How to use it
The GPT-4o model processes images and assigns labels based on the content, filtering out any images that do not meet the quality criteria.Step 1: Data Collection
Navigate to the Data acquisition page and add images to your project’s dataset. In the video tutorial above, we show how to collect a video recorded directly from a phone, upload it to Edge Impulse and split the video into individual frames.Step 2: Add the labeling block
In the Data sources tab, add the “Label image data using GPT-4o” block: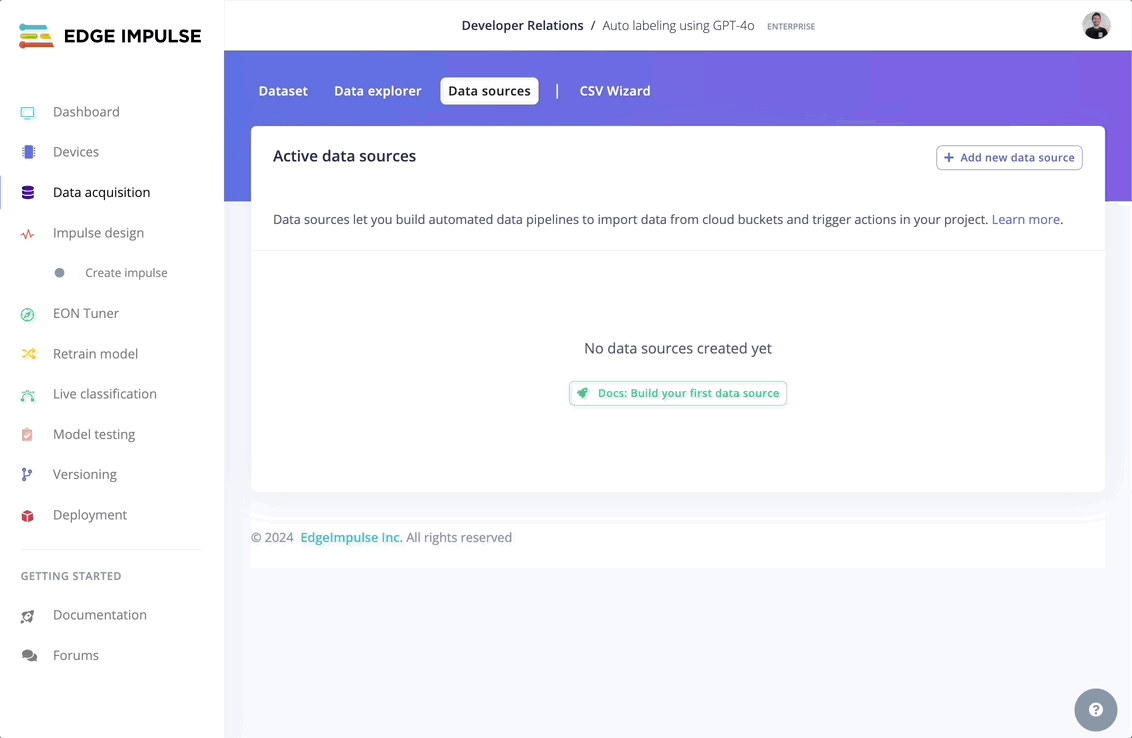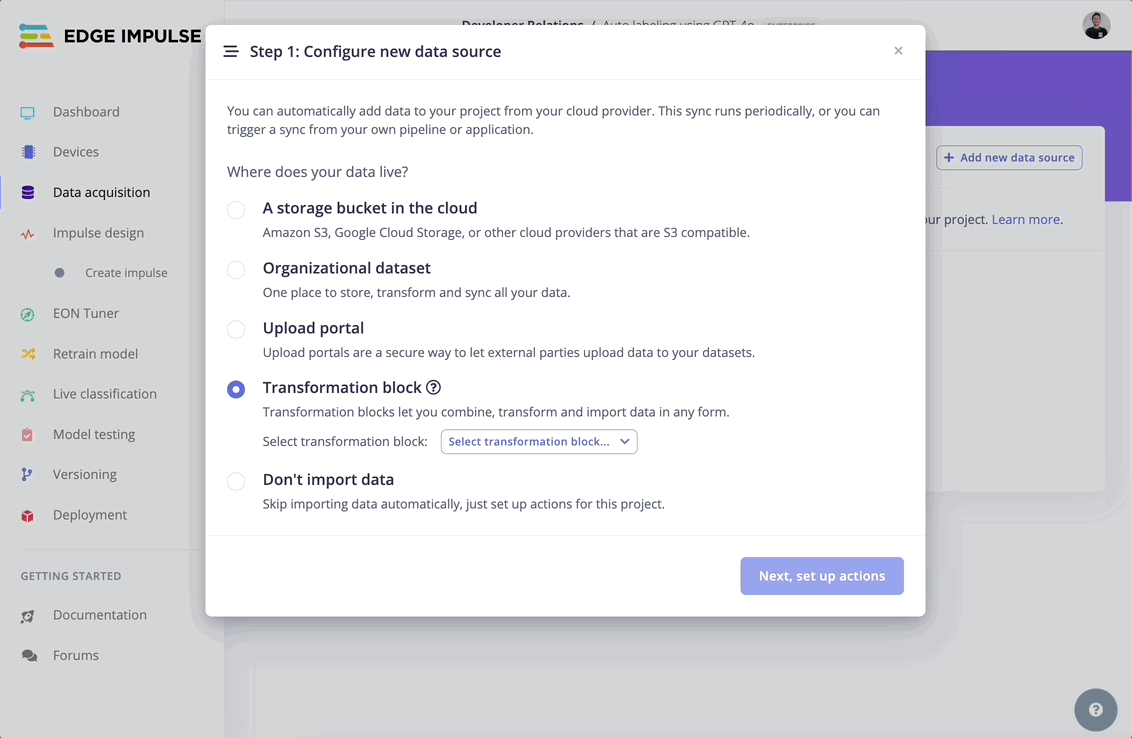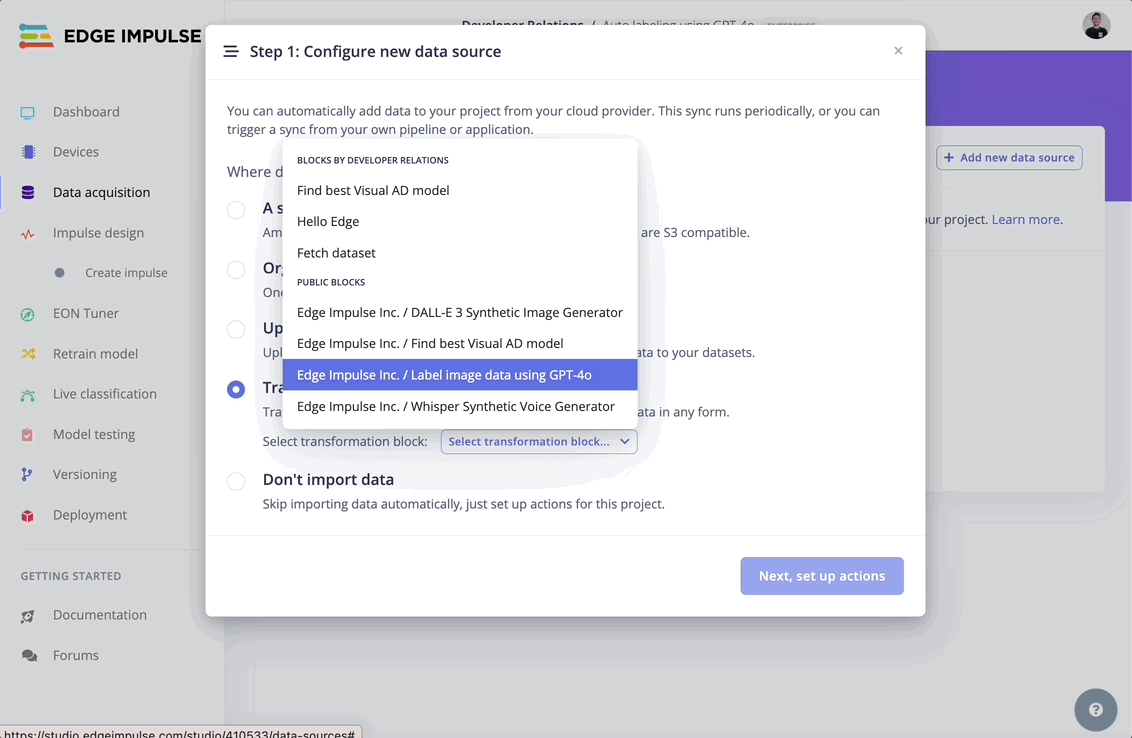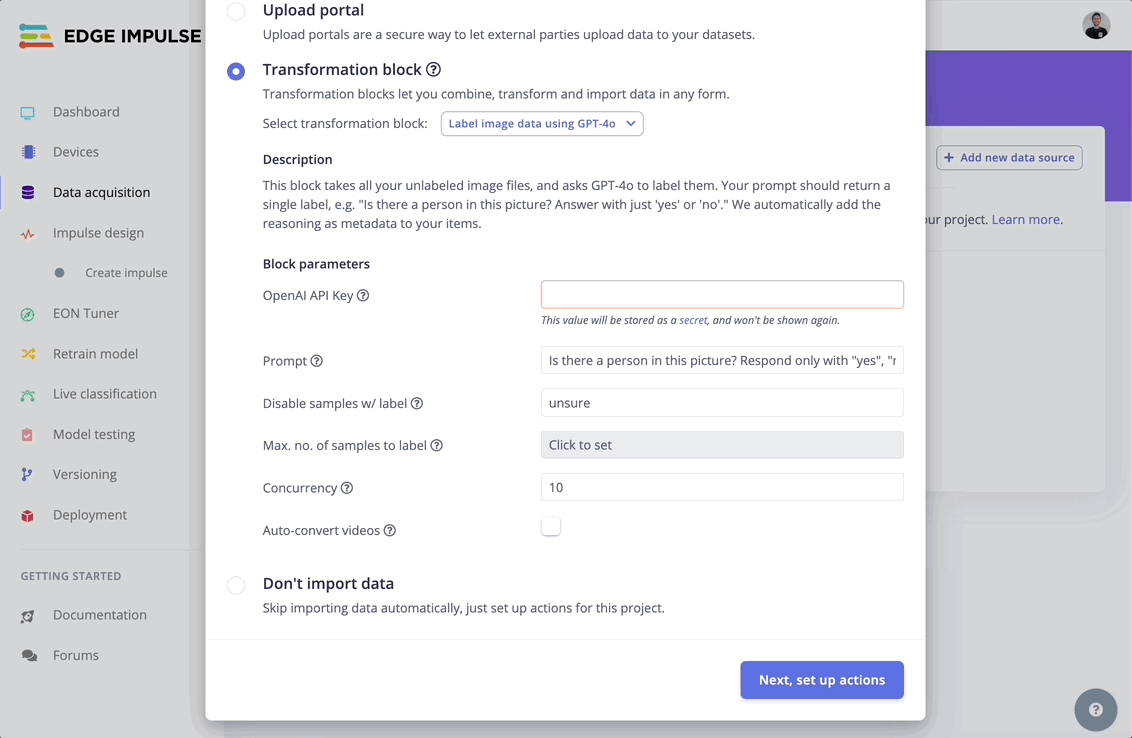
Add pre-built transformation block
Step 4: Configure the labeling block
- OpenAI API key: Add your OpenAI API key. This value will be stored as a secret, and won’t be shown again.
- Prompt: Your prompt should return a single label. For example:
- Disable samples w/ label: If a certain label is output, disable the data item - these are excluded from training. Multiple labels are accepted, separate them with a coma.
- Max. no. of samples to label: Number of samples to label.
- Concurrency: Number of samples to label in parallel.
- Auto-convert videos: If set, all videos are automatically split into individual images before labeling.
Optional: Editing your labeling block
To edit your configuration, you need to update the json-like steps of your block: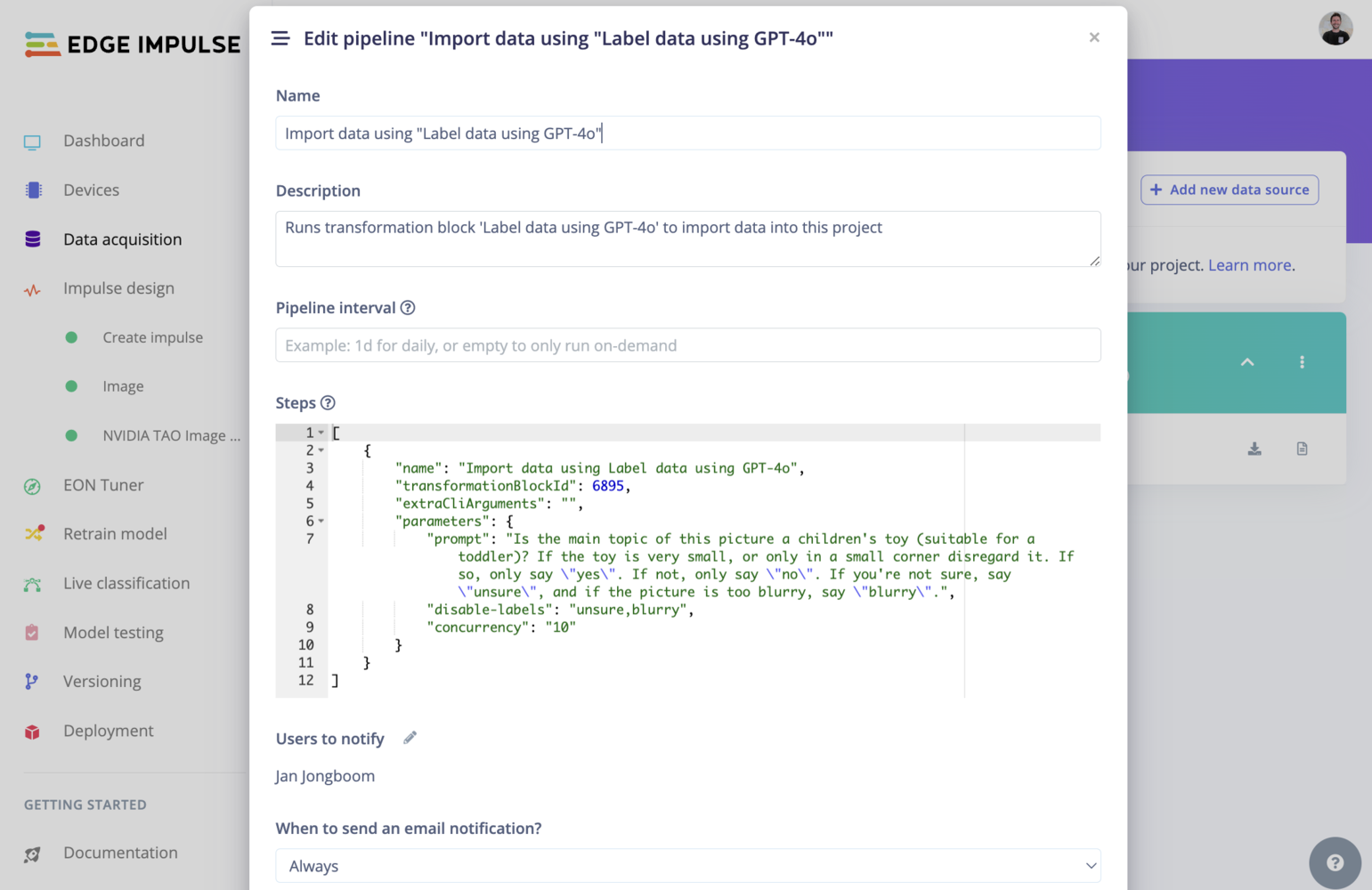
Edit block
Step 5: Execute
Then, run the block to automatically label the frames.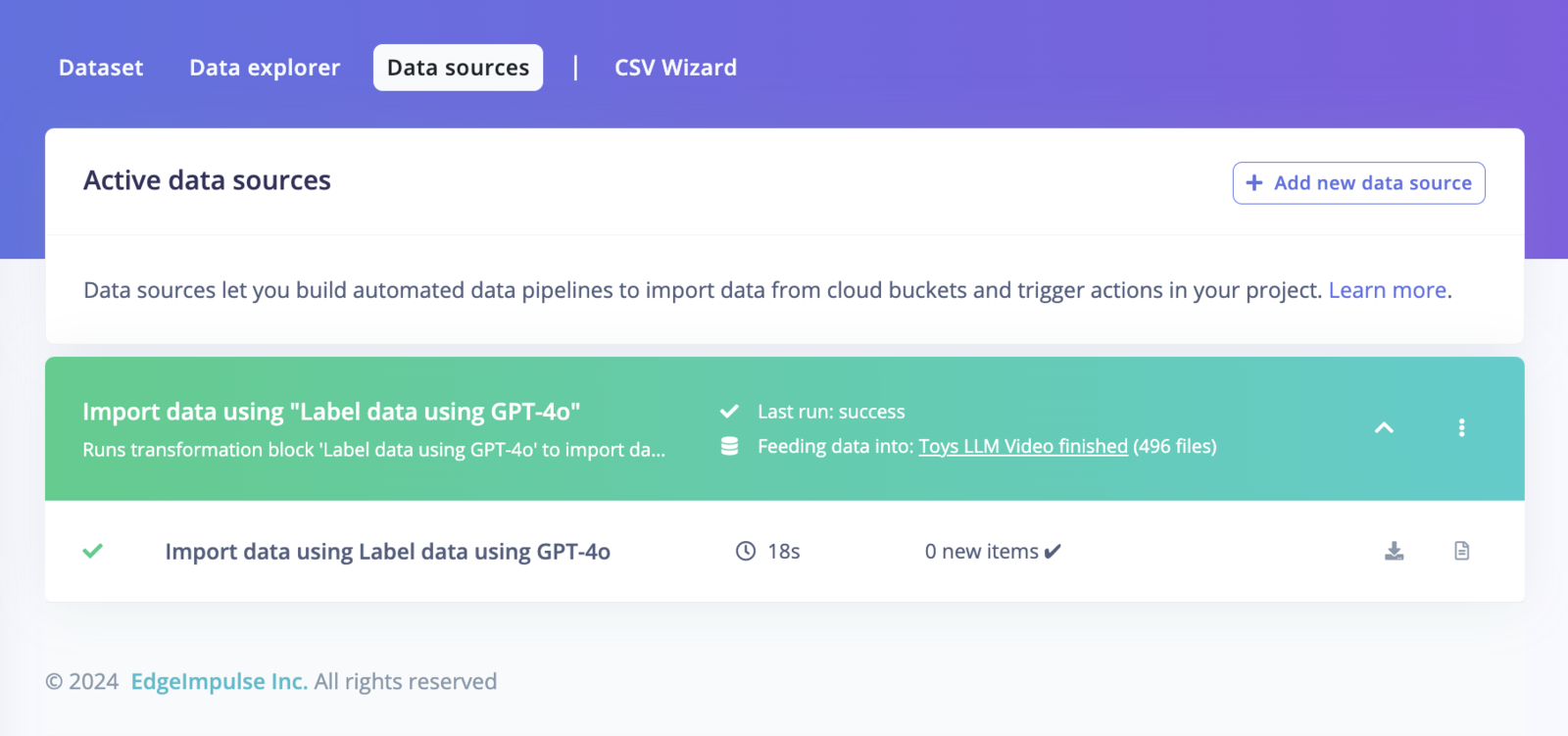
Job ran successfully
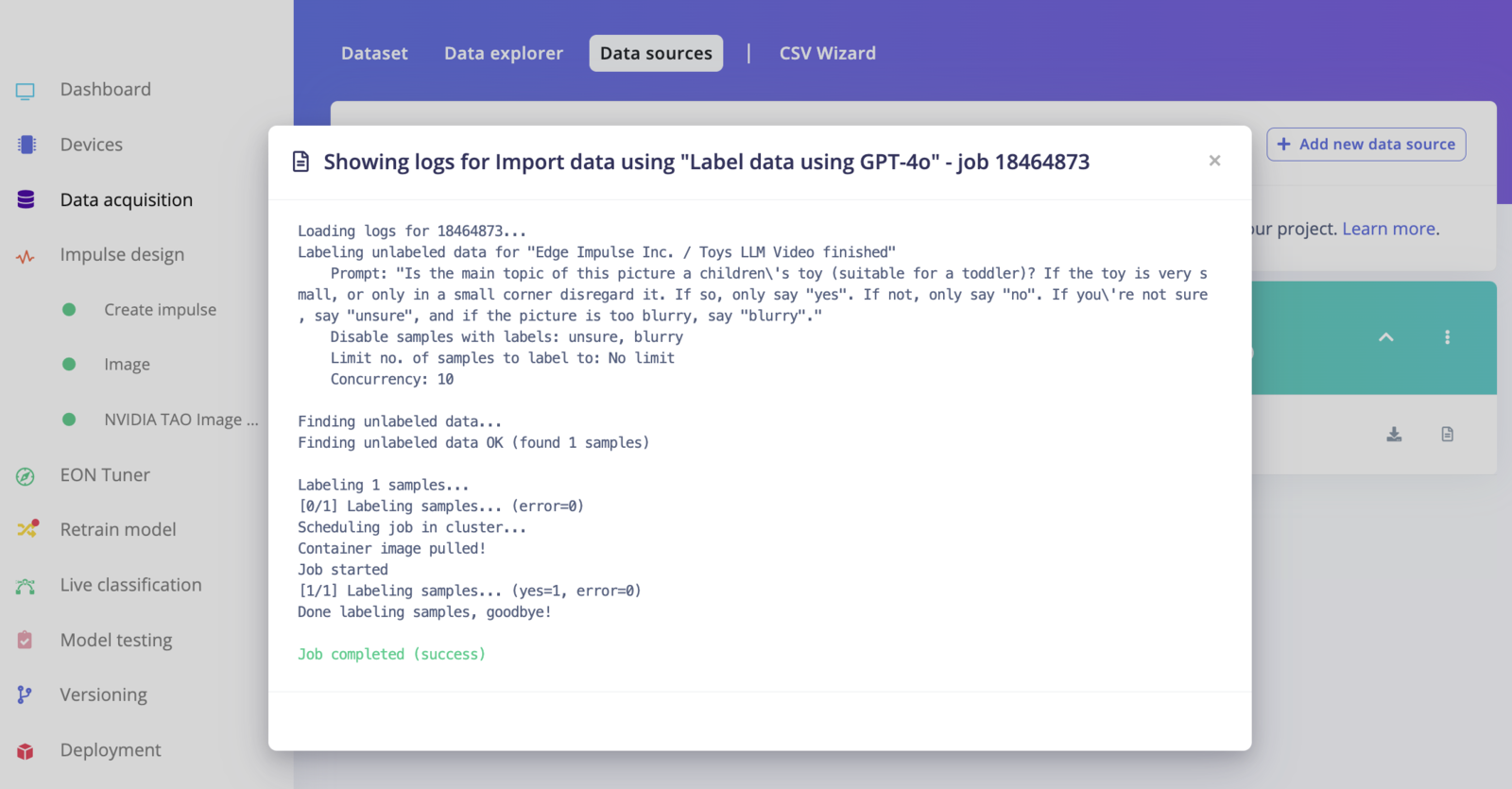
GPT-4o labeling block logs
Step 6: Train your model
Use the labeled data to train a machine learning model. See the end-to-end tutorial Image classification.Step 7: Deployment
In the video tutorial, we deployed the trained model to an MCU-based edge device - the Arduino Nicla Vision.Results
The small model we tested this on performed exceptionally well, identifying toys in various scenes quickly and accurately. By distilling knowledge from the large LLM, we created a specialized, efficient model suitable for edge deployment.Conclusion
The latest multimodal LLMs are incredibly powerful but too large for many practical applications. At Edge Impulse, we enable the transfer of knowledge from these large models to smaller, specialized models that run efficiently on edge devices. Our “Label image data using GPT-4o” block is available for enterprise customers, allowing you to experiment with this technology. For further assistance, visit our forum.Examples & Resources
- Blog post: Label image data using GPT-4o blog post