Only available on the Enterprise planThis feature is only available on the Enterprise plan. Review our plans and pricing or sign up for our free expert-led trial today.
Block structure
The deployment block structure is shown below. A custom deployment block consists of:- Scripts: Your deployment logic (Python, JavaScript, etc.)
- Dockerfile: Instructions for building the container image
- parameters.json: Block metadata and parameter definitions
- package.json (optional): Node.js dependencies if using JavaScript/TypeScript
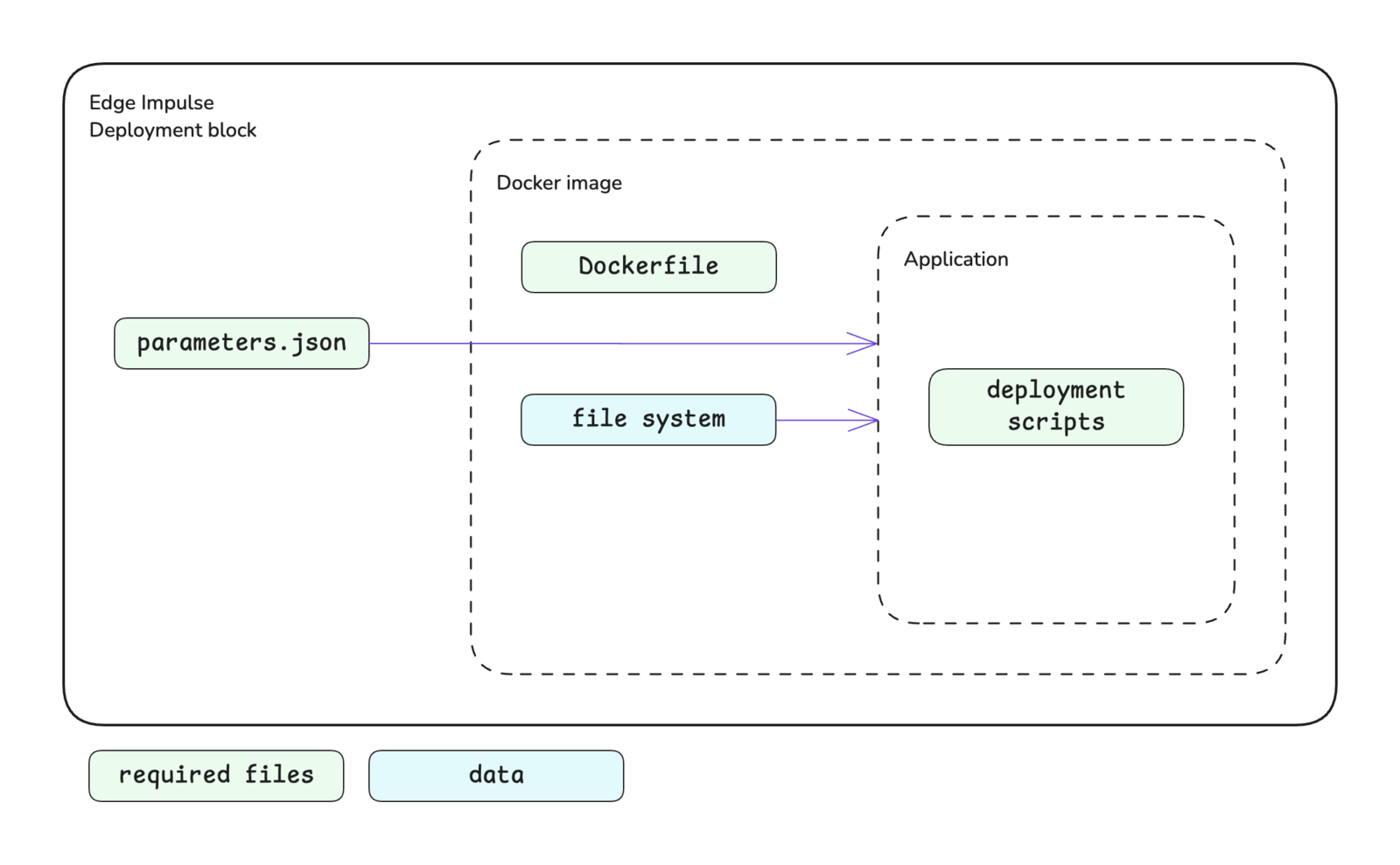
Custom deployment block structure
package.json for a Node.js-based deployment block:
Block interface
The sections below define the required and optional inputs and the expected outputs for custom deployment blocks.Inputs
Deployment blocks have access to command line arguments and input files.Command line arguments
The following arguments will be automatically passed to your custom deployment block.
CLI arguments can also be specified using the
cliArguments property in the parameters.json file. Alternatively, these arguments can be added (or changed) by editing the block in Studio.
Files
Your deployment block will be passed an input directory that contains all the information required for a deployment, including: deployment metadata, the Edge Impulse SDK, the trained model (in multiple formats), and all supporting source code to run the impulse. The input directory path is stored in theinput property under the folders property in the deployment-metadata.json file, which can be loaded using the --metadata <file> argument that is passed to the deployment block.
The input directory structure is shown below.
Outputs
The expected output from your custom deployment block is a ZIP file nameddeploy.zip located in the output directory. This archive is what will be downloaded for the user after your block has finished building.
The output directory path is stored in the output property under the folders property in the deployment-metadata.json file, which can be loaded using the --metadata <file> argument that is passed to the deployment block.
Creating a build directory
The input and output directories listed in thedeployment-metadata.json file are located on network storage. Therefore to improve the speed of your deployment block, it is best practice to create a build directory, copy in the required items for your build, then write the output archive to the output directory.
In the example below, the app_dir contained the build instructions and files required to compile a Linux application.
Mounting learning block data
If your custom deployment block requires access to the data used to train your model, you can mount the learning block by setting themountLearnBlock property to true. This will mount all files for the learning block, including the training data, under a /data directory within your block.
The training data is already split into train and test (validation) sets. Please refer to the Data section under Inputs in the custom learning block documentation for additional details.
Accessing the internet
Deployment blocks do not have access to the internet by default. If you need to access information outside of your block, such as project items through the Edge Impulse API, you will need to set theprivileged property to true.
This will enable internet access and pass in the project API key in the deployment-metadata.json file (if a project development API key is set) that can be used to authenticate with the Edge Impulse API. Note that if you also require the project ID, this can be retrieved using the list active projects API endpoint.
Custom parameters
Custom deployment blocks can accept user-defined parameters that are configured at deployment time. These parameters are defined in theparameters array within your parameters.json file and are presented to users in the Studio UI when they deploy with your custom block.
Each parameter defines a configuration option with properties including:
name: The display label shown in the UIparam: The parameter name used when passed to your script as a command line argument (e.g.,--param-name <value>)type: The input type (e.g.,selectfor dropdown menus)value: The default valuevalid: Array of allowed values for the parameterhelp: Optional description text to guide users
- Selected values are passed to your deployment block script as command line arguments
- Configuration is stored in
project_deployment_historyto persist settings across deployments
- Target hardware configurations
- Build optimization levels
- Custom firmware settings
- Output format selection
Build options
Parameters can be presented as dropdown menus in the deployment UI, allowing users to select from predefined options. This is particularly useful for build configurations where only specific values are valid. Example dropdown parameter configuration:showIf property:
Showing optimization options
Setting theshowOptimizations property to true will present the user with additional optimization options on the Deployment page in Studio.
Firstly, if the supportsEonCompiler property is set to true (see below), the user will be presented with a dropdown to select between building the deployment using the EON Compiler or standard TFLite file inputs.
Secondly, the user will be presented with quantization options, if applicable. If the user selects the quantized model option, the trained.tflite file will be the int8 version of the model; otherwise it will be the float32 version.
Using the EON Compiler
If thesupportsEonCompiler property is set to true, the inputs for the deployment block will be the EON Compiler version of the files; otherwise the inputs will be the TFLite version of the files.
However, if the showOptimizations property is set to true (see above), the user will have the option on the Deployment page in Studio to select between the EON Compiler or standard TFLite file inputs.
Setting an image for the block
The default image that will appear for your block in the dropdown in Studio on the Deployment page is the Edge Impulse logo. If you would like to change this, you can do so by editing the block after it has been pushed to Studio.Initializing the block
When you are finished developing your block locally, you will want to initialize it. The procedure to initialize your block is described in the custom blocks overview page. Please refer to that documentation for details.Testing the block locally
To speed up your development process, you can test your custom deployment block locally. There are two ways to achieve this. You will need to have Docker installed on your machine for either approach.With blocks runner
For the first method, you can use the CLIedge-impulse-blocks runner tool. See Block runner for additional details. The runner does not expect any command line arguments for deployment blocks. However, if your deployment block requires arguments, you can pass them as a single string using the --extra-args <args> argument.
--clean flag.
Using the above approach will create an ei-block-data directory within your custom block directory. It will contain several subdirectories.
With Docker
For the second method, you can use the CLI block runner or Studio to download the required data from your project, then build the Docker image and run the container directly. You can download the data by calling the block runner with the--download-data <dir> argument. The directory specifies the location where the downloaded data should be extracted. To make this work properly the directory needs to be named input/. Before extraction, the data archive will first be downloaded to ei-block-data/download/.
Custom block as your deployment option. This will allow you to download a ZIP file of the required input files for you deployment block. Extract this archive to a directory called input/ within your custom deployment block directory.
After downloading the required input files for your block, you can then build the Docker image and run the container.
Pushing the block to Edge Impulse
When you have initialized and finished testing your block locally, you will want to push it to Edge Impulse. The procedure to push your block to Edge Impulse is described in the custom blocks overview page. Please refer to that documentation for details.Using the block in a project
After you have pushed your block to Edge Impulse, it can be used in the same way as any other built-in block.Examples
Edge Impulse has developed several examples of custom deployment blocks. The code for these blocks can be found in public repositories under the Edge Impulse GitHub account. Unfortunately, the repository names don’t follow a naming convention. However, they can be found by going to the Edge Impulse account and searching the repositories fordeploy.
Below are direct links to a some examples:
Troubleshooting
No common issues have been identified thus far. If you encounter an issue, please reach out on the forum or, if you are on the Enterprise plan, through your support channels.