Skip to main contentEdge machine learning operations (MLOps) is the set of practices and techniques used to automate and unify the various parts of machine learning (ML), system development (dev), and system operation (ops) for edge deployments. Such activities include data collection, processing, model training, deployment, application development, application/model monitoring, and maintenance. Edge MLOps follows many of the same principles of MLOps but with a focus on edge computing.
In the previous section, we discussed the edge AI lifecycle. We will build on that knowledge by examining how to monitor model performance in the field and how to automate various parts of the lifecycle.
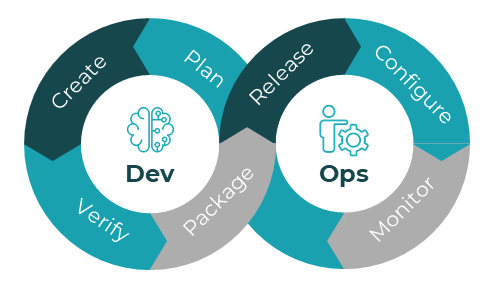
DevOps
DevOps is the collaboration between software development teams and IT operations to formalize and automate various parts of both cycles in order to deliver and maintain software.
In this cycle, the software development team works with management and business teams to identify requirements, plan the project, create the required software, verify the code, and package the application for consumption. In many instances, this packaged software is simply “thrown over the fence” to the operations team to manage the release, which consists of pushing the software to users, configuring and installing the software for users, and monitoring the deployment for any issues.
The concept of DevOps comes into play when these two teams work together to ensure smooth delivery and operation of the software. Many aspects of the packaging and delivery can be automated in a process known as continuous integration and continuous delivery (CI/CD). Any problems or maintenance needs can be identified by the operations team and fed back to the development team for fixes and improvements in future releases.
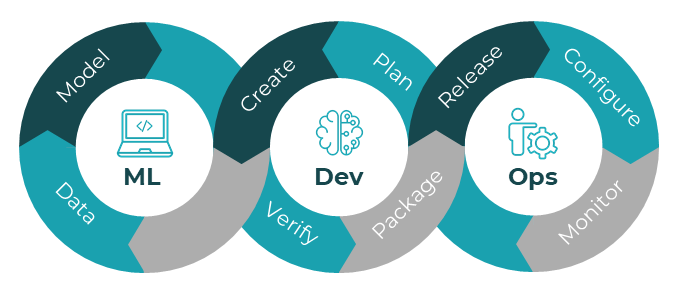
MLOps
Machine learning operations extends the DevOps cycle by adding the design and development of ML models into the mix.
Data collection, model creation, training, and testing is added to the flow. The machine learning team must work closely with the software development and operations teams to ensure that the model meets the needs of the customer and can operate within the parameters of the application, hardware, and environment.
For cloud-based deployments, the application may be a simple prediction serving web interface, or the model may be fully integrated into the application. In most edge AI deployments, an application is built around the model, as inference is often performed locally on the edge device.
Building frameworks for inter-team operation and lifecycle automation offers a number of benefits:
- Shorter development cycles and time to market
- Increased reliability, performance, scalability, and security
- Standardized and automated model development/deployment frees up time for developers to tackle new problems
- Streamlined operations and maintenance (O&M) for efficient model deployment
Team effort
In most cases, implementing an edge MLOPs framework is not the work of a single person. It involves the cooperation of several teams. These teams can include some of the following experts:
- Data scientists - analyze raw data to find patterns and trends, create algorithms and data models to predict outcomes (which can include machine learning)
- Data engineers - build systems to collect, manage, and transform raw data into useful information for data scientists, ML researchers/engineers, and business analysts
- ML researchers - similar to data scientists, they work with data and build mathematical models to meet various business or academic needs
- ML engineers - build systems to train, test, and deploy ML models in a repeatable and robust manner
- Software developers - create computer applications and underlying systems to perform specific tasks for users
- Operations specialists - oversee the daily operation of network equipment and software maintenance
- Business analysts - form business insights and market opportunities by analyzing data
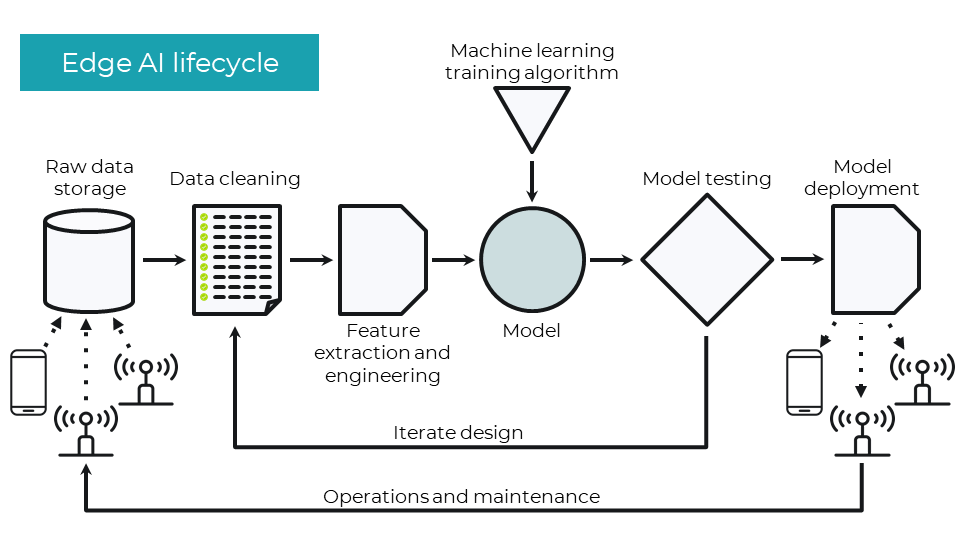
Edge AI lifecycle
The edge AI lifecycle consists of the steps required to collect data, clean that data, extract required features, train one or more ML models, test the model, deploy the model, and perform necessary maintenance. Note that these steps do not include some of the larger project processes of identifying business needs and creating the application around the model.
In edge MLOps we can automate many of these steps to make the flow through this process easier and without human intervention.
Principles
Edge MLOps is built on three main principles: version control, automation, and governance.
Version control
In software development, the ability to track code versions and roll back versions is incredibly important. It goes beyond simply “saving a copy,” as it allows you to create branches to try new features and merge code from other developers. Tools like git and GitHub offer fantastic version control capabilities.
While these tools can be used for files and data beyond just code, they are mostly focused on text-based code. Versioning data can be tricky, as the storage requirements increases with the amount of data. You likely also want to version various ML pipelines in addition to the training/testing code and model itself.
Edge Impulse offers the ability to version control individual blocks as well as your entire project and pipeline.
Automation
Automating anything requires an initial, up-front investment to build the required processes and software. In cases where you need to use that process multiple times, such automation can pay off in the long run. Setting up automated tasks is a crucial step in edge MLOps, as it allows your teams to work on other tasks once the automation is built.
Almost anything in the edge AI lifecycle can be automated, including data collection, data cleaning, model training, and deployment. These often fall into one of the following categories:
- Continuous collection - Data collection happens continuously or triggered by some event.
- Continuous training - Feature extraction and model training/testing can occur autonomously.
- Continuous integration - Any code changes checked into a repository can trigger a series of unit and system tests to ensure correct operation before the code is merged into the main application.
- Continuous delivery - Software is created in short cycles and can be reliably released to users on a continuous basis as needed. Some deployment steps in this stage can be automated.
- Continuous monitoring - Automated tools are used to monitor the performance and security of an application or system to detect problems early to mitigate risks.
The development teams can decide how such automated processes are triggered. Examples of triggers include:
- User-requested - the user makes a request to update or rebaseline the model
- Time - one or more steps in the lifecycle can be executed on a set schedule, such as once per day or once per month
- Data changes - the presence of newly collected data can trigger a new lifecycle execution to clean the data, train a model, and deploy the model
- Code change - a new version of the application might necessitate a new model and thus trigger any of the collection, cleaning, training, testing, or deployment processes
- Model monitoring - issues with deployed models (such as model drift) might require any or all of the lifecycle to execute in order to update the model
Governance
Part of edge MLOps includes ensuring that your data and processes adhere to best practices and complies with any necessary regulations. Such regulations might include data privacy laws, such as HIPAA and GDPR. Similar rules are currently being enacted around AI, such as the EU AI act. Be sure to become familiar with any potential governing regulations around data, privacy, and AI! The rules can vary by country and specific technology usage (e.g. medical vs. consumer electronics).
In addition to adhering to laws, you should check for fairness and bias in your data and model. Bias can come in many different forms and greatly impact your resulting model. The popular computer science phrase garbage in, garbage out applies here: if you train a model on biased data, the model will reflect that bias.
Finally, like with any computer system, you should design and implement best security practices to ensure:
- Confidentiality to protect sensitive data from unauthorized access
- Integrity to guarantee that data has not been altered
- Availability of data to authorized users when needed
Machine learning can involve lots of (potentially personal) data that you must use and control carefully. Edge computing devices should also be secured to limit potential intrusion risks. For digging deeper into security, we recommend checking out CISA’s guides on best practices and Amazon’s ultimate IoT security best practices guide. Hiring or consulting with a cybersecurity expert is also highly advised.
As a good steward of AI, it is your responsibility to ensure that your systems comply with laws and regulations, data and models are free from bias, and devices are secured from unauthorized access.
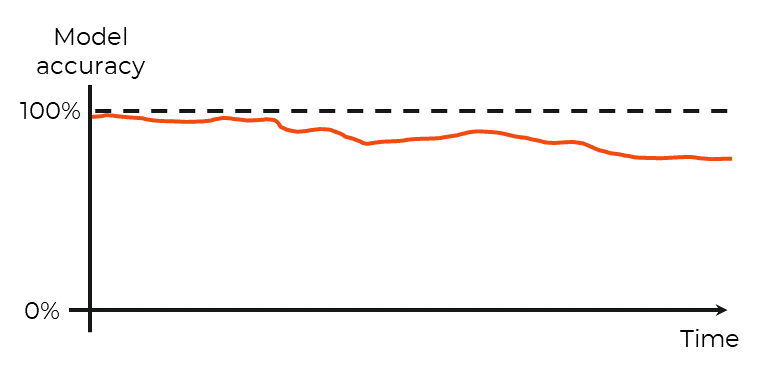
Model drift
Model drift occurs when an ML model’s loses accuracy over time. This can happen over the course of days or years.
In reality, the model does not lose accuracy. Instead, the data being fed to the model or the relationships that data represents in the physical world change over time. Such drift can be placed into two categories:
- Data drift occurs when the incoming data skews from the original training/test datasets. For example, the operating environment may change (e.g. collecting data on a machine in winter and expecting inference to work the same during the summer).
- Concept drift happens when the relationship between the input data and target changes. For example, spammers discover a new tactic to outwit spam filters. The spam filters are still accurate, but only on older methods.
One way to combat model drift is to consistently monitor the model’s performance over a period of time. If the accuracy dips below a threshold or users notice a decline in performance, then you may be experiencing such drift. At this point, you would need to collect new data (either from scratch or supplement your existing dataset), retrain the model, and redeploy.
You can set up automatic processes to handle this. For example, perhaps an on-device process notices too many false positives, which triggers another process to collect data to send to your datalake. The presence of new data in that store then triggers a retraining of the model, which can then be deployed back to the edge device.
Edge device updates
For cloud-based AI, updating the model involves a little effort. Either the end device requests or the server pushes the model to the prediction server. Because most of these servers run operating systems (e.g. Linux), stopping a process or program and restarting it is often trivial. The same holds true for edge devices like laptops and smartphones.
On the other hand, updating models on microcontroller-based IoT devices is more involved. The model is usually baked into the firmware compiled for the device. As such, the firmware must be completely reloaded (flashed) onto the device. In general, these devices are created with the intention of requiring little or no interaction from the user to update its application.
If a model or application update is required, you could notify your users to manually update the firmware (e.g. by plugging the device into a computer). Alternatively, you could create an over-the-air (OTA) solution to push and update the firmware automatically.
You can see how Edge Impulse helps support OTA updates to create automated updates to IoT devices here.
A number of MLOps tools exist to help data scientists, ML experts, and developers create fully automated ML pipelines. Here are a few examples:
Edge Impulse is a unique solution by offering the tools necessary to build full MLOps pipelines optimized for the edge.
Quiz
Test your knowledge on edge MLOps with the following quiz: