
ask as a function in your own Python scripts:
The first call in a session takes longer because the model loads from disk. Subsequent calls in the same Python process reuse the loaded model and index.
How the retrieval and generation works
ask.py uses three constants that you can adjust at the top of the file:
ask() function:
k retrieves more chunks (more context) at the cost of a longer prompt and slightly slower generation.
Step 3 — Run the HTTP server
serve.py wraps ask() in a minimal Flask endpoint so other services, scripts, or tools running on the same device can query the assistant without importing the Python module directly.
Start the server bound to localhost:
curl:
question field is missing or empty, the server responds with HTTP 400 and {"error": "question is required"}.
Adding new docs to the index on the fly
One of the core advantages of RAG over fine-tuning is that you can add entirely new content to the assistant without any retraining — just drop the files into a folder, rerunbuild_index.py, and the new knowledge is immediately available at query time. The adapter’s weights never change; only the retrieval index does.
This is useful whenever new documentation lands that the adapter has not seen, or when you want to extend the assistant with project-specific guides, internal notes, or content from another source entirely.
Example — adding new robotics docs
As a concrete example, suppose a new set of robotics tutorials has just been published as a.zip of .mdx files. The adapter was trained before these existed, so it has no knowledge of their content. With a fine-tuned model that would mean waiting for a new training run. With RAG you can have the assistant answering questions from those docs in minutes.
Unzip the new content alongside the existing docs:
edgeai_docs.index and edgeai_docs_texts.pkl, and is immediately live on the next ask.py call or after restarting serve.py.

build_index.py accepts any folder of .md or .mdx files via --docs. The glob pattern is passed directly to Python’s glob.glob(..., recursive=True), so you can point it at a zip extract, an internal wiki export, a cloned external docs repo, or any mix of directories.Updating the index after a documentation pull
After pulling documentation updates, rebuild the index to reflect the new content:edgeai_docs.index and edgeai_docs_texts.pkl in place. Any running serve.py instance will need to be restarted to pick up the new index.
Best practices
- On a Raspberry Pi 4 with 4 GB RAM, close unused services before running
ask.pyorserve.py. The combined memory footprint of the FAISS index, the sentence-transformer model, and the Qwen2.5-Coder adapter is around 2.5–3 GB. - Increase
kinask()from 3 to 5 if answers feel incomplete, but expect a small increase in generation time. - Validate generated code and API calls before using them against live Edge Impulse projects or hardware.
- The adapter’s training cut-off is mid-2026. For documentation added after that date, retrieval still works correctly because the FAISS index reflects your local docs clone — the model just relies more heavily on the retrieved context rather than its own weights.
Related
This series- Offline SLMs for Edge AI Development — Part 1: Direct Inference with a Qwen LoRA Adapter — prerequisite guide covering environment setup and direct adapter inference
- Offline SLMs for Edge AI Development — Part 3: Agentic Coding with an Arduino Fine-Tuned Adapter via llama.cpp and OpenCode — run GGUF models with llama-server and use OpenCode as an offline agentic coding assistant
eoinedge/edgeai-docs-embedding-qwen1.5-0.5b-instruct— the LoRA adapter used in this guideQwen/Qwen2.5-Coder-0.5B-Instruct— base model on Hugging Facesentence-transformers/all-MiniLM-L6-v2— embedding model used to build and query the FAISS indexeoinedge/arduino-qwen0.5-lora— companion adapter fine-tuned on Arduino documentation
- Full MCP stack: eoinjordan/pi-openclaw-mcp-stack
Reference
- GitHub:
eoinjordan/rag-docs-demo - Base model:
Qwen/Qwen2.5-Coder-0.5B-Instruct - Embedding model:
all-MiniLM-L6-v2(sentence-transformers) - Index type:
faiss.IndexFlatIP(inner product, L2-normalized embeddings = cosine similarity) - Hardware guides: Thundercomm Rubik Pi 3 · Raspberry Pi 5 · Qualcomm RB3 Gen 2 · NVIDIA Jetson Orin
- Python libraries:
transformers,peft,torch,sentence-transformers,faiss-cpu,flask