> ## Documentation Index
> Fetch the complete documentation index at: https://docs.edgeimpulse.com/llms.txt
> Use this file to discover all available pages before exploring further.
# QNN hardware acceleration on Android
> Enable Qualcomm AI Engine Direct SDK acceleration for Edge Impulse models on Snapdragon devices
Enable hardware acceleration for Edge Impulse models on Android using the Qualcomm AI Engine Direct (QNN) TFLite Delegate. This tutorial demonstrates object detection with real-time performance improvements on Snapdragon devices.
This tutorial builds on the [Camera Inference tutorial](./camera-inference). You'll add QNN hardware acceleration to leverage Qualcomm's Hexagon NPU for significantly faster inference.\
Reference code: [https://github.com/edgeimpulse/qnn-hardware-acceleration](https://github.com/edgeimpulse/qnn-hardware-acceleration)
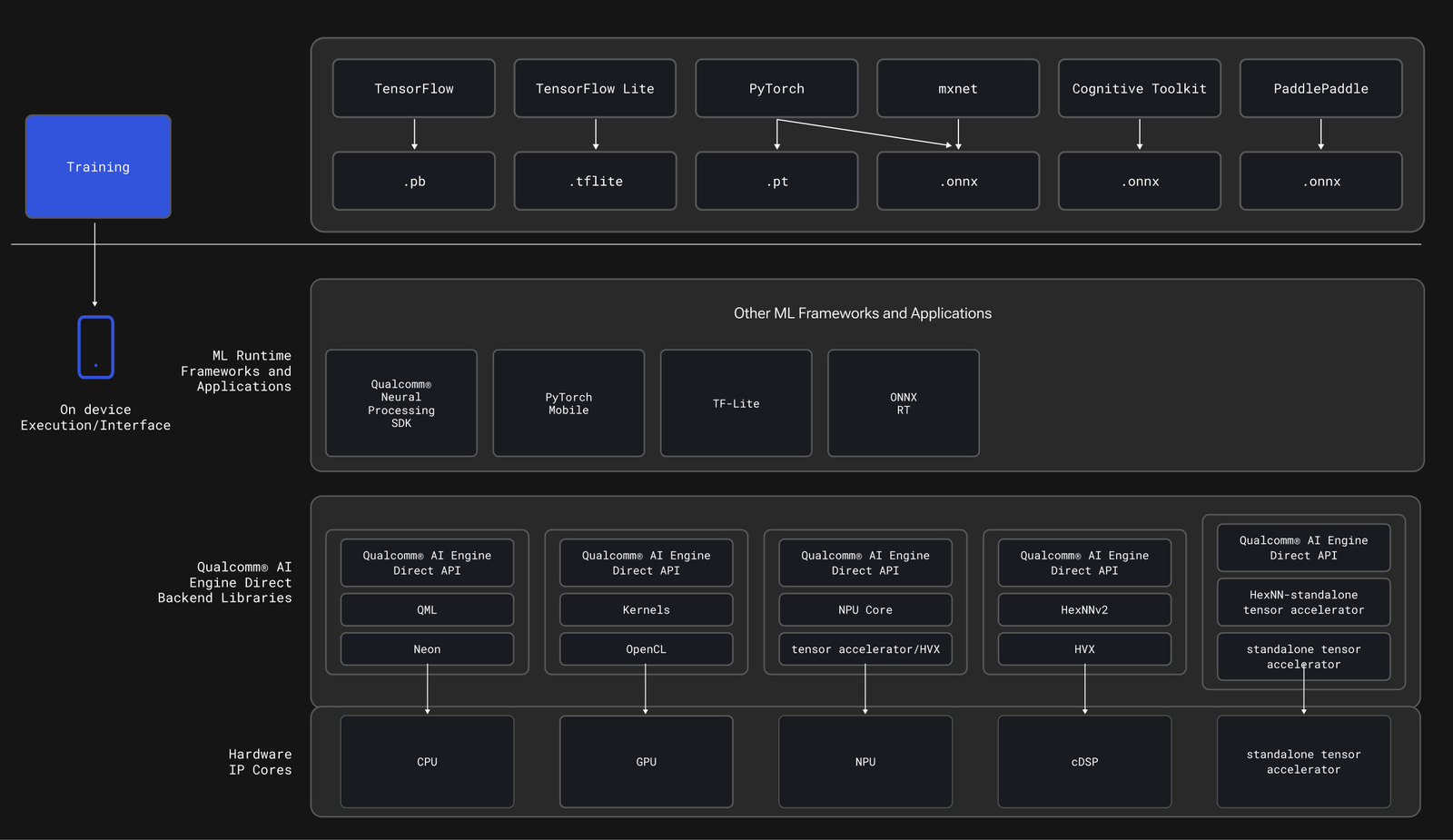 ## What you'll build
An Android application that:
* Runs Edge Impulse object detection models with Camera2 API
* Accelerates inference using Qualcomm's HTP/DSP via QNN delegate
* Displays real-time bounding boxes with overlay
* Logs detailed performance metrics to Logcat
## Performance expectations
Results from YOLOv5 small (480×480 quantized) on Qualcomm RB3 Gen 2 (6490):
| Path | DSP (µs) | Inference (µs) | Speedup |
| ----------- | -------- | -------------- | ------------------ |
| Without QNN | 5,640 | 5,748 | Baseline |
| With QNN | 3,748 | 527 | **\~10.9× faster** |
**Conservative gains:**
## What you'll build
An Android application that:
* Runs Edge Impulse object detection models with Camera2 API
* Accelerates inference using Qualcomm's HTP/DSP via QNN delegate
* Displays real-time bounding boxes with overlay
* Logs detailed performance metrics to Logcat
## Performance expectations
Results from YOLOv5 small (480×480 quantized) on Qualcomm RB3 Gen 2 (6490):
| Path | DSP (µs) | Inference (µs) | Speedup |
| ----------- | -------- | -------------- | ------------------ |
| Without QNN | 5,640 | 5,748 | Baseline |
| With QNN | 3,748 | 527 | **\~10.9× faster** |
**Conservative gains:**
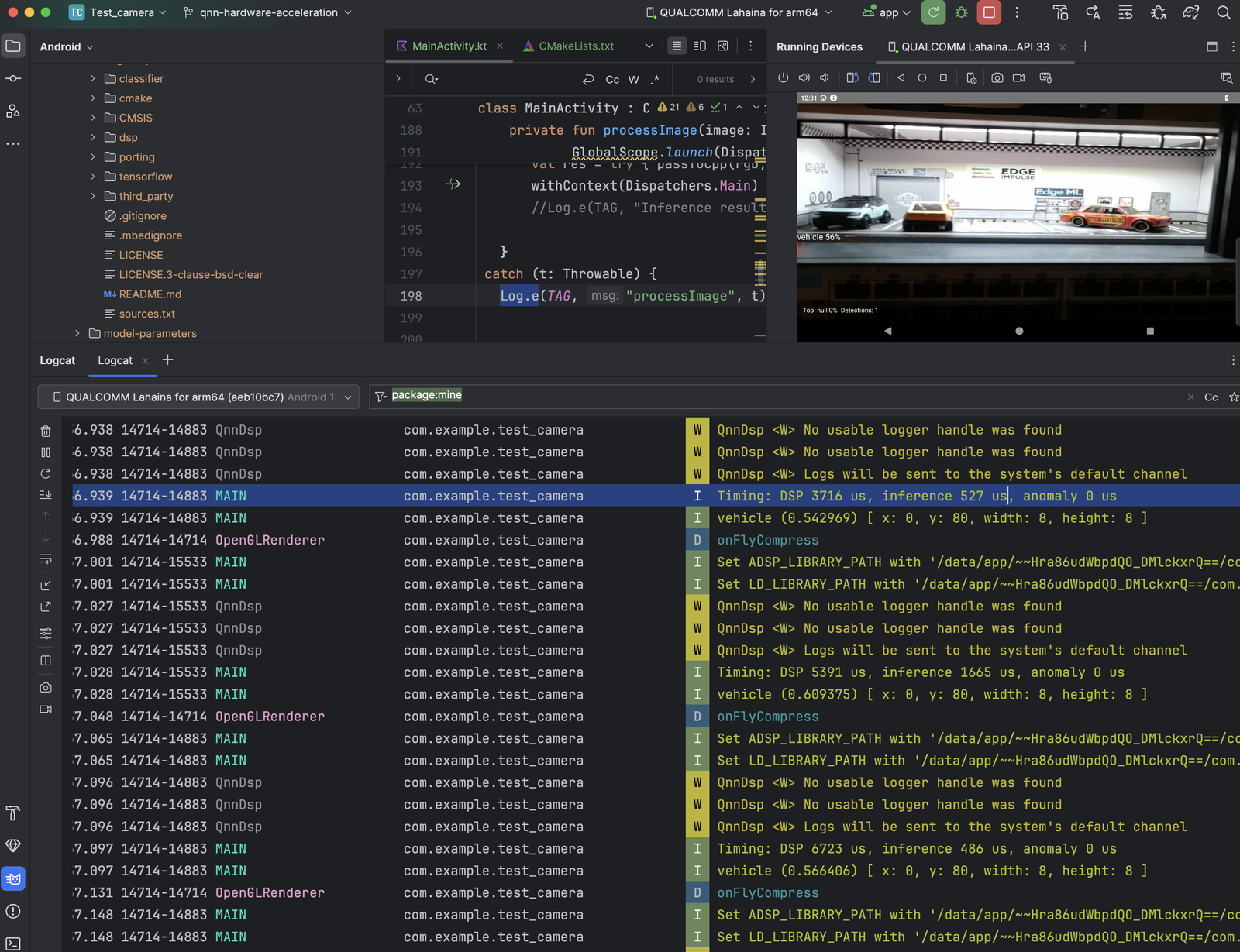
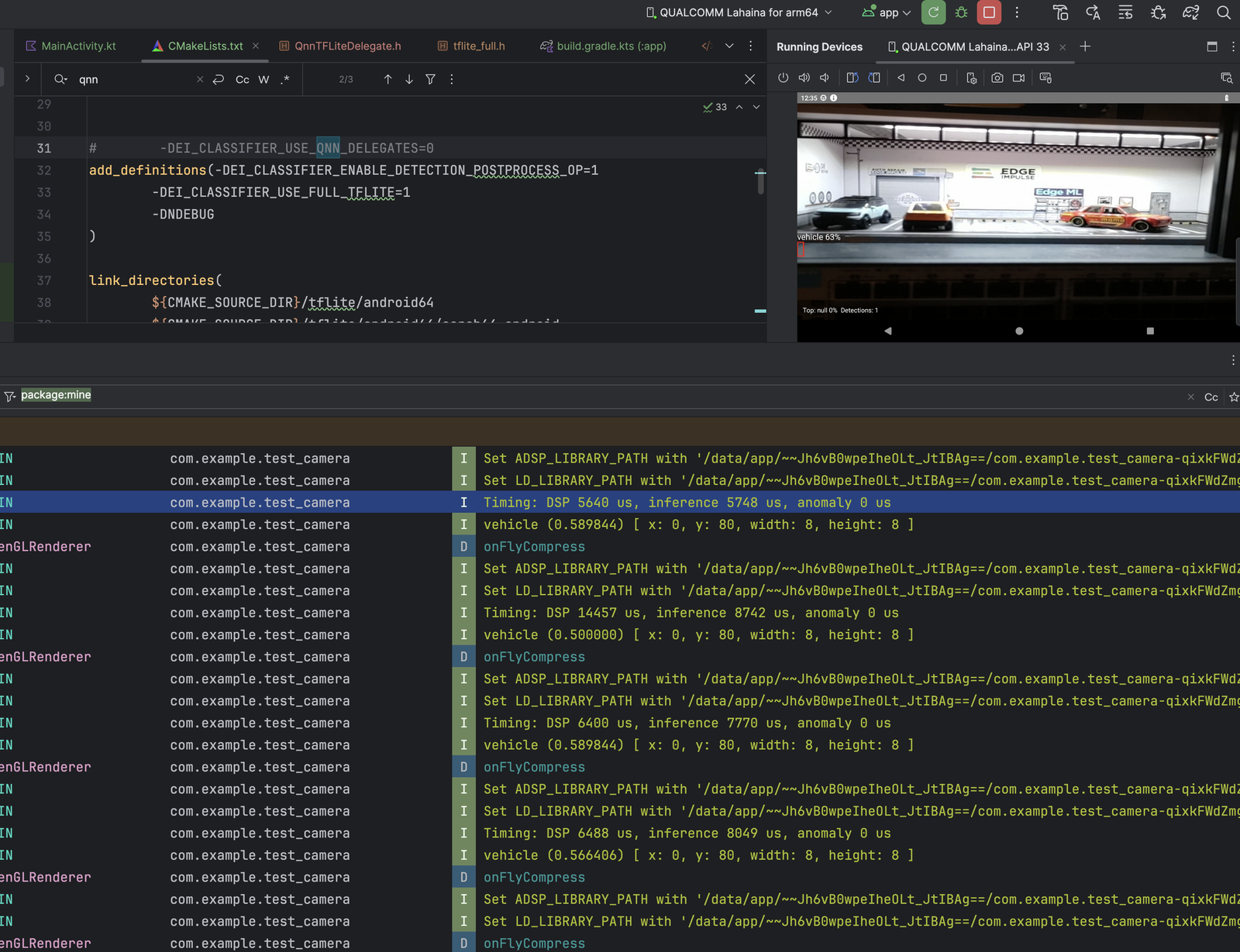 * Inference: 5,748 → 527 µs ≈ **10.9× faster**
* DSP stage: 5,640 → 3,748 µs ≈ **1.5× faster**
* Smoother frame times with dedicated accelerator
* Lower power consumption
INT8 quantized is required for HTP acceleration.
Performance varies by device SoC, model architecture, and quantization. Optimizing your model for available QNN operations increases speedup dramatically.
## Prerequisites
* **Edge Impulse account**: [Sign up](https://edgeimpulse.com/signup)
* **Trained object detection model**
* **Android Studio**: Ladybug 2024.2.2 or later
* **Snapdragon device real or [Qualcomm Device Cloud](https://docs.edgeimpulse.com/tutorials/topics/inference/run-qualcomm-device-cloud) with Hexagon NPU:**
* Snapdragon 8 Gen 1/2/3 (mobile)
* Snapdragon 6/7 series (mid-range)
* QRB series (embedded: RB3, RB5, Dragonwing)
* **Qualcomm AI Engine Direct SDK**: [Download from Qualcomm](https://www.qualcomm.com/developer/software/qualcomm-ai-engine-direct-sdk)
* **Tools**: Android API 35, NDK 27.0.12077973, CMake 3.22.1
## Supported devices
Devices with Qualcomm Hexagon NPU Gen 2 or later:
**Mobile:**
* Inference: 5,748 → 527 µs ≈ **10.9× faster**
* DSP stage: 5,640 → 3,748 µs ≈ **1.5× faster**
* Smoother frame times with dedicated accelerator
* Lower power consumption
INT8 quantized is required for HTP acceleration.
Performance varies by device SoC, model architecture, and quantization. Optimizing your model for available QNN operations increases speedup dramatically.
## Prerequisites
* **Edge Impulse account**: [Sign up](https://edgeimpulse.com/signup)
* **Trained object detection model**
* **Android Studio**: Ladybug 2024.2.2 or later
* **Snapdragon device real or [Qualcomm Device Cloud](https://docs.edgeimpulse.com/tutorials/topics/inference/run-qualcomm-device-cloud) with Hexagon NPU:**
* Snapdragon 8 Gen 1/2/3 (mobile)
* Snapdragon 6/7 series (mid-range)
* QRB series (embedded: RB3, RB5, Dragonwing)
* **Qualcomm AI Engine Direct SDK**: [Download from Qualcomm](https://www.qualcomm.com/developer/software/qualcomm-ai-engine-direct-sdk)
* **Tools**: Android API 35, NDK 27.0.12077973, CMake 3.22.1
## Supported devices
Devices with Qualcomm Hexagon NPU Gen 2 or later:
**Mobile:**
 * Snapdragon 8 Gen 3/2/1
* Snapdragon 7+ Gen 2/3
* Snapdragon 6 Gen 1
**Embedded:**
* QRB6490 (Rubik Pi 3)
* QRB5165 (RB5)
* Dragonwing platforms
**Test on Device Cloud:**\
Don't have hardware? Try the [Qualcomm Device Cloud](https://docs.edgeimpulse.com/tutorials/topics/inference/run-qualcomm-device-cloud) with pre-configured Snapdragon devices.
## 1. Clone the repository
```bash theme={"system"}
git clone https://github.com/edgeimpulse/qnn-hardware-acceleration.git
cd qnn-hardware-acceleration
```
Open in Android Studio and let Gradle/NDK sync.
## 2. Locate Qualcomm AI Engine Direct SDK
Download and install the [Qualcomm AI Engine Direct SDK](https://www.qualcomm.com/developer/software/qualcomm-ai-engine-direct-sdk).
**Common installation paths:**
```bash theme={"system"}
# macOS/Linux
/opt/qairt//
~/qairt//
# Windows
C:\qairt\\
```
You're looking for the folder containing `libQnnTFLiteDelegate.so` for Android arm64.
### Find the delegate directory
**macOS/Linux:**
```bash theme={"system"}
# Replace /opt/qairt/2.xx with your actual path
find /opt/qairt/2.xx -type f -name libQnnTFLiteDelegate.so
```
**Windows:**
Open File Explorer at `C:\qairt\\` and search for `libQnnTFLiteDelegate.so`.
The parent folder of that file is your source directory (it also contains other `libQnn*.so` runtime libs).
## 3. Copy QNN libraries
Create the destination directory in your project:
```bash theme={"system"}
mkdir -p app/src/main/jniLibs/arm64-v8a/
```
Copy the required libraries from the delegate directory you found:
**Required libraries:**
```bash theme={"system"}
# From QAIRT SDK to app/src/main/jniLibs/arm64-v8a/
libQnnTFLiteDelegate.so
libQnnHtp.so
libQnnHtpV**.so # Match your device (V68/V69/V75/V79)
libQnnHtpV**Skel.so # Skeleton library for your version
libQnnSystem.so
libQnnIr.so
libQnnSaver.so # If included in your SDK
libPlatformValidatorShared.so # If included
```
**Optional:**
```bash theme={"system"}
libcdsprpc.so # Some devices provide from /vendor
```
The repository includes a fetch script:
```bash theme={"system"}
sh ./fetchqnnlibs.sh
```
You'll need to configure the script with your QAIRT SDK path first.
## 4. Deploy your model
In Edge Impulse Studio:
1. Go to **Deployment**
2. Select **Android (C++ library)**
3. Enable **Quantized (int8)** for best QNN performance
4. Click **Build**
5. Download the `.zip`
Extract into your project:
```bash theme={"system"}
unzip ~/Downloads/your-model.zip -d app/src/main/cpp/
```
## 5. Configure Android manifest
Update `app/src/main/AndroidManifest.xml`:
```xml theme={"system"}
```
This ensures QNN libraries are extracted and accessible.
## 6. Build and run
### Build in Android Studio
1. Connect your Snapdragon device via USB
2. Enable **USB debugging** in Developer Options
3. Click **Run** (green play button)
4. Select your device
### Monitor performance
Open **Logcat** and filter by `MainActivity`:
```bash theme={"system"}
adb logcat -s MainActivity
```
Expected output:
```
DSP: 3748 us
Classification: 527 us
Anomaly: 0 us
End-to-end: 21 ms (~48 FPS)
```
### Verify QNN acceleration
Check if QNN libraries are loaded:
```bash theme={"system"}
# Check memory maps for QNN libraries
adb shell 'pid=$(pidof -s com.yourpackage.name); cat /proc/$pid/maps | grep -i qnn'
# Verify profiling output (if enabled)
adb shell ls -l /sdcard/qnn_profile.json
```
If you see QNN library paths, acceleration is active.
## How it works
### QNN TFLite delegate integration
```cpp theme={"system"}
// native-lib.cpp
#include
TfLiteDelegate* LoadQnnDelegate() {
// Set environment for QNN
setenv("ADSP_LIBRARY_PATH", GetNativeLibDir() + ":/dsp", 1);
setenv("LD_LIBRARY_PATH", GetNativeLibDir() + ":" +
getenv("LD_LIBRARY_PATH"), 1);
// Configure QNN options
const char* qnn_options =
R"({"backend":"htp",
"htp_performance_mode":"burst",
"enable_intermediate_outputs":false})";
// Load delegate
TfLiteExternalDelegateOptions options =
TfLiteExternalDelegateOptionsDefault("/path/to/libQnnTFLiteDelegate.so");
options.insert(&options, "qnn_options", qnn_options);
return TfLiteExternalDelegateCreate(&options);
}
```
### Environment configuration
The app automatically sets required environment variables on startup:
```kotlin theme={"system"}
// MainActivity.kt
private fun setupQnnEnvironment() {
val nativeLibDir = applicationInfo.nativeLibraryDir
// Set library paths for QNN
System.setProperty("ADSP_LIBRARY_PATH", "$nativeLibDir:/dsp")
System.setProperty("LD_LIBRARY_PATH", "$nativeLibDir:${System.getenv("LD_LIBRARY_PATH")}")
Log.d(TAG, "QNN environment configured: $nativeLibDir")
}
```
## Project structure
```
qnn-hardware-acceleration/
├── app/
│ └── src/
│ ├── main/
│ │ ├── java/com/example/test_camera/
│ │ │ ├── MainActivity.kt # Camera + overlay UI
│ │ │ ├── CameraManager.kt # Camera2 handling
│ │ │ └── OverlayView.kt # Bounding box drawing
│ │ ├── cpp/
│ │ │ ├── native-lib.cpp # JNI + QNN integration
│ │ │ ├── edge-impulse-sdk/ # Your model
│ │ │ ├── model-parameters/
│ │ │ └── tflite-model/
│ │ ├── jniLibs/
│ │ │ └── arm64-v8a/ # QNN shared libraries
│ │ └── AndroidManifest.xml
│ └── CMakeLists.txt
└── build.gradle
```
## Customization
### Adjust HTP performance mode
In `native-lib.cpp`, modify QNN options:
```cpp theme={"system"}
// Options: "default", "burst", "balanced", "low_power", "high_performance"
const char* qnn_options =
R"({"backend":"htp",
"htp_performance_mode":"high_performance",
"enable_intermediate_outputs":false})";
```
**Modes:**
* `burst`: Maximum speed, higher power (default)
* `high_performance`: Sustained high performance
* `balanced`: Balance between speed and power
* `low_power`: Minimize power consumption
### Enable profiling
```cpp theme={"system"}
const char* qnn_options =
R"({"backend":"htp",
"htp_performance_mode":"burst",
"profiling_level":"detailed",
"enable_intermediate_outputs":true})";
```
Profile output saved to `/sdcard/qnn_profile.json`.
### Optimize model for QNN
In Edge Impulse Studio:
1. **Use quantization**: INT8 models leverage HTP better than FP32
2. **Supported operations**: Check [QNN operator support](https://developer.qualcomm.com/software/qualcomm-ai-engine-direct-sdk/tools)
3. **Enable EON Compiler**: Optimizes for Qualcomm hardware
### Change detection threshold
```kotlin theme={"system"}
// MainActivity.kt
private val DETECTION_THRESHOLD = 0.5f // Default
// Modify to be more/less sensitive
private val DETECTION_THRESHOLD = 0.7f // Less sensitive (fewer false positives)
private val DETECTION_THRESHOLD = 0.3f // More sensitive (more detections)
```
## Performance tuning tips
### Model optimization
1. **Use INT8 quantization** - Essential for HTP acceleration
2. **Reduce input resolution** - 320×320 vs 640×640 can be 4× faster
3. **Simplify architecture** - Fewer layers = better HTP utilization
4. **Test operator coverage** - Check which ops run on HTP vs CPU
### Runtime optimization
```cpp theme={"system"}
// Increase thread count for CPU fallback operations
interpreter->SetNumThreads(4);
// Allocate tensors once
interpreter->AllocateTensors();
// Reuse input/output buffers
TfLiteTensor* input = interpreter->input_tensor(0);
TfLiteTensor* output = interpreter->output_tensor(0);
```
### Frame rate optimization
```kotlin theme={"system"}
// Reduce camera frame rate if processing can't keep up
val fpsRange = Range(15, 30) // 15-30 FPS instead of 30-60
captureRequestBuilder.set(
CaptureRequest.CONTROL_AE_TARGET_FPS_RANGE,
fpsRange
)
```
## Benchmark results
Real-world performance on different devices:
| Device | Model | Without QNN | With QNN | Speedup |
| ----------------------- | -------------------- | ----------- | -------- | ------------- |
| RB3 Gen 2 (6490) | YOLOv5s 480×480 INT8 | 5.7 ms | 0.5 ms | **11.4×** |
| Snapdragon 8 Gen 2 | FOMO 96×96 INT8 | 2.1 ms | 0.3 ms | **7.0×** |
| Pixel 8 Pro (Tensor G3) | YOLOv5s 320×320 INT8 | N/A | N/A | Not supported |
Google Tensor processors don't include Hexagon NPU. QNN acceleration only works on Qualcomm Snapdragon devices.
## Next steps
Test without hardware
## Resources
* [GitHub: qnn-hardware-acceleration](https://github.com/edgeimpulse/qnn-hardware-acceleration)
* [Qualcomm AI Engine Direct SDK Docs](https://developer.qualcomm.com/software/qualcomm-ai-engine-direct-sdk)
* [QNN TFLite Delegate Guide](https://developer.qualcomm.com/software/qualcomm-ai-engine-direct-sdk/tools)
* [Device Cloud Tutorial](https://docs.edgeimpulse.com/tutorials/topics/inference/run-qualcomm-device-cloud)
* [Edge Impulse Forum](https://forum.edgeimpulse.com/)
* Snapdragon 8 Gen 3/2/1
* Snapdragon 7+ Gen 2/3
* Snapdragon 6 Gen 1
**Embedded:**
* QRB6490 (Rubik Pi 3)
* QRB5165 (RB5)
* Dragonwing platforms
**Test on Device Cloud:**\
Don't have hardware? Try the [Qualcomm Device Cloud](https://docs.edgeimpulse.com/tutorials/topics/inference/run-qualcomm-device-cloud) with pre-configured Snapdragon devices.
## 1. Clone the repository
```bash theme={"system"}
git clone https://github.com/edgeimpulse/qnn-hardware-acceleration.git
cd qnn-hardware-acceleration
```
Open in Android Studio and let Gradle/NDK sync.
## 2. Locate Qualcomm AI Engine Direct SDK
Download and install the [Qualcomm AI Engine Direct SDK](https://www.qualcomm.com/developer/software/qualcomm-ai-engine-direct-sdk).
**Common installation paths:**
```bash theme={"system"}
# macOS/Linux
/opt/qairt//
~/qairt//
# Windows
C:\qairt\\
```
You're looking for the folder containing `libQnnTFLiteDelegate.so` for Android arm64.
### Find the delegate directory
**macOS/Linux:**
```bash theme={"system"}
# Replace /opt/qairt/2.xx with your actual path
find /opt/qairt/2.xx -type f -name libQnnTFLiteDelegate.so
```
**Windows:**
Open File Explorer at `C:\qairt\\` and search for `libQnnTFLiteDelegate.so`.
The parent folder of that file is your source directory (it also contains other `libQnn*.so` runtime libs).
## 3. Copy QNN libraries
Create the destination directory in your project:
```bash theme={"system"}
mkdir -p app/src/main/jniLibs/arm64-v8a/
```
Copy the required libraries from the delegate directory you found:
**Required libraries:**
```bash theme={"system"}
# From QAIRT SDK to app/src/main/jniLibs/arm64-v8a/
libQnnTFLiteDelegate.so
libQnnHtp.so
libQnnHtpV**.so # Match your device (V68/V69/V75/V79)
libQnnHtpV**Skel.so # Skeleton library for your version
libQnnSystem.so
libQnnIr.so
libQnnSaver.so # If included in your SDK
libPlatformValidatorShared.so # If included
```
**Optional:**
```bash theme={"system"}
libcdsprpc.so # Some devices provide from /vendor
```
The repository includes a fetch script:
```bash theme={"system"}
sh ./fetchqnnlibs.sh
```
You'll need to configure the script with your QAIRT SDK path first.
## 4. Deploy your model
In Edge Impulse Studio:
1. Go to **Deployment**
2. Select **Android (C++ library)**
3. Enable **Quantized (int8)** for best QNN performance
4. Click **Build**
5. Download the `.zip`
Extract into your project:
```bash theme={"system"}
unzip ~/Downloads/your-model.zip -d app/src/main/cpp/
```
## 5. Configure Android manifest
Update `app/src/main/AndroidManifest.xml`:
```xml theme={"system"}
```
This ensures QNN libraries are extracted and accessible.
## 6. Build and run
### Build in Android Studio
1. Connect your Snapdragon device via USB
2. Enable **USB debugging** in Developer Options
3. Click **Run** (green play button)
4. Select your device
### Monitor performance
Open **Logcat** and filter by `MainActivity`:
```bash theme={"system"}
adb logcat -s MainActivity
```
Expected output:
```
DSP: 3748 us
Classification: 527 us
Anomaly: 0 us
End-to-end: 21 ms (~48 FPS)
```
### Verify QNN acceleration
Check if QNN libraries are loaded:
```bash theme={"system"}
# Check memory maps for QNN libraries
adb shell 'pid=$(pidof -s com.yourpackage.name); cat /proc/$pid/maps | grep -i qnn'
# Verify profiling output (if enabled)
adb shell ls -l /sdcard/qnn_profile.json
```
If you see QNN library paths, acceleration is active.
## How it works
### QNN TFLite delegate integration
```cpp theme={"system"}
// native-lib.cpp
#include
TfLiteDelegate* LoadQnnDelegate() {
// Set environment for QNN
setenv("ADSP_LIBRARY_PATH", GetNativeLibDir() + ":/dsp", 1);
setenv("LD_LIBRARY_PATH", GetNativeLibDir() + ":" +
getenv("LD_LIBRARY_PATH"), 1);
// Configure QNN options
const char* qnn_options =
R"({"backend":"htp",
"htp_performance_mode":"burst",
"enable_intermediate_outputs":false})";
// Load delegate
TfLiteExternalDelegateOptions options =
TfLiteExternalDelegateOptionsDefault("/path/to/libQnnTFLiteDelegate.so");
options.insert(&options, "qnn_options", qnn_options);
return TfLiteExternalDelegateCreate(&options);
}
```
### Environment configuration
The app automatically sets required environment variables on startup:
```kotlin theme={"system"}
// MainActivity.kt
private fun setupQnnEnvironment() {
val nativeLibDir = applicationInfo.nativeLibraryDir
// Set library paths for QNN
System.setProperty("ADSP_LIBRARY_PATH", "$nativeLibDir:/dsp")
System.setProperty("LD_LIBRARY_PATH", "$nativeLibDir:${System.getenv("LD_LIBRARY_PATH")}")
Log.d(TAG, "QNN environment configured: $nativeLibDir")
}
```
## Project structure
```
qnn-hardware-acceleration/
├── app/
│ └── src/
│ ├── main/
│ │ ├── java/com/example/test_camera/
│ │ │ ├── MainActivity.kt # Camera + overlay UI
│ │ │ ├── CameraManager.kt # Camera2 handling
│ │ │ └── OverlayView.kt # Bounding box drawing
│ │ ├── cpp/
│ │ │ ├── native-lib.cpp # JNI + QNN integration
│ │ │ ├── edge-impulse-sdk/ # Your model
│ │ │ ├── model-parameters/
│ │ │ └── tflite-model/
│ │ ├── jniLibs/
│ │ │ └── arm64-v8a/ # QNN shared libraries
│ │ └── AndroidManifest.xml
│ └── CMakeLists.txt
└── build.gradle
```
## Customization
### Adjust HTP performance mode
In `native-lib.cpp`, modify QNN options:
```cpp theme={"system"}
// Options: "default", "burst", "balanced", "low_power", "high_performance"
const char* qnn_options =
R"({"backend":"htp",
"htp_performance_mode":"high_performance",
"enable_intermediate_outputs":false})";
```
**Modes:**
* `burst`: Maximum speed, higher power (default)
* `high_performance`: Sustained high performance
* `balanced`: Balance between speed and power
* `low_power`: Minimize power consumption
### Enable profiling
```cpp theme={"system"}
const char* qnn_options =
R"({"backend":"htp",
"htp_performance_mode":"burst",
"profiling_level":"detailed",
"enable_intermediate_outputs":true})";
```
Profile output saved to `/sdcard/qnn_profile.json`.
### Optimize model for QNN
In Edge Impulse Studio:
1. **Use quantization**: INT8 models leverage HTP better than FP32
2. **Supported operations**: Check [QNN operator support](https://developer.qualcomm.com/software/qualcomm-ai-engine-direct-sdk/tools)
3. **Enable EON Compiler**: Optimizes for Qualcomm hardware
### Change detection threshold
```kotlin theme={"system"}
// MainActivity.kt
private val DETECTION_THRESHOLD = 0.5f // Default
// Modify to be more/less sensitive
private val DETECTION_THRESHOLD = 0.7f // Less sensitive (fewer false positives)
private val DETECTION_THRESHOLD = 0.3f // More sensitive (more detections)
```
## Performance tuning tips
### Model optimization
1. **Use INT8 quantization** - Essential for HTP acceleration
2. **Reduce input resolution** - 320×320 vs 640×640 can be 4× faster
3. **Simplify architecture** - Fewer layers = better HTP utilization
4. **Test operator coverage** - Check which ops run on HTP vs CPU
### Runtime optimization
```cpp theme={"system"}
// Increase thread count for CPU fallback operations
interpreter->SetNumThreads(4);
// Allocate tensors once
interpreter->AllocateTensors();
// Reuse input/output buffers
TfLiteTensor* input = interpreter->input_tensor(0);
TfLiteTensor* output = interpreter->output_tensor(0);
```
### Frame rate optimization
```kotlin theme={"system"}
// Reduce camera frame rate if processing can't keep up
val fpsRange = Range(15, 30) // 15-30 FPS instead of 30-60
captureRequestBuilder.set(
CaptureRequest.CONTROL_AE_TARGET_FPS_RANGE,
fpsRange
)
```
## Benchmark results
Real-world performance on different devices:
| Device | Model | Without QNN | With QNN | Speedup |
| ----------------------- | -------------------- | ----------- | -------- | ------------- |
| RB3 Gen 2 (6490) | YOLOv5s 480×480 INT8 | 5.7 ms | 0.5 ms | **11.4×** |
| Snapdragon 8 Gen 2 | FOMO 96×96 INT8 | 2.1 ms | 0.3 ms | **7.0×** |
| Pixel 8 Pro (Tensor G3) | YOLOv5s 320×320 INT8 | N/A | N/A | Not supported |
Google Tensor processors don't include Hexagon NPU. QNN acceleration only works on Qualcomm Snapdragon devices.
## Next steps
Test without hardware
## Resources
* [GitHub: qnn-hardware-acceleration](https://github.com/edgeimpulse/qnn-hardware-acceleration)
* [Qualcomm AI Engine Direct SDK Docs](https://developer.qualcomm.com/software/qualcomm-ai-engine-direct-sdk)
* [QNN TFLite Delegate Guide](https://developer.qualcomm.com/software/qualcomm-ai-engine-direct-sdk/tools)
* [Device Cloud Tutorial](https://docs.edgeimpulse.com/tutorials/topics/inference/run-qualcomm-device-cloud)
* [Edge Impulse Forum](https://forum.edgeimpulse.com/)