An epoch (also known as training cycle) in machine learning is a term used to describe one complete pass through the entire training dataset by the learning algorithm. During an epoch, the machine learning model is exposed to every example in the dataset once, allowing it to learn from the data and adjust its parameters (weights) accordingly. The number of epochs is a hyperparameter that determines the number of times the learning algorithm will work through the entire training dataset.Documentation Index
Fetch the complete documentation index at: https://docs.edgeimpulse.com/llms.txt
Use this file to discover all available pages before exploring further.
Importance of epochs
The number of epochs is an important hyperparameter for the training process of a machine learning model. Too few epochs can result in an underfitted model, where the model has not learned enough from the training data to make accurate predictions. On the other hand, too many epochs can lead to overfitting, where the model has learned too well from the training data, including the noise, making it perform poorly on new, unseen data.When to change the number of epochs (training cycles)
Selecting the appropriate number of epochs is a balance between underfitting and overfitting.Underfitting: One of the most straightforward indicators of underfitting is if the model performs poorly on the training data. This can be observed in Edge Impulse Studio through metrics such as accuracy, or loss, depending on the type of problem (classification or regression). If these metrics indicate poor performance, it suggests that the model has not learned the patterns of the data well. In that case, increasing the number of epochs can improve your model performance. Please note that other solutions exist such as increasing your neural network architecture complexity, changing the preprocessing technique or reducing regularization.Overfitting: Detecting overfitting involves recognizing when the model has learned too much from the training data, including its noise and outliers, to the detriment of its performance on new, unseen data. Overfitting is characterized by the model performing exceptionally well on the training data but poorly on the validation or test data. Evaluating overfitting can be achieved by comparing the performance of the model between the training set and the validation set during training. When the performance on the validation set starts to degrade, it might indicate that the model is beginning to overfit the training data. In that case, decreasing the number of epochs can improve your model performance. As with underfitting, other solutions exist to reduce overfitting such as increasing the number of training data, adding regularization techniques to add penalties on large weights, adding dropout layers, simplifying the model architecture and even using early stopping.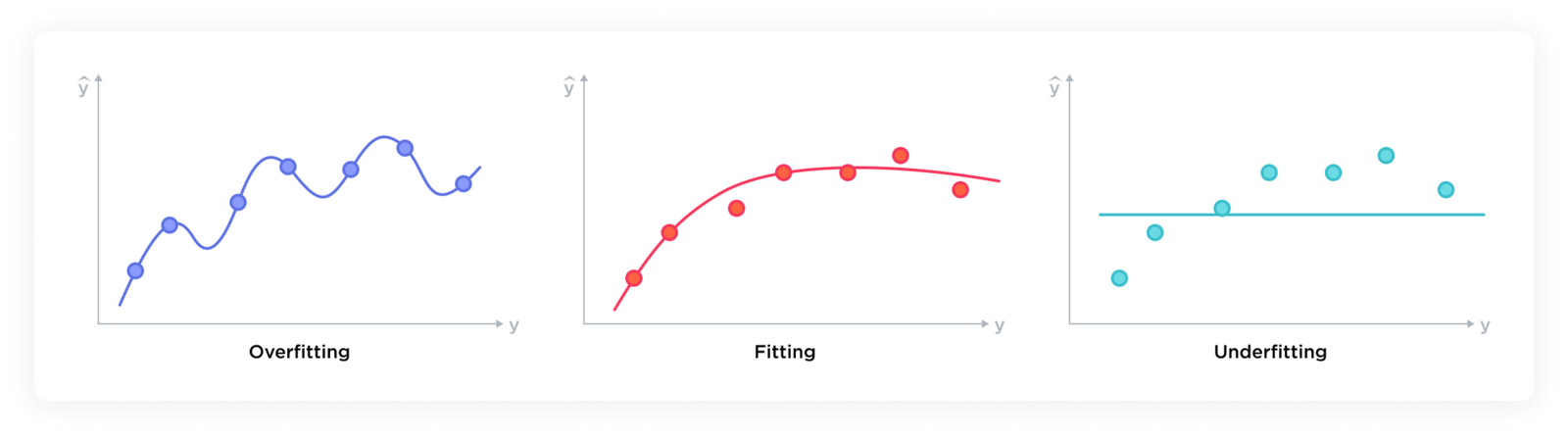
How epochs work
During each epoch, the dataset is typically divided into smaller batches. This approach, known as batch training, allows for more efficient and faster processing, especially with large datasets. The learning algorithm iterates through these batches, making predictions, calculating errors, and updating model parameters using an optimizer. An epoch consists of the following steps: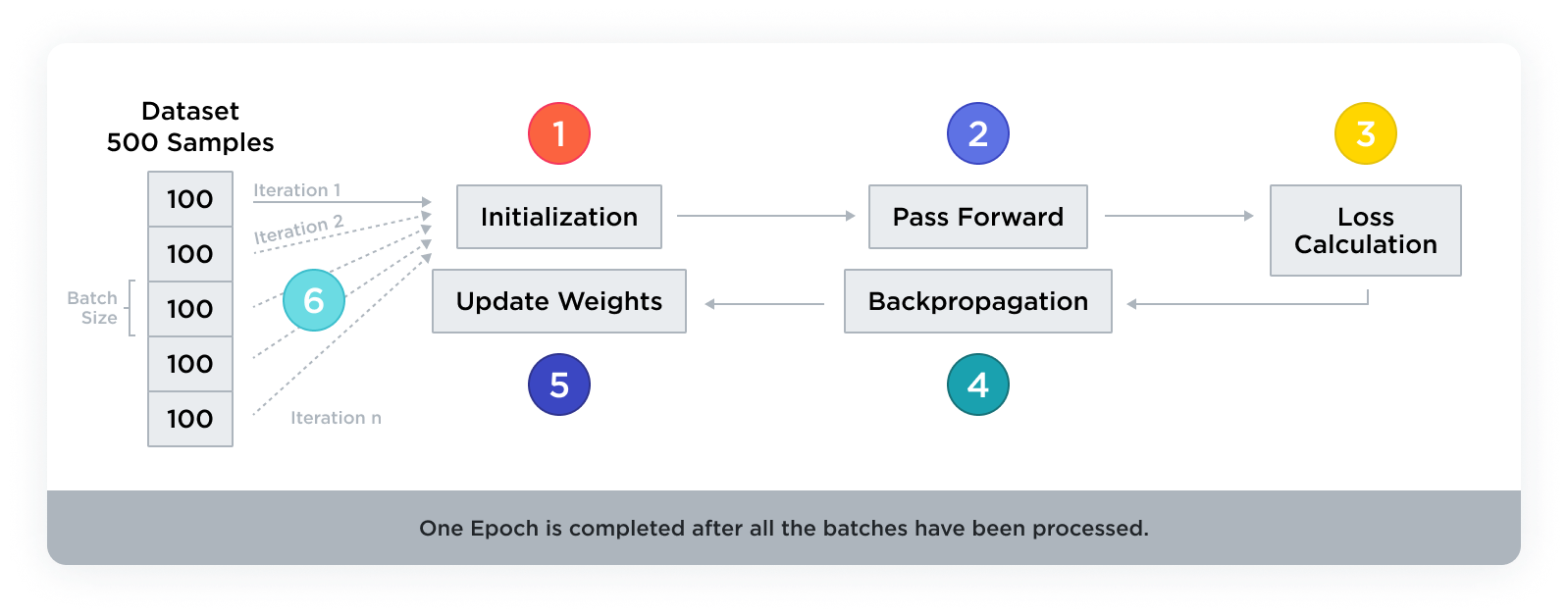
- Initialization: Before training begins, the model’s internal parameters (weights) are typically initialized randomly or according to a specific strategy.
- Forward pass: For each example in the training dataset, the model makes a prediction (forward pass). This involves calculating the output of the model given its current weights and the input data.
- Loss calculation: After making a prediction, the model calculates the loss (or error) by comparing its prediction to the actual target value using a loss function. The loss function quantifies how far the model’s prediction is from the target.
- Backward pass (backpropagation): The model updates its weights to reduce the loss. This is done through a process called backpropagation, where the gradient of the loss function of each weight is computed. The gradients indicate how the weights should be adjusted to minimize the loss.
- Weight update: Using an optimization algorithm (such as Gradient Descent, Adam, etc.), the model adjusts its weights based on the gradients calculated during backpropagation. The goal is to reduce the loss by making the model’s predictions more accurate.
- Iteration over batches: An epoch consists of iterating over all batches in the dataset, performing the forward pass, loss calculation, backpropagation, and weight update for each batch.
- Completion of an epoch: Once the model has processed all batches in the dataset, one epoch is complete. The model has now seen each example in the dataset exactly once.
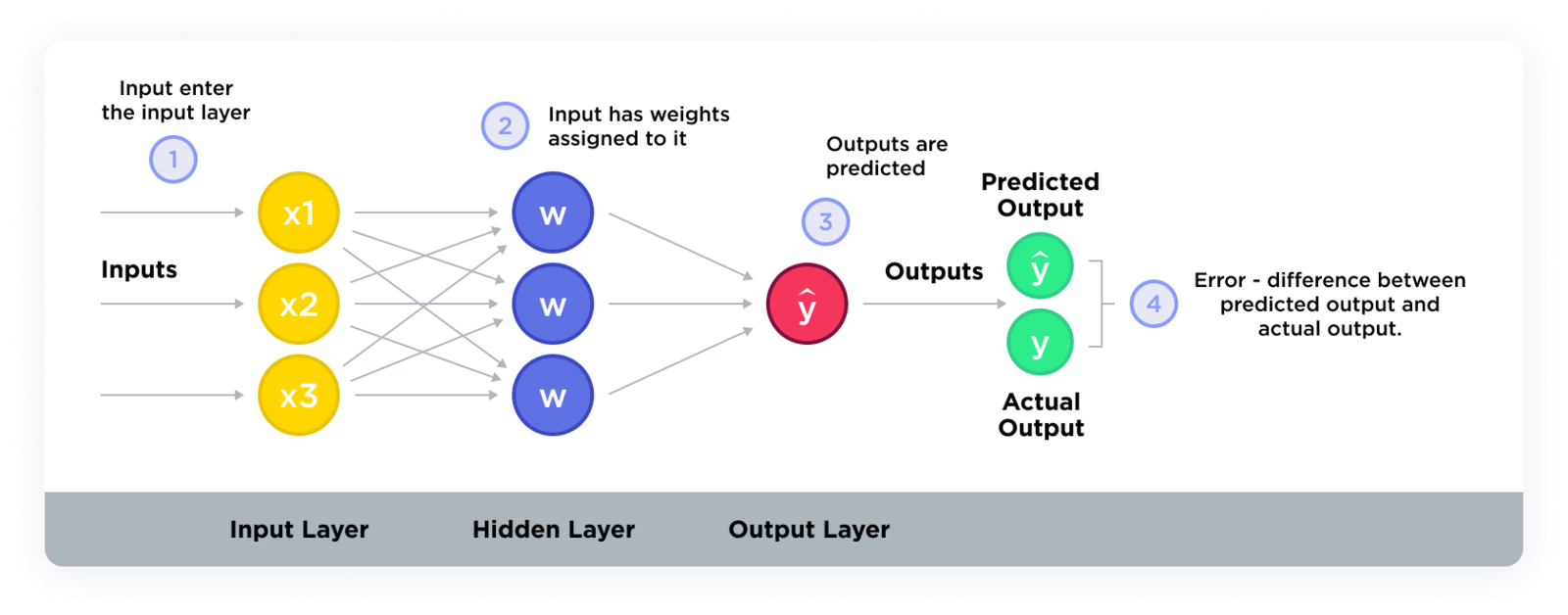
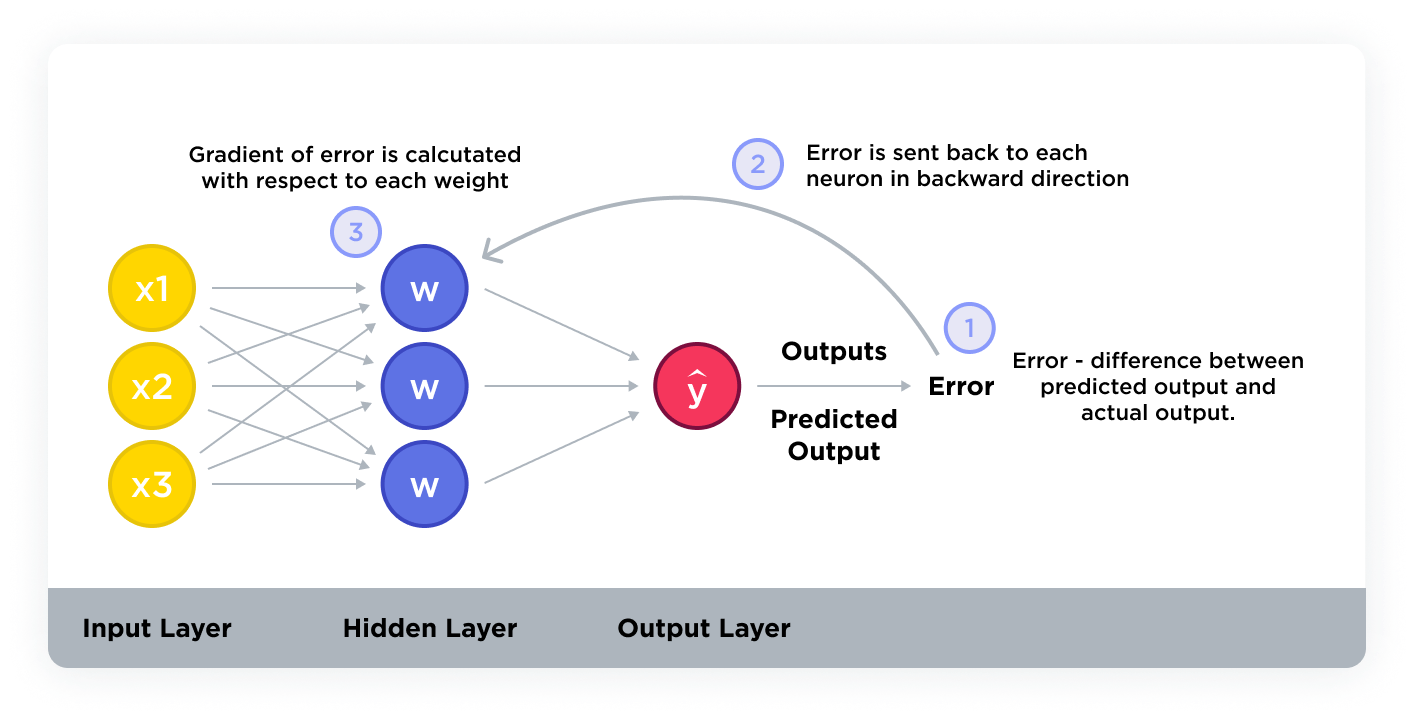
What’s the difference between an epoch and a batch size?
When training neural networks, both epochs and batch sizes are fundamental concepts, yet they serve distinct roles in the training process. An epoch represents one complete pass through the entire training dataset, where the model has the opportunity to learn from every example within the dataset once. This means that if you set the training to run for, say, 10 epochs, the entire dataset will be passed through the neural network 10 times, allowing the model to refine its weights and biases to improve its accuracy with each pass.On the other hand, the batch size refers to the number of training examples utilized in one iteration of the training process. Instead of passing the entire dataset through the network at once (which can be computationally expensive and memory-intensive), the dataset is divided into smaller batches. For example, if you have a dataset of 2000 examples and choose a batch size of 100, it would take 20 iterations (batches) to complete one epoch. The batch size affects the updating of model parameters; with smaller batch sizes leading to more frequent updates, potentially increasing the granularity of the learning process but also introducing more variance in the updates. Conversely, larger batch sizes provide a more stable gradient estimate, but with less frequent updates, it could lead to slower convergence.Change the number of epochs in Edge Impulse
In Edge Impulse, you can specify the number of training cycles in the training settings for your neural network-based models. Adjusting this parameter allows you to fine-tune the training process, aiming for the best possible model performance on your specific dataset. It’s important to monitor both training and validation loss to determine the optimal number of epochs for your model.Changing the epochs in Expert Mode
When using the Expert Mode in Edge Impulse, you can access the full Keras API: You can modify the following line in the expert mode to change the number of training cycles:model.fit() function as follows:
Apply Early Stopping in Expert Mode
The following approach allows your model to stop training as soon as it starts overfitting, or if further training doesn’t lead to better performance, making your training process more efficient and potentially leading to better model performance. ImportEarlyStopping from tensorflow.keras.callbacks.
EarlyStopping callback, specifying the metric to monitor (e.g., val_loss or val_accuracy), the minimum change (min_delta) that qualifies as an improvement, the number of epochs with no improvement after which training will be stopped (patience), and whether training should stop immediately after improvement (restore_best_weights).