Data pipelines
Building data pipelines is a very useful feature where you can stack several transformation blocks similar to the Data sources pipelines. They can be used in a standalone mode (just execute several transformation jobs in a pipeline), to feed a dataset or to feed a project.
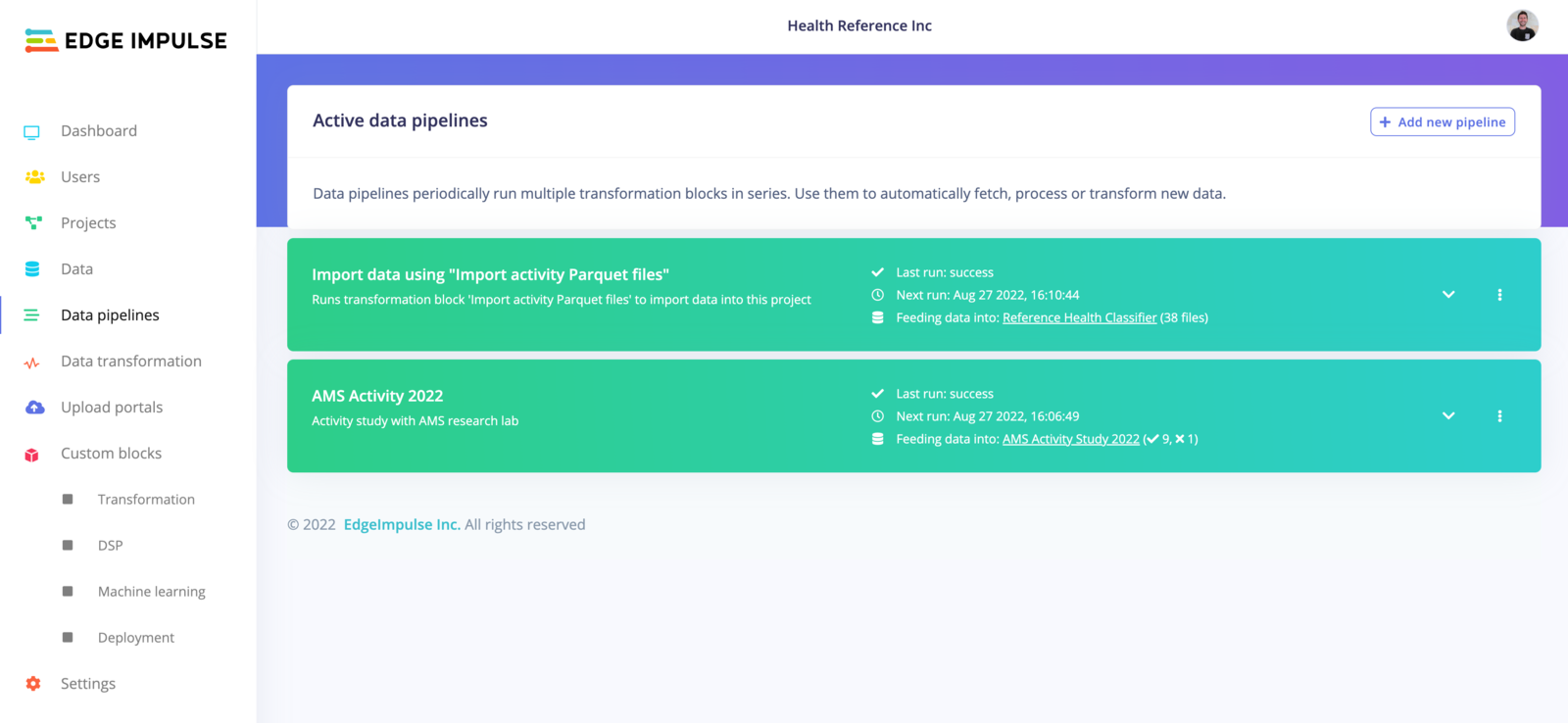 The examples in the screenshots below shows how to create and use a pipeline to create the ‘AMS Activity 2022’ dataset.
The examples in the screenshots below shows how to create and use a pipeline to create the ‘AMS Activity 2022’ dataset.
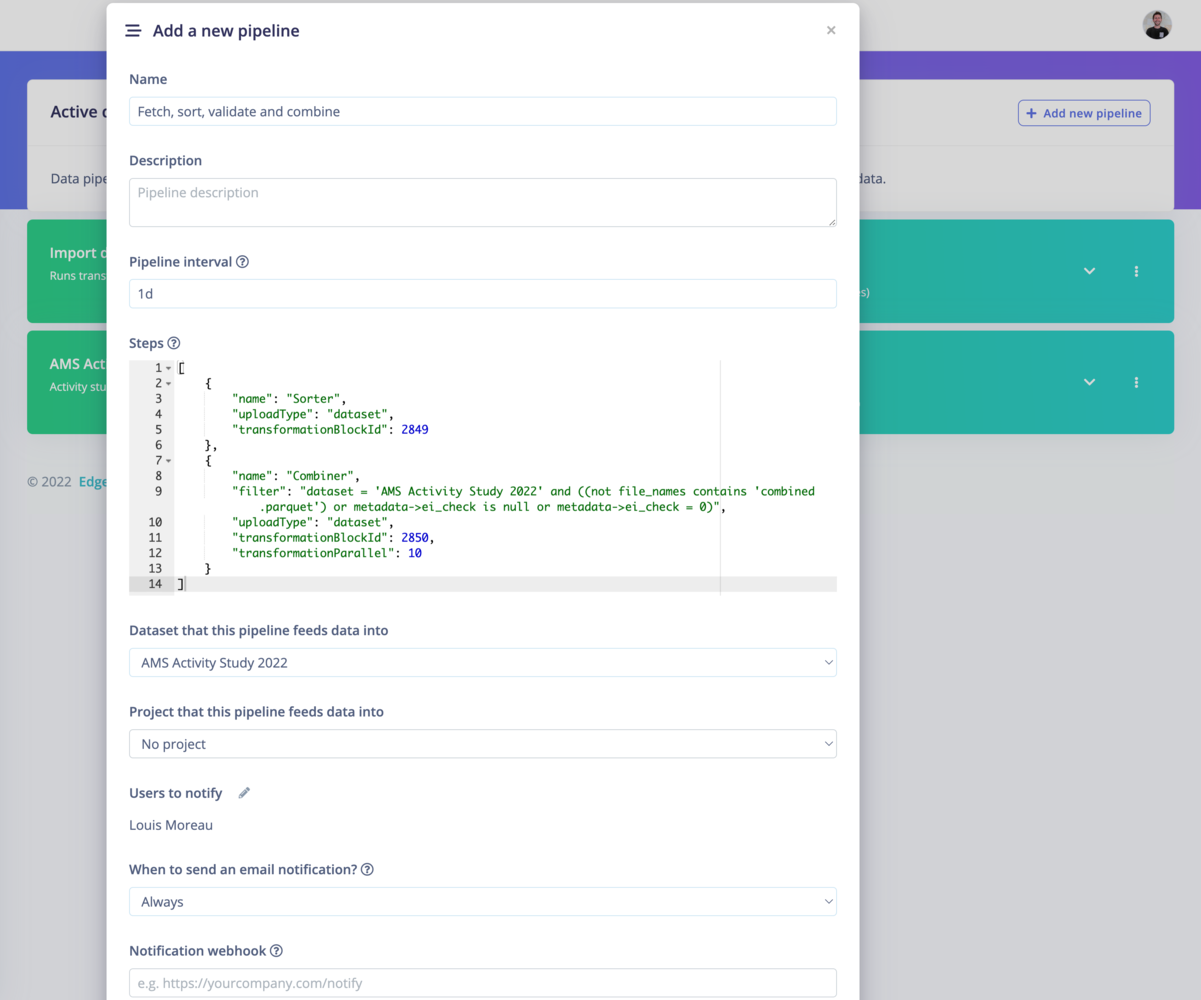
 Select Copy as pipeline step and paste it to the configuration json file.
Select Copy as pipeline step and paste it to the configuration json file.
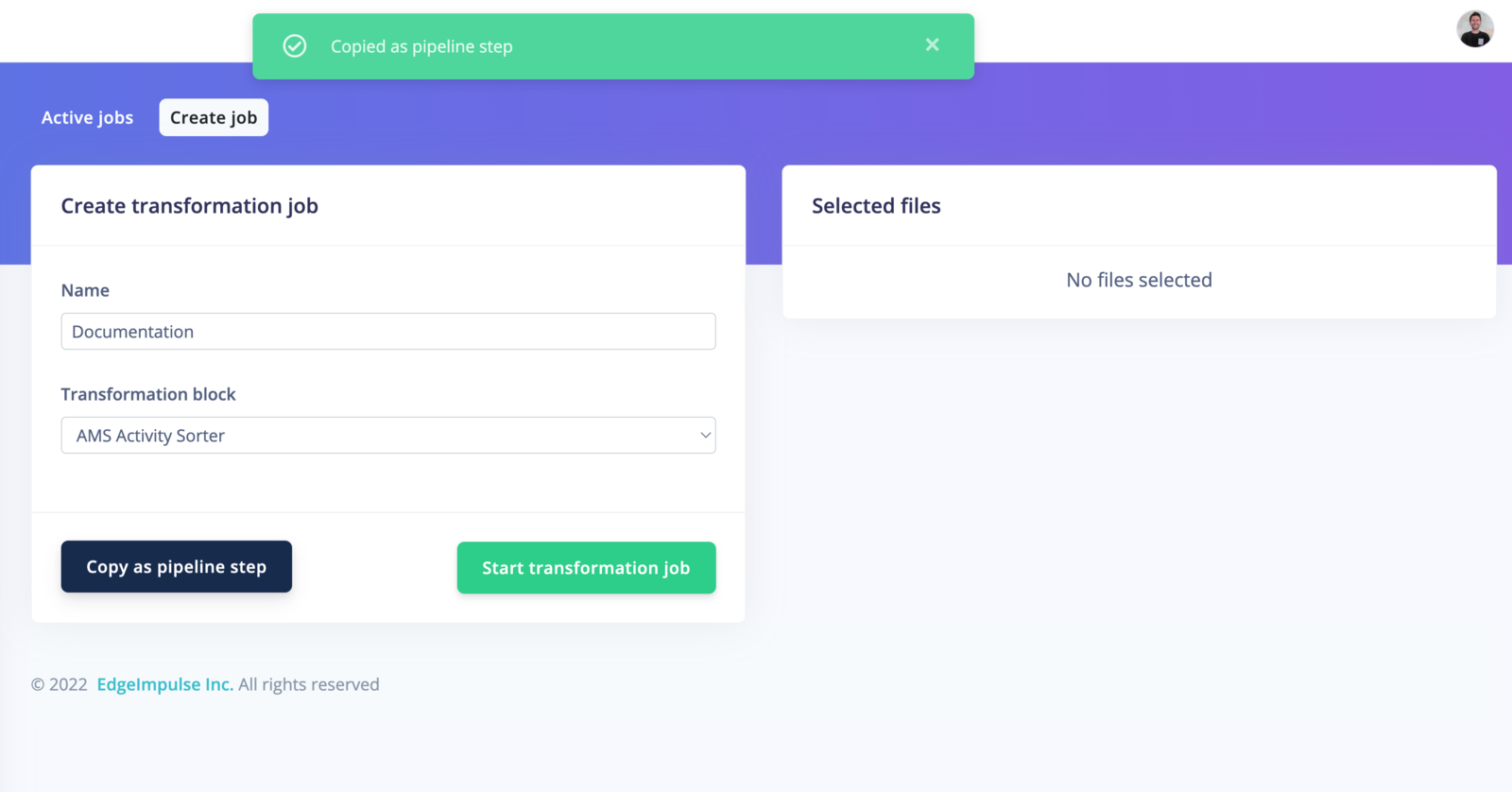 You can then paste the copied step directly to the respected field.
Below, you have an option to feed the data to either a organisation dataset or an Edge Impulse project
You can then paste the copied step directly to the respected field.
Below, you have an option to feed the data to either a organisation dataset or an Edge Impulse project
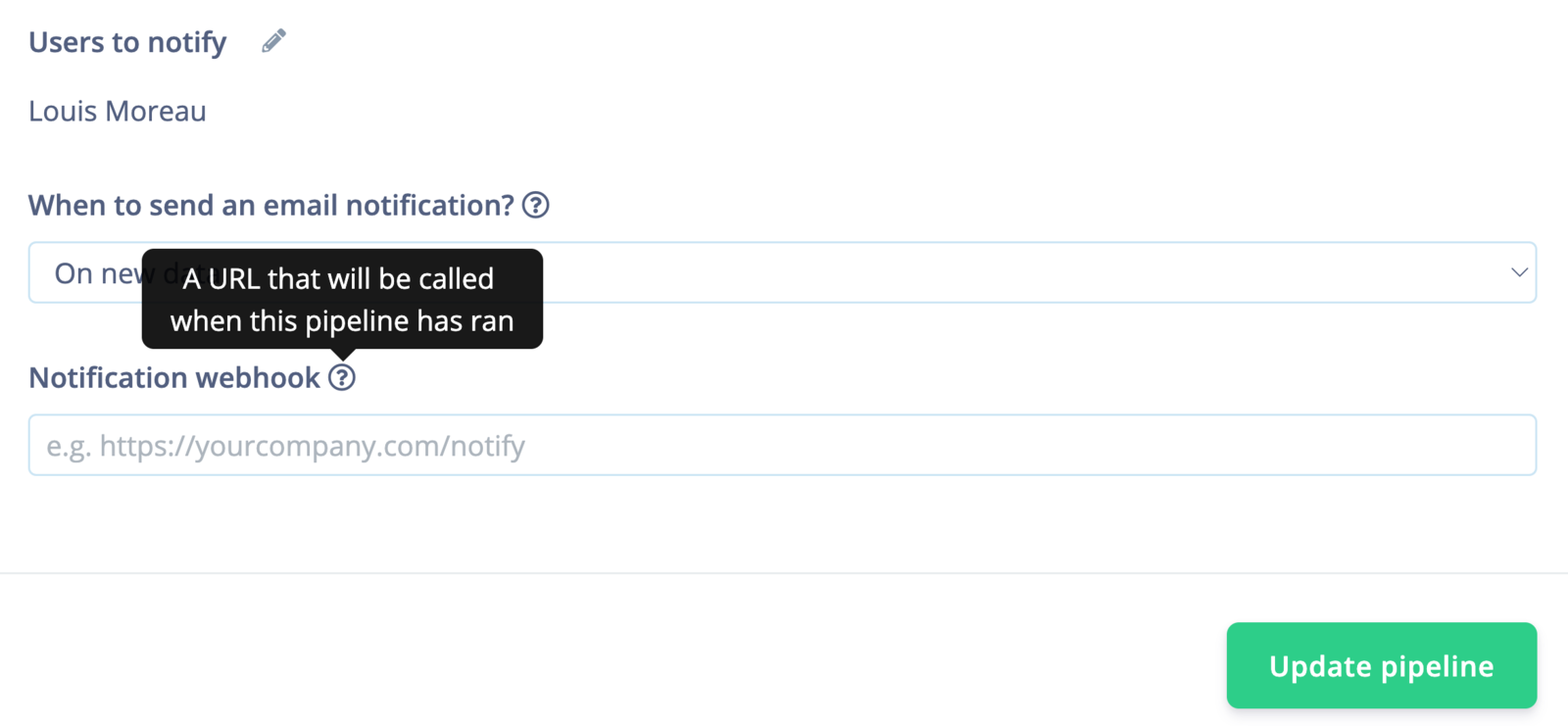
 Once the pipeline has successfully finished, it can send an email to the Users to notify.
Once the pipeline has successfully finished, it can send an email to the Users to notify.
clinical data pipelines example
Only available on the Enterprise planThis feature is only available on the Enterprise plan. Review our plans and pricing or sign up for our free Enterprise trial today.
Create a pipeline
To create a new pipeline, click on ‘+Add a new pipeline:Add a new clinical data pipeline
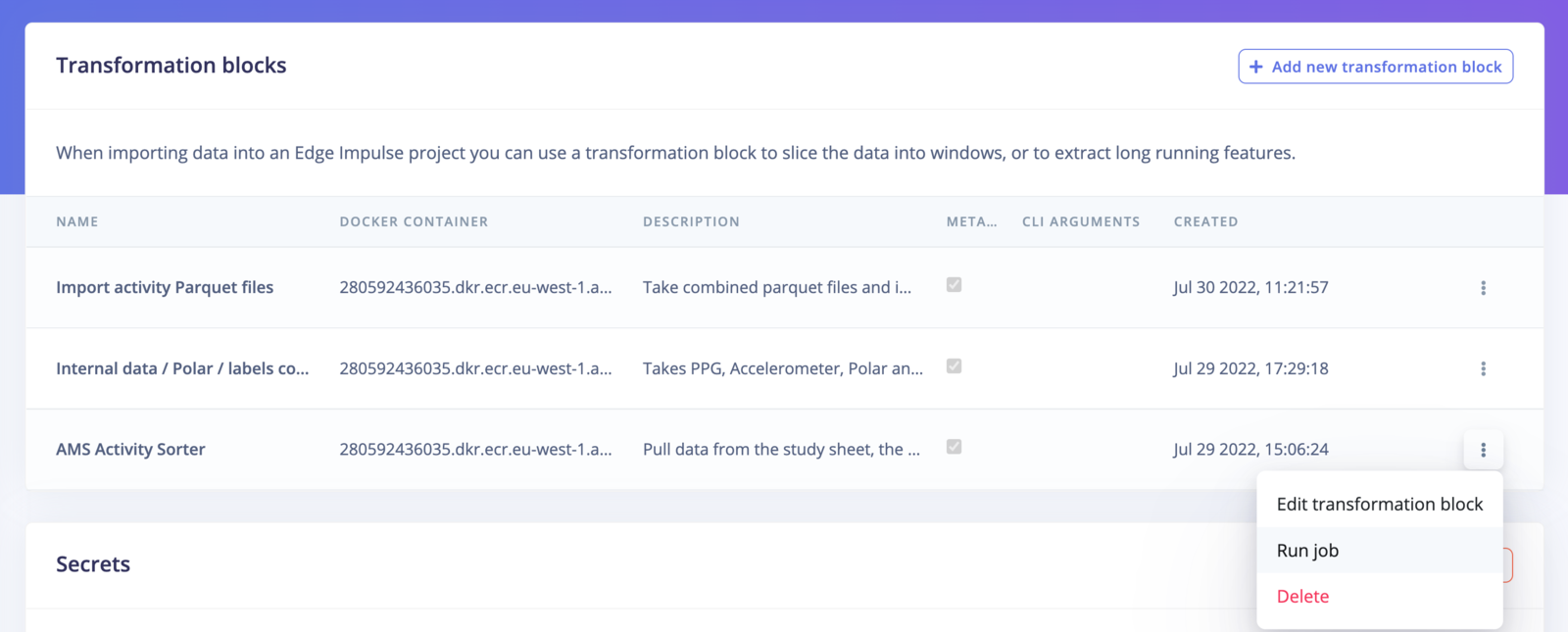
Get the steps from your transformation blocks
In your organization workspace, go to Custom blocks -> Transformation and select Run job on the job you want to add.Transformation blocks
Copy
Schedule and notify
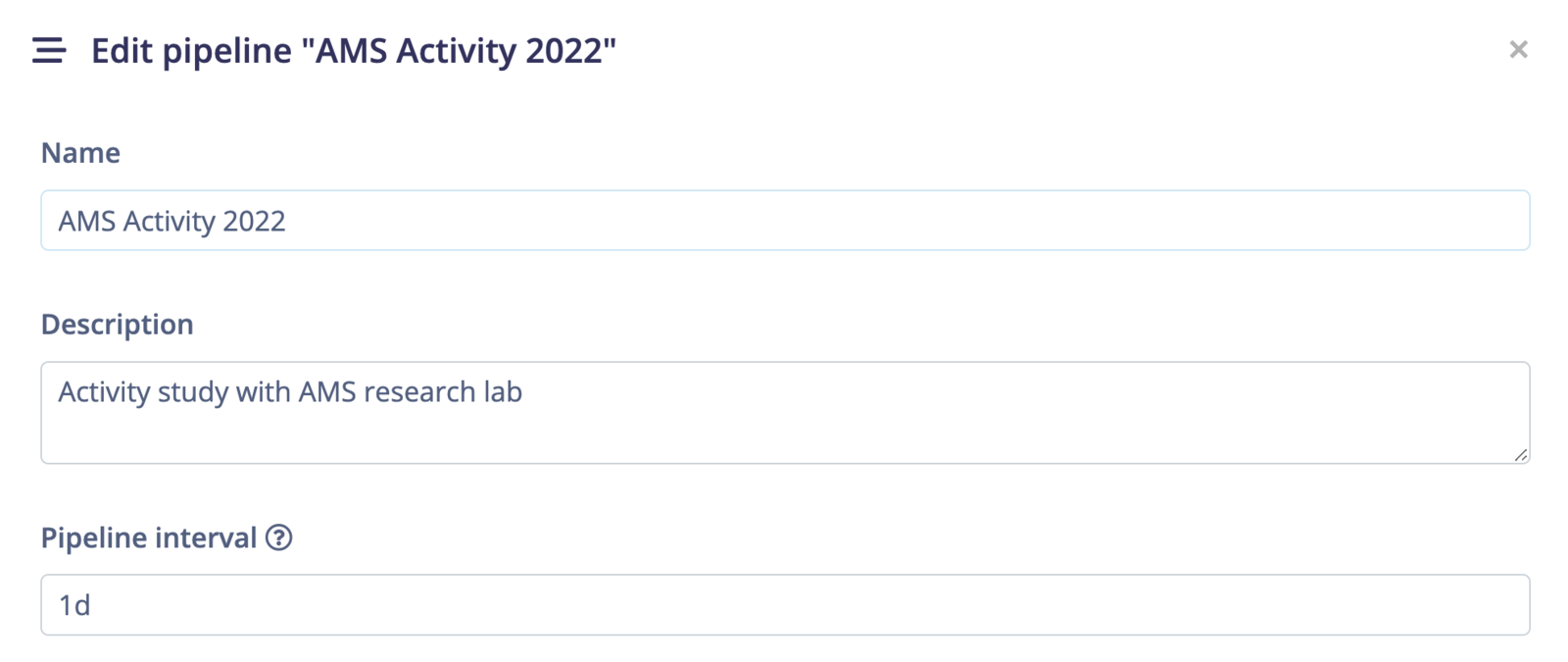
By default, your pipeline will run every day. To schedule your pipeline jobs, click on the⋮ button and select Edit pipeline.
Edit pipeline
Run the pipeline
Once your pipeline is set, you can run it directly from the UI, from external sources or by scheduling the task.Run the pipeline from the UI
To run your pipeline from Edge Impulse studio, click on the⋮ button and select Run pipeline now.
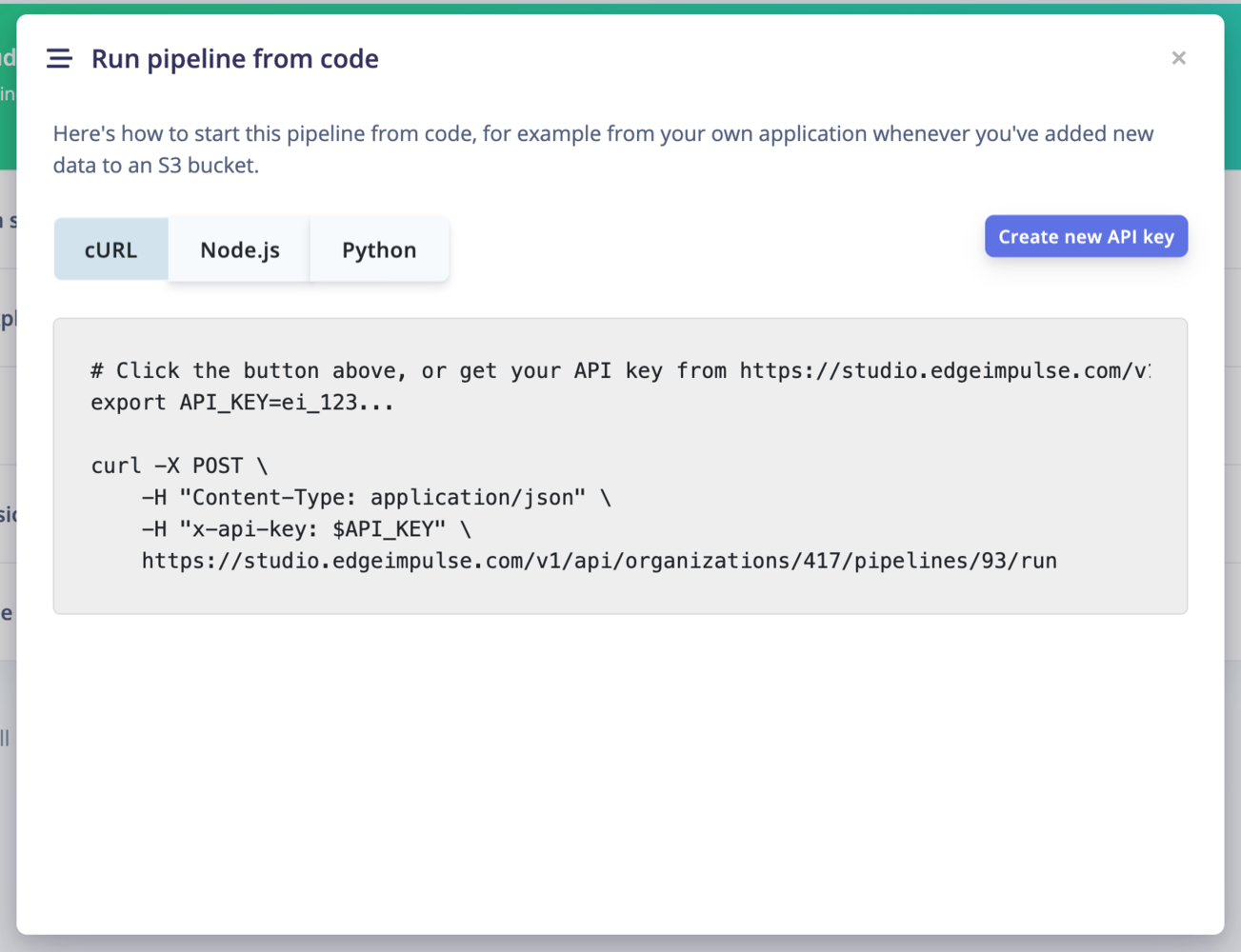
Run the pipeline from code
To run your pipeline from Edge Impulse studio, click on the⋮ button and select Run pipeline from code. This will display an overlay with curl, Node.js and Python code samples.
You will need to create an API key to run the pipeline from code.
Run the pipeline from code
Webhooks
Another useful feature is to create a webhook to call a URL when the pipeline has ran. It will run a POST request containing the following information:Data sources webhooks