Use cases
Traditional YOLO models are powerful, but they were designed for cloud environments and academic datasets like COCO in mind, not to mention the restrictive licensing for commercial use. YOLO-Pro flips that paradigm. These architectures and training scripts are engineered from the ground up to excel in real-word edge deployments, with future optimizations specifically for industrial applications coming. That means better performance, lower latency, and smarter resource usage for your embedded object detection projects. As we work towards a full release of the models, we will provide a list of example use cases where these models excel.Metrics
YOLO-Pro will be optimized against benchmarks that are relevant for industrial situations, leading to better performance at real-world tasks. Future releases of YOLO-Pro will be accompanied by benchmarks.Using the models in a project
The YOLO-Pro models can be accessed in your project in the same way as other object detection models.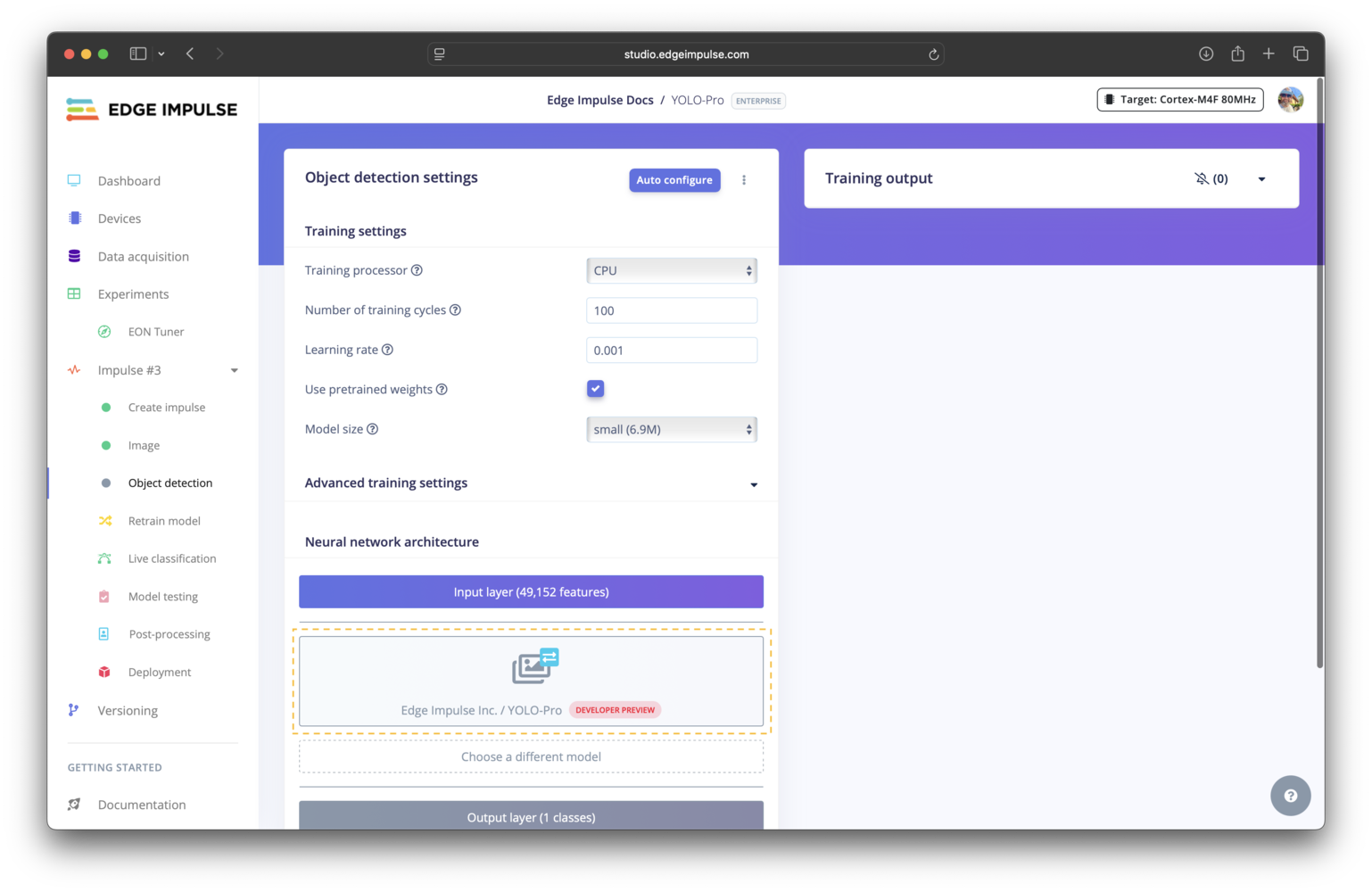
YOLO-Pro architecture selection
1
Add learning block
Add an object detection learning block to your impulse.
2
Select YOLO-Pro architecture
Select YOLO-Pro as your neural network architecture on the settings page for the object detection learning block.
3
Configure training settings
Configure your desired model size, architecture type, augmentation, and additional training parameters.
Training settings
There are a number of settings specific to the YOLO-Pro models that can be configured. When in doubt, the best approach is to use the EON Tuner to help you decide. Please refer to the learning blocks overview for settings that are common across all learning blocks.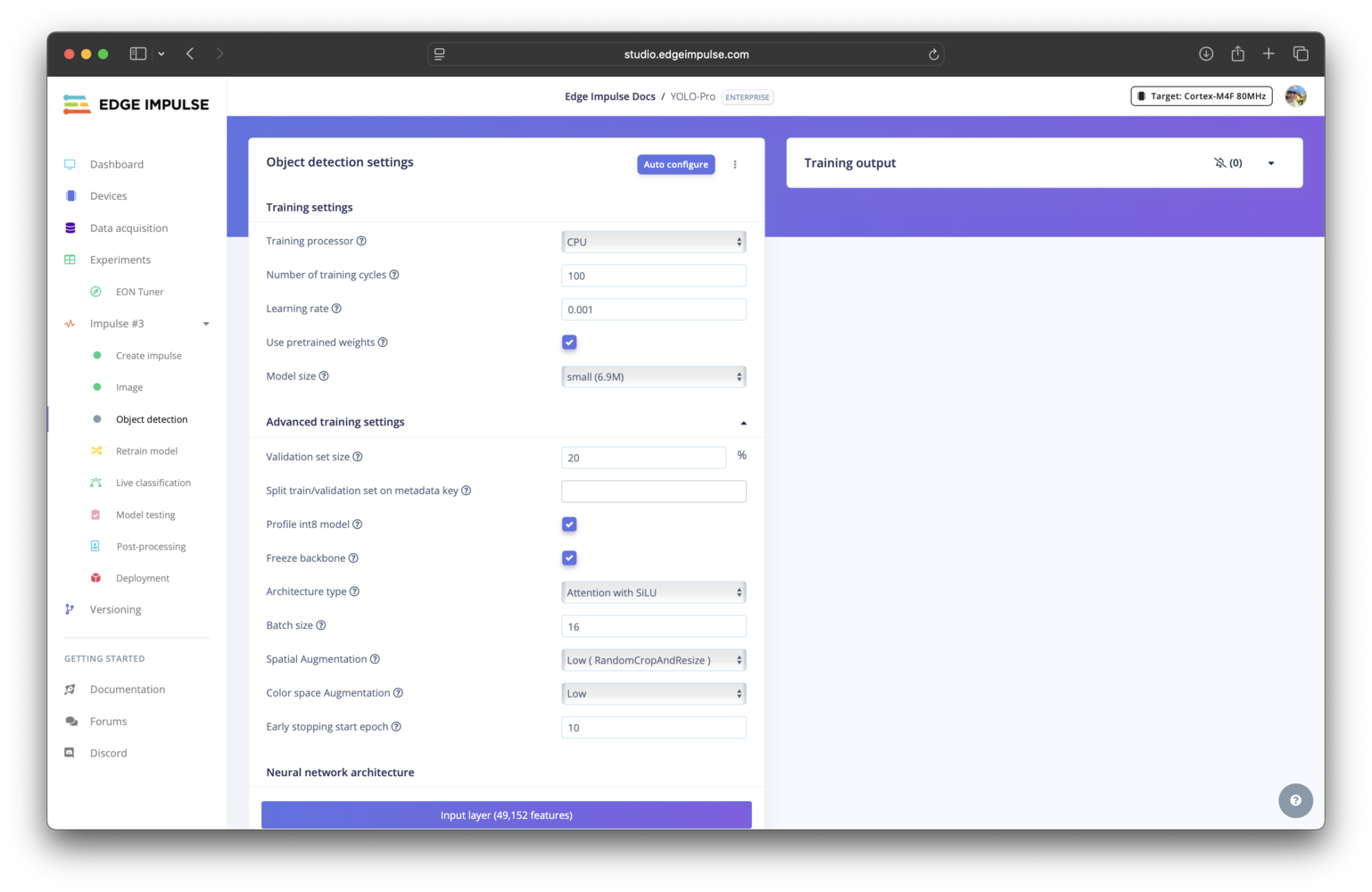
YOLO-Pro training settings
Model size
The table below shows approximate sizes for the YOLO-Pro models. To help you choose the appropriate model size for your edge hardware based on its available memory, there is anAuto configure button. You must first select your target device to use this functionality.
Use pre-trained weights
The YOLO-Pro models can use pre-trained weights or be trained from scratch. For most use cases, you will want to enable the use of pre-trained weights, as this will substantially reduce the amount of data and time required for training. If you have a very large dataset (e.g. 100,000+ images), disabling the use of pre-trained weights may lead to better model performance.Freeze backbone
Parameter is conditionally shownThe freeze backbone parameter is conditionally shown based on the selection for the use pre-trained weights parameter. It will be shown if the use pre-trained weights option is enabled.
Architecture type
Besides selecting the model size, there are two options for the architecture type:Attention with SiLU and No attention with ReLU. The two options are described below.
Attention with SiLU
The attention with SiLU option is the more traditional of the two, and is similar to many modern YOLO architectures. The final block of the backbone uses partial self-attention, and all convolutional blocks use SiLU as the activation function. This is the preferred option for most use cases, and is the default selection.No Attention with ReLU
The no attention with ReLU option is a custom variant developed by Edge Impulse. It has two key differences when compared to the attention with SiLU option. First, the backbone does not use partial self-attention. This choice was made because not all edge hardware is able to efficiently run the operations required in the attention layer. Secondly, all convolutional blocks use ReLU as the activation function since some edge hardware will run ReLU notably faster. This option is recommended when deploying to hardware that does not efficiently support attention layers or SiLU activations. It has been developed to provide a wider compatibility with edge hardware, but may not perform as well as the attention with SiLU option.Augmentation
The data used for training the YOLO-Pro models can be augmented using both spatial transformations and color space transformations. The transformations applied are from the KerasCV preprocessing layers. Spatial transformations change the locations of pixels but not their colors, whereas color transformations change pixel colors, but not their location. These can be used to tune augmentation based on the application. For example, a fixed camera use case may benefit from lower spatial transformations and color sensitive use cases may want no color space transformations.Spatial transformations
When spatial transformations are selected, the applied augmentation includes random flips, crops, resizes, shears, rotations, and mosaic. The table below shows the specific transformations for each spatial augmentation option.Color space transformations
When color space transformations are selected, the applied augmentation includes random transforms according to the method defined in RandAugment: Practical automated data augmentation with a reduced search space. The low, medium, and high level options correspond to increasing amounts of augmentation being applied.Early stopping start epoch
If an early stopping start epoch is set, early stopping conditions are ignored until that epoch is reached. This is used to allow the model to “settle in”. After that epoch, the early stopping callback is used. The early stopping condition is based on improvement of validation loss.Examples
In future, please see this section for a list of example projects that use YOLO-Pro.Troubleshooting
No common issues have been identified thus far. If you encounter an issue, please reach out on the forum or, if you are on the Enterprise plan, through your support channels.