This tutorial showcases cutting-edge AI capabilities on mobile devices. You’ll build a chat-like interface where users can speak prompts to generate images using hardware-accelerated AI models.
Reference code: https://github.com/edgeimpulse/example-android-inferencing/tree/main/qnn-genai-speech_to_image

What you’ll build
An Android application that:- Records speech input using Android’s audio APIs
- Processes speech to text using Whisper model accelerated by QNN
- Generates detailed images from text prompts using Stable Diffusion
- Displays results in a chat-like interface
- Runs entirely on-device with hardware acceleration
Difficulty: Advanced
Architecture overview
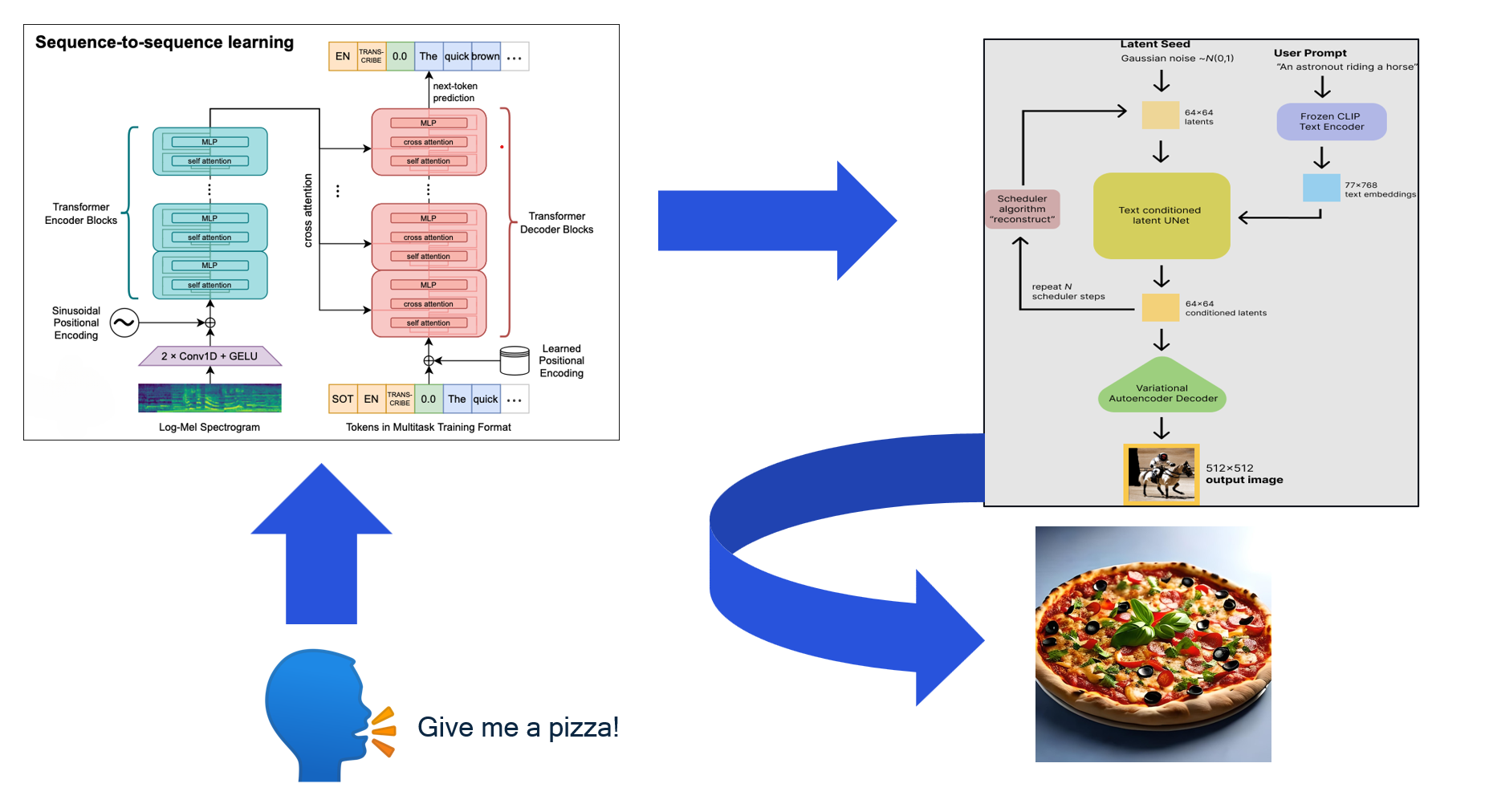
- Kotlin UI: Handles user interaction, audio recording, and display
- C++ Backend: QNN APIs for model inference on Snapdragon HTP
- JNI Bridge: Seamless communication between Kotlin and C++
- Rust Libraries: Tokenization/detokenization for model inputs/outputs
Prerequisites
- Edge Impulse account: Sign up
- Trained model: Complete a tutorial first (for custom workflows)
- Android Studio: 2024.3.1 or later
- Android NDK: Version 27.2.12479018
- Rust toolchain: Latest stable with Android targets
- Qualcomm AI Engine Direct SDK: v2.40.0 (Download)
- Python 3.10: For asset generation scripts
- Snapdragon device with Hexagon NPU (see supported devices below)
Supported devices
Tested on Snapdragon 8 Elite. Compatible with devices featuring Hexagon NPU Gen 2 or later: Mobile:- Snapdragon 8 Gen 3/2/1
- Snapdragon 7+ Gen 2/3
- Snapdragon 6 Gen 1
- QRB6490 (Rubik Pi 3)
- QRB5165 (RB5)
- QCS2210 (Arduino UNO Q)
1. Clone the repository
Step 1: Clone the repository2. Set up Qualcomm AI Engine Direct SDK
Step 2: Set up Qualcomm AI Engine Direct SDK Download and extract the QNN SDK, then set the environment variable:The SDK provides the necessary libraries and tools for QNN acceleration. Version 2.40.0 is recommended.
3. Install Rust and Android targets
Step 3: Install Rust and Android targets4. Compile Rust tokenization libraries
Step 4: Compile Rust tokenization libraries The app uses Rust libraries for text tokenization. Build them for Android:5. Set up Android project dependencies
Step 5: Set up Android project dependenciesCopy QNN libraries
Create the JNI libs directory and copy required libraries:Copy QNN headers and utilities
Run the dependency resolution script:Copy additional dependencies
Download and copy required source files:6. Download AI model assets
Step 6: Download AI model assets Create the assets directory and download model files:Tokenizers
Stable Diffusion models
Download from Qualcomm Package Manager (requires account):- text_encoder.bin
- unet.bin
- vae_decoder.bin
speech_to_image/app/src/main/assets/
Whisper models
Audio processing assets
Generate embedding tokens
Run the Python script to generate required token files:t_emb_0.raw through t_emb_19.raw and tokens.raw in the assets directory.
7. Configure device for QNN
Step 7: Configure device for QNN For proper QNN functionality, push the HTP skeleton library to device:8. Build and run the application
Step 8: Configure microphone permissions Add the following to yourAndroidManifest.xml if not already present:
- Request microphone permissions
- Display a chat interface
- Record speech when you tap the microphone button
- Process speech to text using Whisper
- Generate images using Stable Diffusion
- Display results in the chat
Common workflow
All Android tutorials in this series follow this pattern:- Export model from Studio → Deployment → Android (C++ library)
- Download TFLite libraries (if using TFLite):
- Copy model files to
app/src/main/cpp/(skip CMakeLists.txt) - Update test features or assets as needed
- Build and run in Android Studio
Troubleshooting
Build issues
- Missing libraries: Verify all QNN and Rust libraries are copied to
jniLibs/arm64-v8a/ - Header errors: Ensure
resolveDependencies.shran successfully - CMake errors: Check NDK and CMake versions match requirements
Runtime issues
- QNN initialization fails: Confirm device has Hexagon NPU and libraries are pushed correctly
- Model loading fails: Verify all asset files are present and not corrupted
- Poor performance: Ensure device is not overheating; QNN acceleration may throttle
Audio processing
- No speech detected: Check microphone permissions and device audio settings
- Poor transcription: Whisper tiny model is lightweight; consider larger models for better accuracy
Performance expectations
On Snapdragon 8 Elite:- Speech-to-text: ~100-200ms for 5-10 second clips
- Image generation: ~2-5 seconds for 512×512 images
- Total latency: ~3-7 seconds end-to-end
Performance varies by device, model size, and prompt complexity. The app demonstrates on-device AI capabilities without cloud dependency.
Additional resources
- GitHub: qnn-hardware-acceleration
- Qualcomm AI Engine Direct SDK Docs
- QNN TFLite Delegate Guide
- Device Cloud Tutorial
- Edge Impulse Forum
Summary
You’ve successfully utilized the Qualcomm QNN hardware acceleration for GenAI models on Android. Key takeaways:- Integrated Whisper and Stable Diffusion models for speech-to-image generation
- Leveraged QNN SDK for efficient on-device inference
- Built a user-friendly Android application with Kotlin and C++